RFC: Dataverse + Globus Integration

Gerrick Teague
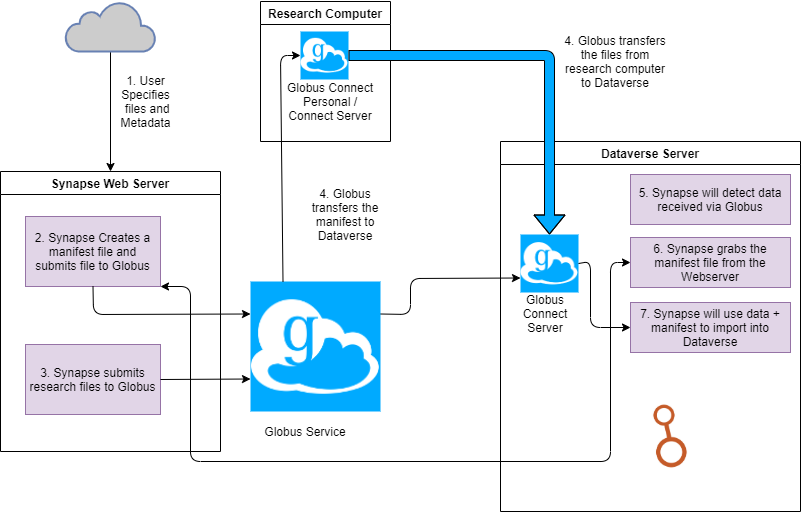
Step 7 is a python cli job that checks if any new data appears in the 'inbox'. If so, it grabs the ID from the inbox, then retrieves the manifest from the Synapse web server. If Globus says the transfer is complete, we utilize the standard Dataverse API to import the files as normal, then do clean up. Since the large file is already "on" the Dataverse server (which itself is on the HPC cluster), the importing into Dataverse won't be constrained by bandwidth/connection issues. But this is a partial solution.
We are planning on checking if a file is large, and if so, import a 'dummy' file into the API with the correct metadata, etc. but not the actual file itself. (or perhaps just a truncated version of the file) Once the small dummy is imported, we then replace the Dataverse file with the large file, then go into PostgreSQL and update the file size in the corresponding record.

me...@hkl.hms.harvard.edu

Philip Durbin
I'm glad you've already found this big data mailing list. You're in the right place. I'd say you should also feel free to mention what you're up to on the main list (dataverse-community). Perhaps you could link to the thread here.
I have a couple of suggestions for you.
First, please consider joining the Remote Storage/Large Datasets Working Group. This and other working groups are still forming so you can get in on the ground floor. For details, please see the "GDCC working groups" thread at https://groups.google.com/g/dataverse-community/c/EY0dduRj3Ac/m/EDcEQHLoAwAJ
Second, I highly recommend watching the "Globus Transfer Integration" talk by Meghan Goodchild from Scholars Portal, where she summarizes their recent efforts to integrate Globus with Dataverse and gives a great demo at the end. (This is the work that Pete mentioned.) The talk can be found at https://youtu.be/LHyiA3JeiwE?t=725 and the code at https://github.com/scholarsportal/dataverse/tree/dataverse-v4.17-SP-globus-phase1
As for your implementation, it looks great to me. I hope you haven't had to fork Dataverse. If there are changes you need to the core code, please go ahead and open issues on GitHub.
Since OnDemand is part of your solution, you might want to comment on this issue I opened about integrating with data repositories: https://github.com/OSC/ondemand/issues/354
I was pretty excited to see the "send to cluster" button you put into Dataverse. As we may have talked about elsewhere, when Dataverse is configured for rsync the dataset landing page will indicate where the files are on the cluster, which directory they reside in. That is to say we definitely understand the need for this functionality, mostly thanks to Pete.
You mentioned dummy files. We use that exact trick to get large files into Dataverse, sometimes. Hopefully various large data efforts will obviate the need for that trick. :)
The last thing I'll mention for now is that we maintain a list of integrations as part of the Dataverse Admin Guide. When Synapse is ready to be added to the list, please go ahead and open an issue. Here's the list as of the latest release, Dataverse 4.20: http://guides.dataverse.org/en/4.20/admin/integrations.html
Thanks for putting all this together. Again, it looks great.
--
You received this message because you are subscribed to the Google Groups "Dataverse Big Data" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-big-d...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-big-data/fa931767-5fde-413c-957d-3f9d7405cd06n%40googlegroups.com.
--
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
Gerrick Teague
me...@hkl.hms.harvard.edu

Victoria Lubitch
Gerrick
--
You received this message because you are subscribed to the Google Groups "Dataverse Big Data" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-big-d...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-big-data/273f245a-dd4b-42e5-bfb0-09fba7b39ee4n%40googlegroups.com.
Philip Durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Big Data" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-big-d...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-big-data/250ddce4-d31f-4494-a0c1-98f6c453e76eo%40googlegroups.com.