Counting True Pixel Height of a Capital Letter
78 views
Skip to first unread message

David R Anderson
Mar 13, 2023, 6:17:23 PM3/13/23
to tesseract-ocr
I'm preparing text images (JPG) for Tesseract OCR conversion to text files (TXT) I note that it is important to resize my image docs so that capital letters are about 30-32 pixels in height. See Optimal image resolution (dpi/ppi) for Tesseract 4.0.0 and eng.traineddata?
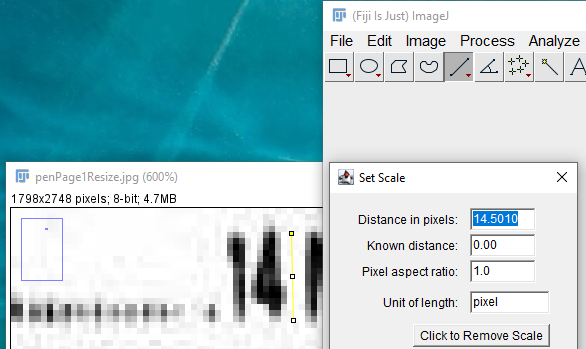
I am using the Fiji/ImageJ to count capital letter height in pixels. From https://imagej.nih.gov/ij/docs/pdfs/ImageJ.pdf
- Open image file
- Enlarge text (zoom in)
- Draw parallel vertical line beside vertical of number or straight edge letter
- Select Analyze>Set Scale (see image below)
How to count pixels? Do I count the 'half pixels'? Where the pixel 'block' is a half-tone? In other words, for my total count, do I estimate the true height by including these half-tones.
Does anyone have a better procedure than this?
My aim is to come up with a resizing ratio that I can apply to a large collection of text files using a Python script. This being another step along the way to preparing docs for Tesseract.
Any suggestions would be appreciated.

Isidore Paris
Mar 14, 2023, 5:41:48 PM3/14/23
to tesseract-ocr
I get the best result with PBM images, i.e b&w. Doing that way, there would be no half-tones… (Don't know if this could help…)
David R Anderson
Mar 14, 2023, 6:25:49 PM3/14/23
to tesser...@googlegroups.com
Thank you for your input. I appreciate the PBM file type has its uses. But my source material is JPG. And there are a lot of files!
--
You received this message because you are subscribed to a topic in the Google Groups "tesseract-ocr" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/tesseract-ocr/bZh3j_i8MYU/unsubscribe.
To unsubscribe from this group and all its topics, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/2434d564-f2b5-40df-b180-8465bc9c5c42n%40googlegroups.com.
Isidore Paris
Mar 16, 2023, 4:05:52 AM3/16/23
to tesseract-ocr
I don't know how big is your "lot of files"… So, sorry if this doesn't match:
I use IRFANVIEW (free software) to convert JPG either in PBM or in B&W
(2 COLORS) JPG, with the batch option (open an image and then press
letter B on keyboard) – but maybe you already know Irfanview…?
It converts very good and quite quickly. I just converted 224 files (jpg b&w 256 colors (greys)) in 40 seconds.
If you only have some hundreds of files, it could be a pretty solution… But if you have thousands or 10.000's, surely it could be heavy…
If you only have some hundreds of files, it could be a pretty solution… But if you have thousands or 10.000's, surely it could be heavy…
David R Anderson
Mar 16, 2023, 2:32:52 PM3/16/23
to tesser...@googlegroups.com
Thank you. Although, after thinking about it. I think that converting JPG to PBM in order to get full pixels may be compromising what I am trying to achieve.
The Tesseract doc Improving the quality of the output mentions “Willus Dotkom” (Under rescaling) with this link Optical Image Resolution This page (Optical Image Resolution) is about the pixel height of capital letters/numbers of source documents.
I need an accurate count (not adjusted because it's easier) The image I have included in this post shows my measuring 'ruler' on the right of the 14
I am looking for a rule or method that is an accepted scientific approach regarding the counting of pixels.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/5e6e70e8-b1ab-4b1d-8923-9f8f357210f2n%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages