Optimal image resolution (dpi/ppi) for Tesseract 4.0.0 and eng.traineddata?
46,451 views
Skip to first unread message

Willus Dotkom
Dec 28, 2018, 12:42:51 AM12/28/18
to tesseract-ocr
I've been trying some OCR of the attached PDF (I convert it to a bitmap at various dpi). I know the attached PDF file already has a text layer. I'm just seeing how Tesseract does on it. I'm using the Tesseract v4.0.0 released library code and the 22.4 MiB eng.traineddata file from the github site. I OCR the bitmap line by line--see an example of a bitmap that is passed to Tesseract at 400 dpi (ocrt_0004.png). I'm noticing that about 200 dpi seems optimum. If I go much above 200 dpi, for example, many of the lowercase i's get turned into 1's (see below). The attached PDF scales crisply to whatever resolution is desired since it is stored as text, not as a bitmap, so I'm a little surprised that a higher dpi setting can make things worse. Shouldn't Tesseract internally down-convert to a lower dpi if that's what it likes best? Can somebody explain why this might be happening?
Here's the conversion at 200 dpi:
"Worraworraworraworraworra," said Whatever-it-was, and Pooh
found that he wasn't asleep after all.
"What can it be?" he thought. "There are lots of noises in the For-
est, but this is a different one. It isn't a growl, and it isn't a purr, and it
isn't a bark, and it isn't the noise-you-make-before-beginning-a-piece-
of-poetry, but it's a noise of some kind, made by a strange animal.
And he's making it outside my door. So I shall get up and ask him not
to do it."
[...]
found that he wasn't asleep after all.
"What can it be?" he thought. "There are lots of noises in the For-
est, but this is a different one. It isn't a growl, and it isn't a purr, and it
isn't a bark, and it isn't the noise-you-make-before-beginning-a-piece-
of-poetry, but it's a noise of some kind, made by a strange animal.
And he's making it outside my door. So I shall get up and ask him not
to do it."
[...]
Here's the conversion at 400 dpi (highlights mine):
"Worraworraworraworraworra," said Whatever-it-was, and Pooh
found that he wasn't asleep after all.
"What can it be?" he thought. "There are lots of noises in the For-
est, but this 1s a different one. It 1sn't a growl, and it isn't a purr, and it
1sn't a bark, and it isn't the noise-you-make-before-beginning-a-piece-
of-poetry, but it's a noise of some kind, made by a strange animal.
And he's making it outside my door. So I shall get up and ask him not
to do 1t."
[...]
found that he wasn't asleep after all.
"What can it be?" he thought. "There are lots of noises in the For-
est, but this 1s a different one. It 1sn't a growl, and it isn't a purr, and it
1sn't a bark, and it isn't the noise-you-make-before-beginning-a-piece-
of-poetry, but it's a noise of some kind, made by a strange animal.
And he's making it outside my door. So I shall get up and ask him not
to do 1t."
[...]
Willus Dotkom
Dec 29, 2018, 1:26:49 PM12/29/18
to tesseract-ocr
So I've done a more extensive analysis of Tesseract v4.0.0 accuracy vs. text size / resolution.
1. I used the released Tesseract v4.0.0 library
2. I used the English language training file 22.4 MB in size from this folder
3. I created bitmaps for OCR-ing in six different fonts, at 6 pts, 12 pts, and 24 pts in size, each across a wide range of dpi. The six fonts are shown in the attachment.
4. I used the text from the Declaration of Independence--approximately 6600 letters.
5. Overall I OCR'd over 2 million English alphabet characters
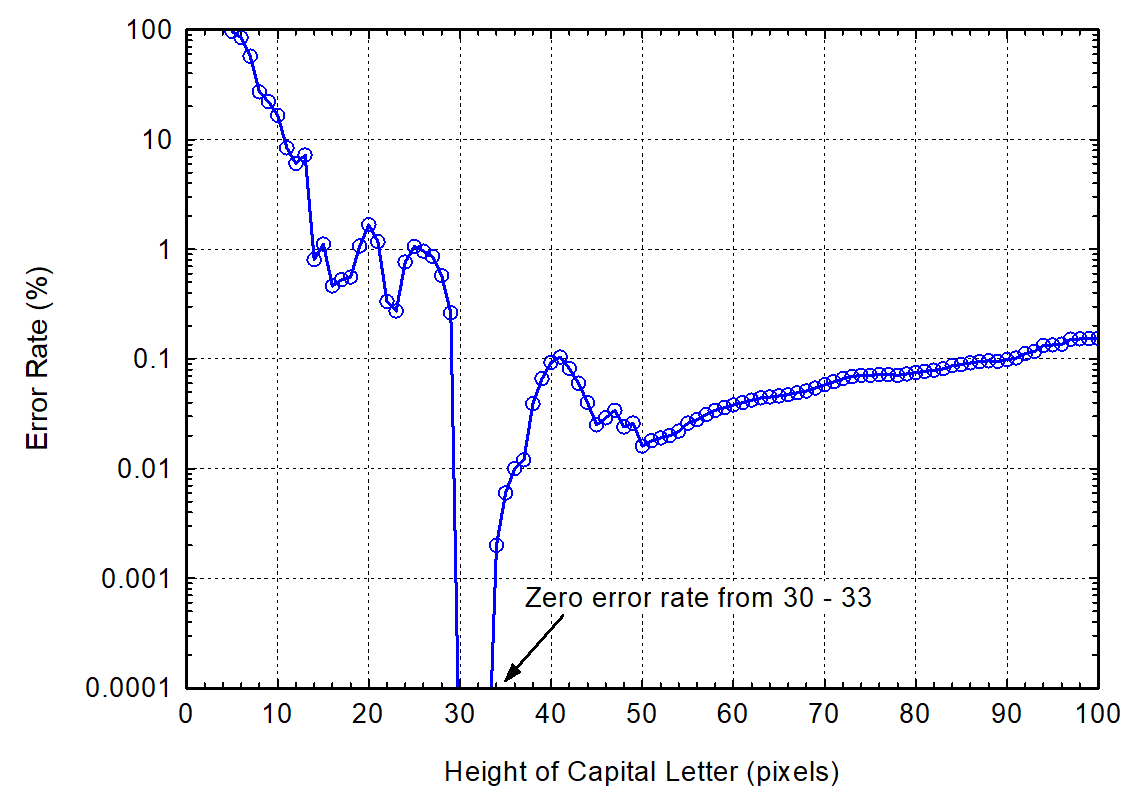
The OCR error rate was most strongly correlated to the height of a capital letter in pixels, regardless of dpi or point size. See plot below.
The most common errors when the letter height got too large were dependent on a particular font but included interpreting i as 1 (most common with serif fonts), f as t, confusing a semicolon with a colon, and interpreting a lower case letter as it's capital letter (e.g. i/I, s/S, o/O, k/K).
I have to say, the fact that there is an optimum letter size (in pixels) is quite unexpected. I would have expected that the higher the resolution of the letter (the more pixels), the lower the error rate would be. There is not a good reason I can think of to expect otherwise. If the OCR algorithm has an optimal letter size and it can down-sample to that size, then it should do that. I hope that future revisions of Tesseract will address this.
Next step: See if this also occurs on Tesseract v3.0.5 with Cube training data.
Here is the plot:
Willus Dotkom
Dec 29, 2018, 1:34:06 PM12/29/18
to tesseract-ocr
Whoops--sorry. For my more extensive analysis I used the 14.7 MB "best" English trained data file here.
Willus Dotkom
Dec 31, 2018, 5:23:39 PM12/31/18
to tesseract-ocr
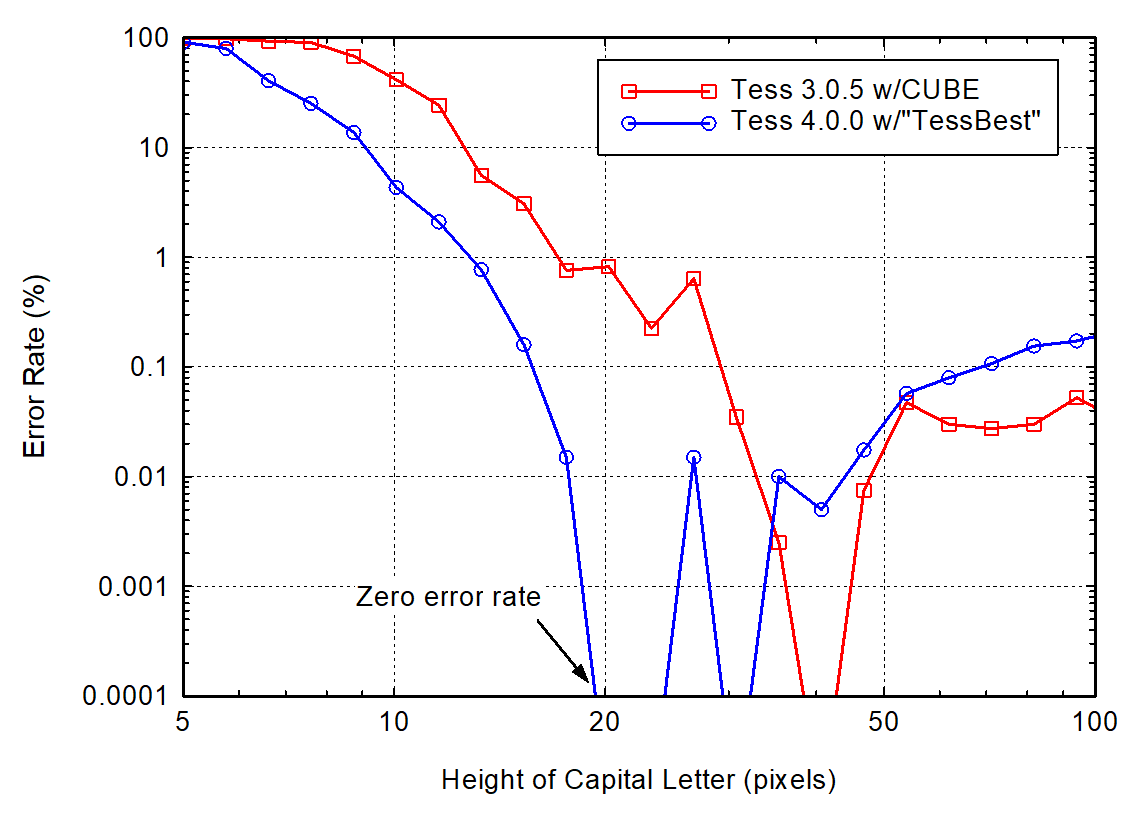
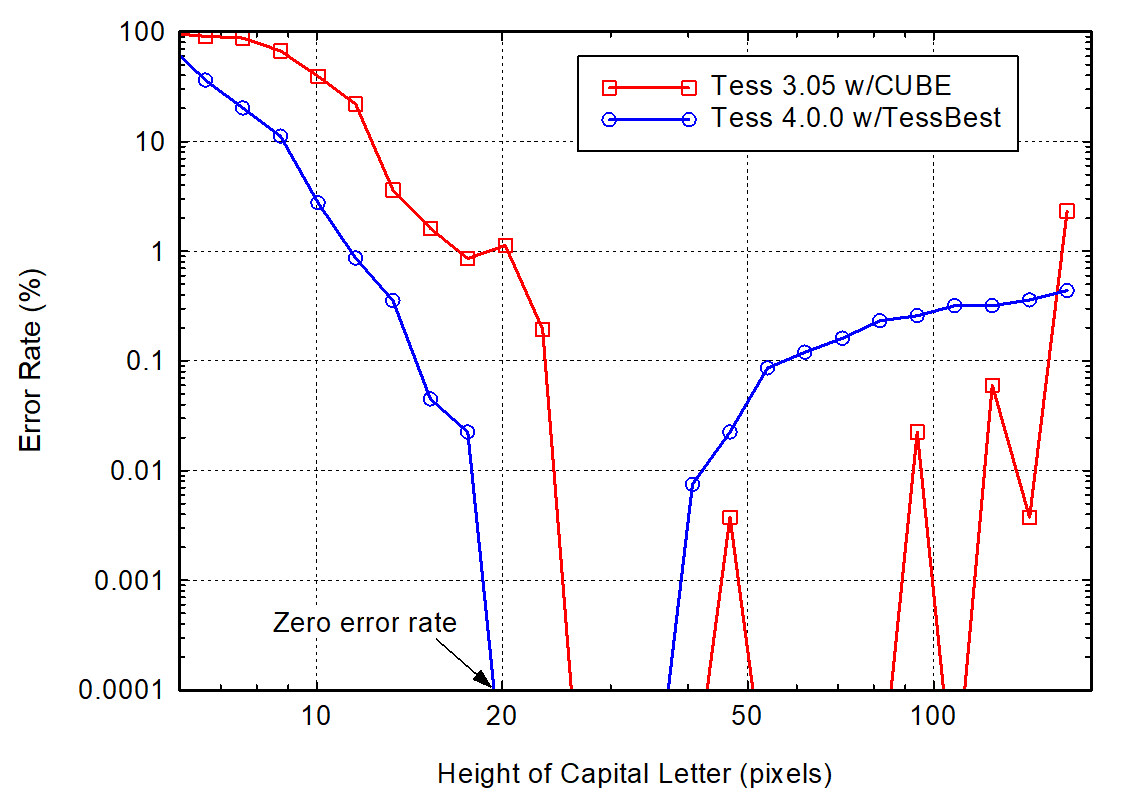
So I did some more experimenting and convinced myself that the "xres" and "yres" values in the PIX structure passed to Tesseract have virtually no impact to the results unless the resolution is so poor as to make the error rate very high. Using that information, I re-ran my tests in a more systematic way on both Tesseract 4 (with the "TessBest" English training data file--14.7 MiB) and Tesseract 3.05 (with CUBE). The results below show the average error rate for the six fonts and then excluding Bookman-Demi and Helvetica-Narrow since they're a little out of the ordinary. The error-rate is plotted against the height of a capital letter in pixels, as before. A couple of things to note:
1. Tess v4.0.0 does far better at the lower resolutions (fewer pixels in a capital letter).
2. Tess v4.0.0 is more consistent across a broader font selection than Tess v3.05. This is very good to see.
3. However, if I exclude Bookman-Demi and Helvetica-Narrow, Tess v3.05 does better for the higher resolutions (40-140 pixel heights). Tess v4.0.0 definitely has a consistent issue with high-res fonts which should be addressed, as I stated in my earlier posts.
6-font average:
Without Bookman-Demi and Helvetica-Narrow:

zdenop
Feb 27, 2022, 12:08:32 PM2/27/22
to tesseract-ocr
Hello Willus,
Can you also test tesseract 5? Can you share your input data for testing or script for evaluation, how you generate output charts?
Zdenko
Dátum: pondelok 31. decembra 2018, čas: 23:23:39 UTC+1, odosielateľ: wil...@gmail.com
wil...@gmail.com
Feb 21, 2023, 4:22:47 PM2/21/23
to tesseract-ocr
Sorry it took a while. Take a look here.
wil...@gmail.com
Feb 21, 2023, 4:24:50 PM2/21/23
to tesseract-ocr
...So v5 seems to have identical accuracy to v4. But it is faster. Here are some timing test benchmarks between v4 and v5.

{kind=link}
{kind=link}
Lorenzo Bolzani
Feb 22, 2023, 6:31:18 AM2/22/23
to tesser...@googlegroups.com
Looks like the "fast" models are better or on par with the "best" ones and more robust.
Or is there a difference in the 20-40 range that is not visibile from the chart at this resolution?
Thanks, Lorenzo
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/647bdd8a-28bc-4111-bb36-bc8560a78d18n%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages