Systemic Effects of Generation GC
1,287 views
Skip to first unread message

Michael Barker
Jan 30, 2013, 9:45:21 PM1/30/13
to mechanica...@googlegroups.com
Hi,
Firstly a caveat, this email will be "pub conversation" standard of
technical detail. These are largely half-formed thoughts that I
thought may be interesting as discussion point.
TL;DR
I've had a nagging thought in the back of my head for a while, which
jumps to the front every time I look at improving GC behaviour
(tuning, reducing allocation or reading/watching material on the
subject). The common wisdom is "the good die young" as collection of
the new generation is fairly cheap and promotion is expensive. I
assume everybody on this list has seen the bytes allocated vs bytes
surviving chart in the Oracle Hotspot tuning document
(http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html).
I'm not what the original source of this image is, but it is talked
about in context of Java 1.2, so I'm guessing it probably from
somewhere in the late-90s (so at least 10-15 years old).
So to me there seems to have been a process that started some time ago
(around 10 years, but probably earlier, I couldn't find any references
to the first generational GC implementations and I didn't look very
hard either) that goes something like:
1) Applications are observed to have a high proportion of short lived objects.
2) GC authors optimise for this case (e.g. generational GC), in many
cases sacrificing performance for the less common cases (mid and long
lived objects).
3) Developers optimise for best GC behaviour by ensure objects are short-lived.
4) GOTO #1
However, since my (not-quite arbitrary reference point) of the late
90s a couple of things have changed. Available memory has increased
1000-fold, e.g. my desktop has 32GB of ram compared to 32MB in the one
I had at uni. The demands of modern applications has increased
significantly, e.g. Facebook's 1B users, anything that turns up on
highscalability.com, increasing financial trading volumes
(http://imgur.com/DxWer).
These have lead toward more solutions needing to focus on holding and
keeping the (increasing large) working sets in memory. Examples
include financial exchanges and the success of caching tools like
Coherence, Terracotta and memcached. Where as 10 or so years ago
without the memory to support it we were pushing business entities
(that were still part of the working set) with life-cycles longer than
our young generation cycle time out to the database. So we are in a
situation where we have the memory to do what we need, but if we want
our implementation to be sympathetic to the GC we need to look for
locations for these entities that is not on the Java heap, with
off-heap memory being the soupe du jour. E.g. the Java cache tools
mentioned above both have support for off-heap memory, some of the
devs on this list have built whole services where the majority of the
working set is off-heap and right now I'm implementing a solution for
moving our large data buffers used for messaging off-heap.
So my question is, is generation GC holding developers back? Is the
self-reinforcing advice of keeping objects short lived pushing against
the desire to keep objects in memory for their true (business
requirement defined) life-cycle?
Sorry about weak assumptions and half-formed ideas; any thoughts, or
am I miles off base?
Mike.
Firstly a caveat, this email will be "pub conversation" standard of
technical detail. These are largely half-formed thoughts that I
thought may be interesting as discussion point.
TL;DR
I've had a nagging thought in the back of my head for a while, which
jumps to the front every time I look at improving GC behaviour
(tuning, reducing allocation or reading/watching material on the
subject). The common wisdom is "the good die young" as collection of
the new generation is fairly cheap and promotion is expensive. I
assume everybody on this list has seen the bytes allocated vs bytes
surviving chart in the Oracle Hotspot tuning document
(http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html).
I'm not what the original source of this image is, but it is talked
about in context of Java 1.2, so I'm guessing it probably from
somewhere in the late-90s (so at least 10-15 years old).
So to me there seems to have been a process that started some time ago
(around 10 years, but probably earlier, I couldn't find any references
to the first generational GC implementations and I didn't look very
hard either) that goes something like:
1) Applications are observed to have a high proportion of short lived objects.
2) GC authors optimise for this case (e.g. generational GC), in many
cases sacrificing performance for the less common cases (mid and long
lived objects).
3) Developers optimise for best GC behaviour by ensure objects are short-lived.
4) GOTO #1
However, since my (not-quite arbitrary reference point) of the late
90s a couple of things have changed. Available memory has increased
1000-fold, e.g. my desktop has 32GB of ram compared to 32MB in the one
I had at uni. The demands of modern applications has increased
significantly, e.g. Facebook's 1B users, anything that turns up on
highscalability.com, increasing financial trading volumes
(http://imgur.com/DxWer).
These have lead toward more solutions needing to focus on holding and
keeping the (increasing large) working sets in memory. Examples
include financial exchanges and the success of caching tools like
Coherence, Terracotta and memcached. Where as 10 or so years ago
without the memory to support it we were pushing business entities
(that were still part of the working set) with life-cycles longer than
our young generation cycle time out to the database. So we are in a
situation where we have the memory to do what we need, but if we want
our implementation to be sympathetic to the GC we need to look for
locations for these entities that is not on the Java heap, with
off-heap memory being the soupe du jour. E.g. the Java cache tools
mentioned above both have support for off-heap memory, some of the
devs on this list have built whole services where the majority of the
working set is off-heap and right now I'm implementing a solution for
moving our large data buffers used for messaging off-heap.
So my question is, is generation GC holding developers back? Is the
self-reinforcing advice of keeping objects short lived pushing against
the desire to keep objects in memory for their true (business
requirement defined) life-cycle?
Sorry about weak assumptions and half-formed ideas; any thoughts, or
am I miles off base?
Mike.

Gil Tene
Jan 31, 2013, 2:06:06 AM1/31/13
to
The currently common form of generational GC, which typically apply a monolithic copying collectors for the youngest generation, and are supported purely by a store barrier (no barrier needed on load instructions) is generally tracked back to David Ungar's 1984 paper titled "Generation Scavenging: A non-disruptive high per- formance storage reclamation algorithm". AFAIK the real generational thing started with Lieberman & Hewitt's 1983 paper titled "A real-time garbage collector based on the lifetimes of objects" - that one was incremental (interleaves with program execution) and required barriers on load instructions.
So the observation that using age to focus collection effort on young objects pays off is now about 30 years old.

Peter Lawrey
Jan 31, 2013, 2:43:52 AM1/31/13
to mechanica...@googlegroups.com
For the application I have worked on lately, the use of the limited last L2/L3 cache is critical for multi-threaded performance. This cache is shared by all CPUs and is the "gateway" to accessing main memory.
The problem I have with creating lots of short lived objects is this results in the caches constantly "scrolling" reducing the effectiveness of this precious and shared resource. While GC of short lived objects may be cheap, it is not entirely free and there is still a significant gain in ensuring your caches work effectively esp if you want to use more than one CPU at once. From what I have seen the L2/L3 cache works well for one thread no matter what you do and simple micro-benchmarks don't show this as an issue, but if you want to scale your performance with more CPU usage you want to use minimise use of shared caches and make sure it pretty stable i.e. not constantly being flushed. :j
On 31 January 2013 07:05, Gil Tene <g...@azulsystems.com> wrote:
The currently common form of generational GC, which typically apply a monolithic copying collectors for the youngest generation, and are supported purely by a store barrier (no barrier needed on load instructions) is generally tracked back to David Ungar's 1984 paper titled "Generation Scavenging: A non-disruptive high per- formance storage reclamation algorithm". AFAIK the real generational thing started with Lieberman & Hewitt's 1983 paper titled "A real-time garbage collector based on the lifetimes of objects" - that one was incremental (interleaves with program execution) and required barriers on load instructions.So the observation that using age to focus collection effort on young objects pays off is now about 30 years old.
On Wednesday, January 30, 2013 6:45:21 PM UTC-8, mikeb01 wrote:
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.
Gil Tene
Jan 31, 2013, 2:46:56 AM1/31/13
to mechanica...@googlegroups.com
Generational GC gives us all multiple benefits:
On Wednesday, January 30, 2013 6:45:21 PM UTC-8, mikeb01 wrote:
1. It is VERY efficient.
This starts by focusing on recently allocated heap areas, and by leveraging the nearly universal observation that most allocated objects die soon after the are allocated. It combines this with the use of an algorithm that is linear in work to the live set (as opposed to being linear to the size of the heap area being collected). This leads to extreme efficiency for the young generation collection as long as the sparseness property holds. These algorithms (e.g. a copy collector, or a mark/compact) are usually not much less efficient than other forms of collection even when things are not so sparse (but non-sparse is definitely much less efficient than sparse).
2. It typically has shorter pauses in the "common case" [for collectors that pause]
In pausing collectors, young generation collections are typically much shorter in length than oldgen collections. This means shorter pauses on the average. This "on average" behavior can be sensitive though, and has some tradeoffs - if you use large newgen sizes to get high efficiency, you run the risk of an occasional non-sparse situation (e.g. during a data-load phase, or on some program phase changes) that could result in a long pause due to massive copying and promotion work on a temporarily non-sparse newgen.
3. It typically reduces the frequency of oldgen collection [and their pauses if they have those]
I find that people often confuse the three things above.
#1 still holds for pretty much all practical workloads. The simple reason for that is that there is a prevalence of temporary objects in common compute workloads. The strange thing [to me] is that people often labour under the mis-conception that reducing allocation rate helps efficiency in some way. The reality is that reducing allocation rates reduces GC frequency, but does not improve efficiency. The efficiency of individual GC cycles actually becomes worse when allocation is reduced (since the allocation being eliminated would have cost nothing to collect). This drop is efficiency within a GC cycle is offset by related drop in GC frequency - resulting in the actual GC work staying roughly the same.
#2 and #3 matter [only] when collectors use algorithms that pause during copying, or during compaction. At Azul we don't have to worry about #2 and #3, but we still use generational collection purely for the #1 reason above. It's worth 10-20x in efficiency, which translates into high sustainable allocation rates.
On Wednesday, January 30, 2013 6:45:21 PM UTC-8, mikeb01 wrote:
Gil Tene
Jan 31, 2013, 2:48:39 AM1/31/13
to mechanica...@googlegroups.com
As to the "advice to keep objects short lived" part of your discussion-provoking topic, and the need to move things off the heap if they are expected to live long, those are not consequences of generational collection. They are a consequence of pausing oldgen collectors. Generational collection is a great filter, but a newgen is only a partial filter. Unless all your state is short-lived, the newgen won't take it all away. And if it *is* all short-lived, you don't really have any use for those temping cheap GBs on your server.
In real-world situations where long-lived state is useful (caches, in-memory graphs and databases, long-lived session state, etc.), that state will drive you to one of the following options [or combinations thereof]:
1) live on the heap and be dealt with by try-hard-not-to-make-a-big-pause-happen-to-often collectors, accepting the occasional (and hopefully rare) huge and annoying oldgen pause
2) Split your nice fat many-GB computer into many small processes with heaps small enough to have "acceptable pause times" per process. Find ways to stripe and distribute your work across those pieces.
3) Move off heap. Accepting cost both in inefficiency (moving to/from object form) and in loss of the benefits of "being an object" [there no such things as object references in off-heap storage, and therefore no such thing as first class objects]. This often works well for simple, flat data structures (e.g. key/value stores, or simple caches), but when you "try too hard" to put general state in this "off heap" thing. You usually find that you are building a new type of heap, with it's own malloc/free (or it's own refcounting, or some other form of crude GC), and with all the complexities and bugs that comes with that. E.g. try thinking of a good way holding a hashtable of linked lists of directional graphs in an off heap data structure...
4) Use a robustly non-pausing collector...
I find that while people usually start using our Zing JVM to eliminate some sort of big bad pause problem, the most common comments I hear from developers who've used Zing for more than a few weeks relates to the amount of duct-tape-enginerering they no longer have to do... No more "keep allocation rates down". No more "keep objects young". No more "avoid large state". No more "avoid circular data structures and references so we can flatten this stuff".
POJOs win. Again.
On Wednesday, January 30, 2013 6:45:21 PM UTC-8, mikeb01 wrote:
...

Kirk Pepperdine
Jan 31, 2013, 3:24:14 AM1/31/13
to Michael Barker, mechanica...@googlegroups.com
Hi Michael,
Interesting thoughts. My experience with graphing object life spans suggests that the nature of the curve has not changed. This curve can be traced back to Smalltalk. From my view point, Java completely ignored the work done in Smalltalk. That trend ended as it was the Smalltalk people with more OO maturity that were out-competing others in the migration to Java. The first visible parts of the migration can be seen in the influences of Smalltalk in the collection classes. I can't say for sure what the Smalltalk influence was on GC in Sun but I do know that the same people who wrote VisualAge Smalltalk for IBM were the same people who wrote the VM for IBM's initial versions of Java. Dave Thomas (Smalltalk Dave, not Pargmatic Dave) was influential in the designs and he has a firm view that single space heap arrangements properly done should out perform multi-space implementations. This view survived all the way up to the 1.4..2. IBMs 1.5 finally embraces generational spaces. Sun started on generational spaces as part of the integration of HotSpot. The tie into Smalltalk was; ParcPlace had 7 different memory pools that included a nursery, two hemi spaces and an old space (I forget exactly what they called it). The GNU engine, which I did some modifications to, simply employed hemi spaces with a partial/incremental collection scheme that involved every allocation scanning 5 references from the inactive from space (yeah crude I know).
Anyways, the idea of how to better partition data are based on the same observations that pre-date Java. Another point, most developers don't live in your bubble and consequently don't think of the effects of GC when they are writing their code. So, IMHO, the observation is still valid. That said, conditions on the ground have changed quite considerably since Smalltalk's heydays. As you've pointed out we have larger datasets and memory and as you know, we have far more cores available to us.
IMHO, one of the most understated effects due to GC these days is safe-pointing. I've found that especially in latency sensitive applications that the Oracle JVM simply safe-points far too often inflicting all of the disruptive effects that come with that activity. Unfortunately it's not only GC activity that triggers safe-pointing but that leads in a different direction.
Back to GC, as you've mentioned generational spaces change the cost model to the one that favours short lived objects. It does this by setting up a scheme where it deals with live objects cheaply and ignores long lived objects about as well as it can. Problem is, with the larger and larger datasets you run into one of the other limiting costs, scan for roots. Object-life cycle cost is a function of the number of collections objects survive. The cost of any collection is now a function of a number of factors but is primarily dominated by (in no particular order) the number of threads, size of space (or spaces, ie total heap size), and the number of surviving objects. As heap size grows and working sets grow, the scan for roots costs start to limit the scalability of generational spaces. My hope was that the G1 would cure this scalability issue but I fear that it's carried over too much baggage from the generational implementations to be of much use. I was hoping that the G1 would be much better than it appears to be at ignoring the long lived stable portion of your working set.
The other issue is what I consider to be poor use of processors. We've got tons of cores, there is work that could be done all the time to reduce the effects of those instances when you need exclusive access to heap data structures. IOWs collectors should be working all the time IMHO. This is one reason why iCMS is a lot more popular than Oracle engineering believes. When a couple of us spoke out against deprecating iCMS they were surprised but they still deprecated it anyways. A move that should make Gil happy ;-).
Maybe Gil can comment on the C4's MMU vs G1 and CMS's MMU numbers.
Anyways, I could say a lot more but.. 'nuff for now.
-- Kirk
Interesting thoughts. My experience with graphing object life spans suggests that the nature of the curve has not changed. This curve can be traced back to Smalltalk. From my view point, Java completely ignored the work done in Smalltalk. That trend ended as it was the Smalltalk people with more OO maturity that were out-competing others in the migration to Java. The first visible parts of the migration can be seen in the influences of Smalltalk in the collection classes. I can't say for sure what the Smalltalk influence was on GC in Sun but I do know that the same people who wrote VisualAge Smalltalk for IBM were the same people who wrote the VM for IBM's initial versions of Java. Dave Thomas (Smalltalk Dave, not Pargmatic Dave) was influential in the designs and he has a firm view that single space heap arrangements properly done should out perform multi-space implementations. This view survived all the way up to the 1.4..2. IBMs 1.5 finally embraces generational spaces. Sun started on generational spaces as part of the integration of HotSpot. The tie into Smalltalk was; ParcPlace had 7 different memory pools that included a nursery, two hemi spaces and an old space (I forget exactly what they called it). The GNU engine, which I did some modifications to, simply employed hemi spaces with a partial/incremental collection scheme that involved every allocation scanning 5 references from the inactive from space (yeah crude I know).
Anyways, the idea of how to better partition data are based on the same observations that pre-date Java. Another point, most developers don't live in your bubble and consequently don't think of the effects of GC when they are writing their code. So, IMHO, the observation is still valid. That said, conditions on the ground have changed quite considerably since Smalltalk's heydays. As you've pointed out we have larger datasets and memory and as you know, we have far more cores available to us.
IMHO, one of the most understated effects due to GC these days is safe-pointing. I've found that especially in latency sensitive applications that the Oracle JVM simply safe-points far too often inflicting all of the disruptive effects that come with that activity. Unfortunately it's not only GC activity that triggers safe-pointing but that leads in a different direction.
Back to GC, as you've mentioned generational spaces change the cost model to the one that favours short lived objects. It does this by setting up a scheme where it deals with live objects cheaply and ignores long lived objects about as well as it can. Problem is, with the larger and larger datasets you run into one of the other limiting costs, scan for roots. Object-life cycle cost is a function of the number of collections objects survive. The cost of any collection is now a function of a number of factors but is primarily dominated by (in no particular order) the number of threads, size of space (or spaces, ie total heap size), and the number of surviving objects. As heap size grows and working sets grow, the scan for roots costs start to limit the scalability of generational spaces. My hope was that the G1 would cure this scalability issue but I fear that it's carried over too much baggage from the generational implementations to be of much use. I was hoping that the G1 would be much better than it appears to be at ignoring the long lived stable portion of your working set.
The other issue is what I consider to be poor use of processors. We've got tons of cores, there is work that could be done all the time to reduce the effects of those instances when you need exclusive access to heap data structures. IOWs collectors should be working all the time IMHO. This is one reason why iCMS is a lot more popular than Oracle engineering believes. When a couple of us spoke out against deprecating iCMS they were surprised but they still deprecated it anyways. A move that should make Gil happy ;-).
Maybe Gil can comment on the C4's MMU vs G1 and CMS's MMU numbers.
Anyways, I could say a lot more but.. 'nuff for now.
-- Kirk
Kirk Pepperdine
Jan 31, 2013, 3:40:19 AM1/31/13
to Gil Tene, mechanica...@googlegroups.com
On 2013-01-31, at 8:46 AM, Gil Tene <g...@azulsystems.com> wrote:
> Generational GC gives us all multiple benefits:
>
> 1. It is VERY efficient.
>
> This starts by focusing on recently allocated heap areas, and by leveraging the nearly universal observation that most allocated objects die soon after the are allocated. It combines this with the use of an algorithm that is linear in work to the live set (as opposed to being linear to the size of the heap area being collected). This leads to extreme efficiency for the young generation collection as long as the sparseness property holds. These algorithms (e.g. a copy collector, or a mark/compact) are usually not much less efficient than other forms of collection even when things are not so sparse (but non-sparse is definitely much less efficient than sparse).
>
> 2. It typically has shorter pauses in the "common case" [for collectors that pause]
>
> In pausing collectors, young generation collections are typically much shorter in length than oldgen collections. This means shorter pauses on the average. This "on average" behavior can be sensitive though, and has some tradeoffs - if you use large newgen sizes to get high efficiency, you run the risk of an occasional non-sparse situation (e.g. during a data-load phase, or on some program phase changes) that could result in a long pause due to massive copying and promotion work on a temporarily non-sparse newgen.
>
> 3. It typically reduces the frequency of oldgen collection [and their pauses if they have those]
>
> I find that people often confuse the three things above.
>
> #1 still holds for pretty much all practical workloads. The simple reason for that is that there is a prevalence of temporary objects in common compute workloads. The strange thing [to me] is that people often labour under the mis-conception that reducing allocation rate helps efficiency in some way. The reality is that reducing allocation rates reduces GC frequency, but does not improve efficiency. The efficiency of individual GC cycles actually becomes worse when allocation is reduced (since the allocation being eliminated would have cost nothing to collect). This drop is efficiency within a GC cycle is offset by related drop in GC frequency - resulting in the actual GC work staying roughly the same.
-- Kirk

jamie...@typesafe.com
Jan 31, 2013, 12:58:55 PM1/31/13
to
Kirk - Nice writeup. Interesting to see that David Ungar's most recent work has been with a subset of Smalltalk-80. The manycore RoarVM they've built for it (http://soft.vub.ac.be/~smarr/renaissance/), is using Cliff Click's pauseless generational GC algorithm (from Gil and Azul's C4).
Gil Tene
Jan 31, 2013, 7:03:58 PM1/31/13
to mechanica...@googlegroups.com
On Thursday, January 31, 2013 9:58:19 AM UTC-8, jamie...@typesafe.com wrote:
Kirk - Nice writeup. Interesting to see that David Ungar's most recent work has been with a subset of Smalltalk-80. The manycore RoarVM they've built for it (http://soft.vub.ac.be/~smarr/renaissance/), is using Cliff Click's pauseless generational GC algorithm (from Gil and Azul's C4).
Ahem... It's actually Gil and Michael (Wolf)'s Pauseless GC and generational Pauseless GC (C4) algorithms... With key contributions from Cliff Click and Balaji Iyengar...
-- Gil.
Kirk Pepperdine
Feb 1, 2013, 1:02:00 AM2/1/13
to Gil Tene, mechanica...@googlegroups.com
Hi Gil,
On Thursday, January 31, 2013 9:58:19 AM UTC-8, jamie...@typesafe.com wrote:Kirk - Nice writeup. Interesting to see that David Ungar's most recent work has been with a subset of Smalltalk-80. The manycore RoarVM they've built for it (http://soft.vub.ac.be/~smarr/renaissance/), is using Cliff Click's pauseless generational GC algorithm (from Gil and Azul's C4).Ahem... It's actually Gil and Michael (Wolf)'s Pauseless GC and generational Pauseless GC (C4) algorithms... With key contributions from Cliff Click and Balaji Iyengar...
No, he got it right..... ;-)
I've been thinking more about the weak generational hypothesis and that long ago pub'ed graph. Though I'm sure the shape of the curve hasn't changed much I'm wondering about magnitudes. I've got tons of GC logs but they all exhibit some pathological condition so I don't have a good basis for maybe redrawing this map.. but I'm wondering if we could expand my send me your GC log campaign to see if we can redraw that chart with current data?
-- Kirk

Martin Thompson
Feb 1, 2013, 1:44:47 AM2/1/13
to mechanica...@googlegroups.com, Gil Tene
I think this is a good idea.
Over the years I've seen server application evolve from pretty much stateless request-response systems feeding web pages, to having complex in-memory models with object lifetimes that match the business domain. A lot of the Java gymnastics seems to be because these rich models so hurt current GC implementations, Gil's excluded ;-), that we are using in-memory KV stores, object pooling, and going off-heap as a work arounds.
Martin...
Gil Tene
Feb 1, 2013, 3:21:28 AM2/1/13
to mechanica...@googlegroups.com, Gil Tene
I agree that it would be interesting redraw the graph based on more current profiles, by collecting data to from real world apps (not from benchmarks - they are the worst possible source).
Yes. You can get some small amount of information from the optional age distribution reporting avialable in GC logging, but that data is only about the stuff that survives at least one newgen collection. Unless the newgen is dramatically undersized and thrashing, that's a tiny percentage of the overall allocation, and you'd have no information about behavior and lifetime profile within a single newgen collection. As a simple example, there is no visibility or information at all into the lifetime and frequency of temporary (die within a frame or two) objects.
It would be fairly straightforward to hack a JVM like OpenJDK into a GC-alot mode, where both newgen and oldgen collections run almost back to back STW cycles, giving the application a millisecond here and there to run between complete GC cycles, and to collect fairly accurate object lifetime distribution information with that technique. I'm not sure how we could entice people to actually run in that mode to give us useful data, since it would be a badly trashing mode...
Kirk Pepperdine
Feb 1, 2013, 3:28:38 AM2/1/13
to Martin Thompson, mechanica...@googlegroups.com
Hi Martijn,
I guess this is where our experiences might have come down different routes. I worked for GemStone for a number of years. GemStone morphed into a caching solution once the OODB market failed to mature but prior to that we were working with a large number of applications both in Smalltalk and Java that were very stateful. In a sense these applications *were* pushing data into an off-heap space but since GemStone had access to the underlying reference system they could maintain the singularity guarantee that no one else has been able to replicate. Thus all existing models rely on some form of foreign key relationships to rebuild the notion of singularity. That aside, from an application point of view persistence was completely orthogonal, just connect your object to a persistent root, call commit and that object would be "GC'ed" into the persistent space. In Smalltalk there was no difference between the persistent space and the regular (volatile) heap. In Java object needed to be copied from persistent pages into (volatile) heap and then copied back so from a system perspective it wasn't as nice. That said, developers never saw a difference with the exception of having to deal with the badly overloaded definition of the transient keyword. Winding back to weak gen hypothesis... the smalltalk apps we started with expressed it, the apps we eventually connected to the persistent store expressed it and every GC log that I have including recent ones expresses it unless there is an underlying pathology that is interfering. That said, the data from existing GC logs only tells you what's happening up to the time data has been tenured. After that all you know is what the working set size is. There is some instrumentation that you could cook up using phantom references that could be used to calculate an age distribution but I fear that this would place a horrible burden on memory management, both at point of allocation and collection. I'm not sure that there is any support for this in the JVMTI as if there was the profilers would take advantage of it.The only other thing I can think of that would have less of an impact would be to juice up a version of the JVM (OpenJDK) to include aging information in the header.
Regards,
Kirk
Kirk Pepperdine
Feb 1, 2013, 5:45:38 AM2/1/13
to Gil Tene, mechanica...@googlegroups.com
Ah, I should have read this before writing my previous email. I'd use some statistical sampling to try to draw down on the drag. You don't need to capture everything.. just a large enough sample size to be significant.
Martin Thompson
Feb 1, 2013, 3:53:27 PM2/1/13
to mechanica...@googlegroups.com, Martin Thompson
On the my name spelling I think you are confusing me with a Dutch Kiwi you know well :-)
I seen similar systems to what you described in the early 90s but with ObjectStore rather than Gemstone. These were all much more fat client apps written in C++ focused on things like CAD and vehicle modelling/configuration. I spent a lot of that time replacing SmallTalk apps that did not perform with C++ or Java Apps for finance. Then the web came along and things went much more request response and Java exploded on the server side due to Servlets performing much better than CGI implementations at the time. The DB backed EJB/Spring/.Net gang of technologies were all very stateless otherwise they did not scale so, other than session state, little object retention existed in the managed runtimes. In the high transaction volume domains - like finance, gaming, and gambling - DB backed systems struggle to scale and complex domain models are going in-memory and are often materialising as event sourced systems. These types of systems having a real domain model, free from the crap that comes with an ORM, can be a joy to work with but you get badly bitten by the GC. Mike Barker and I have worked on some of these systems together so I can totally understand his issues.
A simple approach to get a feel for object lifetimes would be to sample an application with some bytecode weaving in a similar way to how JXInsight does metering. That is, instrument everything then back-off and only sample what is relevant at an appropriate level. If you back-off before Hotspot kicks in then the dead instrumentation code can be removed. This would likely be more acceptable to folk than a hacked version of OpenJDK.
Martin...
Martin...
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsub...@googlegroups.com.
Gil Tene
Feb 2, 2013, 2:44:03 AM2/2/13
to mechanica...@googlegroups.com, Gil Tene
I'm not saying it's impossible to get good data for this from statistical sampling. There may be some clever way around the below, but it's going to be very very tricky. Whenever I've tried this before (get a good feel for lifetime distribution for non-long-lived-obejcts), it basically comes down to this:
The challenge with statistical lifetime sampling (e.g. sample only at natural GC frequency without making GC happen virtually all the time) is that you have no knowledge about when an object died within a GC cycle, only that it is dead (or alive) at the end of a cycle. This can give you data on the distribution of objects that survive at least one GC cycle, which we already know have a different behavior that the vast majority of allocations... Most object do die very young, and that would mean that they die without a single lifetime information sample, and before the GC cycle could determine if they are alive or dead. Using only the sample from live-at-end-of-cycle objects would completely skew your data.
Without an actual GC cycle, there is no way to tell if an object is still alive or dead. This includes hacked JVMs as well as BCI stuff, JVMTI stuff, and weak or phantom ref based stuff. All of these would only get their information and actions from what a GC cycle figures out, and have nothing to act on without a trace in a mark phase (or a copy phase in the case of most newgens).
So lifetime profiling of long-lived objects is fairly straight forward, but that doesn't even take a statistical sampler. Lifetime profiling of short lived (which are dominantly collected by newgen) objects is hard, unless you make newgen happen so frequently that virtually nothing gets collected in the first scan (read: unless you completely thrash your system).
-- Gil.
Martin Thompson
Feb 2, 2013, 3:26:34 AM2/2/13
to mechanica...@googlegroups.com, Gil Tene
I might be being dumb here but does it matter if objects live less than a GC cycle? We want to track the ones that live longer and for how many new generation cycles to give an idea of what gets promoted and the lifetime we should expect.
From a GC algorithm perspective it seems the right thing to have generational GC. The issues come from the fact that the young generation collection is not concurrent in modern large memory systems combined with issue of copying objects multiple times between survivor spaces as they age rather than straight promotion and have a compacting concurrent collector on the old generation. I think the generational issue is a red herring and more a case of how we better do GC concurrently.
Kirk Pepperdine
Feb 2, 2013, 4:22:22 AM2/2/13
to Martin Thompson, mechanica...@googlegroups.com, Gil Tene
On 2013-02-02, at 9:26 AM, Martin Thompson <mjp...@gmail.com> wrote:
I might be being dumb here but does it matter if objects live less than a GC cycle? We want to track the ones that live longer and for how many new generation cycles to give an idea of what gets promoted and the lifetime we should expect.
Ok, stupid question but how long is it between GC cycles?
As to Gil's points, he's right if you rely on GC to let you know when an object has died. And nothing we've suggested gets around that as all that instrumentation is only triggered by a GC cycle. That said, we can get good measures byte allocation rates and at a GC we can see how much is remaining. So if we partition the problem into what happens at the beginning and what happens later on I think a solution is reachable. The beginning we already understand. That is pretty clear in just about every GC log that I see. Another point, if we rely on the collector to trigger the measure then the resolution of that measure will be a function of GC frequency. I'm going to throw this one out, does it matter after a long enough period of time if the resolution is GC interval time?
From a GC algorithm perspective it seems the right thing to have generational GC. The issues come from the fact that the young generation collection is not concurrent in modern large memory systems combined with issue of copying objects multiple times between survivor spaces as they age rather than straight promotion and have a compacting concurrent collector on the old generation. I think the generational issue is a red herring and more a case of how we better do GC concurrently.
The problem is that GC algorithms were written on the premise that CPU is limited. While one can argue if that still holds today the point is most apps I see are not even capable of consuming more than 10% of the CPU available to them. Under those conditions one has to ask why are the collectors not running all the time? If they were running all the time. Another point is that generational collectors are good at ignoring dead objects in the nursery. They are terrible at ignoring medium and long lived objects. I was hoping the G1 would be better at ignoring long lived data by packing it up into regions that would be rarely visited by the collectors but this has proven to not be the case.. which is good for Gil ;-) This means that application's memory usage patterns is falling into Gil's sweet spot!
-- Kirk
On Saturday, February 2, 2013 7:44:03 AM UTC, Gil Tene wrote:I'm not saying it's impossible to get good data for this from statistical sampling. There may be some clever way around the below, but it's going to be very very tricky. Whenever I've tried this before (get a good feel for lifetime distribution for non-long-lived-obejcts), it basically comes down to this:The challenge with statistical lifetime sampling (e.g. sample only at natural GC frequency without making GC happen virtually all the time) is that you have no knowledge about when an object died within a GC cycle, only that it is dead (or alive) at the end of a cycle. This can give you data on the distribution of objects that survive at least one GC cycle, which we already know have a different behavior that the vast majority of allocations... Most object do die very young, and that would mean that they die without a single lifetime information sample, and before the GC cycle could determine if they are alive or dead. Using only the sample from live-at-end-of-cycle objects would completely skew your data.Without an actual GC cycle, there is no way to tell if an object is still alive or dead. This includes hacked JVMs as well as BCI stuff, JVMTI stuff, and weak or phantom ref based stuff. All of these would only get their information and actions from what a GC cycle figures out, and have nothing to act on without a trace in a mark phase (or a copy phase in the case of most newgens).So lifetime profiling of long-lived objects is fairly straight forward, but that doesn't even take a statistical sampler. Lifetime profiling of short lived (which are dominantly collected by newgen) objects is hard, unless you make newgen happen so frequently that virtually nothing gets collected in the first scan (read: unless you completely thrash your system).-- Gil.
On Friday, February 1, 2013 2:45:38 AM UTC-8, Kirk Pepperdine wrote:Ah, I should have read this before writing my previous email. I'd use some statistical sampling to try to draw down on the drag. You don't need to capture everything.. just a large enough sample size to be significant.On 2013-02-01, at 9:21 AM, Gil Tene <g...@azulsystems.com> wrote:I agree that it would be interesting redraw the graph based on more current profiles, by collecting data to from real world apps (not from benchmarks - they are the worst possible source).Unfortunately, GC logs for actual runs don't really have the data needed to draw the graph. In fact, having the data would in itself contradict the main cause for generational GC efficiency: the fact that newgen collections do not visit or collect any information about dead objects. If they did, their complexity would jump from being linear to the surviving live set to being linear to the newgen heap size, at which point they would be no more efficient than a full gc [they'd still provide a form of incremental GC, with more frequent but smaller pauses than a full GC, but they will spend even more CPU per allocated volume for doing this than a full gc would].Yes. You can get some small amount of information from the optional age distribution reporting avialable in GC logging, but that data is only about the stuff that survives at least one newgen collection. Unless the newgen is dramatically undersized and thrashing, that's a tiny percentage of the overall allocation, and you'd have no information about behavior and lifetime profile within a single newgen collection. As a simple example, there is no visibility or information at all into the lifetime and frequency of temporary (die within a frame or two) objects.It would be fairly straightforward to hack a JVM like OpenJDK into a GC-alot mode, where both newgen and oldgen collections run almost back to back STW cycles, giving the application a millisecond here and there to run between complete GC cycles, and to collect fairly accurate object lifetime distribution information with that technique. I'm not sure how we could entice people to actually run in that mode to give us useful data, since it would be a badly trashing mode...
On Thursday, January 31, 2013 10:02:00 PM UTC-8, Kirk Pepperdine wrote:I've been thinking more about the weak generational hypothesis and that long ago pub'ed graph. Though I'm sure the shape of the curve hasn't changed much I'm wondering about magnitudes. I've got tons of GC logs but they all exhibit some pathological condition so I don't have a good basis for maybe redrawing this map.. but I'm wondering if we could expand my send me your GC log campaign to see if we can redraw that chart with current data?
Martin Thompson
Feb 2, 2013, 5:38:32 AM2/2/13
to
On Saturday, February 2, 2013 9:22:22 AM UTC, Kirk Pepperdine wrote:
On 2013-02-02, at 9:26 AM, Martin Thompson <mjp...@gmail.com> wrote:I might be being dumb here but does it matter if objects live less than a GC cycle? We want to track the ones that live longer and for how many new generation cycles to give an idea of what gets promoted and the lifetime we should expect.Ok, stupid question but how long is it between GC cycles?
I get that in a perfect world we would really know all object life cycles. However I'm thinking that given the constraints, does it really matter when before a new gen GC cycle an object dies. If the new gen is sized to reasonable level for bytes collected, we could then dig in further to see what actual objects are getting promoted as this is likely to be related to the domain model.
For me the bytes allocated and collected is too blunt a tool to understand the actual model and for that we need objects by type. The actual types lets us better tune an application rather than guessing then experimenting to see if we can improve things.
The one significant area where I often see generational GC hurting is dealing with large batch jobs or sets of data. For example allocating a large collection of object means individual object allocation and promotion as new gen fills. It would be much better to just allocate a large array of objects/structures in the old gen directly, just like large primitive arrays, and work on them directly. Instead we end up going off heap and memory-mapping such collections into memory.
Kirk Pepperdine
Feb 2, 2013, 10:54:38 AM2/2/13
to Martin Thompson, mechanica...@googlegroups.com, Gil Tene
I might be being dumb here but does it matter if objects live less than a GC cycle? We want to track the ones that live longer and for how many new generation cycles to give an idea of what gets promoted and the lifetime we should expect.Ok, stupid question but how long is it between GC cycles?
I get that in a perfect world we would really know all object life cycles. However I'm thinking that given the constraints, does it really matter when before a new gen GC cycle an object dies.
If the new gen is sized to reasonable level for bytes collected, we could then dig in further to see what actually object are getting promoted as this is likely to be related to the domain model.For me the bytes allocated and collected is too blunt a tool to understand the actual model and for that we need objects by type. The actual types lets us better tune an application rather than guessing then experimenting to see if we can improve things.
Me thinks that there are two points wrapped up in this comment, one is about life span which for the young gen can be inferred by bytes and tuning an application to be more memory efficient. For that you'll need an object allocation profiler. But to our original topic, it doesn't really matter whats there, we just want to see what that curve looks like so that we can use the observation to decide on the best implement for managing memory. I don't believe getting an exact measure is possible. If you can accept that, then what we're reduced to talking about is how to get some approximation.
The one significant area where I often see generational GC hurting is dealing with large batch jobs or sets of data. For example allocating a large collection of object means individual object allocation and promotion as new gen fills. It would be much better to just allocate a large array of objects/structures in the old gen directly, just like large primitive arrays, and work on them directly. Instead we end up going off heap and memory-mapping such collections into memory.
Not sure how to respond but this sounds like the single space is better argument that delayed IBM moving to generational collectors for quite some time. That said, I'll stick to my previous email, regional collector running all the time.
Gil Tene
Feb 2, 2013, 1:06:06 PM2/2/13
to mechanica...@googlegroups.com, Gil Tene
On Saturday, February 2, 2013 12:26:34 AM UTC-8, Martin Thompson wrote:
I might be being dumb here but does it matter if objects live less than a GC cycle? We want to track the ones that live longer and for how many new generation cycles to give an idea of what gets promoted and the lifetime we should expect.
This all depends on what you want to do with this data we are talking about collecting:
- [The thing I was addressing]: If what we want to do is re-plot the old object lifetime distribution graph (like the one in http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html) for "current" applications, we need data to do that. The common reaction I often see to the classic object lifetime distribution graphs is "how do I know if my application actually behaves like that?", and "What types of apps behave lie this.". Saying "we see this sort of distribution for practically all apps" with authority is glossing over the fact that we don't have up-to-date pictures, or pictures for many different apps. Saying "the shape doesn't matter, all that matters is what survives the newgen" is glossing over all sorts off cool stuff you may be able to do within a newgen IF object distributions had certain behaviors. E.g. escape analysis and stack-based allocation patterns are forms of super-young, thread-local collection ahead of a newgen. The question of "what portion of allocation could be addressed by those things" is hard to answer without fine grain lifetime information for ephermal objects.
My point [regarding this purpose] is that most of the data for drawing that picture is not available without super-heavy instrumentation cost. We could collect it in artificially slowed down environments, and I think that it would be interesting to do that sort of sampling to update/validate the shape of the graph. My point was that it won't be as easy as asking people to upload GC logs or run some instrumented version on the production environments...
- If you want to validate that the weak generational hypothesis still applies, GC logs show you that all the time. Every time newgen recoups a very large percentage of it's size, you get that validation. No graphing, plotting, or data collection needed.
- If what you want to know is what the lifetime distribution is for long living objects, you can get a crude feel for that in all sorts of ways. Once an object is actually promoted, your sampling rate drops to oldgen frequency, but common way to establish lifetime for mid-length objects is to let newgen collections give this information at fairly good frequency by increasing the time [number of newgen cycles] objects stay in the newgen before being promoted - you loose some efficiency (copying around long lived objects more often than needed), but you get some information.
My question would be "why do you need to know this?. What do you hope to do with the data?"
Michael Barker
Feb 2, 2013, 1:24:03 PM2/2/13
to Gil Tene, mechanica...@googlegroups.com
> It would be fairly straightforward to hack a JVM like OpenJDK into a GC-alot
> mode, where both newgen and oldgen collections run almost back to back STW
> cycles, giving the application a millisecond here and there to run between
> complete GC cycles, and to collect fairly accurate object lifetime
> distribution information with that technique. I'm not sure how we could
> entice people to actually run in that mode to give us useful data, since it
> would be a badly trashing mode...
If you were going to hack a JVM to gather this information, rather
> mode, where both newgen and oldgen collections run almost back to back STW
> cycles, giving the application a millisecond here and there to run between
> complete GC cycles, and to collect fairly accurate object lifetime
> distribution information with that technique. I'm not sure how we could
> entice people to actually run in that mode to give us useful data, since it
> would be a badly trashing mode...
than run a full GC cycle could you just run a concurrent mark
periodically based on the desired measurement frequency e.g. 1 per
second? In addition counting the number of allocations between each
mark - stil not full accurate but closer. If you have the spare CPU
cycles/cores, this should too taxing on the application.
Mike.
Gil Tene
Feb 2, 2013, 2:00:20 PM2/2/13
to
On Saturday, February 2, 2013 2:37:01 AM UTC-8, Martin Thompson wrote:
The one significant area where I often see generational GC hurting is dealing with large batch jobs or sets of data. For example allocating a large collection of object means individual object allocation and promotion as new gen fills. It would be much better to just allocate a large array of objects/structures in the old gen directly, just like large primitive arrays, and work on them directly. Instead we end up going off heap and memory-mapping such collections into memory.
This is not really a *problem* with generational collection. It's simply an observations that they do not provide the same extreme filtering benefit to some part of allocation as they to to others. They do incur a small extra linear cost for promoted objects, but that cost is under your control to a large degree.
Lets put pauses aside for a minute [Imagine you could do that], and consider the cost incurred by generational collection of such large batches/bursts of data being allocated (that would then live for a long time before being discarded) compared to the cost of handling the same with either a single space collector (the put it straight in olden thing).
Here is a simplistic cost model for the for things that live in the heap and would survive newgen to be promoted:
1. In all cases you will "pay" for allocating and initializing the data.
2. With generational collection, you will also pay to copy the data around as many times [newgen GC cycles] as it takes for it to be promoted.
3. In both generational and single space collectors, you will pay for copying the data around as many times as oldgen cycles actually compact this data during it's lifetime.
4. You will pay for a live-object-finding costs of some sort (copying or marking) once per GC cycle. This tracing cost will be linear to what is actually alive in the generation the GC is working on. [In newgen this tends to be very small most of the time, but large batch spikes are exactly the thing that makes it temporarily large].
5. In oldgen (or single space) collectors that sweep (and usually manage space in free lists), the sweeping cost will be linear to the heap size (not live set).
If we focus on the amount of work done, #2, #3, and #4 can basically be arbitrarily reduced by increasing the amount of empty memory that newgen or olden get to grow into before GC is forced on them. You get to trade off CPU for memory here, which is pretty cool (again, ignoring pauses).
#5 comes in the way of doing that for oldgen collectors that sweep (which is why a pure Mark/Compact has some key benefits when it comes to efficiency, especially if you can throw empty memory at the problem).
Our experience, in and environment that actually lets you ignore pauses and focus on the cost of moving things around and tracking their liveness is that the power of throwing empty memory at reducing work is pretty extreme. When your GC CPU % drops to 5% or less, you tend to just stop caring about the amount of work done. Especially since background CPU work is something you can usually easily afford burn (if it doesn't hurt you running application threads).
We also find that that:
- It is generally important to avoid promoting objects that were allocated "very close" to the newgen cycle triggering. Otherwise stuff allocated right before the newgen kicks in gets prematurely promoted and newgen efficiency drops by a large factor. This is why most collectors force surviving things to stay in newgen at least one cycle (the HotSpot default is 7 cycles, I believe, and is dynamically adjusted).
- A huge newgen size is a great way to avoid copying around stuff, and to make objects stay around in newgen no more than two cycles (and often 0 cycles). E.g. in Zing our promotion criteria is time based (objects are old if they stay alive more than 2 seconds by default [configurable]). So as long as newgen can grow large enough to hold more than 2 seconds of allocation, no surviving object will be copied more than twice by the newgen collector. All it takes to keep up with 10GB/sec of allocation without keeping stuff in newgen more than 2 cycles is 20GB of empty memory for the newgen to use.
- IF you use a Mark/Compact oldgen collector, AND you keep your heap sparse even for oldgen (again, "just throw lots of empty memory at the problem"), the same efficiency can be had for oldgen as for newgen. For collectors whose work is linear only to live set (true for copying and Mark/Compact, false for anything the sweeps, and certainly false for anything that only compacts a small increment for each complete heap mark), efficiency is controlled by the ratio of live data to total heap size. A 20:1 empty memory to live memory ratio in oldgen can make it as efficient as a common newgen small-heap collector.
- Allowing newgen and oldgen to both use the entire heap as needed is a big plus, since empty memory is a very useful resource. In Zing, the heap is not divided into new or old parts. Either generation can make use of all the empty memory as needed to support efficiency and avoid triggering GC cycles or copying stuff around too often.
- And last: Copying stuff around is really not a big deal. Not if is done in the background by GC thread running on otherwise empty cores. In fact, the act of copying objects is generally ~5x cheaper than the act of marking the same objects. Since copying/compacting more stuff delays the need to mark that same stuff, it is dramatically more efficient to copy or compact virtually everything you can each time you mark, that it is do delay compaction of parts and mark them again and again. [Again, ignoring pauses as an issue].
Martin Thompson
Feb 2, 2013, 2:10:54 PM2/2/13
to mechanica...@googlegroups.com
But here is the rub - "[Again ignoring pauses as an issue]." With Hotspot we cannot ignore the pauses as they are mega, I've seen ~40 seconds on a 6GB heap, when dealing with bulk sets like this. :-(
Gil Tene
Feb 2, 2013, 2:26:29 PM2/2/13
to mechanica...@googlegroups.com, Gil Tene
You'd have to have a concurrent marker for newgen, and OpenJDK is far from being able to do this. Marking newgen requires a scan that [among other things] reliably covers all oldgen-objects-pointing-into-newgen. Doing that in a stop-the-world pause is fairly easy (that's what the card table and card scannign is for). But a concurrent newgen marker needs to do this safely while the program is running and the card table is mutating. [Zing uses the LVB barrier documented in the C4 collector paper to make this happen right].
If the resolution you want is 1 second, that's pretty easy to do with a concurrent marker like we have in Zing. But it's also probably reasonable to do with a stop-the-world newgen triggered every second in a hacked OpenJDK, which may remain acceptable in setups where the newgen cycle takes a small fraction of a second.
If you want higher resolution (to the 1/10th of a second or better), then even with a concurrent marker you'd start running into a problem. Concurrent markers generally consider all the stuff allocated during the concurrent mark phase as live [at least all concurrent makers I know work like that]. This means your resolution cannot be better than the marking pass length.
In addition, since marking is usually the longest part of a GC cycle (usually 60-90% of the total cycle time), we may as well just run back-to-back concurrent newgen collection and get the full benefit.
I'll take a look at what we can already get for this with Zing. We already collect and report heap velocity information as part of our concurrent GC. But we only do that for oldgen objects right now, since the driving purpose is usually to track down leaks, and things not in oldgen cannot be leaks. Reporting on lifetime distribution with a resolution no better than newgen cycle frequency can be straightforward (and you can make it do back-to-back concurrent newgens if you want to improve resolution).

Georges Gomes
Feb 2, 2013, 3:50:34 PM2/2/13
to Martin Thompson, mechanica...@googlegroups.com
I would like to share some of our experimentation my colleague Jean-Philippe Bempel and I have been doing the past years on this topic.
Let me first give you some background on product we are working on:
It's a 'middleware' processing messages for the financial markets.
Very low latency and high predictability is required.
We need to process messages under 0.05ms for 99 percentile.
Processing is very classic: we get a message, process it, add some data to a 'persistent cache' send another message and done.
Everything is short live except the data set in the 'persisted cache'.
This cache is growing and growing all the time.
We can process up to 10 000 messages in one new gen.
So 'only 1 message gets impacted' by minor GC every 10 000 messages. 0.01%.
But this in the best case scenario because if the throughput is, for exemple, 1000 messages / second. A GC pause of 10ms will impact 10 messages queuing on TCP => 0.10% of the messages.
(We never run FullGC we have enough heap for the whole week)
Then we can increase the new gen to process more message before a GC
But GC pause will be longer because more promotionable data will be in it.
We can decrease it so pauses will be shorter but more frequent.
We have done enormous developments over the years to improve this.
Off heap buffer, weak reference not promoted, refactoring a lot of low level JDK in no-allocation fashion to reduce improve all this... And all sort of other tricks.
We have pretty good results with Oracle JDK today but it was not free :)
Still, for customers that want to have guaranted latency for 99.9% or 100% of the orders, we recommend Azul Zing. The only treal VM that can achieve this.
All this being said, I don't think we are not alone in similar GC 'pattern'.
Even a web server, take a request, do some processing, read data from a 'cache' (key value pair), update 'cache' and send response.
(Ok you can use memcache on the box or on another box but it not always a good solution and it's not the same performance of a Object in HashMap in heap)
We have been analysing minor GC times and, as you know, most of the time is spent in promotion and card scanning.
What is frustrating is that we know exactly what needs to be promoted.
We would love to annonate a class and tell the JVM : 'long live object' or have a 'newold' keywork instead of 'new' to do the allocation :)
But it will be too hard to use... Completely in opposite to the GC spirit - I understand.
One thing that we are asking ourselves now: how much impact is done to L3 CPU cache when promoting data between gens. It looks like the biggest problem to generational GC in today's hardware for maximum performance and predictability.
My conclusion to all this is that I would dream of a GC with no copy, no object movement.
A GC that allocate sequentially and clean in the background.
We even tried a VM with no young with 100% allocation to old using +XX:PreTenureSizeThreshold=2 (don't ask me but 1 doesn't work)
The all thing running with big heap 8GB+ and CMS.
That's my dream GC on the paper.
In reality, allocation is slow because slot finding on the old is slow (CMS)
But pauses are low and fragmentation is not a problem (at least for us)
Cheers
Gg
Ps: this group is great - loving it :)
--
Georges Gomes
Feb 3, 2013, 6:09:46 AM2/3/13
to Martin Thompson, mechanica...@googlegroups.com
Also adding on the subject of Survivors:
If your processing unit (a message or a http request) can fit from A to Z into the new gen, then many survivors cycles are useless. New gens of today can be big. You can process many times your units of hours in a single young gen. Meanning that what is left after First survivor is going to stay.
In our product, the JVM auto-tune le survivors cycles to 16 cycles... Useless. Everything surviving more than 1 cycle is going to be promoted to old anyway. And the cycles are copying objects back and forward between survivors space. Making Minor GC pauses much longer.
Cycles in survivors are only useful if the process unit from A to Z can't be done in the new gen.
Given the size of new gen today... I don't think it's happenning much.
Or at least I don't think the auto-tuning of the JVM is right.
In our case, you can even remove survivors completly.
The extra garbage promoted (because GC kickin in the middle of a processing unit) is not significant. This remove all extra copies.
And if you use Azul Zing, this extra promotion (once after each minor GC) will likely be cleaned in the background anyway... May be Gil can comment on this?
IMHO, going with zero survivors is the way to go. it reduces Minor GC dramatically because it reduces promotion copies to the minimum. The extra promotion to old generated by it, in most cases, can be very well managed by CMS or Azul Zing... New gen today are much much bigger than 10 years ago.
It may not apply to all scenarios... but I think it applies to all scenarios that are pause sensitive.
Happy to hear your experiences with survivor cycles.
Gil Tene
Feb 3, 2013, 2:40:44 PM2/3/13
to
The motivation around this (tuning survivor behavior and newgen size) is very different between Zing and other JVMs. That's because whether or not newgen collection does object copying and promotion during a pause makes all the difference. Pausing collectors have tradeoffs that concurrent collector don't have to deal with...
When newgen does object copying and promotion in a pause:
- The frequency of the pause drops linearly as the size of newgen is increased
- The size of the pause is generally linear to the amount of stuff surviving and being copied.
- The amount of stuff being copied [in each newgen cycle] that would eventually die in newgen is generally constant (after newgen size passes a tiny critical level)
- The amount of stuff being copied and promoted [in each newgen cycle] that will eventually end up in oldgen grows linearly with newgen size (the longer the time between newgenes, the more stuff will be copied around into survivors in each pause, and the more stuff will be promoted in each pause)
So if your application has no long lived (will end up in oldgen no matter how large you set newgen) object churn AT ALL, newgen pause sizes remain constant and growing newgen is a way to reduce the pause frequency with no down side. However, if some promotion flow is inevitable, growing newgen size increased newgen pause size.
Promotion flow is inevitable in many common cases: Caching is a classic one (most caches evict the oldest stuff first), but many other scenarios drive promotion behavior. The behavior you [Georges] describes where there is a data stream that you retain in a growing cache "forever" (oldgen is large enough that you can grow it for a week without collecting it) includes such a constant promotion stream, which will grow newgen pause times if newgen sizes are increased. But the most dangerous behavior that keeps newgen sizes small in most applications is application phase shifts, like the reloading/refreshing of catalogs and other relatively static large data sets, like indexes. Anything that loads lots data in a "batch" or some rate that is not sustained but spiky, and discards it minutes or hours later, will have to run the load through the newgen - and for that temporary spike time the newgen pauses can become huge [if the newgen itself is not kept small] as a huge portion of newgen is being promoted in a single pause. Keeping survivor spaces small helps make sure that this sort of stuff would get promoted once, and not get copied around 16 times before being promoted, but that one promotion pause is still going to be big.
So in a pausing newgen collector you end up trading off efficiency against pause time and pause frequency. Increased throughput means both increased pause frequency and potentially increasing pause times. Changing newgen size and survivor behvavior can combat one at the expense of the other. "What's right" depends both on your application behavior and on what acceptable latency behavior is. E.g. some apps are ok with the occasional 2 second newgen pause on data reload, and some would consider than a total failure, where others would require a cap on newgen pause time, leading to capped newgen size, higher frequency pauses, and reduced efficiency.
When newgen does object copying and promotion concurrently with the running application:
- The frequency of the pause drops linearly as the size of newgen is increased
- The size of a newgen pause is completely independent of the amount of stuff surviving and being copied. [In Zing there are pauses for phase flips in newgen, but they are generally sub-millisecond work things].
- The amount of stuff being copied [in each newgen cycle] that would eventually die in newgen is generally constant (after newgen size passes a tiny critical level) [But the object copying is concurrent, and does not pause anything]
- The amount of stuff being copied and promoted [in each newgen cycle] that will eventually end up in oldgen grows linearly with newgen size (the longer the time between newgenes, the more stuff will be copied around into survivors in each pause, and the more stuff will be promoted in each pause) [but object copying both within the newgen and for promotion is concurrent, and does not pause anything].
With these qualities, there is NEVER a need to keep newgen size small. Growing newgen size always increases efficiency for such a setup, and will reduce the frequency of the already short phase flip pauses.
Since Zing's newgen and oldgen GC mechanisms are actually identical (Concurrent Mark/Compact), the only reason we even have a newgen is the efficiency it gets us (and the 10x-20x efficiency it brings us is worth a lot in reducing GC CPU load and supporting very high sustainable allocation rates)
This also why in Zing there is no such thing as a newgen size. It's also why we consider promotion based on time and not on the number of newgen collections done. NewGen and Oldgen are conceptual things. Objects are either new or old, and they turn old when they've been alive more than a certain amount of [elapsed] time. Newgen and Oldgen both concurrently expand and use the whole heap as needed, pre-triggering concurrent newgen or oldgen collections as allocation and promotion trajectories indicate the need to do so to keep from running out of empty heap space before collection cycles free up more room to play in.
And if you use Azul Zing, this extra promotion (once after each minor GC) will likely be cleaned in the background anyway... May be Gil can comment on this?
Since both surviving in the newgen and promoting are background things, and since compacting and collecting dead things in oldgen is also a background thing, it doesn't really matter. The only benefit of staying in newgen is the chance to die quicker and recover the space with less marking effort expended. That's a [very] big benefit, but how much of it you get has no real effect of latencies anymore with Zing, only on CPU amount expended on GC for a given workload. If you're down to 5% or less, you just don't care usually.
Michael Barker
Feb 4, 2013, 3:59:30 AM2/4/13
to Gil Tene, mechanica...@googlegroups.com, Martin Thompson
Firstly thank you for all the well thought out replies to a not
particularly well thought out question.
> So if your application has no long lived (will end up in oldgen no matter
> how large you set newgen) object churn AT ALL, newgen pause sizes remain
> constant and growing newgen is a way to reduce the pause frequency with no
> down side. However, if some promotion flow is inevitable, growing newgen
> size increased newgen pause size.
This is exactly the situation that prompted my initial email and is
the one I am currently in. While have been convinced that
applications will continue to follow the weak generational hypothesis,
it appears that there is spectrum for the amount of allocations that
will end up in the mid to long term life cycle ranging from zero to
some. As more applications want to make use of larger heaps size
pulling by holding more of the working set into RAM we will tend
toward larger values of some (probably asymptotically against some
bound). Putting C4 to one side for a moment (as the exceptional
case). The majority of the GCs implemented and in use today do a stop
the world copy for new-gen (Parallel, CMS, G1, Balanced - correct me
if I am wrong). What I was wondering was if there was some sort of
social effect amongst GC designers that, driven by the generational
hypothesis, assume that it is sufficiently valid that they can
ignore/accept the latency cost of that stop the world copy. Based on
the observations that the 2 newest collectors (G1 and Balanced) have
continued with a stop the world new-gen copy and the that new-gen
collections appear to be around 20-30% longer for JDK7 over JDK6
(iCMS) and no-one really noticed (I have evidence across 4 different
applications - just haven't had the time to formulate it into a bug
report yet) most GC designers don't appreciate that this is a
hinderance for certain applications and will become an increasing
burden when we want to utilise ever increasing heap sizes.
With our application we have an amount of natural promotion, i.e. the
life cycle of the entities implemented by the objects is
indeterminable even for entities of the same type (I don't think our
application is unique in that way and I believe it is a direction that
applications have been trending in for some time). Life cycles can
range from milliseconds to months. I've had numerous conversations
around GC, our app and reducing NewGC pause times, most of the
partipants have generally said, more tuning, less promotion or
no-garbage at all. No-one (with the exception of Gil) has suggested
that there is a fundamental flaw in the design of those collectors
that have taken the generation hypothesis as an absolute (rather than
the source of an optimisation, to bring C4 back into the picture) and
placed a lower bound on the time taken for a pause for any application
that has some degree of promotion.
Mike.
particularly well thought out question.
> So if your application has no long lived (will end up in oldgen no matter
> how large you set newgen) object churn AT ALL, newgen pause sizes remain
> constant and growing newgen is a way to reduce the pause frequency with no
> down side. However, if some promotion flow is inevitable, growing newgen
> size increased newgen pause size.
the one I am currently in. While have been convinced that
applications will continue to follow the weak generational hypothesis,
it appears that there is spectrum for the amount of allocations that
will end up in the mid to long term life cycle ranging from zero to
some. As more applications want to make use of larger heaps size
pulling by holding more of the working set into RAM we will tend
toward larger values of some (probably asymptotically against some
bound). Putting C4 to one side for a moment (as the exceptional
case). The majority of the GCs implemented and in use today do a stop
the world copy for new-gen (Parallel, CMS, G1, Balanced - correct me
if I am wrong). What I was wondering was if there was some sort of
social effect amongst GC designers that, driven by the generational
hypothesis, assume that it is sufficiently valid that they can
ignore/accept the latency cost of that stop the world copy. Based on
the observations that the 2 newest collectors (G1 and Balanced) have
continued with a stop the world new-gen copy and the that new-gen
collections appear to be around 20-30% longer for JDK7 over JDK6
(iCMS) and no-one really noticed (I have evidence across 4 different
applications - just haven't had the time to formulate it into a bug
report yet) most GC designers don't appreciate that this is a
hinderance for certain applications and will become an increasing
burden when we want to utilise ever increasing heap sizes.
With our application we have an amount of natural promotion, i.e. the
life cycle of the entities implemented by the objects is
indeterminable even for entities of the same type (I don't think our
application is unique in that way and I believe it is a direction that
applications have been trending in for some time). Life cycles can
range from milliseconds to months. I've had numerous conversations
around GC, our app and reducing NewGC pause times, most of the
partipants have generally said, more tuning, less promotion or
no-garbage at all. No-one (with the exception of Gil) has suggested
that there is a fundamental flaw in the design of those collectors
that have taken the generation hypothesis as an absolute (rather than
the source of an optimisation, to bring C4 back into the picture) and
placed a lower bound on the time taken for a pause for any application
that has some degree of promotion.
Mike.
Gil Tene
Feb 5, 2013, 6:25:36 PM2/5/13
to mechanica...@googlegroups.com, Gil Tene, Martin Thompson
On Monday, February 4, 2013 12:59:30 AM UTC-8, mikeb01 wrote:
... No-one (with the exception of Gil) has suggested
that there is a fundamental flaw in the design of those collectors
that have taken the generation hypothesis as an absolute (rather than
the source of an optimisation, to bring C4 back into the picture) and
placed a lower bound on the time taken for a pause for any application
that has some degree of promotion.
To be fair to the generations of GC designers out there: I don't think there is fundamental flaw in the design of the collectors. Instead, I think there is a fundamental flaw in the attempts to apply a design and a solution to a space that it was not meant to cover. [Even] I would argue that newgen collection pauses [in pausing collectors] are generally acceptable for human-repsonse time web apps today [It's the oldgen pauses that kill you there]. It is the attempt to use systems with such pausing behavior in machine-to-machine applications where lower-latency expectations abound that has a fundamental mismatch with the core design goals of pausing newgen collectors. It's not the pausing collector designer's fault that people are trying to apply their pausing collector in a space where pauses are not acceptable...
The brilliant observations about Generational GC in the early 1980s were done in environments that are very different than those of our current computers, and aimed at interactive human use. Humans haven't become much faster since 1980, so their rough feel for what is "ok" as a pause hasn't shifted by much.
For context, here are some useful table from Ungar's 1984 paper (it's an image, so click on the right things to make it show):
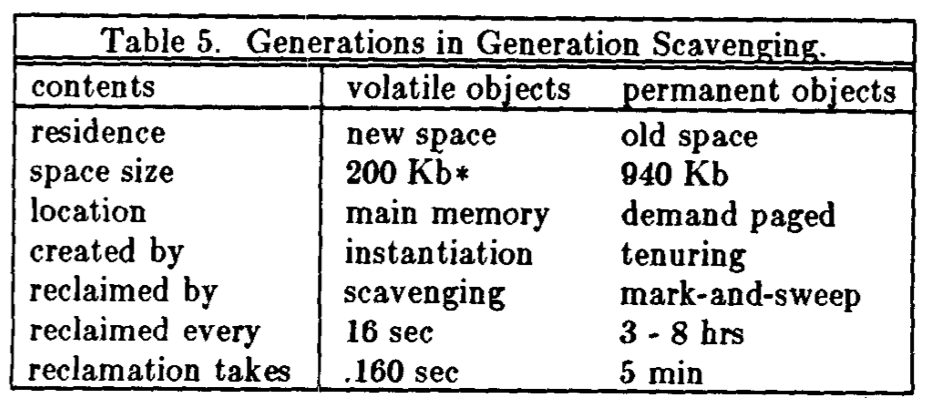
So a 200KB newgen, collected every 16 seconds (meaning ~12KB/sec of allocation), and pausing for 160msec per pause. A huge 940KB oldgen, that pauses for 5 minutes at a time (and pages to disk). Elsewhere in the paper, it notes that max newgen pause times of 330msec, and there is mention of allocation rates as whoppingly high as 100KB/sec.
Our computers today have [literally] 100,000 times as much RAM, and we no longer consider paging to disk to be acceptable. The newgens we work with today are [literally] ~10,000 larger. The rate at which we operate in them is at least 10,000x faster. Sadly, while CPU throughputs have certainly grown a bunch (in similar factors) in that time, the latencies to between a CPU and memory has only dropped by factor of ~100x in the same period.
Generational collectors have improved significantly since the early 1980s. But their primary design target has always been around human interaction times, generally accepting 10s and low 100s of msec as "pretty good", and trying hard to avoid or delay the multi-seconds and many-second pause artifacts that drive humans crazy. In the last decade or so, collectors have also trended more and more towards [what I would argue are] smallish-memory footprints. When a $5K buys you a 128GB server on the recently privatized Dell web site, a 2GB heap is very "smallish".
Stretching these collectors by taking them into the realm of systems with lower-latency bounds, and/or systems that use larger memory heaps is not impossible. It is still an exercise in square peg round hole fitting, a classic case of duct-tape engineering which can even make it fun for the practitioner. I am a firm believer that with a big enough lever and a big enough roll of duct tape, great engineers can do almost anything.

(a picture of the square peg made to fit into a round hole with duct tape, that saved Apollo 13).
Zing was designed to do this without duct tape.

Ariel Weisberg
Feb 14, 2013, 2:50:36 PM2/14/13
to mechanica...@googlegroups.com
Hi,
I think it is incorrect to assuming that writing applications in Java means you have to store data on the Java heap. You can go the ByteBuffer route or use JNI for the small number of objects that have long or variable lifetimes. As an added bonus you can get a nice boost in density and efficiency since you can control layout and indirection in ways Java doesn't allow. You can also structure your application to return memory to the operating system as load increases/decreases.
I am not a believer in using managed memory for anything other then short lived objects and very long lived state (cluster metadata, config) that basically never changes. I haven't had the good fortune to work with Zing, but no matter how good it is am I am still required to make my applications run well on Oracle JDK.
Even if old gen throughput and pause time issues were solved I would still need to get the same density and locality I can get with carefully implemented data structures and memory management. I still feel like I get a lot of benefits from using the JVM and Java. For most of my application I get bump the pointer allocation without any extra work on my part, no thread safe shared pointers, closures, and third party libraries that build and run without a fuss.
If anything I think Java should make native memory and structures a 1st class part of the language. Unsafe byte buffers, byte buffers that can grow and shrink by mapping/unmapping pages, byte buffers that index with longs, maybe some syntactic sugar for interacting with objects in a bytebuffer.
Ariel
Peter Lawrey
Feb 14, 2013, 3:01:54 PM2/14/13
to Ariel Weisberg, mechanica...@googlegroups.com
For syntactic sugar around ByteBuffers you could try javolution structs.
--
Kirk Pepperdine
Feb 15, 2013, 1:04:40 AM2/15/13
to Ariel Weisberg, mechanica...@googlegroups.com
On 2013-02-14, at 8:50 PM, Ariel Weisberg <arielw...@gmail.com> wrote:
> Hi,
>
> I think it is incorrect to assuming that writing applications in Java means you have to store data on the Java heap. You can go the ByteBuffer route or use JNI for the small number of objects that have long or variable lifetimes. As an added bonus you can get a nice boost in density and efficiency since you can control layout and indirection in ways Java doesn't allow. You can also structure your application to return memory to the operating system as load increases/decreases.
>
> I am not a believer in using managed memory for anything other then short lived objects and very long lived state (cluster metadata, config) that basically never changes. I haven't had the good fortune to work with Zing, but no matter how good it is am I am still required to make my applications run well on Oracle JDK.
>
> Even if old gen throughput and pause time issues were solved I would still need to get the same density and locality I can get with carefully implemented data structures and memory management. I still feel like I get a lot of benefits from using the JVM and Java. For most of my application I get bump the pointer allocation without any extra work on my part, no thread safe shared pointers, closures, and third party libraries that build and run without a fuss.
>
> If anything I think Java should make native memory and structures a 1st class part of the language. Unsafe byte buffers, byte buffers that can grow and shrink by mapping/unmapping pages, byte buffers that index with longs, maybe some syntactic sugar for interacting with objects in a bytebuffer.
-- Kirk
Peter Lawrey
Feb 15, 2013, 2:30:40 AM2/15/13
to Kirk Pepperdine, Ariel Weisberg, mechanica...@googlegroups.com
Writing your own garbage collector makes sense if you have really simple cleanup assumptions. e.g. Chronicle assumes it is okay to keep all the data for every stored object for a day or a week at which point you can roll the logs (or restart the application)
This allows you to clean up any number of objects at a known point in time. It also uses int or long indecies which avoids SEG/BUS Faults.
Of course anything much more complicated than this model quickly runs into trouble and you end up with most of the disadvantages of Java's GC with less of the benefits.
Kirk Pepperdine
Feb 15, 2013, 2:41:56 AM2/15/13
to Peter Lawrey, Ariel Weisberg, mechanica...@googlegroups.com
Hi Peter,
You know the old saying about assumptions.. ;-) As much as I respect your ability to make this judgement call as to when roll your own make sense over not, I fear that my experiences leave me with a far less optimistic point of view on this subject. People tends to know less about the life-cycle of their objects than they do about about rocket science. They tend to know even less about how things are connected to each other in their heap...... just drag anyone into a heapwalker and have them splunk about for a while and you'll get a feeling for what I'm talking about. I fear that these naive implementation placed in the wild are going to destabilize applications in a way that the vast majority of Java developers out there are ill equipped to handle.
Regards,
Kirk
Peter Lawrey
Feb 15, 2013, 2:58:27 AM2/15/13
to Kirk Pepperdine, Ariel Weisberg, mechanica...@googlegroups.com
In short terms, you are right, but if there is longer natural application/business day like daily trading or 24x5 this is not such a big assumption.
I think the problem is not so much that some developers don't have a pretty good idea about the life cycle of their objects (admittedly most Java developers don't care too much, and don't need to) the problem is that the cleanup can *never ever* clean up an object you assume is there later but can allow for a trivial memory leak. e.g. The Java GC allows for short term consumption of memory by objects which are not needed if there is plenty of free memory to reduce overhead.
Kirk Pepperdine
Feb 15, 2013, 3:37:13 AM2/15/13
to Peter Lawrey, Ariel Weisberg, mechanica...@googlegroups.com
On 2013-02-15, at 8:58 AM, Peter Lawrey <peter....@gmail.com> wrote:
In short terms, you are right, but if there is longer natural application/business day like daily trading or 24x5 this is not such a big assumption.
You're right! Domain constraints can often allow one to simplify or ignore difficult or intractable problems. This is what lead to specific in-house solutions being built for ORM... which was ok. The problems came with projects tried to generalize a solution built the assumptions that their constraints allowed then to make but were no longer applicable.
I think the problem is not so much that some developers don't have a pretty good idea about the life cycle of their objects (admittedly most Java developers don't care too much, and don't need to) the problem is that the cleanup can *never ever* clean up an object you assume is there later but can allow for a trivial memory leak. e.g. The Java GC allows for short term consumption of memory by objects which are not needed if there is plenty of free memory to reduce overhead.
My concern isn't with leaks, it's with dangling pointers and scan for root activities. It's also with the state of tooling for Java compared to C++ as well as the level of difficulties in moving between Java and C++ tooling.
Regards,
Kirk
Peter Lawrey
Feb 15, 2013, 3:48:15 AM2/15/13
to Kirk Pepperdine, Ariel Weisberg, mechanica...@googlegroups.com
|
I think we are saying the same thing. |
> It's also with the state of tooling for Java compared to C++ as well as the level of difficulties in moving between Java and C++ tooling.
|
The state of the tooling is important to consider for any language. Some language are easier to write tools for, or have enough mass that they have better tools. This is one of the things which puts me off newer, cooler languages. Better tools and having more time to run them is one reason I have seen Java out perform C++ in real applications. Another reason is that having some protection from the faults of a complex system is something your need whether you have Java or C++ but in the later case you end up having to re-invent what Java supports natively which means Java can be a) more reliable and b) faster in the end.
|
Kirk Pepperdine
Feb 15, 2013, 3:57:48 AM2/15/13
to Peter Lawrey, Ariel Weisberg, mechanica...@googlegroups.com
On 2013-02-15, at 9:48 AM, Peter Lawrey <peter....@gmail.com> wrote:
Ariel Weisberg
Feb 15, 2013, 12:05:29 PM2/15/13
to mechanica...@googlegroups.com, Ariel Weisberg
Hi,
For some applications the data that is taking up hundreds of gigabytes can be managed with strategies that are simpler than garbage collection.
VoltDB has two strategies based on no holes (de)allocation. Anytime something is deleted an object from the end of the allocator's pool is moved to fill the hole. The pools are fixed size and objects can be something like a red black tree nodes which are fixed size. Every time a tree node is moved to fill a hole the children and parent are updated to reflect the new location. Binary and character blobs are handled by allocating a tombstone that will never move to point to the blob and the blob contains a pointer to the tombstone so the tombstone can be updated if the blob is moved. Tombstones can never be deallocated, but they can be used for any kind of allocation and can be shared across different types of memory pools. Pools can be sized to fit the object type being allocated without any padding or fragmentation.
The density you get from this kind of approach over the life of a long running application can be a good tradeoff if you can squeeze your data into it. We don't try and shoe horn all things into this kind of allocator, just the very large data structures and objects we know might have variable and long lifetimes. What I have come to like about this approach is that it has predictable and constant overhead.
Sure pointers make for an additional set of headaches, but it is a case of risk/reward.
Thanks,
Ariel
Gil Tene
Feb 15, 2013, 2:10:03 PM2/15/13
to mechanica...@googlegroups.com, Ariel Weisberg
On Friday, February 15, 2013 6:05:29 PM UTC+1, Ariel Weisberg wrote:
Hi,For some applications the data that is taking up hundreds of gigabytes can be managed with strategies that are simpler than garbage collection.
I think you mean "with a simpler garbage collection strategy".
VoltDB has two strategies based on no holes (de)allocation. Anytime something is deleted an object from the end of the allocator's pool is moved to fill the hole. The pools are fixed size and objects can be something like a red black tree nodes which are fixed size. Every time a tree node is moved to fill a hole the children and parent are updated to reflect the new location. Binary and character blobs are handled by allocating a tombstone that will never move to point to the blob and the blob contains a pointer to the tombstone so the tombstone can be updated if the blob is moved. Tombstones can never be deallocated, but they can be used for any kind of allocation and can be shared across different types of memory pools. Pools can be sized to fit the object type being allocated without any padding or fragmentation.
If the "something is deleted" in the above is automatically detected (i.e. not an explicit free operation), then this is still automatic memory management (AMM), and what you described is a garbage collector. An incremental, compacting, able-to-limit-pointer-remapping-work-because-the-things-pointing-to-one-thing-are-well-known, and probably also doesn't-have-to-sfaepoint-because-its-access-api-is-syncronized collector. Maybe even a handle-based heap collector. But it's a collector.
On the other hand, if "something is deleted" in the above refers to explicit freeing by the program, this is not an automatic memory manager. It's a specialized malloc()/free() library that uses knowledge about the object topology it's being used for to combat fragmentation.
The non-AMM variants can be useful for managing stuff you completely own, and fully control the access to. But they are "less" useful for managing generic objects (the sort that any code can get and keep a memory reference to, and the sort that can hold references to other objects). They become harder and harder to use when you want to share that contents as objects with code you don't control or write...
There is a reason the frameworks in ecosystems like Java are as big as they are - there is a well known, memory lifeycle contract that all code can follow and expect. Without this sort of thing, the need to define the memory lifecycle contract (allocator frees, receiver frees, everyone free and ref-counts [retain/release], etc.) gets quickly in the way of building ecosystems. At least for stuff that can hold data with non-trivial topologies. For those of you who may think this is wrong, try to write down a contract for the proper allocating, handing off, and releasing objects that can form circular reference lists (where it is ok to hold things like cyclic graphs of hashmaps of doubly linked lists of the graphs themselves), and see how many other people you can get to correctly write to it so that nothing leaks and nothing gets double-freed.
Peter Lawrey
Feb 15, 2013, 10:39:59 AM2/15/13
to Gil Tene, Kirk Pepperdine, Ariel Weisberg, mechanica...@googlegroups.com
> I'm not saying that index based storage pool management is "wrong", or even that it is "worse", just that it is never better.
An assumption I am making is that you may want to persist your data (which is not true in the general case) In this situation having a relative address, or an index which can be easily checked for correctness is an improvement over regular pointers. I agree that for in memory datasets indexes are slower, though they can be checked easier has they have a valid range,On 15 February 2013 15:28, Gil Tene <g...@azulsystems.com> wrote:
On Feb 15, 2013, at 7:30 AM, "Peter Lawrey" <peter....@gmail.com> wrote:
> ...
> This allows you to clean up any number of objects at a known point in time. It also uses int or long indecies which avoids SEG/BUS Faults.im
> ...
I'm with you on the "when I know I am allowed to throw objects away, garbage collection becomes simpler" point. E.g. defragmenting a pure-cache memory pool does not require compaction and moving of objects, just aggressive eviction.
However, an int/long index system is never superior to a pointer based system. At most it can hope to be almost-equivalent on speed, and it is never more stable.
"Avoiding" SEGVs by using integer indexes into large pre-allocated regions is not a benefit. SEGV is your friend. Virtual memory protection on pointer access does not create logic bugs; It helps detect them (at times). Without it, the same logic would just silently corrupt or miscompute stuff. 20 times out of 10, you should be much happier to trigger a SEGV, than to have the same logical bug in an int/long index system go undetected.
I'm not saying that index based storage pool management is "wrong", or even that it is "worse", just that it is never better.
-- Gil.
Gil Tene
Feb 15, 2013, 10:28:20 AM2/15/13
to Peter Lawrey, Kirk Pepperdine, Ariel Weisberg, mechanica...@googlegroups.com

Rüdiger Möller
Jun 26, 2013, 10:05:19 PM6/26/13
to mechanica...@googlegroups.com
In my opinion, full service GC will stay a problem as memory size, mem access latency and cpu performance do not improve at the same rate. Any GC algorithm will suffer from that. I worked with GC systems for a long time (Lisp, Smalltalk, Java) and GC always was an issue, regardless of hardware improvements. Currenty we have a pretty bad situation as memory size has increased a lot, however a full GC on some 4Gb of smallish objects still consumes up to 10 seconds. To fit realtime requirements we had to split up our application to 40 processes running on 10 servers connected with costly hi-end network hardware to support low latency/hi throughput IPC. Still we can only use a fraction of avaiable memory.
I think its time to face reality and get VM support to ease+improve offheap object creation and handling. Long term there is a need for a new class of heap containing mostly static state. It would be perfectly acceptable if offheap objects require language level hints and have constraints (e.g. Disallow pointers from offheap => onheap) however only broad language and VM level support can make this manageable for the mass of Java programmers.
Gil Tene
Jun 26, 2013, 10:41:11 PM6/26/13
to mechanica...@googlegroups.com
Rüdiger,
Just because most current implementations have stayed behind the times is not a reason to conclude that there is some imperative issue here, and that GC cannot scale or be made to work above certain levels.
The notion of a FullGC (or even a newgen GC, or any form of GC work) being a stop-the-world event is at the heart of what's wrong with most current systems: since large (by some definition of large) pauses are unacceptable, pause times end up limiting the practical range and use of GC. However, when you eliminate the very idea that GC work is done in a pause, things fold away nicely. There is nothing wrong with spending 1 second of CPU effort per live GB on GC work, if that GC work doesn't stall your application, and when GC is efficient enough that the CPU spent on GC work is a tiny fraction of overall CPU spent by the application.
Zing provides proof-by-example that by going concurrent for all GC work (in all generations), GC can easily handle current server memory sizes and object creation throughputs with ease and with efficiency, all without having to resort to any of those requirement-breaking pause behaviors you mention bleow. It does so using current cpu performance and memory latencies, and also demonstrates that once GC is decoupled from the notion of pausing, you get arbitrary efficiency: you get to exchange arbitrary extra empty memory for matching reductions in cpu effort. There is plenty of headroom in this approach, and while it's hard to make far-forward looking statements, it's pretty clear that the current approach can go well into the 1-2TB memory and 64-128 core levels without running out of steam.
There are several people on this list that have hands-on experience deploying Zing in low latency systems, and can attest first hand to it's ability to keep application pauses and stalls down to 1-2msec worst-observed-case levels. While those same people also tend to be strong advocates for stable off-heap semantics (and other unsafe stuff), I don't think that their motivation is driven by wanting to get away from GC issues any more...
The current GC'ed heap semantics work just fine, and provide a pretty clean programming and architectural model. I'd hate to see them messed up, and would hate to see malloc/free re-introduced to Java, just because some latent GC implementations are having a hard time using more than a few % of a $5K server without it.
Kirk Pepperdine
Jun 27, 2013, 1:18:04 AM6/27/13
to Gil Tene, mechanica...@googlegroups.com
I how heartily agree with GIl's position on GC pauses. There are a number of things that are quite apparent when you start tuning collectors across a variety of applications. The first is that there is plenty of idle CPU available on every system I've tuned. Getting the collectors to use some of that concurrently with application threads has *always* been greatly beneficial In fact an application that I've just recently tuned we had 24 cores available and only 2-3 were ever being used. IOWs I had ~20 cores to throw at the memory management problem yet no way to get the current Oracle implementations to cooperate. (Yes, I wished we could have used Zing).
If you look at CMS there are a number of obvious improvements that could be made. The first thing I'd consider is eliminating all of the rescanning both concurrent and STW. That would leave just one pause phase and recent improvements in that phase leave it about 3-5x faster than it currently is. Now if you trigger CMS cycles on a more frequent basis I believe there is still a lot more room or supporting much larger heaps with this older technology. Rescanning sounds like a good idea but I've come to believe that it's not necessary and forces a second very long pause to occur.
Plus, we know have RedHat designing their own collector. I've no details (yet) on how this is going to work but I'm sure that they are going to have problems integrating it into the current OpenJDK project structure if only because the way GC and the HotSpot optimizing engines are coupled together. Any changes in the collector will most certainly require changes in other aspects of HotSpot. I do hope I'm wrong on this potential pain point.
-- Kirk
Reply all
Reply to author
Forward
0 new messages