The count query based on the vertex traversal edges is too slow!!!
93 views
Skip to first unread message

wd w
Oct 20, 2020, 8:22:59 AM10/20/20
to JanusGraph users
g.V().hasLabel("Instance").has("instanceId", P.within("12", "34")).bothE('Cause').has('enabled', true).as('e').bothV().has('instanceId', P.within('64', '123')).select('e').count();
The above count query executes very slowly, what method can be used to speed up its query.
I have created compositeIndex and mixedIndex for instanceId, enabled.
How should I convert this query to a direct index query!

HadoopMarc
Oct 20, 2020, 10:38:46 AM10/20/20
to JanusGraph users
Can you show the profiling of the query using the profile() step?
Best wishes, Marc
Op dinsdag 20 oktober 2020 om 14:22:59 UTC+2 schreef wangwe...@gmail.com:
Message has been deleted
wd w
Oct 24, 2020, 9:18:48 AM10/24/20
to JanusGraph users
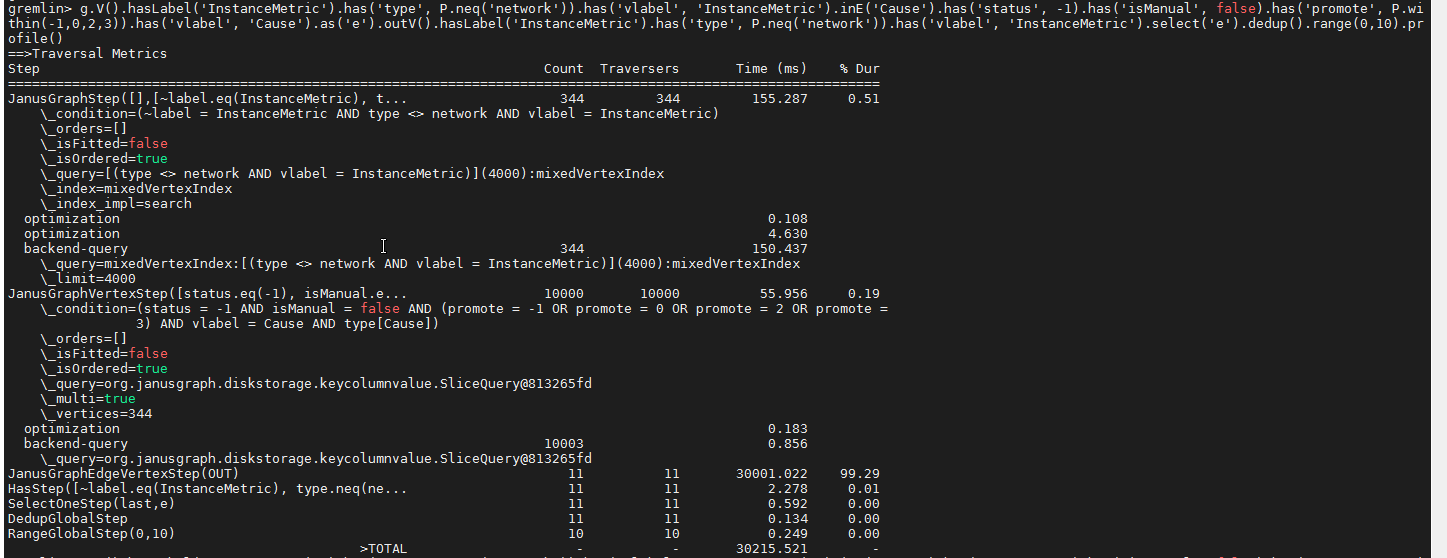
wd w
Oct 24, 2020, 9:19:12 AM10/24/20
to JanusGraph users
The total number of sides is 15000
The edge data meets the query condition is only 10000 in total
The edge data meets the query condition is only 10000 in total
HadoopMarc
Oct 25, 2020, 11:57:58 AM10/25/20
to JanusGraph users
Hi,
Apparently, the query planner is not able to use the index for the outV() step. Can you see what happens if we split the query like this (not tested):
targetIds = g.V().hasLabel('InstanceMetric').has('type', neq('network)).has('vlabel', 'InstanceMetric').toList()
g.V().hasLabel('InstanceMetric').has('type', neq('network)).has('vlabel', 'InstanceMetric')
.inE('Cause').has('status', -1).has('isManual', false)
.has('promote', within(-1,0,2,3)).has('vlabel', 'Cause')
.where(outV().has(id, within(targetIds)))
g.V().hasLabel('InstanceMetric').has('type', neq('network)).has('vlabel', 'InstanceMetric')
.inE('Cause').has('status', -1).has('isManual', false)
.has('promote', within(-1,0,2,3)).has('vlabel', 'Cause')
.where(outV().has(id, within(targetIds)))
Note that you can use the where() step instead of the as/select construct, just for readability.
HTH, Marc
Op zaterdag 24 oktober 2020 om 15:19:12 UTC+2 schreef wangwe...@gmail.com:
wd w
Oct 26, 2020, 2:46:45 AM10/26/20
to JanusGraph users
Thank you very much for your answers
,
When I change the query statement to look like yours , it can go index query normally!
g.V().hasLabel('InstanceMetric').has('type', neq('network)).has('vlabel', 'InstanceMetric')
.inE('Cause').has('status', -1).has('isManual', false)
.has('promote', within(-1,0,2,3)).has('vlabel', 'Cause')
.inE('Cause').has('status', -1).has('isManual', false)
.has('promote', within(-1,0,2,3)).has('vlabel', 'Cause')
.where(outV().
.hasLabel('InstanceMetric').has('type', neq('network)).has('vlabel', 'InstanceMetric')
).range(0,10)
But I found another problem, when the data ragne is 0~10,
it takes less than 400ms to execute, when the data range is 30000~300010, it takes more than 12s+ to execute,
Does it start reading from 0 to 300000 and then read the data from 300000 to 300010?
The vertex number of 'InstanceMetric' just is 344.
The edge number of 'Cause' is 300000+ and there are 300,000 edges established between two vertices
HadoopMarc
Oct 26, 2020, 2:49:43 AM10/26/20
to JanusGraph users
Hi,
The first line in the code suggestion in my previous post should have been (added id() step):
targetIds = g.V().hasLabel('InstanceMetric').has('type', neq('network)).has('vlabel', 'InstanceMetric').id().toList()
Best wishes, Marc
Op zondag 25 oktober 2020 om 16:57:58 UTC+1 schreef HadoopMarc:
wd w
Oct 26, 2020, 3:21:32 AM10/26/20
to JanusGraph users
Hi,
Please help me look at the following question
HadoopMarc
Oct 26, 2020, 6:27:36 AM10/26/20
to JanusGraph users
Hi,
You are right, when the index is not used in the outV() step, Janugraph resorts to a full table scan until it has enough results, 10 in the first case and 30.010 in the second. Can you also try my other suggestion to first get the targetIds and use these in you main query? My hope is that the inE() step is sufficiently fast. The edges returned from inE() already contain the vertex id's that can be matched locally against targetIds.
Marc
Op maandag 26 oktober 2020 om 08:21:32 UTC+1 schreef wangwe...@gmail.com:
wd w
Oct 26, 2020, 11:42:05 PM10/26/20
to JanusGraph users
I did a test in the terminal environment and it can indeed speed up the query. But in real development, I can’t use this method, because this method will load a lot of vertex ids and increase additional network overhead.
In addition, is there any way to speed up the query of the last few pages of data in the paging query?
HadoopMarc
Oct 27, 2020, 3:17:05 AM10/27/20
to JanusGraph users
Hi,
As explained earlier, the range(30000, 30010) causes a table scan starting at result 0. There is no way to circumvent this using range.
As to the many targetIds during development, you can do:
targetIds = g.V().hasLabel('InstanceMetric').has('type', neq('network)).has('vlabel', 'InstanceMetric').id().limit(10).toList()
HTH, Marc
Op dinsdag 27 oktober 2020 om 04:42:05 UTC+1 schreef wangwe...@gmail.com:
wd w
Oct 27, 2020, 5:57:04 AM10/27/20
to JanusGraph users
Is there no other way to speed up the page turning and querying the last few pages?
And I still have a requirement that many edges may be loaded. At present, the speed of loading is not ideal.
HadoopMarc
Oct 27, 2020, 7:53:03 AM10/27/20
to JanusGraph users
Hi
You have a lot of perseverance and you are welcome with that! This is an open source community, so use this perseverance to find a solution for us all.
Some resources on janusgraph performance:
Best wishes, Marc
Op dinsdag 27 oktober 2020 om 10:57:04 UTC+1 schreef wangwe...@gmail.com:

alexandr...@gmail.com
Nov 14, 2020, 3:45:13 AM11/14/20
to JanusGraph users
Hi,
`count` step doesn't use mixed index right now. There is a WIP PR which will allow to use mixed index for count step: https://github.com/JanusGraph/janusgraph/pull/2200
Right now, the best you can do is using direct indexQuery count. See the comment here on how to use indexQuery to speedup count: https://github.com/JanusGraph/janusgraph/issues/926#issuecomment-401442381
range(low,high) - is a deep pagination problem. It always searches from 0 to `high` but you can change your logic to have a workaround for deep pagination. Here is a comment where I discuss the workaround: https://github.com/JanusGraph/janusgraph/issues/986#issuecomment-451601715
You can read more about deep pagination problem here: https://www.elastic.co/guide/en/elasticsearch/guide/current/pagination.html
Best regards,
Oleksandr
Reply all
Reply to author
Forward
0 new messages