Skip to first unread message

Germán Biozzoli
Jun 11, 2019, 11:26:29 AM6/11/19
to ica-ato...@googlegroups.com
Hi group
We are testing Atom with a huge CSV import of entities (divisions, files and items). The items have images associated in a image server and included in digitalObjectURI column The URI is according to IIP (internet image protocol), something like the following:
The problem is that in the Atom front-end , when the user see the screen of the file or the item, appears some standard no-image image in the viewer. But the link to image currently runs OK and the image is provided.
I've tried re-creating derivatives, but no luck. I'm wondering if is there a way to create something as local (or remote) thumbnails for the image viewer?
Thank you very much for the help
Kind Regards
Germán

Dan Gillean
Jun 11, 2019, 11:52:01 AM6/11/19
to ICA-AtoM Users
Hi Germán,
Unfortunately, unless you are able to change the configuration of the URI your image server provides, then you might have to come up with some creative workarounds.
AtoM's requirements for being able to import remote digital objects via URI are:
- They must be web-accessible without any barriers to access (no logins, firewalls, VPNs, etc)
- They must be HTTP or HTTPS links (FTP links won't work)
- They must end in the file extension of the digital object. You can't link to a landing page, unfortunately
Without a URL that ends in a file extension, AtoM has no way of knowing what on the page you are trying to grab, and it therefore can't generate the derivatives. You can manually upload your own thumbnail and reference display copy, as well as change the media type by going to the Digital object metadata edit page - see:
Unfortunately, however, there's no way to bulk upload derivatives to AtoM, so that would be a rather time consuming approach.
If you are able to right-click on your image link and get a "View image" option in your browser, this will generally give you a URI right to the object that should work (assuming the other criteria are met as well). Glancing quickly at the IIP specification, it does look like there are ways to have your server construct a file path that ends in an extension however, so I would suggest you start by investigating those options.
Cheers,
--
You received this message because you are subscribed to the Google Groups "AtoM Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ica-atom-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAPwfJBBeOCiauRO6cfX9Omsa-nWSn4uXuVW%2BFi7zMqdHXWsHFA%40mail.gmail.com.
Germán Biozzoli
Jun 14, 2019, 1:32:49 PM6/14/19
to ica-ato...@googlegroups.com
Dear Dan
Thank you very much for your answer and pointing me into the right direction.
Currently I'm using Cantaloupe as image server respecting IIIF2.0 and testing a bunch of OCRs single items, folders and divisions as containers.
I have some doubts that perhaps you can help me to clarify:
1. Is not relative to atom but I'm wondering if is there some limit in mysql records lenght. I'm creating a CSV with OCR text and including in generalNotes of the item, just to be indexed by ES. Is there any suggestion about how to manage OCR textual versions (ISADG standard relative, I was trying to use a field that could be "searcheable").
2. Looking at previous answers in relation to the use of the image server
I'm a litlle concerned about my process because I'm importing the CSV with the reference to the image without any special parameter relative to the link or importing the digital object in a separate process. I have one only CSV that referrs to the image. The import process seems to be slower than previous one, but I'm assuming that is creating derivatives. My concern is relative to atom does not try to store locally the image and preserve it (more than a temporary process to create the derivative). Sorry by the ignorance, but where could I see the space that is occuppying currently atom for digital objects?
3. I wish to make a demonstration of the features of atom but changing at the level of the single item the image viewer for a JS IIIF2 enabled one. I have no problem with the carousel for the container entity but for the item I wish to use all the posible features that comes with IIIF. Could you send me suggestions about where to look/touch the code and recommendations for sharing (if the project is approved) the modification?
Kind regards and thank you very much in advance
Germán
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZL3%3D%3DS2mZr4OXCDx%2Bi4Z8EcwkL%2BUjtSq-ia5NVL90GvGg%40mail.gmail.com.
Dan Gillean
Jun 14, 2019, 2:20:01 PM6/14/19
to ICA-AtoM Users
Hi Germán,
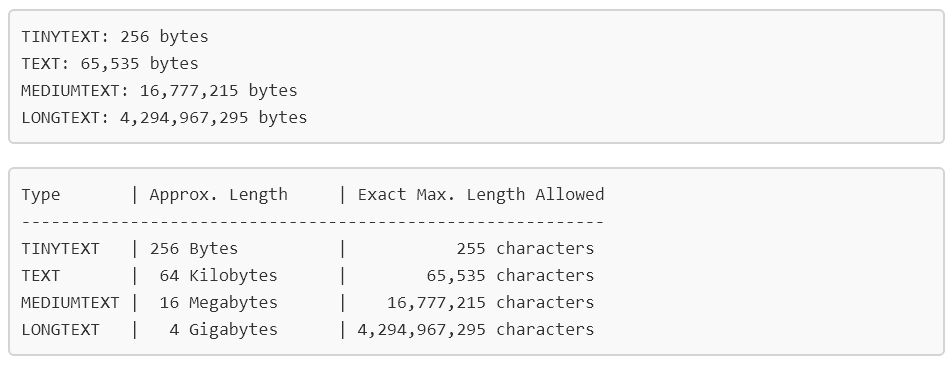
Regarding database fields, OCR and character limits:
The following is from MySQL 5.6, but I don't believe it has changed in 5.7 - these are the size limits depending on the field type set in MySQL:
AtoM stores any text layer in an uploaded digital object (such as the OCR layer on a PDF) in the transcript field found in the property table. The transcript field is searchable in AtoM - in the advanced search menu, there is a filter that can limit searches to digital object text. This transcript field is set as a TEXT type in MySQL - meaning it has a limit of 65,535 characters or bytes by default. Remember as well that AtoM uses UTF-8 character encoding, in which characters can be 1-4 bytes, depending. Soooooooo.... it depends on the characters as to how much text that translates to, unfortunately. When the limit is surpassed, the transcript simply clips - the digital object will be saved, but it means that later pages in a very large PDF or text document may not in fact be searchable.
We haven't experimented with this, but I assume it would be possible to change this field type to MEDIUMTEXT or LONGTEXT. Keep in mind that you'll likely need to restart mysql, PHP-FPM, and repopulate the search index after making such a change - and that it will cause the size of your search index to grow considerably if you are uploading large documents. For reference, you can find a copy of our database Entity Relationship Diagrams on the wiki, here:
When I have some time, I will try to generate an updated version for the final public 2.5 release, though many of the database changes included in 2.5 were already completed by November 2018, when the last ERD was uploaded to the wiki.
Also remember that your ability to get accurate search results against text found in a PDF or other text document will depend on the quality of the OCR, which may not accurately reflect that a human can read on a page! I have shown an example of this from our demo site in this thread:
Regarding the size of your digital objects stored:
You can check this in Admin > Settings - see:
Another way to check via the command line would be to check the total size of the uploads directory, where all digital objects (including derivatives, and repository logos and banners) are stored.
Note that there are a number of settings or configuration values that can limit digital object upload, that you should be aware of. I describe many of them here:
If your master digital objects are stored on a separate IIIF server, then I would recommend that you simply ensure that backups of this server are being made - to me it seems to defeat the purpose of using an IIIF server if you are also going to upload the masters directly to AtoM. AtoM simply uses the uploads directory to store digital objects - it is not a repository or a digital preservation platform. However, when making backups of your AtoM data, we do recommend that you back up the uploads directory, as well as the downloads directory if you are generating finding aids. If your IIIF server is backed up separately, then it's not as urgent to back up the uploads directory - your derivatives could always be generated again in the future using the regen-derivatives task listed here:
So long as the path to the master object that is stored in AtoM hasn't changed, and that is is publicly accessible and points directly to the object (i.e. using a URL ending in the file extension), then this regeneration task will work with objects where the master is stored elsewhere as well. There is even an --only-externals option in the task, if you only want to regenerate remote digital objects uploaded via URL.
For reference, I've previously described how the uploads directory is organized in this forum thread:
Regarding code contributions to the public project:
I will ask one of our developers if they have suggestions for where to look regarding digital object management in the code that might affect your work.
In the meantime, some thoughts on sharing development work with the public AtoM project.
This thread was in response to a question about custom theme plugin development, but my response includes a large list of the development resources we have available:
If you are considering development that you wish to share back with the public project, please be sure to review this page:
However, I must make it clear that Artefactual cannot guarantee that all code shared with us will be accepted and merged into a public release. We have only recently started to receive large feature-based pull requests from the community, and so far in general, many of these do not follow our coding standards and development guidelines, are often developed against old versions or branches of the application, are presented to us as one huge commit rather than a series of atomic commits that can be easily reviewed and understood, and/or are submitted by users with no resources (e.g. time and budget) reserved to make changes based on our feedback and recommendations. This has unfortunately made it very difficult for us to accept these.
Merging publicly created features is unsponsored work for us, and we have in the past invested many hours of staff time into reviewing features and functionality and preparing feedback, only to never hear from the developers again. If we accept a feature and merge it into the public release, that means that we are taking on its maintenance going forward through successive versions. This also means we will need to ensure that future development works with the new functionality, that we can provide basic support via our user forum as well as support for our paid clients, that we will invest further time to preparing and then maintaining documentation, that the module can be translated so we can coordinate with our international community to translate the feature, and so forth. All of this represents a huge amount of effort and staff time on Artefactual's part, with no recompense from our community. Because of this, we are cautious in what features we feel able to merge into the public project. If you are curious to learn more about how Artefactual maintains AtoM currently, I encourage you to review the following wiki page:
For us to be able to merge large feature-based pull requests, it is therefore imperative that the code be in a state that our team can maintain - that is, it follows our standards and development patterns; it reuses existing functions, methods, and libraries whenever possible; it includes clarifying comments that helps to explain the code for future developers - and all of the other aspects outlined in the Community Development Recommendations linked above. Any time we are offered code, we have to consider:
Given our recent experiences we are now requesting that, for large, feature-based pull requests to the public project, we require that the original community development team include budget for Artefactual to undertake the following:
One alternative is to continue to maintain the feature yourself as a fork, so other users can access it and implement it as desired. If there is a lot of uptake, this will likely make it much easier for more community members to share costs associated with the work of merging it into the public release in the future, should that remain desirable. In such cases, we are happy to list the available features on our wiki (as with these features), and as we encounter interest, we will continue to encourage our community to help us sponsor the addition of these features to a public release.
Merging publicly created features is unsponsored work for us, and we have in the past invested many hours of staff time into reviewing features and functionality and preparing feedback, only to never hear from the developers again. If we accept a feature and merge it into the public release, that means that we are taking on its maintenance going forward through successive versions. This also means we will need to ensure that future development works with the new functionality, that we can provide basic support via our user forum as well as support for our paid clients, that we will invest further time to preparing and then maintaining documentation, that the module can be translated so we can coordinate with our international community to translate the feature, and so forth. All of this represents a huge amount of effort and staff time on Artefactual's part, with no recompense from our community. Because of this, we are cautious in what features we feel able to merge into the public project. If you are curious to learn more about how Artefactual maintains AtoM currently, I encourage you to review the following wiki page:
For us to be able to merge large feature-based pull requests, it is therefore imperative that the code be in a state that our team can maintain - that is, it follows our standards and development patterns; it reuses existing functions, methods, and libraries whenever possible; it includes clarifying comments that helps to explain the code for future developers - and all of the other aspects outlined in the Community Development Recommendations linked above. Any time we are offered code, we have to consider:
- Is this something we have heard many different community members ask for? Will there be uptake to make this worth maintaining?
- Will this benefit the entire AtoM community, or just a small part?
- Can the feature be turned off for those in our community who don't wish to use it? Will it change what a default new installation looks like?
- Have upgrades from the current version to a new version that includes this feature been considered in the development? Are there database migration schemas in place?
- How much time will this require for review, fixes/revisions, documentation, forum support?
- How much work will this be to maintain through future versions?
- Can Artefactual afford to undertake the work required without support?
Given our recent experiences we are now requesting that, for large, feature-based pull requests to the public project, we require that the original community development team include budget for Artefactual to undertake the following:
- Code review
- Merging and code conflict resolution where needed
- Testing
- Documentation
One alternative is to continue to maintain the feature yourself as a fork, so other users can access it and implement it as desired. If there is a lot of uptake, this will likely make it much easier for more community members to share costs associated with the work of merging it into the public release in the future, should that remain desirable. In such cases, we are happy to list the available features on our wiki (as with these features), and as we encounter interest, we will continue to encourage our community to help us sponsor the addition of these features to a public release.
Regards,
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAPwfJBDRQjC0L%3DSzXiO%2BkTAtQcdQSPbL%2BwsQbVj2KUsZzoueZg%40mail.gmail.com.
Dan Gillean
Jun 14, 2019, 2:28:52 PM6/14/19
to ICA-AtoM Users
Hi again,
I've found a couple recent threads that have further pointers to the code for managing digital objects that should be of help to you. See:
I would also recommend that you do some exploring and searching in our code repository:
Regards,
Germán Biozzoli
Jun 21, 2019, 10:56:41 AM6/21/19
to ica-ato...@googlegroups.com
Dear Dan
# Query_time: 8.009458 Lock_time: 0.000041 Rows_sent: 0 Rows_examined: 88325
SET timestamp=1561058923;
UPDATE information_object
SET information_object.LFT = information_object.LFT + '2'
Thank you very very much for all the information.
I've managed to create a very quick-and-dirty IIIF client inside atom. Of course that because of my poor knowledge about symfony, I cannot make it as a plug-in, as shoud it be. But my purposes for the time being is studying and showing the factibility of use atom with the volume of information that exist (+/- 1.5 millons digital objects and images).
My problem now is that after some time of processing the CSV, let's say 80K lines, the process turns to be very slow, at the point that inserting 1000 documents takes more or less 3 hours. I've tried skip derivatives just, but there is no way to manage the number of documents that we wanted with this speed. It will take ages.
I was trying to adjust innodb settings with no luck, except for the slow queries log. I've found the following
SET timestamp=1561058923;
UPDATE information_object
SET information_object.LFT = information_object.LFT + '2'
WHERE information_object.LFT >= '69543';
It seems that taking something as 8 seconds by row isn't it? I've tried to look at the indexes but both LEFT and RIGHT seems to be indexed, the problem seems to be the update in general that goes for this number of rows.
I'm really stucked on this problem. Seems to be the limit for atom for the time being, at least for inserting a siginifcant level of our material.
Is there something that I've forgot or have to test or make in a different way?
Kind regards
Germán
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZKz5BcnVoojVdBza7qFSVUULV-in5vM6kcjC1eGDrhPqA%40mail.gmail.com.
Dan Gillean
Jun 21, 2019, 11:13:55 AM6/21/19
to ICA-AtoM Users
Hi Germán,
There are definitely places where AtoM's code needs some review and optimization, and the CSV import is one of them.
We have included a number of CSV import optimizations in the most recent 2.5 release, so if you're not currently using that, you might consider upgrading to see if it helps.There are likely more improvements we could make in the future - hopefully we will have a chance to do further analysis and improvements in a future release.
Additionally, if you are using the --index option to index each file as the import task progresses, this slows the process down considerably - we recommend instead that you run the import command without the index option, and the use the search:populate command to reindex after the import is complete.
There is also a --skip-nested-set-build option on the command-line CSV import task, that will likely help avoid a some of the issues you are encountering. You can then use php symfony propel:build-nested-set to build the nested set after the import completes. See:
Finally, it may be that your available system memory is not being released properly by the CSV import task. If possible, I would suggest that you consider breaking up your massive CSV into a couple smaller CSVs that you can import sequentially. You could try rebuilding the nested set and restarting services between the imports, and wait until all the files are imported before re-indexing.
I hope some of these suggestions help!
Cheers,
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAPwfJBBk8KnfSmPEMr1ytr%2BQ7QvGyxCSzrrdEki_3_GyM4oi0A%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages