ZFS w/o ECC RAM -> Total loss of data
3,642 views
Skip to first unread message

Philip Robar
Feb 26, 2014, 8:56:50 PM2/26/14
to zfs-...@googlegroups.com
Please note, I'm not trolling with this message. I worked in Sun's OS/Net group and am a huge fan of ZFS.
Given this, aren't the various ZFS communities--particularly those that are small machine oriented [3]--other than FreeNAS (and even they don't say it as strongly enough in their docs), doing users a great disservice by implicitly encouraging them to use ZFS w/o ECC RAM or on machines that can't use ECC RAM?
As an indication of how persuaded I've been for the need of ECC RAM, I've shut down my personal server and am not going to access that data until I've built a new machine with ECC RAM.
Phil
[1] ECC vs non-ECC RAM and ZFS: http://forums.freenas.org/index.php?threads/ecc-vs-non-ecc-ram-and-zfs.15449/
[2] cyberjock: "So when you read about how using ZFS is an "all or none" I'm not just making this up. I'm really serious as it really does work that way. ZFS either works great or doesn't work at all. That really truthfully [is] how it works."
[3] ZFS-macos, NAS4Free, PC-BSD, ZFS on Linux

Jason Belec
Feb 26, 2014, 10:04:08 PM2/26/14
to zfs-...@googlegroups.com
Well that's one point of view and choice.
I'm sure those you refer to are far more knowledgeable than any other individuals.
I can only speak for myself. I have intentionally attempted to destroy data for years under ZFS, amazingly enough all data is always recoverable. I have intentionally stayed away from protected RAM to ensure data for clients is safe.
So back to trolling. Let's be honest, if you were not trolling you would have started a new thread for people to discuss your views.
Jason
Jason
Sent from my iPhone 5S
--
---
You received this message because you are subscribed to the Google Groups "zfs-macos" group.
To unsubscribe from this group and stop receiving emails from it, send an email to zfs-macos+...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.

Daniel Becker
Feb 26, 2014, 10:09:06 PM2/26/14
to zfs-...@googlegroups.com
A few things to think about when reading that forum post:
- The scenario described in that post is based on the assumption that all blocks read from disk somehow get funneled through a single memory location, which also happens to have a permanent fault.
- In addition, it assumes that after a checksum failure, the corrected data either gets stored in the exact same memory location again, or in another memory location that also has a permanent fault.
- It also completely ignores the fact that ZFS has an internal error threshold and will automatically offline a device once the number of read/checksum errors seen on it exceeds that threshold, preventing further corruption. ZFS will *not* go and happily mess up your entire pool.
- This would *not* be silent; ZFS would report a large number of checksum errors on all your devices.
- Blocks corrupted in that particular way would *not* actually spread to incremental backups or via rsync, as the corrupted blocks would not be seen as modified.
- There is no indication that the reported cases of data loss that he points to are actually due to the particular failure mechanism described in the post; there are *lots* of other ways in which memory corruption can lead to a file system becoming unmountable, checksums or not.
- Last but not leasts, note that “Cyberjock" is a community moderator, not somebody who’s actually in any way involved in the development of ZFS (or even FreeNAS; see the preface of his FreeNAS guide for some info on his background). If this were really as big of a risk as he thinks it is, you’d think somebody who is actually familiar with the internals of ZFS would have raised this concern before.
Daniel Becker
Feb 26, 2014, 10:47:29 PM2/26/14
to zfs-...@googlegroups.com
Actually, thinking about this some more, the real reason that this hypothetical horror scenario cannot actually happen in real life is that the checksum would never get recomputed from the improperly “corrected” data to begin with: The checksum for a given block is stored in its *parent* block (which itself has a checksum that is stored in its parent, and so on and so forth, all the way up to the uberblock), not in the block itself. Therefore, if a checksum failure is detected for a block, only the block itself will be corrected (and possibly corrupted as a result of a memory error), not its checksum (which is protected by the parent block’s checksum).
See e.g. the following website for more explanation of how things are organized internally: <http://www.nexenta.com/corp/zfs-education/207-nexentastor-zfs-copy-on-write-checksums-and-consistency>
Philip Robar
Feb 27, 2014, 1:04:24 AM2/27/14
to zfs-...@googlegroups.com
On Wed, Feb 26, 2014 at 9:04 PM, Jason Belec <jason...@belecmartin.com> wrote:
Well that's one point of view and choice.I'm sure those you refer to are far more knowledgeable than any other individuals.
It's unclear to me how what I said (or possibly how I said it) caused you to reply in such a snarky way. I thought that my question was posed in a reasonable tone and based on a reasoned argument by a specific ZFS related community leader.
I, and certainly not cyberjock, made no claims that either he is "far more knowledgeable than any other individuals." If I recall correctly, cyberjock has specifically said that he has not looked at ZFS's source code. Rather, what he has said is that his recommendations are based on "a month of 12 hour days reading forums, experimenting with a VM, and then later a test platform." (And, presumably, his couple of years since then actively using ZFS.)
I can only speak for myself. I have intentionally attempted to destroy data for years under ZFS, amazingly enough all data is always recoverable. I have intentionally stayed away from protected RAM to ensure data for clients is safe.
Great! Have you made your procedures public and repeatable so that others can replicate and verify them or use them for future testing?
So back to trolling. Let's be honest, if you were not trolling you would have started a new thread for people to discuss your views.
I did start a new thread. Why are you lying about me not having done so?
Phil
Philip Robar
Feb 27, 2014, 1:24:30 AM2/27/14
to zfs-...@googlegroups.com
Thank you for your reasoned and detailed response and subsequent followup. This was exactly what I was hoping for.
I'm curious, have you read, End-to-end Data Integrity for File Systems: A ZFS Case Study by Zhang, et al?
Abstract: present a study of the effects of disk and memory corruption on file system data integrity. Our analysis focuses on Sun’s ZFS, a modern commercial offering with numerous reliability mechanisms. Through careful and thorough fault injection, we show that ZFS is robust to a wide range of disk faults. We further demonstrate that ZFS is less resilient to memory corruption, which can lead to corrupt data being returned to applications or system crashes. Our analysis reveals the importance of considering both memory and disk in the construction of truly robust file and storage systems.
...memory corruptions still remain a serious problem to data integrity. Our results for memory corruptions indicate cases where bad data is returned to the user, operations silently fail, and the whole system crashes. Our probability analysis shows that one single bit flip has small but non-negligible chances to cause failures such as reading/writing corrupt data and system crashing.
Phil
Daniel Becker
Feb 27, 2014, 1:51:41 AM2/27/14
to zfs-...@googlegroups.com
Incidentally, that paper came up in a ZFS-related thread on Ars Technica just the other day (as did the link to the FreeNAS forum post). Let me just quote what I said there:
The conclusion of the paper is that ZFS does not protect against in-memory corruption, and thus can't provide end-to-end integrity in the presence of memory errors. I am not arguing against that at all; obviously you'll want ECC on your ZFS-based server if you value data integrity -- just as you would if you were using any other file system. That doesn't really have anything to do with the claim that ZFS specifically makes lack of ECC more likely to cause total data loss, though.
The sections you quote below basically say that while ZFS offers good protection against on-disk corruption, it does *not* effectively protect you against memory errors. Or, put another way, the authors are basically finding that despite all the FS-level checksumming, ZFS does not render ECC memory unnecessary (as one might perhaps naively expect). No claim is being made that memory errors affect ZFS more than other filesystems.

Richard Elling
Feb 27, 2014, 12:30:30 PM2/27/14
to zfs-...@googlegroups.com
On Feb 26, 2014, at 10:51 PM, Daniel Becker <razz...@gmail.com> wrote:
> Incidentally, that paper came up in a ZFS-related thread on Ars Technica just the other day (as did the link to the FreeNAS forum post). Let me just quote what I said there:
>
>> The conclusion of the paper is that ZFS does not protect against in-memory corruption, and thus can't provide end-to-end integrity in the presence of memory errors. I am not arguing against that at all; obviously you'll want ECC on your ZFS-based server if you value data integrity -- just as you would if you were using any other file system. That doesn't really have anything to do with the claim that ZFS specifically makes lack of ECC more likely to cause total data loss, though.
>
> The sections you quote below basically say that while ZFS offers good protection against on-disk corruption, it does *not* effectively protect you against memory errors. Or, put another way, the authors are basically finding that despite all the FS-level checksumming, ZFS does not render ECC memory unnecessary (as one might perhaps naively expect). No claim is being made that memory errors affect ZFS more than other filesystems.
people write apps that self-check everything, there is a possibility that
something you trust [1] can fail. As it happens, only the PC market demands
no ECC. TANSTAAFL.
[1] http://en.wikipedia.org/wiki/Pentium_FDIV_bug
-- richard

Bill Winnett
Feb 27, 2014, 12:42:27 PM2/27/14
to zfs-...@googlegroups.com
Why is this a zfs issue. If you have bad ram data, the OS is
compromised already.
Where is the blame supposed to be. ZFS is not an OS and is has to
trust some api's it calls to actually perform work.

Daniel Jozsef
Feb 27, 2014, 5:36:40 PM2/27/14
to zfs-...@googlegroups.com
Wouldn't ZFS actually make things better as opposed to worse?
Say I have a Macbook with failing memory, and there's a magnetic storm. If I was using HFS+, with each write I'd be seeding the drive with bit errors, without ever noticing until the system crashes. If the bit error happens infrequently, the data corruption would likely be propagated to any backup I maintain.
With ZFS, the bit error would likely result in me being alerted of a corruption, and even if error correction "fixed" the data on the drive, this would result in an inconsistent state, and soon ZFS would take the drive offline due to fault threshold, and the system would crash. Then I would know that the data is damaged, and I could restore from backup after replacing the memory.
(And of course, ZFS protects me from the much more common hard drive bit errors.)
I don't see how this isn't awesome.
Philip Robar
Feb 28, 2014, 4:32:21 AM2/28/14
to zfs-...@googlegroups.com
On Thu, Feb 27, 2014 at 11:42 AM, Bill Winnett <bill.w...@gmail.com> wrote:
Why is this a zfs issue.
This is a ZFS issue because ZFS is advertised as being the most resilient file system currently available; however, a community leader in the FreeNAS forums (though, as pointed out by Daniel Becker, one without knowledge of ZFS internals) has argued repeatedly and strongly, and in detail that this robustness is severely compromised by using ZFS without ECC memory. Further he argues that ZFS without ECC memory is more vulnerable than other file systems to data corruption and that this corruption is likely to silently cause complete and unrecoverable pool failure. This in turn, if true, is an issue because ZFS is increasing being used on systems that either are not using or can not use ECC memory.
Jason Belec has asserted that his testing shows that there is not an increased chance of partial or complete loss of data when not using ECC memory.
Daniel Becker has cogently argued that the scenario and logic in the warning is incorrect and that it has not been shown that ZFS is in fact more vulnerable than other file systems when ECC memory is not used.
While I am reassured by their responses, I would still like an authoritative and preferably definitive answer as to whether or not ZFS is in fact any more or less vulnerable than other file systems when ECC memory is not used. So I'm going to ask my question on the Open ZFS developer's list. (Since that's the only list they have.)
Phil
Richard Elling
Feb 28, 2014, 3:36:46 PM2/28/14
to zfs-...@googlegroups.com
On Feb 28, 2014, at 1:32 AM, Philip Robar <philip...@gmail.com> wrote:
> On Thu, Feb 27, 2014 at 11:42 AM, Bill Winnett <bill.w...@gmail.com> wrote:
>
> Why is this a zfs issue.
>
> This is a ZFS issue because ZFS is advertised as being the most resilient file system currently available; however, a community leader in the FreeNAS forums (though, as pointed out by Daniel Becker, one without knowledge of ZFS internals) has argued repeatedly and strongly, and in detail that this robustness is severely compromised by using ZFS without ECC memory. Further he argues that ZFS without ECC memory is more vulnerable than other file systems to data corruption and that this corruption is likely to silently cause complete and unrecoverable pool failure. This in turn, if true, is an issue because ZFS is increasing being used on systems that either are not using or can not use ECC memory.
vulnerabilities. But *all* of them do -- including OSX. So it is disingenuous
to claim this as a ZFS deficiency.
-- richard
Philip Robar
Mar 1, 2014, 5:39:48 PM3/1/14
to zfs-...@googlegroups.com
On Fri, Feb 28, 2014 at 2:36 PM, Richard Elling <richard...@gmail.com> wrote:
vulnerabilities. But *all* of them do -- including OSX. So it is disingenuous
We might buy this argument if, in fact, no other program had the same
to claim this as a ZFS deficiency.
No it's disingenuous of you to ignore the fact that I carefully qualified what I said. To repeat, it's claimed with a detailed example and reasoned argument that ZFS is MORE vulnerable to corruption due to memory errors when using non-ECC memory and that that corruption is MORE likely to be extensive or catastrophic than with other file systems.
As I said, Jason's and Daniel Becker's responses are reassuring, but I'd really like a definitive answer to this so I've reached out to one of the lead Open ZFS developers. Hopefully, I'll hear back from him.
Phil
Jason Belec
Mar 1, 2014, 6:07:15 PM3/1/14
to zfs-...@googlegroups.com
Technically, what you qualify below is a truism under any hardware. ZFS is neither more or less susceptible to RAM failure as it has nothing to do with ZFS. Anything that gets written to the pool technically is sound. You have chosen a single possible point of failure, what of firmware, drive cache, motherboard, power surges, motion, etc.?
RAM/ECC RAM is like consumer drives vs pro drives in your system, recent long term studies have shown you don't get much more for the extra money.
I have been running ZFS in production using the past and current versions for OS X on over 60 systems (12 are servers) since Apple kicked ZFS loose. No systems (3 run ECC) have had data corruption or data loss. Some pools have disappeared on the older ZFS but were easily recovered on modern (current development) and past OpenSolaris, FreeBSD, etc., as I keep clones of 'corrupted' pools for such tests. Almost always, these were the result of connector/cable failure. In that span of time no RAM has failed 'utterly' and all data and tests have shown quality storage. In that time 11 drives have failed and easily been replaced, 4 of those were OS drives, data stored under ZFS and a regular clone of the OS also stored under ZFS just in case. All pools are backed-up/replicated off site. Probably a lot more than most are doing for data integrity.
No this data I'm providing is not a guarantee. It's just data from someone who has grown to trust ZFS in the real world for clients that cannot lose data for the most part due to legal regulations. I trust RAM manufacturers and drive manufacturers equally, I just verify for peace of mind with ZFS.
--
Jason Belec
Sent from my iPad

Jean-Yves Avenard
Mar 2, 2014, 1:46:32 AM3/2/14
to zfs-...@googlegroups.com
On 28 February 2014 20:32, Philip Robar <philip...@gmail.com> wrote:
> This is a ZFS issue because ZFS is advertised as being the most resilient
> file system currently available; however, a community leader in the FreeNAS
> forums (though, as pointed out by Daniel Becker, one without knowledge of
> ZFS internals) has argued repeatedly and strongly, and in detail that this
> robustness is severely compromised by using ZFS without ECC memory. Further
cyberjock is the biggest troll ever, not even the people actually
> This is a ZFS issue because ZFS is advertised as being the most resilient
> file system currently available; however, a community leader in the FreeNAS
> forums (though, as pointed out by Daniel Becker, one without knowledge of
> ZFS internals) has argued repeatedly and strongly, and in detail that this
> robustness is severely compromised by using ZFS without ECC memory. Further
involved with FreeNAS (iX system) knows what to do with him. He does
spend an awful amount of time on the freenas forums helping others and
as such tolerate him on that basis..
Otherwise, he just someone doing nothing, with a lot of time on his
hand and spewing the same stuff over and over simply because he has
heard about it.
Back to the ECC topic; one core issue to ZFS is that it will
specifically write to the pool even when all you are doing is read, in
an attempt to correct any data found to have incorrect checksum.
So say you have corrupted memory, you read from the disk, zfs believes
the data is faulty (after all, the checksum will be incorrect due to
faulty RAM) and start to rewrite the data. That is one scenario where
ZFS will corrupt an otherwise healthy pool until its too late and all
your data is gone.
As such, ZFS is indeed more sensitive to bad RAM than other filesystem.
Having said that; find me *ONE* official source other than the FreeNAS
forum stating that ECC is a minimal requirements (and no a wiki
written by cyberjock doesn't count). Solaris never said so, FreeBSD
didn't either, nor Sun.
Bad RAM however has nothing to do with the occasional bit flip that
would be prevented using ECC RAM. The probability of a bit flip is
low, very low.
Back to the OP, I'm not sure why he felt he had to mentioned being
part of SunOS. ZFS was never part of sunos.
JY
Philip Robar
Mar 2, 2014, 2:32:45 AM3/2/14
to zfs-...@googlegroups.com
On Sun, Mar 2, 2014 at 12:46 AM, Jean-Yves Avenard <jyav...@gmail.com> wrote:
Back to the OP, I'm not sure why he felt he had to mentioned being
part of SunOS. ZFS was never part of sunos.
I didn't say I was part of SunOS (later renamed to Solaris 1). SunOS was dead and buried years before I joined the network side of OS/Net. "OS" in this case just means operating system, it's not a reference to the "OS" in SunOS.
By mentioning that I worked in the part of Sun that invented ZFS and saying that I am a fan of it I was just trying to be clear that I was not attacking ZFS by questioning some aspect of it. Clearly, at least in some minds I failed at that.
Phil
Philip Robar
Mar 2, 2014, 3:45:52 AM3/2/14
to zfs-...@googlegroups.com
On Sun, Mar 2, 2014 at 12:46 AM, Jean-Yves Avenard <jyav...@gmail.com> wrote:
cyberjock is the biggest troll ever, not even the people actually
involved with FreeNAS (iX system) knows what to do with him. He does
spend an awful amount of time on the freenas forums helping others and
as such tolerate him on that basis..
Otherwise, he just someone doing nothing, with a lot of time on his
hand and spewing the same stuff over and over simply because he has
heard about it.
Well, that's at odds with his claims of how much time and effort he has put into learning about ZFS and is basically an ad hominem attack, but since Daniel Becker has already cast a far amount of doubt on both the scenario and logic behind cyberdog's EEC vs non-ECC posts and his understanding of architecture of ZFS I'll move on.
Back to the ECC topic; one core issue to ZFS is that it will
specifically write to the pool even when all you are doing is read, in
an attempt to correct any data found to have incorrect checksum.
So say you have corrupted memory, you read from the disk, zfs believes
the data is faulty (after all, the checksum will be incorrect due to
faulty RAM) and start to rewrite the data. That is one scenario where
ZFS will corrupt an otherwise healthy pool until its too late and all
your data is gone.
As such, ZFS is indeed more sensitive to bad RAM than other filesystem.
So, you're agreeing with cyberdog's conclusion, just not the path he took to get there.
Having said that; find me *ONE* official source other than the FreeNAS
forum stating that ECC is a minimal requirements (and no a wiki
written by cyberjock doesn't count). Solaris never said so, FreeBSD
didn't either, nor Sun.
So if a problem isn't documented, it's not a problem?
Most Sun/Solaris documentation isn't going to mention the need for ECC memory because all Sun systems shipped with ECC memory. FreeBSD/PC-BSD/FreeNAS/NAS4Free/Linux in turn derive from worlds where ECC memory is effectively nonexistent so their lack of documentation may stem from a combination of the ZFS folks just assuming that you have it and the distro people not realizing that you need it. FreeNAS's guide does state pretty strongly that you should use ECC memory. But if you insist: from "Oracle Solaris 11.1 Administration: ZFS File Systems", "Consider using ECC memory to protect against memory corruption. Silent memory corruption can potentially damage your data." [1]
It seems to me that if using ZFS without ECC memory puts someone's data at an increased risk over other file system then they ought to be told that so that they can make an informed decision. Am I really being unreasonable about this?
Bad RAM however has nothing to do with the occasional bit flip that
would be prevented using ECC RAM. The probability of a bit flip is
low, very low.
You and Jason have both claimed this. This is at odds with papers and studies I've seen mentioned elsewhere. Here's what a little searching found:
Soft Error: https://en.wikipedia.org/wiki/Soft_error
Which says that there are numerous sources of soft errors in memory and other circuits other than cosmic rays.
ECC Memory: https://en.wikipedia.org/wiki/ECC_memory
States that design has dealt with the problem of increased circuit density. It then mentions the research IBM did years ago and Google's 2009 report which says:
The actual error rate found was several orders of magnitude higher than previous small-scale or laboratory studies, with 25,000 to 70,000 errors per billion device hours per megabit (about 2.5–7 × 10−11 error/bit·h)(i.e. about 5 single bit errors in 8 Gigabytes of RAM per hour using the top-end error rate), and more than 8% of DIMM memory modules affected by errors per year.
So, since you've agreed that ZFS is more vulnerable than other file systems to memory errors, and Google says that these errors are a lot more frequent than most people think that they are then the question becomes just how much more vulnerable is ZFS and is the extent of the corruption likely to be wider or more catastrophic than on other file systems?
Phil
[1] Oracle Solaris 11.1 Administration: ZFS File Systems: http://docs.oracle.com/cd/E26502_01/html/E29007/zfspools-4.html
Philip Robar
Mar 2, 2014, 4:16:19 AM3/2/14
to zfs-...@googlegroups.com
On Sat, Mar 1, 2014 at 5:07 PM, Jason Belec <jason...@belecmartin.com> wrote:
Technically, what you qualify below is a truism under any hardware. ZFS is neither more or less susceptible to RAM failure as it has nothing to do with ZFS. Anything that gets written to the pool technically is sound. You have chosen a single possible point of failure, what of firmware, drive cache, motherboard, power surges, motion, etc.?
I'm sorry, but I'm not following your logic here. Are you saying that ZFS doesn't use RAM so it can't be affected by it? ZFS likes lots of memory and uses it aggressively. So my understanding is that large amounts of data are more likely to be in memory with ZFS than with other file systems. If Google's research is to believed then random memory errors are a lot more frequent than you think that they are. As I understand it, ZFS does not checksum data while it's in memory. (While there a debug flag to turn this on, I'm betting that the performance hit is pretty big.) So how does RAM failure or random bit flips have nothing to do with ZFS?
RAM/ECC RAM is like consumer drives vs pro drives in your system, recent long term studies have shown you don't get much more for the extra money.
Do you have references to these studies? This directly conflicts with what I've seen posted, with references, in other forums on the frequency of soft memory errors, particularly on systems that run 24x7, and how ECC memory is able to correct these random errors.
I have been running ZFS in production using the past and current versions for OS X on over 60 systems (12 are servers) since Apple kicked ZFS loose. No systems (3 run ECC) have had data corruption or data loss.
That you know of.
Some pools have disappeared on the older ZFS but were easily recovered on modern (current development) and past OpenSolaris, FreeBSD, etc., as I keep clones of 'corrupted' pools for such tests. Almost always, these were the result of connector/cable failure. In that span of time no RAM has failed 'utterly' and all data and tests have shown quality storage. In that time 11 drives have failed and easily been replaced, 4 of those were OS drives, data stored under ZFS and a regular clone of the OS also stored under ZFS just in case. All pools are backed-up/replicated off site. Probably a lot more than most are doing for data integrity.No this data I'm providing is not a guarantee. It's just data from someone who has grown to trust ZFS in the real world for clients that cannot lose data for the most part due to legal regulations. I trust RAM manufacturers and drive manufacturers equally, I just verify for peace of mind with ZFS.
I have an opinion of people who run servers with legal or critical business data on it that do not use ECC memory but I'll keep it to myself.
Phil
Daniel Becker
Mar 2, 2014, 5:32:09 AM3/2/14
to zfs-...@googlegroups.com
But if you insist: from "Oracle Solaris 11.1 Administration: ZFS File Systems", "Consider using ECC memory to protect against memory corruption. Silent memory corruption can potentially damage your data." [1]
That is in no way specific to ZFS, though; silent memory corruption can cause corruption in any number of ways for basically any filesystem. If you value your data, you'll want to use ECC, regardless of whether you use ZFS or not.
The actual error rate found was several orders of magnitude higher than previous small-scale or laboratory studies, with 25,000 to 70,000 errors per billion device hours per megabit (about 2.5–7 × 10−11 error/bit·h)(i.e. about 5 single bit errors in 8 Gigabytes of RAM per hour using the top-end error rate), and more than 8% of DIMM memory modules affected by errors per year.So, since you've agreed that ZFS is more vulnerable than other file systems to memory errors, and Google says that these errors are a lot more frequent than most people think that they are then the question becomes just how much more vulnerable is ZFS and is the extent of the corruption likely to be wider or more catastrophic than on other file systems?
It's somewhat misleading to just look at the averages in this case, though, as the paper specifically points out that the errors are in fact highly clustered, not evenly distributed across devices and/or time. I.e., there are some DIMMs that produce a very large number of errors, but the vast majority of DIMMs (92% as per the paragraph you quoted above) actually produce no (detectable) bit errors at all per year.
It seems to me that if using ZFS without ECC memory puts someone's data at an increased risk over other file system then they ought to be told that so that they can make an informed decision. Am I really being unreasonable about this?
You keep claiming this, but I still haven't seen any conclusive evidence that lack of ECC poses a higher overall risk for your data when using ZFS than with other file systems. Note that even if you could find a scenario where ZFS will do worse than others (and I maintain that the specific scenario Cyberjock describes is not actually plausible), there are other scenarios where ZFS will actually catch memory corruption but other file systems will not (e.g., bit flip occurs after checksum has been computed but before data is written to disk, or bit flip occurs after data has been read from disk but before checksum is compared, or bit flip causes stray write of bogus data to disk); without knowing the likelihood of each of these scenarios and their respective damage potential, it is impossible to say which side is more at risk.

Bjoern Kahl
Mar 2, 2014, 5:33:39 AM3/2/14
to zfs-...@googlegroups.com
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA1
Am 02.03.14 09:45, schrieb Philip Robar:
[ cut a lot not relevant to my comment ]
>> Bad RAM however has nothing to do with the occasional bit flip
>> that would be prevented using ECC RAM. The probability of a bit
>> flip is low, very low.
>>
>
> You and Jason have both claimed this. This is at odds with papers
> and studies I've seen mentioned elsewhere. Here's what a little
> searching found:
>
> Soft Error: https://en.wikipedia.org/wiki/Soft_error Which says
> that there are numerous sources of soft errors in memory and other
> circuits other than cosmic rays.
>
> ECC Memory: https://en.wikipedia.org/wiki/ECC_memory States that
> design has dealt with the problem of increased circuit density. It
> then mentions the research IBM did years ago and Google's 2009
> report which says:
>
> The actual error rate found was several orders of magnitude higher
> than previous small-scale or laboratory studies, with 25,000 to
> 70,000 errors per billion device hours per mega*bit* (about 2.5-7 ×
> 10-11 error/bit·h)(i.e. about 5 single bit errors in 8 Gigabytes of
You say that an average 8 GB memory subsystem should experience 5 bit
errors per *hour* of operation.
On the other side you say (only) 8% of all DIMMs are affected per
*year*. I *guess* (and might be wrong) that the majority of installed
DIMMs nowadays are 2 GB DIMMs, so you need four of them to build
8 GB. Assuming equal distribution of bit errors, this means on
average *every* DIMM will experience 1 bit error per hour. That
doesn't fit.
Today's all purpose PC's regularly ship with 8 GB of RAM, and modern,
widely used operating systems, no matter which vendor, all make
excessive use of any single bit of memory they can get. Non of these
have any software means to protect RAM content, including FS caches,
against bit rot.
With 5 bit errors per hour these machines should be pretty unusable,
corrupting documents all day and probably crashing applications and
sometimes the OS repeatedly within a business day. Yet I am not aware
of any reports that daily office computing ceased to be reliably
usable over the last decade.
So something doesn't fit here. Where is (my?) mistake in reasoning?
Of course, this does not say anything about ZFS' vulnerability to RAM
errors compared to other system parts. I'll come to that point in a
different mail, but it will take a bit more time to write it up
without spreading more uncertainty than already produced in this
thread.
Best regards
Björn
- --
| Bjoern Kahl +++ Siegburg +++ Germany |
| "googlelogin@-my-domain-" +++ www.bjoern-kahl.de |
| Languages: German, English, Ancient Latin (a bit :-)) |
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/
iQCVAgUBUxMJAFsDv2ib9OLFAQKIyAQAmZBIryCnndv1FZleZ5JRlQpVMZ8N+TmB
3FYBMTFk9c8caC65Avv9cKsP7Fq5X2F3gRfTzo8f8Kk9evsnOGheksFPs8y14gsP
AYTXz8B0rbZlfH/DQhV5JOYnEdeYXTwuN3Nso41CMER7EFpa6bEGSNiTiA8inbCr
GjHQot2gTwc=
=8fU0
-----END PGP SIGNATURE-----
Hash: SHA1
Am 02.03.14 09:45, schrieb Philip Robar:
[ cut a lot not relevant to my comment ]
>> Bad RAM however has nothing to do with the occasional bit flip
>> that would be prevented using ECC RAM. The probability of a bit
>> flip is low, very low.
>>
>
> You and Jason have both claimed this. This is at odds with papers
> and studies I've seen mentioned elsewhere. Here's what a little
> searching found:
>
> Soft Error: https://en.wikipedia.org/wiki/Soft_error Which says
> that there are numerous sources of soft errors in memory and other
> circuits other than cosmic rays.
>
> ECC Memory: https://en.wikipedia.org/wiki/ECC_memory States that
> design has dealt with the problem of increased circuit density. It
> then mentions the research IBM did years ago and Google's 2009
> report which says:
>
> The actual error rate found was several orders of magnitude higher
> than previous small-scale or laboratory studies, with 25,000 to
> 10-11 error/bit·h)(i.e. about 5 single bit errors in 8 Gigabytes of
> RAM per hour using the top-end error rate), and more than 8% of
> DIMM memory modules affected by errors per year.
Have you some *reliable* source for your claim in above paragraph?
> DIMM memory modules affected by errors per year.
You say that an average 8 GB memory subsystem should experience 5 bit
errors per *hour* of operation.
On the other side you say (only) 8% of all DIMMs are affected per
*year*. I *guess* (and might be wrong) that the majority of installed
DIMMs nowadays are 2 GB DIMMs, so you need four of them to build
8 GB. Assuming equal distribution of bit errors, this means on
average *every* DIMM will experience 1 bit error per hour. That
doesn't fit.
Today's all purpose PC's regularly ship with 8 GB of RAM, and modern,
widely used operating systems, no matter which vendor, all make
excessive use of any single bit of memory they can get. Non of these
have any software means to protect RAM content, including FS caches,
against bit rot.
With 5 bit errors per hour these machines should be pretty unusable,
corrupting documents all day and probably crashing applications and
sometimes the OS repeatedly within a business day. Yet I am not aware
of any reports that daily office computing ceased to be reliably
usable over the last decade.
So something doesn't fit here. Where is (my?) mistake in reasoning?
Of course, this does not say anything about ZFS' vulnerability to RAM
errors compared to other system parts. I'll come to that point in a
different mail, but it will take a bit more time to write it up
without spreading more uncertainty than already produced in this
thread.
Best regards
Björn
- --
| Bjoern Kahl +++ Siegburg +++ Germany |
| "googlelogin@-my-domain-" +++ www.bjoern-kahl.de |
| Languages: German, English, Ancient Latin (a bit :-)) |
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/
iQCVAgUBUxMJAFsDv2ib9OLFAQKIyAQAmZBIryCnndv1FZleZ5JRlQpVMZ8N+TmB
3FYBMTFk9c8caC65Avv9cKsP7Fq5X2F3gRfTzo8f8Kk9evsnOGheksFPs8y14gsP
AYTXz8B0rbZlfH/DQhV5JOYnEdeYXTwuN3Nso41CMER7EFpa6bEGSNiTiA8inbCr
GjHQot2gTwc=
=8fU0
-----END PGP SIGNATURE-----
Daniel Becker
Mar 2, 2014, 5:43:46 AM3/2/14
to zfs-...@googlegroups.com
On Mar 2, 2014, at 2:33 AM, Bjoern Kahl <googl...@bjoern-kahl.de> wrote:
> On the other side you say (only) 8% of all DIMMs are affected per
> *year*. I *guess* (and might be wrong) that the majority of installed
> DIMMs nowadays are 2 GB DIMMs, so you need four of them to build
> 8 GB. Assuming equal distribution of bit errors, this means on
> average *every* DIMM will experience 1 bit error per hour. That
> doesn't fit.
The disconnect is in the fact that they are not uniformly distributed at all; see my other email. Some (bad) DIMMs produce tons of errors, while the vast majority produce none at all. Quoting the averages is really kind of misleading.> On the other side you say (only) 8% of all DIMMs are affected per
> *year*. I *guess* (and might be wrong) that the majority of installed
> DIMMs nowadays are 2 GB DIMMs, so you need four of them to build
> 8 GB. Assuming equal distribution of bit errors, this means on
> average *every* DIMM will experience 1 bit error per hour. That
> doesn't fit.

Chris Ridd
Mar 2, 2014, 7:49:58 AM3/2/14
to zfs-...@googlegroups.com
On 2 Mar 2014, at 09:16, Philip Robar <philip...@gmail.com> wrote:
> On Sat, Mar 1, 2014 at 5:07 PM, Jason Belec <jason...@belecmartin.com> wrote:
>> RAM/ECC RAM is like consumer drives vs pro drives in your system, recent long term studies have shown you don't get much more for the extra money.
>>
> Do you have references to these studies? This directly conflicts with what I've seen posted, with references, in other forums on the frequency of soft memory errors, particularly on systems that run 24x7, and how ECC memory is able to correct these random errors.
http://blog.backblaze.com/2013/12/04/enterprise-drive-reliability/
They have lots more related articles on their blog that are well worth a read.
Chris

Eric Jaw
Mar 31, 2014, 5:23:33 PM3/31/14
to zfs-...@googlegroups.com
I completely agree. I'm experiencing these issues currently. Largely.
Doing a scrub is just obliterating my pool.
I'm using RAM that is definitely non-ECC. They are:
+ OCZ Reaper HPC DDR3 PC3-12800 (ocz3rpr1600lv2g) 3x2GB
+ Corsair Vengeance (cmz12gx3m3a1600c9) 3x4GB
I'm also running ZFS on FreeBSD 10.0 (RELEASE) in VirtualBox on Windows 7 Ultimate.
Things seem to be pointing to non-ECC RAM causing checksum errors. It looks like I'll have to swap out my memory to ECC RAM if I want to continue this project, otherwise the data is pretty much hosed right now.
Doing a scrub is just obliterating my pool.
scan: scrub in progress since Mon Mar 31 10:14:52 2014
1.83T scanned out of 2.43T at 75.2M/s, 2h17m to go
0 repaired, 75.55% done
config:
NAME STATE READ WRITE CKSUM
moon ONLINE 0 0 91
mirror-0 ONLINE 0 0 110
diskid/DISK-VB92cae47b-31125427p1 ONLINE 0 0 112
diskid/DISK-VBd1496f13-1a733a17p1 ONLINE 0 0 114
mirror-1 ONLINE 0 0 72
diskid/DISK-VB343ad927-b4a3f4f8p1 ONLINE 0 0 77
diskid/DISK-VB245c2429-c36e13b0p1 ONLINE 0 0 74
logs
diskid/DISK-VB98bcd93f-cdf5113fp1 ONLINE 0 0 0
cache
diskid/DISK-VB56c14272-ddacbe50p1 ONLINE 0 0 0
errors: 43 data errors, use '-v' for a list
I'm using RAM that is definitely non-ECC. They are:
+ OCZ Reaper HPC DDR3 PC3-12800 (ocz3rpr1600lv2g) 3x2GB
+ Corsair Vengeance (cmz12gx3m3a1600c9) 3x4GB
I'm also running ZFS on FreeBSD 10.0 (RELEASE) in VirtualBox on Windows 7 Ultimate.
Things seem to be pointing to non-ECC RAM causing checksum errors. It looks like I'll have to swap out my memory to ECC RAM if I want to continue this project, otherwise the data is pretty much hosed right now.
Bjoern Kahl
Mar 31, 2014, 5:53:59 PM3/31/14
to zfs-...@googlegroups.com
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA1
Am 31.03.14 23:23, schrieb Eric Jaw:
Hash: SHA1
connection or more likely a dying controller than ECC vs. non-ECC RAM.
Random bit-flips, which ECC RAM is supposed to detect and correct, are
extremely rare in an otherwise healthy system. And as the name says,
they are random, i.e. not located at a fixed memory position but
instead "jumping around" in the address range. So if there should
ever be a bit flip in the ARC that happens after checksumming and
before written out to disc (the only way to write a bad checksum to
disk I can think of), than it would be either dropped soon after from
ARC or overwritten with a new read. In either case, statistically a
long time would pass before the next time a bit flip hit some other
active data.
One of my machines (an old 32 bit Athlon) showed a similar pattern of
checksum errors that could be traced to a weak SATA controller: I got
massive checksum errors on the four internal links when all four
channels were simultaneously active. The situation greatly improved
after rewiring the drives and making sure the SATA cables keep a
minimum distance of 1-2 cm from each other. Apparently in my case it
was a cross-talk problem.
Best regards
Björn
> On Wednesday, February 26, 2014 8:56:50 PM UTC-5, Philip Robar
> wrote:
>>
>> Please note, I'm not trolling with this message. I worked in
>> Sun's OS/Net group and am a huge fan of ZFS.
>>
>> The leading members of the FreeNAS community make it
- --
| Bjoern Kahl +++ Siegburg +++ Germany |
| "googlelogin@-my-domain-" +++ www.bjoern-kahl.de |
| Languages: German, English, Ancient Latin (a bit :-)) |
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/
iQCVAgUBUznj8lsDv2ib9OLFAQLo8wP/SkuFv8lYZdP2+8wuazrPCcLJtToAhoIf
| Bjoern Kahl +++ Siegburg +++ Germany |
| "googlelogin@-my-domain-" +++ www.bjoern-kahl.de |
| Languages: German, English, Ancient Latin (a bit :-)) |
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/
7LVaRznmkrMPOBiDgmcBG+vZbT6y8KRYvsH8D60W33KFASJE4Qj3NIu+kX3I94Ol
UfbcIuivc3VAVCCLNoxVv3khzDEBg9pk7kcF2Yy65ot+xR1l5zLvMWeP7Cult9Xc
60+9aEyIOOE=
=lrdh
-----END PGP SIGNATURE-----
Daniel Becker
Mar 31, 2014, 5:55:21 PM3/31/14
to zfs-...@googlegroups.com
On Mar 31, 2014, at 2:23 PM, Eric Jaw <nais...@gmail.com> wrote:
Doing a scrub is just obliterating my pool.
Is it? I don’t think so:
scan: scrub in progress since Mon Mar 31 10:14:52 2014
1.83T scanned out of 2.43T at 75.2M/s, 2h17m to go
0 repaired, 75.55% done
Note the “0 repaired.”
I'm also running ZFS on FreeBSD 10.0 (RELEASE) in VirtualBox on Windows 7 Ultimate.
Are the disks that the VM sees file-backed or passed-through raw disks?
Things seem to be pointing to non-ECC RAM causing checksum errors. It looks like I'll have to swap out my memory to ECC RAM if I want to continue this project, otherwise the data is pretty much hosed right now.
Did you actually run a memory tester (e.g., memcheck86), or is this just based on gut feeling? Lots of things can manifest as checksum errors. If you import the pool read-only, do successive scrubs find errors in different files (use “zpool status -v”) every time, or are they always in the same files? The former would indeed point to some kind of memory corruption issue, while in the latter case it’s much more likely that your on-disk data somehow got corrupted.
Jason Belec
Mar 31, 2014, 9:10:49 PM3/31/14
to zfs-...@googlegroups.com
As one who has gone through all kinds of permutations to 'corrupt' data under ZFS, I'm calling BS on the RAM as the culprit. As Bjoern mentioned it sounds like connector issues, something I've seen a lot. However depending how you set your pool up, your data may be difficult to access but most likely complete and healthy.
It amazes me how willing people are to blame something definitively with so little knowledge of what's going on and determined that quoting some discussion out of context will justify the irrationality.
These threads are kind of getting redundant, pointless and I think some of these individuals are best served by Drobo or similar technology.
Jason
Sent from my iPhone 5S
Eric Jaw
Mar 31, 2014, 10:05:28 PM3/31/14
to zfs-...@googlegroups.com
I just started using ZFS a few weeks ago. Thanks for the idea! I used all new SATA cables when I built this
I have no idea what's causing this, so I posted some more details here: https://forums.virtualbox.org/viewtopic.php?f=6&t=60975
@Daniel Becker has a very good point about how I have the disks set. I'll have to look into that some more
Eric Jaw
Mar 31, 2014, 10:41:26 PM3/31/14
to zfs-...@googlegroups.com
On Monday, March 31, 2014 5:55:21 PM UTC-4, Daniel Becker wrote:
On Mar 31, 2014, at 2:23 PM, Eric Jaw <nais...@gmail.com> wrote:Doing a scrub is just obliterating my pool.Is it? I don’t think so:
Thanks for the response! Here's some more details on the setup: https://forums.virtualbox.org/viewtopic.php?f=6&t=60975
I started using ZFS about a few weeks ago, so a lot of it is still new to me. I'm actually not completely certain about "proper procedure" for repairing a pool. I'm not sure if I'm supposed to clear the errors after the scrub, before or after (little things). I'm not sure if it even matters. When I restarted the VM, the checksum counts cleared on its own.
I wasn't expecting to run into any issues. But I drew a part of my conclusion from the high numbers of checksum errors that never happened until I started reading from the dataset and that number went up in the tens' when I scrubbed the pool; almost doubling when scrubbed for a second time.
scan: scrub in progress since Mon Mar 31 10:14:52 2014
1.83T scanned out of 2.43T at 75.2M/s, 2h17m to go
0 repaired, 75.55% doneNote the “0 repaired.”
On the first scrub it repaired roughly 1.65MB. None on the second scub. Even after the scrub there were still 43 data errors. I was expecting they were going to go away.
errors: 43 data errors, use '-v' for a list
I'm also running ZFS on FreeBSD 10.0 (RELEASE) in VirtualBox on Windows 7 Ultimate.Are the disks that the VM sees file-backed or passed-through raw disks?
This is an excellent question. They're in 'Normal' mode. I remember looking in to this before and decided normal mode should be fine. I might be wrong. So thanks for bringing this up. I'll have to check it out again.
Things seem to be pointing to non-ECC RAM causing checksum errors. It looks like I'll have to swap out my memory to ECC RAM if I want to continue this project, otherwise the data is pretty much hosed right now.Did you actually run a memory tester (e.g., memcheck86), or is this just based on gut feeling? Lots of things can manifest as checksum errors. If you import the pool read-only, do successive scrubs find errors in different files (use “zpool status -v”) every time, or are they always in the same files? The former would indeed point to some kind of memory corruption issue, while in the latter case it’s much more likely that your on-disk data somehow got corrupted.
memtest86 and memtest86+ for 18 hours came out okay. I'm on my third scrub and the number or errors has remained at 43. Checksum errors continue to pile up as the pool is getting scrubbed.
I'm just as flustered about this. Thanks again for the input.
Eric Jaw
Mar 31, 2014, 10:52:57 PM3/31/14
to zfs-...@googlegroups.com
On Monday, March 31, 2014 9:10:49 PM UTC-4, jasonbelec wrote:
As one who has gone through all kinds of permutations to 'corrupt' data under ZFS, I'm calling BS on the RAM as the culprit. As Bjoern mentioned it sounds like connector issues, something I've seen a lot. However depending how you set your pool up, your data may be difficult to access but most likely complete and healthy.It amazes me how willing people are to blame something definitively with so little knowledge of what's going on and determined that quoting some discussion out of context will justify the irrationality.These threads are kind of getting redundant, pointless and I think some of these individuals are best served by Drobo or similar technology.
JasonSent from my iPhone 5S
It's true. I just started using ZFS a few weeks ago. It made sense to me, since I have no idea why this is happening. I used new cables when I built this. I'm using HDD's that were pretty much from the same batch and one that I've used really heavily, I would say a good 20:1 compared to these four drives in my pool, which have barely been touched.

Gregg Wonderly
Apr 1, 2014, 12:07:29 AM4/1/14
to zfs-...@googlegroups.com
The long and the short of it, is that
most likely you have a failing disk or controller/connector more
than anything. I used to run an 8-disk, 4 mirrored pair pool on a
small box without good airflow and slow, SATA-150 controllers that
were supported by Solaris 10. I ended up replacing the whole
system with a new large box with 140mm fans as well as sata-300
controllers to get better cooling. Over time, every disk has
failed because of heat issues. Many of my SATA cables failed
too. They were cheap junk.
Equipment has to be selected carefully. I do not see any failing bits for the 3+ years now that I have been running on the new hardware with all of the disks being replaced 2 years ago, so I have been making no changes for the past 2 years. All is good for me with ZFS and non-ECC ram.
If I build another system, I will build a new system with ECC RAM and will get new controllers and new cables just because.
My current select is to use ZFS on Linux, because I haven't had a disk array/container that I could hook up to the Macs in the house.
My new ZFS array might end up being Mac Pro based with some of the thunderbolt based disk carriers.
I have about 8TB of stuff that I need to be able to keep safe.
Amazon Glacier is on my radar. At some point I may just get a 4TB USB3.0 drive to copy stuff to and ship off to Glacier.
Gregg
Equipment has to be selected carefully. I do not see any failing bits for the 3+ years now that I have been running on the new hardware with all of the disks being replaced 2 years ago, so I have been making no changes for the past 2 years. All is good for me with ZFS and non-ECC ram.
If I build another system, I will build a new system with ECC RAM and will get new controllers and new cables just because.
My current select is to use ZFS on Linux, because I haven't had a disk array/container that I could hook up to the Macs in the house.
My new ZFS array might end up being Mac Pro based with some of the thunderbolt based disk carriers.
I have about 8TB of stuff that I need to be able to keep safe.
Amazon Glacier is on my radar. At some point I may just get a 4TB USB3.0 drive to copy stuff to and ship off to Glacier.
Gregg
--
---
You received this message because you are subscribed to the Google Groups "zfs-macos" group.
To unsubscribe from this group and stop receiving emails from it, send an email to zfs-macos+...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Daniel Becker
Apr 1, 2014, 12:13:30 AM4/1/14
to zfs-...@googlegroups.com
On Mar 31, 2014, at 7:41 PM, Eric Jaw <nais...@gmail.com> wrote:
I started using ZFS about a few weeks ago, so a lot of it is still new to me. I'm actually not completely certain about "proper procedure" for repairing a pool. I'm not sure if I'm supposed to clear the errors after the scrub, before or after (little things). I'm not sure if it even matters. When I restarted the VM, the checksum counts cleared on its own.
The counts are not maintained across reboots.
On the first scrub it repaired roughly 1.65MB. None on the second scub. Even after the scrub there were still 43 data errors. I was expecting they were going to go away.
errors: 43 data errors, use '-v' for a list
What this means is that in these 43 cases, the system was not able to correct the error (i.e., both drives in a mirror returned bad data).
This is an excellent question. They're in 'Normal' mode. I remember looking in to this before and decided normal mode should be fine. I might be wrong. So thanks for bringing this up. I'll have to check it out again.
The reason I was asking is that these symptoms would also be consistent with something outside the VM writing to the disks behind the VM’s back; that’s unlikely to happen accidentally with disk images, but raw disks are visible to the host OS as such, so it may be as simple as Windows deciding that it should initialize the “unformatted” (really, formatted with an unknown filesystem) devices. Or it could be a raid controller that stores its array metadata in the last sector of the array’s disks.
memtest86 and memtest86+ for 18 hours came out okay. I'm on my third scrub and the number or errors has remained at 43. Checksum errors continue to pile up as the pool is getting scrubbed.
I'm just as flustered about this. Thanks again for the input.
Given that you’re seeing a fairly large number of errors in your scrubs, the fact that memtest86 doesn’t find anything at all very strongly suggests that this is not actually a memory issue.
Jason Belec
Apr 1, 2014, 7:04:39 AM4/1/14
to zfs-...@googlegroups.com
ZFS is lots of parts, in most cases lots of cheap unreliable parts, refurbished parts, yadda yadda, as posted on this thread and many, many others, any issues are probably not ZFS but the parts of the whole. Yes, it could be ZFS, after you confirm that all the parts ate pristine, maybe.
My oldest system running ZFS is an Mac Mini Intel Core Duo with 3GB RAM (not ECC) it is the home server for music, tv shows, movies, and some interim backups. The mini has been modded for ESATA and has 6 drives connected. The pool is 2 RaidZ of 3 mirrored with copies set at 2. Been running since ZFS was released from Apple builds. Lost 3 drives, eventually traced to a new cable that cracked at the connector which when hot enough expanded lifting 2 pins free of their connector counter parts resulting in errors. Visually almost impossible to see. I replaced port multipliers, Esata cards, RAM, mini's, power supply, reinstalled OS, reinstalled ZFS, restored ZFS data from backup, finally to find the bad connector end one because it was hot and felt 'funny'.
Frustrating, yes, educational also. The happy news is, all the data was fine, wife would have torn me to shreds if photos were missing, music was corrupt, etc., etc.. And this was on the old out of date but stable ZFS version we Mac users have been hugging onto for dear life. YMMV
Never had RAM as the issue, here in the mad science lab across 10 rotating systems or in any client location - pick your decade. However I don't use cheap RAM either, and I only have 2 Systems requiring ECC currently that don't even connect to ZFS as they are both XServers with other lives.
Jason Belec
Sent from my iPad
Eric Jaw
Apr 1, 2014, 11:03:37 AM4/1/14
to zfs-...@googlegroups.com
On Tuesday, April 1, 2014 12:07:29 AM UTC-4, Gregg wrote:
The long and the short of it, is that most likely you have a failing disk or controller/connector more than anything. I used to run an 8-disk, 4 mirrored pair pool on a small box without good airflow and slow, SATA-150 controllers that were supported by Solaris 10. I ended up replacing the whole system with a new large box with 140mm fans as well as sata-300 controllers to get better cooling. Over time, every disk has failed because of heat issues. Many of my SATA cables failed too. They were cheap junk.
I have my HDD at a steady 40 degrees or below. I thought about replacing the SATA cables, but I have two of them using new ones and the rest using old ones, and from the checksum errors I'm seeing, it would mean all the cables need replacing, which I don't believe could be the case in this build. A failing disk controller on all four drives that were barely used? I have higher confidence in HDD production than that. I feel certain it's something else, but thank you for your input. I'll keep it as a consideration if all else fails.
I'm running this all through a VM, which is where I believe could be the issue, but we need to figure out why and how to work around it if this is the case.
Equipment has to be selected carefully. I do not see any failing bits for the 3+ years now that I have been running on the new hardware with all of the disks being replaced 2 years ago, so I have been making no changes for the past 2 years. All is good for me with ZFS and non-ECC ram.
That's very good to hear. I'm still trying to gather more data, but I'm getting closer to finding an answer. It seems to point somewhere in the memory realm.
Eric Jaw
Apr 1, 2014, 11:17:52 AM4/1/14
to zfs-...@googlegroups.com
On Tuesday, April 1, 2014 12:13:30 AM UTC-4, Daniel Becker wrote:
On Mar 31, 2014, at 7:41 PM, Eric Jaw <nais...@gmail.com> wrote:I started using ZFS about a few weeks ago, so a lot of it is still new to me. I'm actually not completely certain about "proper procedure" for repairing a pool. I'm not sure if I'm supposed to clear the errors after the scrub, before or after (little things). I'm not sure if it even matters. When I restarted the VM, the checksum counts cleared on its own.The counts are not maintained across reboots.On the first scrub it repaired roughly 1.65MB. None on the second scub. Even after the scrub there were still 43 data errors. I was expecting they were going to go away.errors: 43 data errors, use '-v' for a listWhat this means is that in these 43 cases, the system was not able to correct the error (i.e., both drives in a mirror returned bad data).This is an excellent question. They're in 'Normal' mode. I remember looking in to this before and decided normal mode should be fine. I might be wrong. So thanks for bringing this up. I'll have to check it out again.The reason I was asking is that these symptoms would also be consistent with something outside the VM writing to the disks behind the VM’s back; that’s unlikely to happen accidentally with disk images, but raw disks are visible to the host OS as such, so it may be as simple as Windows deciding that it should initialize the “unformatted” (really, formatted with an unknown filesystem) devices. Or it could be a raid controller that stores its array metadata in the last sector of the array’s disks.
I read about this being a possible issue, so I created a partition for all the drives so Windows see's it as a drive with a partition, rather than unformatted. No raid controller for this setup
memtest86 and memtest86+ for 18 hours came out okay. I'm on my third scrub and the number or errors has remained at 43. Checksum errors continue to pile up as the pool is getting scrubbed.
I'm just as flustered about this. Thanks again for the input.Given that you’re seeing a fairly large number of errors in your scrubs, the fact that memtest86 doesn’t find anything at all very strongly suggests that this is not actually a memory issue.
It very well likely may not be a memory issue. The tricky part of this setup is, it's running through a VM with, what-should-be, direct access to the raw drives. It could be a driver, perhaps that doesn't want to play nice.
I've discovered that with a NAT network, port forwarding does not work properly, so I'm not discarding possible issues with VirtualBox
Eric Jaw
Apr 1, 2014, 11:34:21 AM4/1/14
to zfs-...@googlegroups.com
On Tuesday, April 1, 2014 7:04:39 AM UTC-4, jasonbelec wrote:
ZFS is lots of parts, in most cases lots of cheap unreliable parts, refurbished parts, yadda yadda, as posted on this thread and many, many others, any issues are probably not ZFS but the parts of the whole. Yes, it could be ZFS, after you confirm that all the parts ate pristine, maybe.
I don't think it's ZFS. ZFS is pretty solid. In my specific case, I'm trying to figure out why VirtualBox is creating these issues. I'm pretty sure that's the root cause, but I don't know why yet. So I'm just speculating at this point. Of course, I want to get my ZFS up and running so I can move on to what I really need to do, so it's easy to jump on a conclusion about something that I haven't thought of in my position. Hope you can understand
Jason Belec
Apr 1, 2014, 11:58:09 AM4/1/14
to zfs-...@googlegroups.com
I run over 30 instances of Virtualbox with various OSs without issue all running ontop of ZFS environments. Most of my clients have at least 3 VMs running a variant of Windows ontop of ZFS without any issues. Not sure what you mean with your NAT issue. Perhaps posting your setup info might be of more help.
Jason Belec
Sent from my iPad
Eric
Apr 1, 2014, 12:03:39 PM4/1/14
to zfs-...@googlegroups.com
I have the details on the setup posted to virtualbox's forums, here: https://forums.virtualbox.org/viewtopic.php?f=6&t=60975
Essentially, I'm running ZFS on FreeBSD10 in VBox running in Windows 7. Rather than the other way around. I think I mentioned that earlier
--
---
You received this message because you are subscribed to a topic in the Google Groups "zfs-macos" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/zfs-macos/qguq6LCf1QQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to zfs-macos+...@googlegroups.com.
Jason Belec
Apr 1, 2014, 3:17:38 PM4/1/14
to zfs-...@googlegroups.com
OK. So your running Windows, asking questions on the MacZFS list. That's going to cause problems right out of the gate. And your asking about FreeBSD running under VirtualBox for issues with ZFS.
I know it's not nice, bit I'm laughing myself purple. This is going to make it into my training sessions.
The only advice I can give you at this point is you have made a very complicated situation for yourself. Back up and start with Windows, ensure networking us functions. Then a clean VM of FreeBSD make sure networking is functioning however you want it to. Now setup ZFS where you may have to pre-set/create devices just for the VM to utilize so that OS's are not fighting for the same drive(s)/space.
Jason
Sent from my iPhone 5S
Eric
Apr 1, 2014, 3:46:29 PM4/1/14
to zfs-...@googlegroups.com
haha train away!
This is what I'm trying to do for my own needs. Issues or no issues, I haven't seen it done before. So, I'm reaching out to anyone. Mac or not, I'm just asking from one IT professional to another, is this possible, and if not, why not? (that's just how I feel)Details are in the forum post, but yes, it's a clean setup with a dedicated vdi for the os. Networking shouldn't be related, but it's working as well.
Jason Belec
Apr 1, 2014, 4:13:54 PM4/1/14
to zfs-...@googlegroups.com
I looked through your thread, but I almost always tell people - "STOP using Windows unless its in a VM". ;)
Not enough info in your thread to actually help you with the VM. What are the Guest settings? What drives are actually assigned to what, scripts are only useful after you setup something functional.
As for the NAT issue thread, I don't think its an issue so much a misconception how it works in relation to the parts in question, specifically Windows, the VM and the Guest. I have never really had issues like this but I've never tried with parts your using in the sequence described. As for why it might not work... The Guest settings info might be relevant here as well.
Jason Belec
Sent from my iPad
Eric
Apr 1, 2014, 4:25:58 PM4/1/14
to zfs-...@googlegroups.com
Attached is my vbox Guest settings, and added it to the forums post as well (https://forums.virtualbox.org/viewtopic.php?f=6&t=60975)
The NAT issue is small. I switched my SSH server back to Bridge Mode and everything worked again. There was something about NAT mode where it was breaking the connection and wasn't letting SSH work normally.
Jason Belec
Apr 1, 2014, 5:50:53 PM4/1/14
to zfs-...@googlegroups.com
Going through this bit by bit, but some things that I take issue with but may be interpreting incorrectly.
You created several vmdk's on C: drive (9), your running Windows on this drive, as well as Virtualbox which has an OS making use of the vmdk's, this correct? If yes, we may have stumbled across your issue, thats a lot of i/o for the underlying drive, some of it fighting with the other contenders. You list 6 physical drives, reason they are not utilized? Perhaps just moving the vmdk's to another drive might at least help with the stress.
As an example, I never host the VM on the OS drive, just like I never host ZFS on the OS drive FreeBSD can of course, but I believe attention must be paid to setup) even if I have room for a partition (tried that in the past).
Jason Belec
Sent from my iPad
<ZFS.vbox>
Daniel Becker
Apr 1, 2014, 6:15:08 PM4/1/14
to zfs-...@googlegroups.com
He’s creating “raw” (= pass-through) disk images; i.e., the backing store is a physical disk, not the vmdk file itself.

Bayard Bell
Apr 1, 2014, 7:14:47 PM4/1/14
to zfs-...@googlegroups.com
Could you explain how you're using VirtualBox and why you'd use a type 2 hypervisor in this context?
Here's a scenario where you really have to mind with hypervisors: ZFS tells a virtualised controller that it needs to sync a buffer, and the controller tells ZFS that all's well while perhaps requesting an async flush. ZFS thinks it's done all the I/Os to roll a TXG to stable storage, but in the mean time something else crashes and whoosh go your buffers.
I'm not sure it's come across particularly well in this thread, but ZFS doesn't and can't cope with hardware that's so unreliable that it tells lies about basic things, like whether your writes have made it to stable storage, or doesn't mind the shop, as is the case with non-ECC memory. It's one thing when you have a device reading back something that doesn't match the checksum, but it gets uglier when you've got a single I/O path and a controller that seems to write the wrong bits in stride (I've seen this) or when the problems are even closer to home (and again I emphasise RAM). You may not have problems right away. You may have problems where you can't tell the difference, like flipping bits in data buffers that have no other integrity checks. But you can run into complex failure scenarios where ZFS has to cash in on guarantees that were rather more approximate than what it was told, and then it may not be a case of having some bits flipped in photos or MP3s but no longer being able to import your pool or having someone who knows how to operate zdb do some additional TXG rollback to get your data back after losing some updates.
I don't know if you're running ZFS in a VM or running VMs on top of ZFS, but either way, you probably want to Google for "data loss" "VirtualBox" and whatever device you're emulating and see whether there are known issues. You can find issue reports out there on VirtualBox data loss, but working through bug reports can be challenging.
Cheers,
Cheers,
Bayard
Jason Belec
Apr 1, 2014, 7:24:23 PM4/1/14
to zfs-...@googlegroups.com
I think Bayard has hit on some very interesting points, part of what I was alluding to, but very well presented here.
Jason
Sent from my iPhone 5S

Boyd Waters
Apr 2, 2014, 2:37:51 AM4/2/14
to zfs-...@googlegroups.com
I was able to destroy ZFS pools by trying to access them from inside VirtualBox. Until I read the detailed documentation, and set the disk buffer options correctly. I will dig into my notes and post the key setting to this thread when I find it.
But I've used ZFS for many years without ECC RAM with no trouble. It isn't the best way to,go, but it isn't the lack of ECC that's killing a ZFS pool. It's the hypervisor hardware emulation and buffering.
Sent from my iPad
Eric
Apr 2, 2014, 11:28:21 AM4/2/14
to zfs-...@googlegroups.com
Here's the topography of the Host and Guest system layout
[SSD][SSD]
==> [RAID0]
====> [Host]======> [HHD1] --> \\.\PhysicalDrive1 --> raw vmdk --> PhysicalDrive1.vmdk
======> [HHD2] --> \\.\PhysicalDrive2 --> raw vmdk --> PhysicalDrive2.vmdk
======> [HHD3] --> \\.\PhysicalDrive3 --> raw vmdk --> PhysicalDrive3.vmdk
======> [HHD4] --> \\.\PhysicalDrive4 --> raw vmdk --> PhysicalDrive4.vmdk
======> [HHD5] --> \\.\PhysicalDrive5 --> raw vmdk --> PhysicalDrive5.vmdk
==========> PhysicalDrive0.vmdk
==========> PhysicalDrive1.vmdk
==========> PhysicalDrive2.vmdk
==========> PhysicalDrive3.vmdk
==========> PhysicalDrive4.vmdk
==========> PhysicalDrive5.vmdk
==========> PhysicalDrive2.vmdk
==========> PhysicalDrive3.vmdk
==========> PhysicalDrive4.vmdk
==========> PhysicalDrive5.vmdk
HHD0 and HHD1 are unmounted, NTFS partitioned drives, because they hold a mirror copy of my data
There are two SSDs, SSD0 and SSD1 (not listed), that are created the same way as the HDD, and mounted as zil and l2arc devices.
Eric
Apr 2, 2014, 11:28:42 AM4/2/14
to zfs-...@googlegroups.com
Yes, this is correct
Eric
Apr 2, 2014, 11:47:17 AM4/2/14
to zfs-...@googlegroups.com
All this talk about controller, sync, buffer, storage, cache got me thinking.
I looked up out ZFS handles cache flushing, and how VirtualBox handles cache flushing.ZFS issues infrequent flushes (every 5 second or so) after the uberblock updates. The flushing infrequency is fairly inconsequential so no tuning is warranted here. ZFS also issues a flush every time an application requests a synchronous write (O_DSYNC, fsync, NFS commit, and so on).
According to http://www.virtualbox.org/manual/ch12.html
12.2.2. Responding to guest IDE/SATA flush requests
If desired, the virtual disk images can be flushed when the guest issues the IDE FLUSH CACHE command. Normally these requests are ignored for improved performance. The parameters below are only accepted for disk drives. They must not be set for DVD drives.
I'm going to enable cache flushing and see how that affects results
--
---
You received this message because you are subscribed to a topic in the Google Groups "zfs-macos" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/zfs-macos/qguq6LCf1QQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to zfs-macos+...@googlegroups.com.
Eric
Apr 2, 2014, 11:49:52 AM4/2/14
to zfs-...@googlegroups.com
I believe we are referring to the same things. I JUST read about cache flushing. ZFS does cache flushing and VirtualBox ignores cache flushes by default.
Please, if you can, let me know the key settings you have used.VBoxManage setextradata "VM name" "VBoxInternal/Devices/ahci/0/LUN#[x]/Config/IgnoreFlush" 0
Where [x] is the disk value
--
---
You received this message because you are subscribed to a topic in the Google Groups "zfs-macos" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/zfs-macos/qguq6LCf1QQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to zfs-macos+...@googlegroups.com.
Daniel Becker
Apr 2, 2014, 2:38:05 PM4/2/14
to zfs-...@googlegroups.com
The only time this should make a difference is when your host experiences an unclean shutdown / reset / crash.
Eric
Apr 2, 2014, 3:44:59 PM4/2/14
to zfs-...@googlegroups.com
eh, I suspected that

Matt Elliott
Apr 2, 2014, 6:08:06 PM4/2/14
to <zfs-macos@googlegroups.com>
On Apr 2, 2014, at 1:38 PM, Daniel Becker <razz...@gmail.com> wrote:
> The only time this should make a difference is when your host experiences an unclean shutdown / reset / crash.
>
> On Apr 2, 2014, at 8:49 AM, Eric <nais...@gmail.com> wrote:
Daniel Becker
Apr 2, 2014, 8:37:07 PM4/2/14
to zfs-...@googlegroups.com
On Apr 2, 2014, at 3:08 PM, Matt Elliott <mell...@ncsa.illinois.edu> wrote:
> Not true. ZFS flushes also mark known states. If the zfs stack issues a flush and the system returns, it uses that as a guarantee that that data is now on disk.
However, that guarantee is only needed to ensure that on-disk data is consistent even if the contents of the cache is lost, e.g. due to sudden power loss. A disk cache never just loses dirty data in normal operation.
> Not true. ZFS flushes also mark known states. If the zfs stack issues a flush and the system returns, it uses that as a guarantee that that data is now on disk.
> later writes will assume that the data was written and if the hard drive later changes the write order (which some disks will do for performance) things break. You can have issues if any part of the disk chain lies about the completion of flush commands.
Eric
Apr 3, 2014, 12:03:11 AM4/3/14
to zfs-...@googlegroups.com
I have both my hands up, throwing anything and hoping for something to stick to the wall =\
Philip Robar
Apr 11, 2014, 3:29:23 PM4/11/14
to zfs-...@googlegroups.com
From Andrew Galloway of Nexenta (Whom I'm pretty sure most would accept as the definition of a ZFS expert.*)
ECC vs non-ECC RAM: The Great Debate:
* "...I've been on literally 1000's of large ZFS deployments in the last 2+ years, often called in when they were broken, and much of what I say is backed up by quite a bit of experience. This article is also often used, cited, reviewed, and so on by many of my fellow ZFS support personnel, so it gets around and mistakes in it get back to me eventually. I can be wrong - but especially if you're new to ZFS, you're going to be better served not assuming I am. :)"
Phil
Chris Ridd
Apr 11, 2014, 4:02:57 PM4/11/14
to zfs-...@googlegroups.com
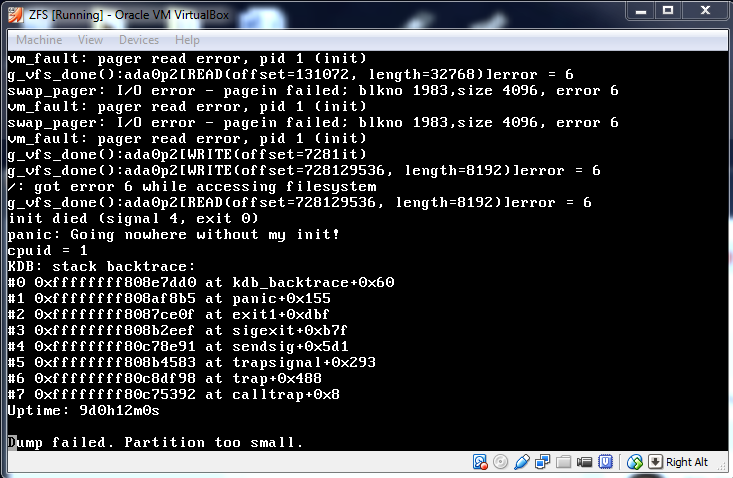
On 11 Apr 2014, at 20:42, Eric <nais...@gmail.com> wrote:
> I don't have a proper dump, but I did get a kernel panic on my ZFS box. This is just informational. I'm not sure what caused it, but I'm guessing it's memory related.
Is ada0 one of your external drives or a vbox virtual disk? How is that disk partitioned and what is using the other partitions?
Chris
Eric
Apr 11, 2014, 4:50:23 PM4/11/14
to zfs-...@googlegroups.com
It's the VDI running FreeBSD on, created by its wizard
$ gpart show -l
=> 34 16777149 ada0 GPT (8.0G)
34 128 1 (null) (64K)
162 15935360 2 (null) (7.6G)
15935522 839680 3 (null) (410M)
16775202 1981 - free - (991K)
$ gpart show -l
=> 34 16777149 ada0 GPT (8.0G)
34 128 1 (null) (64K)
162 15935360 2 (null) (7.6G)
15935522 839680 3 (null) (410M)
16775202 1981 - free - (991K)
Bayard Bell
Apr 11, 2014, 5:09:02 PM4/11/14
to zfs-...@googlegroups.com
If you want more of a smoking gun report on data corruption without ECC, try:
https://blogs.oracle.com/vlad/entry/zfs_likes_to_have_ecc
https://blogs.oracle.com/vlad/entry/zfs_likes_to_have_ecc
This view isn't isolated in terms of what people at Sun thought or what people at Oracle now think. Trying googling for "zfs ecc site:blogs.oracle.com", and you'll find a recurring statement that ECC should be used even in home deployment, with maybe one odd exception.
The Wikipedia article, correctly summarising the Google study, is plain in saying not that extremely high error rates are common but that error rates are highly variable in large-sample studies, with some systems seeing extremely high error rates. ECC gives a significant assurance based on an incremental cost, so what's your data worth? You're not guaranteed to be screwed by not using ECC (and the Google paper doesn't say this either), but you are assuming risks that ECC mitigates. Look at the above blog, however: even DIMMs that are high-quality but non-ECC can go wrong and result in nasty system corruption.
What generally protects you in terms of pool integrity is metadata redundancy on top of integrity checks, but if you flip bits on metadata in-core before writing redundant copies, well, that's a risk to pool integrity.
I also think it's mistaken to say this is distinctly a problem with ZFS. Any "next-generation" filesystem that provides protections against on-disk corruption via checksums ends up with a residual risk focus on making sure that in-core data integrity is robust. You could well have those problems on the pools you've deployed, and there are a lot of situations in you'd never know and quite a lot (such as most of the bits in a photo or MP3) where you'd never notice low rates of bit-flipping. The fact that you haven't noticed doesn't equate to there being no problems in a strict sense, it's far more likely that you've been able to tolerate the flipping that's happened. The guy at Sun with the blog above got lucky: he was running high-quality non-ECC RAM, and it went pear-shaped, at least for metadata cancer, quite quickly, allowing him to recover by rolling back snapshots.
Take a look out there, and you'll find people who are very confused about the risks and available mitigations. I found someone saying that there's no problem with more traditional RAID technologies because disks have CRCs. By comparison, you can find Bonwick, educated as a statistician, talking about SHA256 collisions by comparison to undetected ECC error rates and introducing ZFS data integrity safeguards by way of analogy to ECC. That's why the large-sample studies are interesting and useful: none of this technology makes data corruption impossible, it just goes to extreme length to marginalise the chances of those events by addressing known sources of errors and fundamental error scenarios--in-core is so core that if you tolerate error there, those errors will characterize systematic behaviour where you have better outcomes reasonably available (and that's **reasonably** available, I would suggest, in a way that the Madison paper's recommendation to make ZFS buffers magical isn't). CRC-32 does a great job detecting bad sectors and preventing them from being read back, but SHA256 in the right place in a system detects errors that a well-conceived vdev topology will generally make recoverable. That includes catching cases where an error isn't caught by CRC-32, which may be a rare result, but when you've got the kind of data densities that ZFS can allow, you're rolling the dice often enough that those results become interesting.
ECC is one of the most basic steps to take, and if you look at the architectural literature, that's how it's treated. If you really want to be in on the joke, find the opensolaris zfs list thread from 2009 where someone asks about ECC, and someone else jumps in to remark on how VirtualBox can be poison for pool integrity for reasons rehearsed in my last post.
Cheers,
Bayard
On 1 April 2014 12:04, Jason Belec <jason...@belecmartin.com> wrote:
ZFS is lots of parts, in most cases lots of cheap unreliable parts, refurbished parts, yadda yadda, as posted on this thread and many, many others, any issues are probably not ZFS but the parts of the whole. Yes, it could be ZFS, after you confirm that all the parts ate pristine, maybe.
My oldest system running ZFS is an Mac Mini Intel Core Duo with 3GB RAM (not ECC) it is the home server for music, tv shows, movies, and some interim backups. The mini has been modded for ESATA and has 6 drives connected. The pool is 2 RaidZ of 3 mirrored with copies set at 2. Been running since ZFS was released from Apple builds. Lost 3 drives, eventually traced to a new cable that cracked at the connector which when hot enough expanded lifting 2 pins free of their connector counter parts resulting in errors. Visually almost impossible to see. I replaced port multipliers, Esata cards, RAM, mini's, power supply, reinstalled OS, reinstalled ZFS, restored ZFS data from backup, finally to find the bad connector end one because it was hot and felt 'funny'.Frustrating, yes, educational also. The happy news is, all the data was fine, wife would have torn me to shreds if photos were missing, music was corrupt, etc., etc.. And this was on the old out of date but stable ZFS version we Mac users have been hugging onto for dear life. YMMVNever had RAM as the issue, here in the mad science lab across 10 rotating systems or in any client location - pick your decade. However I don't use cheap RAM either, and I only have 2 Systems requiring ECC currently that don't even connect to ZFS as they are both XServers with other lives.--Jason BelecSent from my iPadOn Mar 31, 2014, at 7:41 PM, Eric Jaw <nais...@gmail.com> wrote:I started using ZFS about a few weeks ago, so a lot of it is still new to me. I'm actually not completely certain about "proper procedure" for repairing a pool. I'm not sure if I'm supposed to clear the errors after the scrub, before or after (little things). I'm not sure if it even matters. When I restarted the VM, the checksum counts cleared on its own.
The counts are not maintained across reboots.On the first scrub it repaired roughly 1.65MB. None on the second scub. Even after the scrub there were still 43 data errors. I was expecting they were going to go away.errors: 43 data errors, use '-v' for a listWhat this means is that in these 43 cases, the system was not able to correct the error (i.e., both drives in a mirror returned bad data).This is an excellent question. They're in 'Normal' mode. I remember looking in to this before and decided normal mode should be fine. I might be wrong. So thanks for bringing this up. I'll have to check it out again.
The reason I was asking is that these symptoms would also be consistent with something outside the VM writing to the disks behind the VM’s back; that’s unlikely to happen accidentally with disk images, but raw disks are visible to the host OS as such, so it may be as simple as Windows deciding that it should initialize the “unformatted” (really, formatted with an unknown filesystem) devices. Or it could be a raid controller that stores its array metadata in the last sector of the array’s disks.memtest86 and memtest86+ for 18 hours came out okay. I'm on my third scrub and the number or errors has remained at 43. Checksum errors continue to pile up as the pool is getting scrubbed.
I'm just as flustered about this. Thanks again for the input.Given that you’re seeing a fairly large number of errors in your scrubs, the fact that memtest86 doesn’t find anything at all very strongly suggests that this is not actually a memory issue.
--
---
You received this message because you are subscribed to the Google Groups "zfs-macos" group.
To unsubscribe from this group and stop receiving emails from it, send an email to zfs-macos+...@googlegroups.com.
Daniel Becker
Apr 11, 2014, 5:14:43 PM4/11/14
to zfs-...@googlegroups.com
So to summarize that article, "using ECC memory is safer than not using ECC memory." I don't think this was ever in doubt. Note that he does *not* talk about anything like the hypothetical "a scrub will corrupt all your data" scenario (nor is anything like that mentioned in his popular "ZFS: Read Me 1st" article); in fact, the only really ZFS-specific point that he raises at all is the part about dirty data likely being in memory (= vulnerable to bit flips) for longer than it would be in other file systems.
Jason Belec
Apr 11, 2014, 5:36:11 PM4/11/14
to zfs-...@googlegroups.com
Excellent. If you feel this is necessary go for it. Those that have systems that don't have ECC should just run like the sky is falling by your point view. That said, I can guarantee non of the systems I have under my care have issues. How do I know? Well the data is tested/compared at regular intervals. Maybe I'm the luckiest guy ever, where is that lottery ticket. Is ECC better, possibly, probably in heavy load environments, no data has been provided to back this up. Especially nothing in the context of what most users needs are at least here in the Mac space. Which ECC? Be specific. They are not all the same. Just like regular RAM are not all the same. Just like HDDs are not all the same. Fear mongering is wonderful and easy. Putting forth a solution guaranteed to be better is what's needed now. Did you actually reference a wiki? Seriously? A document anyone can edit to suit there view? I guess I come from a different era.
Jason
Sent from my iPhone 5S
Eric
Apr 11, 2014, 5:58:28 PM4/11/14
to zfs-...@googlegroups.com
Thanks! I will definitely take this out with my afternoon tea for a read C:
--
---
You received this message because you are subscribed to a topic in the Google Groups "zfs-macos" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/zfs-macos/qguq6LCf1QQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to zfs-macos+...@googlegroups.com.
Eric
Apr 11, 2014, 6:00:39 PM4/11/14
to zfs-...@googlegroups.com
Interesting point about different kinds of ECC memory. I wonder if the difference is important enough to consider for a 20x3TB ZFS pool. For the sake of sakes, I will likely look into getting ECC memory.
--
---
You received this message because you are subscribed to a topic in the Google Groups "zfs-macos" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/zfs-macos/qguq6LCf1QQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to zfs-macos+...@googlegroups.com.
Bayard Bell
Apr 12, 2014, 6:26:48 AM4/12/14
to zfs-...@googlegroups.com
Jason,
Cheers,
Bayard
Jason Belec
Apr 12, 2014, 6:44:53 AM4/12/14
to zfs-...@googlegroups.com
Hhhhmmmmm, oh I get it, you have zero knowledge of the platform this list represents. No worries, appreciate your time clearing that up.
Jason Belec
Sent from my iPad
Bayard Bell
Apr 12, 2014, 7:46:34 AM4/12/14
to zfs-...@googlegroups.com
Jason,
I don't understand why you've decided to invest so much in arguing that ECC is so completely marginal a data integrity measure that you can't have a reasonable discussion about what gets people to different conclusions and feel the need to be overtly dismissive of the professionalism and expertise of those who come to fundamentally different conclusions, but clearly there's not going to be a dialogue on this. My only interest in posting at this point is so that people on this list at least have a clear statement of both ends of the argument and can judge for themselves.
Regards,
Bayard

Peter Lai
Apr 12, 2014, 1:29:05 PM4/12/14
to zfs-...@googlegroups.com
It sounds like people are missing the forest for the trees. Some of us
have been successfully RAIDing/deploying storage for years on
everything from IDE vinum to SCSI XFS and beyond without ECC. We use
ZFS today because of its featureset. Data integrity checking through
checksumming is just one of those features which would have mitigated
some issues that other file systems have historically failed to do.
(Otherwise we should all be happy with existing journaling filesystems
on a soft or hard RAID). ECC just adds another layer of mitigation
(and even in a less-implementation-specific way like how ZFS may
'prefer' raw device access instead of whatever storage abstraction the
controller is presenting). Asserting that ECC is "required" has about
the same logic to it (and I would say less logic to it) than asserting
a 3ware controller with raw jbod passthrough is "required".
On Sat, Apr 12, 2014 at 7:46 AM, Bayard Bell
have been successfully RAIDing/deploying storage for years on
everything from IDE vinum to SCSI XFS and beyond without ECC. We use
ZFS today because of its featureset. Data integrity checking through
checksumming is just one of those features which would have mitigated
some issues that other file systems have historically failed to do.
(Otherwise we should all be happy with existing journaling filesystems
on a soft or hard RAID). ECC just adds another layer of mitigation
(and even in a less-implementation-specific way like how ZFS may
'prefer' raw device access instead of whatever storage abstraction the
controller is presenting). Asserting that ECC is "required" has about
the same logic to it (and I would say less logic to it) than asserting
a 3ware controller with raw jbod passthrough is "required".
On Sat, Apr 12, 2014 at 7:46 AM, Bayard Bell

Rob Lewis
Apr 12, 2014, 8:47:41 PM4/12/14
to zfs-...@googlegroups.com
I have no dog in this fight, but I wonder if possibly the late discovery of the need for ECC was a factor in Apple's abandoning the ZFS project. Unlikely they'd want to reengineer all their machines for it.
Richard Elling
Apr 12, 2014, 9:08:39 PM4/12/14
to zfs-...@googlegroups.com
On Apr 12, 2014, at 5:47 PM, Rob Lewis <grob...@gmail.com> wrote:
I have no dog in this fight, but I wonder if possibly the late discovery of the need for ECC was a factor in Apple's abandoning the ZFS project. Unlikely they'd want to reengineer all their machines for it.
I believe the answer is a resounding NO. If they truly cared about desktop data corruption
they would have punted HSF+. Desktop is as desktop does and Apple is out of the server
business.
FYI, Microsoft requires ECC for Windows server certification.
-- richard

Michael Newbery
Apr 13, 2014, 12:34:27 AM4/13/14
to zfs-...@googlegroups.com
On 13/04/2014, at 12:47 pm, Rob Lewis <grob...@gmail.com> wrote:
I have no dog in this fight, but I wonder if possibly the late discovery of the need for ECC was a factor in Apple's abandoning the ZFS project. Unlikely they'd want to reengineer all their machines for it.
I do not know, and am therefor free to speculate :)
However, rumour hath it that Apple considered the patent/licence situation around ZFS to be problematic. Given the current litigious landscape, this was not a fight that they were willing to buy into. Note that the patent problem also threatens btrfs.
You might discount the magnitude of the threat, but on a cost/benefit analysis it looks like they walked away.
Likewise, some of the benefits and a lot of the emphasis of ZFS lies in server space, which is not a market that Apple is playing in to any great extent. It's not that ZFS doesn't have lots of benefits for client space as well, but the SUN emphasis was very much on the server side (which Oracle only emphasises).
Now, with the OpenZFS model and in particular the options ("We'll support a,b and t, but not c or e") it's possible they might revisit it sometime (why yes, I am an incurable optimist. Why do you ask?) but I suspect they are more interested in distributed file systems a.k.a. the cloud.
--
Michael Newbery
"I have a soft spot for politicians---it's a bog in the west of Ireland!"
Dave Allen

Chris Inacio
Apr 19, 2014, 12:15:24 PM4/19/14
to zfs-...@googlegroups.com
This has been quite the interesting thread. Way back long ago when I was dong graduate work in microarchitecture (aka processor design) there were folks who wanted to put an x86 processor in a satellite. x86, especially at the time, was totally NOT qualified for use in space. The Pentium chip (way back) had this really cool feature, that a single bit flip (e.g. transient fault from alpha particle strike) would deadlock the processor cold. If the correct bit in the reservation queue got toggled.
Daniel Jozsef
May 1, 2014, 2:04:31 PM5/1/14
to zfs-...@googlegroups.com
You know, you remind me of my Computer Architectures lecturer. Considered a weird guy university-wide, he had these funny maxims like "a PC is not a computer" and "Windows is not an Operating System".
Back then, I kind of saw what he meant, but the funny part is that nowadays, it's as if his school of thought is being obsoleted by the reality around us. It's kind of valid to say that x86 chips are not "proper", but the reality is that 95% of the Internet runs on the bloody things. Back twenty years ago, there were things like SPARC servers, Silicon Graphics workstations, and all. Now? It's all just PCs. PCs that fit in your handbag, PCs that fit under your desk, PCs that fit in a server rack. It's still just PCs.
Your credit card transactions are run on PCs. Your bank uses PCs to handle accounting. Investment banks use PCs to run billion-dollar IPOs. Facebook runs on PCs. Google runs on PCs.
Apparently, PCs ARE good enough for the "powers that be". Regardless whether the ALU is protected or not. (Though I think it should be, with all the innovation Intel has been doing.)
Eric
May 2, 2014, 10:52:37 AM5/2/14
to zfs-...@googlegroups.com
@ChrisInacio
THAT'S THE COOLEST THING I LEARNED TODAY :D
THAT'S THE COOLEST THING I LEARNED TODAY :D
--
---
You received this message because you are subscribed to a topic in the Google Groups "zfs-macos" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/zfs-macos/qguq6LCf1QQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to zfs-macos+...@googlegroups.com.

{kind=link}
Bu Jin
Mar 3, 2016, 10:55:45 AM3/3/16
to zfs-macos
Chris:
I'm pretty sure that the X86 architecture has had ALU error correction for a while now. I know my AMD X2s had L1 and L2 ECC, and I think the ALU was protected (though I wouldn't swear to that). However, looking at an Intel white paper on the Xeon E7 family reliability features it says: "E7 family provides
internal on-die error protection to
protect processor registers from
transient faults, and enables dynamic
processor sparing and migration in the
case of a failing processor." In fact the over all architecture looks like it robustness was a top priority concern. If you'd like to read the paper you can find it here: http://www.intel.com/content/dam/www/public/us/en/documents/white-papers/xeon-e7-family-ras-server-paper.pdf
Bu Jin
Mar 3, 2016, 12:56:16 PM3/3/16
to zfs-macos
Hi Phil,
I know this is an old thread, but I didn't see where you ever got word back from the Open ZFS dev team, and this is an issue I feel needs to be address. I am a software engineer, and I have many years of experience working with ZFS. Though admittedly I have not worked on ZFS development myself, but I am familiar with the sort of data structures and processes used by ZFS. I'm very skeptical of this idea of "ZFS cancer" as I would call it, where ZFS's self-healing routines become poisonous and start corrupting the entire filesystem due to a data error which occurs in memory. Now this is a very complicated subject, because there is a lot to take into consideration, but let us consider only the data for a moment. ZFS uses an implementation of what in Computer Science is called a self validating Merkle tree, where each node is validated by a hash from it's parent node all the way back up to the uberblock (the root node) which is then duplicated else where.
The proposed cancer scenario is that there is an in memory error which affects the data in question and in return causes a check sum invalidation to occur, and so ZFS starts self-healing, and writing the corrupted data all over the system. However, this is not how this works. Before ZFS corrects a single block of corrupted data, it first finds a validated copy. That means there has to be redundant data. If you are running ZFS on a single drive in a standard configuration, without block duplication or a split volume, you only have one copy of data, which means self-healing doesn't even turn on. Now let's assume you are running a mirror, or Raidz-1,2,3, where you have duplicate data, and ZFS detects data corruption due to a hash failure. Before ZFS starts healing itself it will try to find a valid copy of the data, by looking at the redundant data and doing hash validation on it. The data must pass this hash validation in order to be propagated. So now you need a second failure where the redundant data is also wrong, BUT MORE OVER the data has to also pass the validation which would require a hash collision (a collision is where you have different data that hashes to the same value). The odds of this are astronomical!!! But assuming you have a check sum failure, which triggers a self-healing operation, which then finds a corrupted piece of data which also managed to pass the hash check, then yes, it would replicate that data. However, it would only replicate the error for that one block! ...because every block is hashed individually. Hardly destroying your entire data set! So it would take a gross set of improbabilities for ZFS to decide to corrupt the single block containing your 32nd picture of Marilyn Monroe. If ZFS was going to corrupt a second block we'd have to repeat all of this!
The above is assuming errors in the data itself the MORE LIKELY case to succeed, if you can believe it. Now lets assume an error in the hash. Well each hash is hashed against it's parent node. So the faulty hash sum would need a hash collision with it's parent node's hash! That is especially difficult, because there are fewer possible collisions in a 1:1 relationship than in say a 1:100 relationship. But even assuming some how you manage to have a successful collision, you still fall back into the above scenario, where you now need to find data that successfully matches the hash, so you now need a second collision! ...and again, that's for a single block of data! That's to say nothing the fact that you will have a hash mismatch between the original corrupted hash, and the hash of the prospective replacement data. So the system will realize at that point there is a problem, and will move to into tie breaker routines in order to sort out the issue. I don't even see a path where this ultimately manages to propagate.
You see how this runaway cancer scenario starts out as statistically untenable and only becomes more and more difficult as you go? Because the odds of ZFS corrupting the very first block are utterly remote, but the odds of it happening a second time are even worse, and so on.
I've read a fair amount of this thread and a lot of stuff has been thrown around which seems poorly understood. Like someone mentioned Jeff Bonwick's comments on SHA256. However, these comments are really tried to the deduplication feature (which I highly recommend not using unless you have a VERY good reason to) where you have data validation disabled (where ZFS checks to make sure duplicates are actually duplicates instead of simply going off of the hash). SHA256 is extreme over kill for block level validation, in fact MD5 would be extreme over kill, which is why the original ZFS implementations used CRC (if I remember correctly, it's been a while), though not I believe ZFS defaults to fletcher (fletcher4?). However, if you were to use SHA256 (which you can specify) all of the above becomes multiple orders of magnitude more remote!
Ok, so that address all of the data related corruption problems. Let's say you have a memory error (be in the system RAM, CPU cache, the ALU registers, etc) that actually affects ZFS's algorithms and routines themselves.
Ok, so that address all of the data related corruption problems. Let's say you have a memory error (be in the system RAM, CPU cache, the ALU registers, etc) that actually affects ZFS's algorithms and routines themselves.
1) Unless the error is not transient, and is affecting a choke point such as the ALU registers, it's extremely unlikely that of all of the data somewhere in memory that it would be the ZFS code that would be affected.
2) Assuming that the ZFS code was affected, in the most likely case the error would be caught by an error handler and dealt with accordingly.
3) Assuming the error got past the in built error detection and handling code, it is most likely the code would be affected in some way that would simply cause a process failure.
4) But let's assume the error gets past all of the above considerations and actually causes ZFS to perform operations outside of spec. Such as bypassing hash validation, this means the validation code would never be triggered, thus the self-healing would never take place! So even though the system would then be vulnerable to new errors coming it, it wouldn't be replicating them. Again, even if the system wanted to replicate errors it would be on a block by block basis. You'd have to have massive coordinated errors to the ZFS routines for it to go into a run away destroy the data condition, but then similar failures could happen to any system process (processes that aren't anywhere nearly as hardened, and for which constitute a larger mount memory usage, and thus a larger threat vector). It's actually more likely that some other piece of software would be corrupted in such a way as to tell ZFS to do bad things, such as delete this or that, or pass ZFS bad data to start with. Say you're working on editing a picture and it's corrupted while in the editor and you save, well obviously ZFS won't fix that. Or say that you are accessing data via samba, well if samba hands ZFS corrupt data, ZFS won't fix that. There are so many ways corrupted data could be handing to ZFS that ZFS would just see as data. Like say the data is corrupted while it's crossing the network, where all you have to do is get back the relatively weak TCP safe guards (which uses CRC). (Though honestly TCP is pretty darn safe, which should really say something about how much better ZFS is!) ZFS's fail safes only kick in AFTER ZFS has the data, so any corruption created by the system's use of the data wouldn't be protected against. This is where the data corruption happens in most cases.
Really, not only is ZFS not more dangerous under unprotected memory conditions, ZFS is in fact a more secure file system under all use cases, included unprotected memory. ZFS does provide for corruption resistance, even from memory errors, ASSUMING the corruption takes place while ZFS is safe guarding the data (if the corruption happens else where in the system, and then it's passed back to ZFS, ZFS will simply see it as an update). Because of ZFS multistep data validation process, ZFS is less likely to get into a runaway data destruction condition than other filesystems approaches, which don't have those steps which must be traversed before writes occur. Further, because of ZFS's copy-on-write nature, even if ZFS did get into such a state, recovery is MUCH easier (especially if prudent safe guards are established) because ZFS isn't going to write over the block in question, and so the data is still there to be recovered. As an aside: I have found myself in truly nasty positions using ZFS beta code, where I ended up with a corrupted pool (I was working with early deduplication code), and still managed to recover the data! ZFS's built in data recover tools are truly extraordinary!
With all of that said, if you are building a storage server, where the point is to store data, and you are selecting ZFS specifically for it's data integrity functionality, you are crazy if you don't buy ECC memory, because you need to not only protect ZFS, but all of the surrounding software. Because, as noted above, external software can corrupt data, and when it is handed back to ZFS it will look like regular data. Also, this improves over all system reliability. ...and ECC memory isn't that expensive
Really, not only is ZFS not more dangerous under unprotected memory conditions, ZFS is in fact a more secure file system under all use cases, included unprotected memory. ZFS does provide for corruption resistance, even from memory errors, ASSUMING the corruption takes place while ZFS is safe guarding the data (if the corruption happens else where in the system, and then it's passed back to ZFS, ZFS will simply see it as an update). Because of ZFS multistep data validation process, ZFS is less likely to get into a runaway data destruction condition than other filesystems approaches, which don't have those steps which must be traversed before writes occur. Further, because of ZFS's copy-on-write nature, even if ZFS did get into such a state, recovery is MUCH easier (especially if prudent safe guards are established) because ZFS isn't going to write over the block in question, and so the data is still there to be recovered. As an aside: I have found myself in truly nasty positions using ZFS beta code, where I ended up with a corrupted pool (I was working with early deduplication code), and still managed to recover the data! ZFS's built in data recover tools are truly extraordinary!
With all of that said, if you are building a storage server, where the point is to store data, and you are selecting ZFS specifically for it's data integrity functionality, you are crazy if you don't buy ECC memory, because you need to not only protect ZFS, but all of the surrounding software. Because, as noted above, external software can corrupt data, and when it is handed back to ZFS it will look like regular data. Also, this improves over all system reliability. ...and ECC memory isn't that expensive
Bu Jin
Mar 21, 2016, 2:46:06 AM3/21/16
to zfs-macos
Apparently one of the devs did comment on this subject. Matthew Ahrens, one of the cofounders of ZFS at Sun Microsystems, stated, “There’s nothing special about ZFS that requires/encourages the use of ECC RAM more so than any other filesystem.” He said it on an Arstechnica forum: http://arstechnica.com/civis/viewtopic.php?f=2&t=1235679&p=26303271#p26303271
Reply all
Reply to author
Forward
0 new messages