split_libraries_fastq.py - filtering
83 views
Skip to first unread message

Becks
Aug 6, 2017, 8:38:38 PM8/6/17
to Qiime 1 Forum
Aloha,
I am running a 16S data set using QIIME 1.9.1 (latest version of MacQIIME) and trying to understand exactly what is being filtered out. We had a not so great Illumina run (53% of the sequences were tossed out right off the machine due to over clustering and not written to the raw data fastq files). But this is a prelim data set, so I have been analyzing it anyway. For a given sample, I am starting with ~ 70,000 sequences, and after using split_libraries_fastq.py, for all 20 samples the sequences written are roughly ~ 5,000. This is a considerable reduction, which may be appropriate based on the quality of the data, but I wanted to double check that I have the parameters correct.
Here is the command I used for the quality filtering (these were already demultiplexed files):
split_libraries_fastq.py -i RDP_2.fastq,RDP_6.fastq,RDP_10.fastq,RDP_13.fastq,RDP_8.fastq,RDP_12.fastq,RDP_7.fastq,RDP_19.fastq,RDP_18.fastq,RDP_9.fastq,RDP_3.fastq,RDP_20.fastq,RDP_15.fastq,RDP_5.fastq,RDP_17.fastq,RDP_16.fastq --sample_ids RDP_2,RDP-6,RDP_10,RDP_13,RDP_8,RDP_12,RDP_7,RDP_19,RDP_18,RDP_9,RDP_3,RDP_20,RDP_15,RDP_5,RDP_17,RDP_16 -o split_libraries_lava_caves/ -q 19 --barcode_type 'not-barcoded'
That means that I left the defaults for -r --max_bad_run_length = 3; -p, --min_per_read_length_fraction = 0.75, -n, --sequence_max_n = 0. I am not clear on what the -r and -p really mean perhaps?
The only parameter I changed was -q (Q-score) which I set at 19. Previously, when working with 454 data, you could set the length of the sequences min and max, as well as the quality score.
The median length of the sequences were 441 bp, but it varies slightly from sample to sample (441-446 for example). These are PE 300 cycle run, and joined paired ends.
I could use some guidance as I want to make sure that sequences with a lower Q-socre than 20 are being removed, as well as reads that are too long and too short.
I have also run this data set in the new EDGE platform from Los Alamos National Lab (there is a QIIME application within it). You can set the -p value, -q, max number of "N" - but EDGE output for split_libraries.py generates 20-30K sequences written after quality filtering, even if I set the parameters I can control to the same ones in QIIME.
Any help or suggestions appreciated.
Cheers
Becks

Colin Brislawn
Aug 7, 2017, 2:07:47 PM8/7/17
to Qiime 1 Forum
Hello Becks,
Thank you for telling me more,
Thanks for getting in touch with us. There are many things that can subtly change the output of quality filtering, even when working with 'normal' data. You mentioned that this MiSeq run had problems, and this could introduce more strange results.
I appreciate all the detail you provided in your post. These could help us identify sources of variation. You didn't mention your settings for joining these reads, and these settings could also have a large effect. Actually, given that join_paired_ends.py is run before split_libraries_fastq.py, pairing could be even more significant!
I saw a presentation on EDGE a few days ago, and I think that joining is included in the qiime workflow. This could contribute greatly to the increase in quality and increase in number of reads produced by EDGE.
Thank you for telling me more,
Colin
Becks
Aug 7, 2017, 3:11:31 PM8/7/17
to Qiime 1 Forum
Aloha,
Yes, joining (I believe from the join_piared_ends.py) is in the EDGE workflow and you have no access to it - its in the script logs though.
In my QIIME workflow, I used multiple_join_paired_ends.py, with all default settings (I just had an output and input directory). I did this before split libraries of course. I have noticed that with the “multiple” anything commands versus the regular command for a function (i.e. join_paired_ends.py) the settings are in the -p (parameters), and I did not change that. If there are best practices for joining ends, please educate let me know. Illumina data still annoys me that you have to join the ends to get a decent length of sequence, so I may be overlooking a detail there, and unaware of the nuances of joining paired ends.
Thanks for the help. I have been using QIIME for years, but with new tech means new bioinformatics, so its always changing seems like. Ready for MinION data yet?? “) I just want to figure it out, especially if I am doing something incorrect in the pipeline. My workflow was multiple_join_paired_ends.py (all default settings), and then split_libraries_py with -q at 19, “not barcoded" (all other settings at default). This generated a considerable drop in number of sequences (roughly 60K to 5K in general) per sample. This may be correct for the data - my good friend at the sequencing lab told me that I might really see the trouble with the quality of the sequences generated. But…I do hold the LANL team in high regard, so I would expect that the pipeline in EDGE would be pretty good…so was surprised at the huge difference. :)
I do not see the join_paired_ends.py commands in the master log from EDGE, but here is an example of the output in the split_libraries_log.txt:
Input file paths Sequence read filepath: /panfs/biopan02/scratch/edge-workshop/edge_ui/EDGE_output/a5115f6bcaf8085316c7f0b6cdcd5623/QiimeAnalysis/fastq-join_joined/pair3/fastqjoin.join.fastq (md5: d1e08dd3f67734244a92304b875db4ad) Quality filter results Total number of input sequences: 85612 Barcode not in mapping file: 0 Read too short after quality truncation: 2340 Count of N characters exceeds limit: 57124 Illumina quality digit = 0: 0 Barcode errors exceed max: 0
You can see that they are using join_paired_ends…in some fashion! I don’t expect you guys to know what EDGE did - I can bug the LANL team about that. :) But, if I am doing something that is not the best practice in the QIIME pipeline, would be good to know. :)
The Illumina data was below specs for a 600 cycles (PF ~43%) and when I looked at the images of the flow cell and other quality specs in BaseSpace, there was both pretty severe over clustering, and what looked like under-clustering too. There was an issue with the library prep, and the lab is re-running the data, but…its prelim for a proposal, so I need to use it, and want to get the most out of it.
Please let me know if that helps and if you need any further info.
Cheers
Becks
Colin Brislawn
Aug 7, 2017, 3:44:44 PM8/7/17
to Qiime 1 Forum
Hello Becks,
Thanks for telling me more. I think we are on the right track!
I'm glad that both the EDGE pipeline and your own pipeline are making use of Illumina paired ends. While this is an extra step over 454 or IonTorrent, the area of overlap allows us to identify and correct errors in these amplicons. This error correction dramatically increases quality, especially for shorter amplicons in which most of the read overlaps.
What region did you amplify? Maybe 16S v3-v5? How long do you expect your amplicons to be?
...6cdcd5623/QiimeAnalysis/fastq-join_joined/pair3/...
Looks like EDGE uses fastq-join, a program that's part of EA-utils that qiime also uses to join ends. IDK if they use the qiime script, or call fastq-join directly.
If the quality of the reads is very low, choosing better settings for joining may keep more of your reads.
Are you losing more reads during joining or during filtering?
You can check by using these commands that count the number of reads in the file:
cat example.fastq | grep ^@ | wc -l
cat example.fasta | grep ^\> | wc -l
Colin
PS. Ah, the fabled MinION. See now, I'm hoping MinION will solve metagenomics so we can all move on to transcriptomics and proteomics.
PPS. You probably already know this, but under_scores_in_sample_names can mess up some qiime scripts. Might want to change those.
Becks
Aug 8, 2017, 5:08:26 AM8/8/17
to Qiime 1 Forum
Aloha,
What region did you amplify? Maybe 16S v3-v5? How long do you expect your amplicons to be?
The lab used a standard protocol for MiSeq 16S amplicon sequencing that covered the V3-V4 region, with an expected 460 bp single amplicon. It supposedly should give the full V3-V4 region with overlapping regions. For all samples, we had less than 100,000 reads per sample, which is lower than the protocol expected (and these are diverse biofilm mat and estuary samples).
16S Amplicon PCR Forward Primer = 5' TCGTCGGCAGCGTCAGATGTGTATAAGAGACAGCCTACGGGNGGCWGCAG
16S Amplicon PCR Reverse Primer = 5' GTCTCGTGGGCTCGGAGATGTGTATAAGAGACAGGACTACHVGGGTATCTAATCC
Are you losing more reads during joining or during filtering?
I will let you decide which one is losing more! :) I have attached an excel spreadsheet with the R1,R2, joined_input sequences (to split_libraries), and the written sequences. In both the QIIME run and the EDGE run, the number of input sequences are the same, so they are using the same settings as I did for joining paired ends. However, the number of sequences written after split_libraires.py is different. I set the EDGE parameters the same that I can access (I did an earlier run that set the min length fraction at 0.50 and that produced a huge number more of sequences written for each sample).
I have also attached the split_libraries.py log files from both my QIIME run and EDGE run.
Ah, the fabled MinION. See now, I'm hoping MinION will solve metagenomics so we can all move on to transcriptomics and proteomics.
Yes! That would be nice indeed - we could just get to the magic, sample in the sequencer = whole genome sequenced in one piece. :) We are working with MinION in our lab, and so far, its not bad. Has some bumps, but I think its the way forward.
Thanks again for any assistance. Just want to optimize me! :) This may be more info than you wanted but, hopefully useful.
Cheers
Becks
Colin Brislawn
Aug 8, 2017, 12:34:51 PM8/8/17
to Qiime 1 Forum
Hello Becks,
Thanks for telling me more. Your 300 bp Illumina reads should be able to cover the 460 bp with plenty of overlap, so that shouldn't be the issue.
I think the issue is in split_libraries_fastq after all. Take a look at the top of your log file. These two lines jumped out at me.
Total number of input sequences: 48499 Count of N characters exceeds limit: 41976 Total number seqs written 5095
So somewhere in your read, there is 1 or more 'N's and qiime is simply removing the full read. I should have seen this in the initial log file you posted from the EDGE server.
To fix this, you could try accepting sequences with additional Ns using --sequence_max_n = 5.
I hope this helps,
Colin
Becks
Aug 8, 2017, 6:08:14 PM8/8/17
to Qiime 1 Forum
Aloha,
yes, I noticed that too in the log, but the EDGE log does not have as large a loss of sequences as the QIIME log, and the "max N base" was set at zero in EDGE, which is the default in QIIME - from my understanding?
If I increase the N, then I am accepting reads of less quality correct? I guess my question is, what are the best practices? I know every data set is different, but we all try to follow similar pipelines. That is why I stick to the default settings often in QIIME.
Can you make any recommendation here?
Cheers
Becks
Colin Brislawn
Aug 8, 2017, 10:18:59 PM8/8/17
to Qiime 1 Forum
Hello Becks,
Lots of great questions here. Let me see if I can get them all.
If I increase the N, then I am accepting reads of less quality correct?
Correct. The basic tradeoff is between fewer high-quality reads or more medium-quality reads.
I guess my question is, what are the best practices? I know every data set is different, but we all try to follow similar pipelines. That is why I stick to the default settings often in QIIME.
I see folks use all kinds of settings. As long as you report everything in methods, you can do change all these settings.
Can you make any recommendation here?
Yes! Sometimes Illumina reads are kind of low quality at the very start or very end. If this is true, you could trim out this low quality section (which might have the Ns!) then use the default settings for quality filtering. This would let you keep most reads, and also remove low quality regions.
If you want to start this process, you first need to get a graph of quality (Q or phred scores) or expected error (ee) across your read so see which sections are high or low quality. This will tell you where to trim. Several programs including vsearch and fastq-qc do this very well.
Let me know what you find,
Colin
Becks
Aug 22, 2017, 2:54:33 AM8/22/17
to Qiime 1 Forum
Aloha,
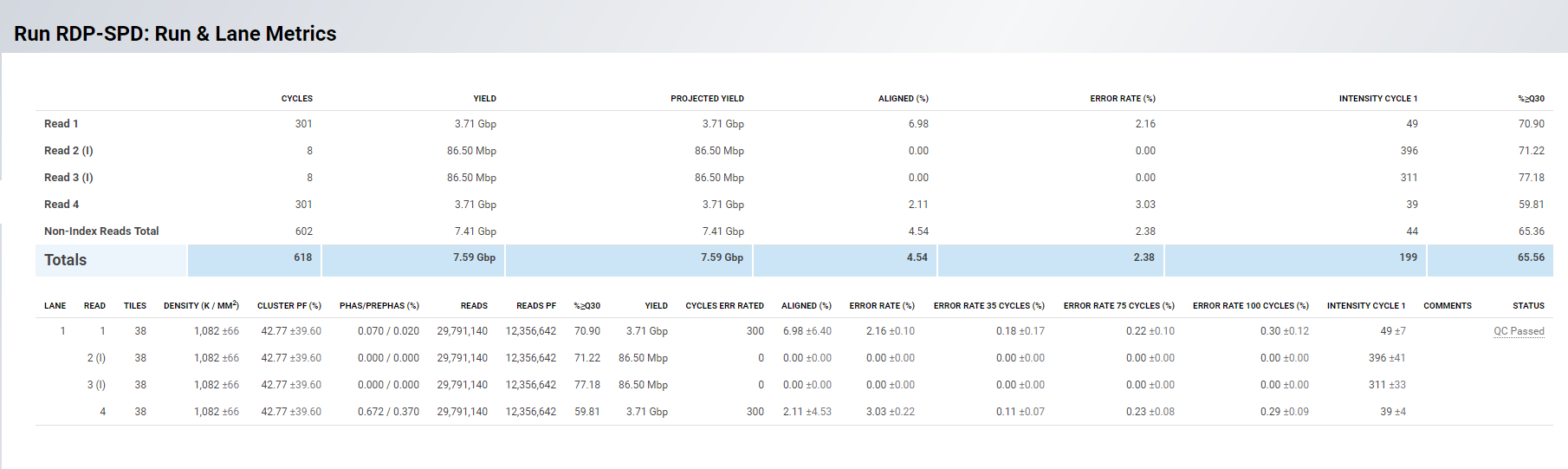
Thanks for the advice. Sorry for the delay - I have taken a look at the FastQC website and the “good” vs. bad Illumina runs. I have looked at a number of the files. An example of one of the reports in given below (RDP-2) and then another from a previous run that I thought was pretty good (RP.36). See attached. Any help on interpreting what might be the problem with the first run (RDP-2) would be great. I see that we could do a little bit of trimming but the Q-scores for the sequences seem to be pretty low overall?? Cheers
Becks
Aug 22, 2017, 3:00:55 AM8/22/17
to Qiime 1 Forum
Aloha again,
By the way, I don't know if it matters, but...these are environmental samples. RDP-2 is from a lava cave (so somewhat complex community), and the second is from estuary sediments (RP.36), so a VERY complex community. Just in case that's important. And I have attached the output from the MiSeq run.
Thanks again so much for help and education! :)
Cheers
Becks
{kind=link}
Colin Brislawn
Aug 22, 2017, 12:41:01 PM8/22/17
to Qiime 1 Forum
Hello Becks,
Thanks for telling me more about your samples. While both of these runs look like are medium quality throughout, two things about RDP-2 stood out.
1.) Near the end of RDP-2 the quality is pretty low.
2.) Near the start of RDP-2, the quality is extremely low around bp 5. The q score is low here, and also about 25 % of the reads have an N at this location.
Remember when we found this line in the split_libraries log file?
Count of N characters exceeds limit: 41976
Looks like we found where the N was hiding!
What would you like to do next? Are you still trying to preserve more reads?
Colin
Becks
Aug 22, 2017, 10:27:17 PM8/22/17
to Qiime 1 Forum
Aloha,
These are just a couple of the samples of course, but they all looked pretty similar. I tried running in both QIIME and EDGE with a higher N value (N=3), to keep more sequences. That did not change things too much. What does greatly increase the number of sequences (reads) retained is if I change the -p, --min_per_read_length_fraction from 0.75 (the default) to 0.5. Can you explain that parameter a bit? Clearly, its keeping reads with lower quality, in some way, but not sure I understand exactly.
Big question: from the data you have, is this simply that trimming is required to retain high quality reads (reducing length of sequences), and that is normal (whatever normal is eh?!). Or, is this a situation where a re-run of the data would be beneficial? Should I just trim at say bp 10? It depends on the sample, as to where the N's are somewhat, but they are higher at the ends of course.
I guess I am not sure what caused this problem in the first place. For example, if you look at the per tile sequence quality, we had a lot of over clustering or under clustering (also seen in the BaseSpace reports), and the per base sequence content is all over the map! My understanding, from FASTQC website, and from EDGE metagenomic runs I have, those should be a lot closer to a straight line for each nucleotide. :)
These data are needed to try and determine diversity in these communities for metagenomic runs, what sequencing depth we need to cover the community and some specific genes we are looking for.
Sorry for all the questions, just trying to learn and understand.
Cheers
Colin Brislawn
Aug 23, 2017, 12:25:48 PM8/23/17
to Qiime 1 Forum
Hello Becks,
The full documentation for both -n and -p and all the other settings are one this page:
Choosing trimming parameters is hard because there is no consensus on the 'right' answer. Frustratingly, trimming does not solve underlying problems with quality; if you have high quality reads, simplifying joining them is enough achieve high quality. If you have low quality reads, removing the worst data through trimming will not help the rest of the read.
So, if you had a bad MiSeq run, you could consider rerunning the sample. This is also a good opportunity to make sure your DNA extraction and PCR is working as expected, before scaling up to more samples. You could try using a different extraction kit, try normalizing the nanograms of PCR product you add to the MiSeq run, or try using a different sequencing center.
I appreciate all your questions. I wish I could offer more advice on how to troubleshoot this process.
Colin
Reply all
Reply to author
Forward
0 new messages