Portal functional ?
36 views
Skip to first unread message

Morris Ford
Sep 6, 2010, 6:00:45 PM9/6/10
to Open Wonderland Forum
I was doing some portal testing today for the first time in many
months and was quite disappointed to find that it won't work for me. I
set up portals between my system and the community world and I get the
'out of memory - permgen space' errors going in either direction. I
have done the
ANT_OPTS="-XX:MaxPermSize=900m -Xmx900m"; export ANT_OPTS
thing as user and as system wide on my mac and I still get the errors.
Am I doing something wrong or is the portal stuff still in bad shape?
Morris
months and was quite disappointed to find that it won't work for me. I
set up portals between my system and the community world and I get the
'out of memory - permgen space' errors going in either direction. I
have done the
ANT_OPTS="-XX:MaxPermSize=900m -Xmx900m"; export ANT_OPTS
thing as user and as system wide on my mac and I still get the errors.
Am I doing something wrong or is the portal stuff still in bad shape?
Morris

wezzax
Sep 7, 2010, 4:14:51 AM9/7/10
to Open Wonderland Forum
I have problems with portal teleporting as well,
http://groups.google.com/group/openwonderland/browse_thread/thread/65946f4e1b305dfb#
I don't think the ANT_OPTS is that useful and should be avoided if you
are running more than 1 java process! I had the experience that if I
try to start OWL server after working with netbeans, I would sure get
the "out of mem" trouble, even there's 2.5GB free mem! And the only
solution is restart my PC, which I hate to do!
http://groups.google.com/group/openwonderland/browse_thread/thread/65946f4e1b305dfb#
I don't think the ANT_OPTS is that useful and should be avoided if you
are running more than 1 java process! I had the experience that if I
try to start OWL server after working with netbeans, I would sure get
the "out of mem" trouble, even there's 2.5GB free mem! And the only
solution is restart my PC, which I hate to do!

micheldenis
Sep 10, 2010, 11:14:47 AM9/10/10
to Open Wonderland Forum
Same problem with me.
Any idea what's going on ?
-michel
On Sep 7, 10:14 am, wezzax <wez...@gmail.com> wrote:
> I have problems with portal teleporting as well,http://groups.google.com/group/openwonderland/browse_thread/thread/65...
Any idea what's going on ?
-michel
On Sep 7, 10:14 am, wezzax <wez...@gmail.com> wrote:
> I have problems with portal teleporting as well,http://groups.google.com/group/openwonderland/browse_thread/thread/65...
Morris Ford
Sep 17, 2010, 12:53:47 PM9/17/10
to openwon...@googlegroups.com
It looks to me like the action of 'abandoning' one world and entering another is not being done in a way that allows for timely garbage collection. I have looked around in the world changeover process but I get over my head pretty quickly. Is this appraisal of what is happening reasonable? Where would I look to start to find out more about the world change process?
Morris

Jonathan Kaplan
Sep 17, 2010, 1:24:53 PM9/17/10
to openwon...@googlegroups.com
Morris,
This is a very reasonable explanation. When you leave one world, it is supposed to clean everything up to allow for garbage collection. The most important item here is the classloader associated with the session -- classloaders put data in the permanent generation. Since classloaders don't do any partial cleanup, any class loaded as part of the session will stay loaded until the entire classloader becomes collectable. Unfortunately, a classloader is only collectable once every instance of every class it has loaded has been collected. This is, as you can guess, extremely difficult.
To tackle this type of problem, all you need is the NetBeans profiler and an insane attention to detail. As a very simple first step, I did the following:
- configure my server to use the empty world
- launch the OWL client from the command line
- after the client connected, I selected "log out", which should clean everything up
- attach the netbeans profiler using a dynamic attach
- use the controls in the upper left panel to force garbage collection
- on the "Profile" menu, select "Take Heap Dump...", which will collect information about all the classes in use, and open the heap walker
- in the heap walker, under classes, search for ScannedClassLoader, then double click on the instance
Now for the fun part. The "References" view at the bottom contains a tree of all objects with references to the ScannedClassLoader. There are lots of them. If you expand the tree, you will see that most paths end in a loop (green icon), which you can ignore. The paths that are an issue are the ones that end in a GC root (blue icon). You can get some help finding the roots by selecting an object, right clicking and selecting "find nearest GC root". For the classloader to be collected, all of the roots need to be cleaned up.
In my simple experiment, I very quickly found two issues:
- my nearest GC root was an AudioProblemJFrame. This frame should be cleaned up using dispose() rather than setVisible(false).
- many of the references were related to ResourceBundles. It turns out there is a manual call to ResourceBundle.clearCache() that will clean these up. We need to make that call during logout.
This was about 10 seconds of looking. Hopefully all the issues will be this easy, but there are literally hundreds of references to the classloader, so it will take a fair amount of time to clean them all up. If you want to go down this road, we should start a running bug where we can add in code that causes GC roots to get added and not cleaned up on logout.
Morris Ford
Sep 17, 2010, 1:36:23 PM9/17/10
to openwon...@googlegroups.com
Jonathan,
Thanks for that. Sounds like an arduous process but one that really needs to happen. I will start by getting the netbeans profiler up and get the display up that you are talking about. As soon as I get through that I will start finding the boo-boos. I am sure that I have some problems like that in my own code so I can start practicing there. Do you want to create the 'running' bug?
Morris
Jonathan Kaplan
Sep 17, 2010, 2:01:28 PM9/17/10
to openwon...@googlegroups.com
Done -- bug 115.
I find it is most useful to scan the "type" field in the references section of the heap walker (I wish you could sort). It seems like anything named "$classloader$", or anything with type "Package", "ResourceBundle$LoaderReference", "DelegationClassLoader", "WeakHashMap$Entry" and "ProtectionDomain" are safe to ignore. This covers the vast majority of objects.
Michel DENIS
Sep 17, 2010, 4:03:33 PM9/17/10
to openwon...@googlegroups.com
Hi .. there seems to a discussion here, but .. portal is just not
functional anymore.
Wasn't portal a basic functionality of OWL ?
-michel
Jonathan Kaplan a écrit :
Wasn't portal a basic functionality of OWL ?
-michel
Jonathan Kaplan a écrit :
Morris Ford
Sep 17, 2010, 5:39:52 PM9/17/10
to openwon...@googlegroups.com
Jon,
I poked at this for a while and I found that there were three 'GCRoot' indications in references that were not in the types you sent. They were in JmeCellCache, ImiAvatarConfigManager and MultimeshEvolverAvatarConfigManager. Seems to me that would not really be enough to cause the permgen error on portal activation. I did the test after starting up a world with a lot of stuff and then logging off. Do you think that would be enough to cause big problems?
Seems to me that either: there is a lot more dangling stuff hidden or the log out actually does clean up well and does not reflect what is actually going on with portalling.
Does the portal activation call for a logout before connecting to the target world?
Morris
Jonathan Kaplan
Sep 17, 2010, 6:25:57 PM9/17/10
to openwon...@googlegroups.com
Morris,
The absolute numbers don't matter -- it's an all-or-nothing effect. The permanent generation is full of class data loaded by the ScannedClassLoader. None of that class data will be unloaded until the ScannedClassLoader is garbage collected. So even if there was only one reference to the ScannedClassLoader keeping it from being collected, the permanent generation would still fill up.
A "standard" Wonderland client is already running pretty close to the limits for the permanent generation -- I learned this when I had to increase the permgen size to make the sorting demo work.
And yes, teleporting from one server to another server calls logout() on the first server. Interestingly, it doesn't seem to call ServerSessionManager.disconnect(), which may be required to clean up properly.
Jonathan Kaplan
Sep 17, 2010, 6:27:02 PM9/17/10
to openwon...@googlegroups.com
Hi Michel,
Do you mean portals between worlds, or portals within a single world? Portals within a single world (via the Portal capability) are definitely working properly. I'm not sure about the default portal object, but that is just some artwork with the portal capability applied.
Morris Ford
Sep 17, 2010, 9:55:51 PM9/17/10
to openwon...@googlegroups.com
In the process of trying to figure out the memory problems, I was side-tracked by the appearance of multiple log on screens for the target world. I tracked that back to the collision listener in the PortalComponent firing multiple times. This looks similar to something I encountered that I called 'proximity stutter' where the way an avatar moves causes multiple crossings of the threshold. Whatever the reason, there are multiple collision firings going on.
Morris
Michel DENIS
Sep 18, 2010, 4:14:46 AM9/18/10
to openwon...@googlegroups.com
Hi Jon,
Sorry for the confusion, I mean portals between worlds.
Cheers,
Sorry for the confusion, I mean portals between worlds.
Cheers,
Morris Ford
Oct 6, 2010, 5:02:10 PM10/6/10
to openwon...@googlegroups.com
Jonathan,
I am working on resolving the perm space problems.
I replaced the setVisible(false) calls in the AudioProblemJFrame with dispose. This removed the GcRoot from the list but it also removed part of the users window. I will look at that code to get it to work correctly with the dispose.
In MultimeshEvolverAvatarConfigManager and ImiAvatarConfigManager it looks like they are both hanging with a ServerSyncThread active. Where would I find those threads at logout time?
Morris
Jonathan Kaplan
Oct 7, 2010, 3:36:57 PM10/7/10
to openwon...@googlegroups.com
Morris,
Similar code is apparently copied in the multimesh evolver code:
There are many things I don't like about this code, including the fact that it seems to have been mostly copied into two places! Also, there is no need to deal with multiple ServerSessionManagers, since a module is only ever associated with a single session. Oh, and it blocks for a very long time when you are initially synchronizing with a new server.
Sadly, I don't have time for a rewrite right now. It looks like the cleanup code should go:
AvatarClientPlugin.deactivate()
AvatarSessionLoader.unload()
ImiAvatarFactory.unregisterAvatars()
ImiAvatarConfigManager.removeServer()
ServerSyncThread.setConnected(false)
Apart from the fact that the connected variable isn't properly synchronized, I'm not sure why that isn't working. Hopefully a quick step through with the debugger will show why.
BTW, I used the new Netbeans "call hierarchy" feature to generate the path to setConnected(). Very cool.
Morris Ford
Oct 7, 2010, 7:47:39 PM10/7/10
to openwon...@googlegroups.com
Well, I poked around in there for a while and found that the sequence as in your post is not happening. Big surprise! It looks like it is supposed to happen based on a PrimaryServerListener. Other places in the system register that listener but nobody in the AvatarClientPlugin -> avatar config manager linkage registers it. Looks to me like the listener should go on AvatarClientPlugin and shut down everything from there. I'll poke at it some more tomorrow.
Morris
Morris Ford
Oct 8, 2010, 6:59:57 PM10/8/10
to openwon...@googlegroups.com
That code is getting executed and setting isConnected to false down in the ServerSyncThread. My debugger wouldn't stop down in there for some reason. The problem is that in the run method of the sync thread there is a call to
job = jobQueue.take();
that gets called to wait for the next job and it blocks waiting and never returns so the run thread never exits. Three options that I see:
that gets called to wait for the next job and it blocks waiting and never returns so the run thread never exits. Three options that I see:
1) Do a jobQueue.size() in the run method to see if there are any jobs before calling take. Seems like a bad idea since this will cause the run method to cycle constantly.
2) Make a non-blocking take function. Same problem - causes run to cycle at full tilt.
3) Interrupt the take lock somehow on the logout.
Suggestions?
Morris
Jonathan Kaplan
Oct 8, 2010, 8:42:45 PM10/8/10
to openwon...@googlegroups.com
Ugly. Have I mentioned how I feel about that particular code?
I think the best solution would be to replace the threads with Executors, which are designed to handle exactly this type of job submission, and also deal with shutdown and other synchronization conditions properly. I've attached a patch to convert to an executor, but I haven't tried it at all. If you don't mind trying it out and letting me know what I did wrong, that would be great!
Next up: asynchronous synchronize...
Morris Ford
Oct 9, 2010, 3:00:07 PM10/9/10
to openwon...@googlegroups.com
That works and no more thread hanging around. I'll see if I can do an evolver version.
On Oct 8, 2010 8:43 PM, "Jonathan Kaplan" <jonat...@gmail.com> wrote:
Ugly. Have I mentioned how I feel about that particular code?I think the best solution would be to replace the threads with Executors, which are designed to handle exactly this type of job submission, and also deal with shutdown and other synchronization conditions properly. I've attached a patch to convert to an executor, but I haven't tried it at all. If you don't mind trying it out and letting me know what I did wrong, that would be great!Next up: asynchronous synchronize...
On Fri, Oct 8, 2010 at 3:59 PM, Morris Ford <morri...@gmail.com> wrote:
>
> That code is gettin...
Morris Ford
Oct 12, 2010, 11:37:04 AM10/12/10
to openwon...@googlegroups.com
Jonathan,
Attached is the diff for the evolver avatar equivalent. I could just check the new version into the module source repository if you want. I looked at the stable evolver avatar module and it has the same structure with the hanging thread. I will get that one fixed and send it along.
I looked some more at the AudioProblemJFrame to try to fix it and I don't think the difficulty is with setVisible vs dispose. It looks like in AudioManagerClient that the audio trouble jframe gets created whether it is needed or not and then is updated out of a timer thread. I'm going to look at it some more later.
As a test I commented out the creation and update of the AudioProblemJFrame to see if it would clear up the permgen issue. I did the heap dump examination again and that entry was gone. There was another one however way down at the bottom of the list. It had no obvious connection to OWL however. I will run the profiling again and get more info about it.
After the avatar threads were gone and the AudioProblem piece gone I was able to portal across worlds much better but I would eventually get the permgen error.
I am definitely seeing at least 3 teleport attempts when the collision occurs in the portal module and they are coming from 3 (or more) collision events. I put code in the scripting component to do a cross world teleport and this part (only one teleported session) works as expected.
Still more to do but it is looking a bit better.
Morris
Morris Ford
Oct 12, 2010, 3:07:38 PM10/12/10
to openwon...@googlegroups.com
Jonathan,
Right now I am not seeing any GCRoot items with the profiler. I have the audio problem panel disabled. I am still getting permgen errors on teleporting. Where do I look now?
Morris
Jonathan Kaplan
Oct 12, 2010, 7:26:45 PM10/12/10
to openwon...@googlegroups.com
Morris,
Thanks for looking into this!
If you select the ScannedClassLoader, click on "this" in the references section (the top item) and select "find nearest GC root", what does it do? I expect it will find some other roots.
In particular, unless you are calling ResourceBundle.clearCache() somewhere, there should still be lots of references by way of resource bundle objects. Also, I don't think that ServerSessionManager.disconnect() is ever actually called. Presumably it should be called from JmeClientMain.logout(). So I expect the path ServerSessionManager -> LoginControl -> ScannedClassloader still exists and is also preventing garbage collection. Incidentally, ServerSessionManager.disconnect() seems like the right place to call ResourceBundle.clearCache(getClassLoader()).
Morris Ford
Oct 13, 2010, 11:43:02 AM10/13/10
to openwon...@googlegroups.com
Jonathan,
I now have disconnect called and cache clearing in disconnect. Here are the two pieces of code:
From JmeClientMain:
protected void logout() {
LOGGER.info("[JMEClientMain] log out");
System.out.println("-------------------------- Enter logout in JmeClientMain");
// disconnect from the current session
if (curSession != null) {
if (curSession.getStatus() == Status.CONNECTED) {
synchronized (this) {
loggingOut = true;
}
}
System.out.println("---------------------- After sync");
// ResourceBundle.clearCache();
// WorldManager wm = ClientContextJME.getWorldManager();
curSession.getCellCache().unloadAll();
ServerSessionManager ssm = curSession.getSessionManager();
System.out.println("---------------------- After get ssm");
curSession.logout();
curSession = null;
frame.connected(false);
// notify listeners that there is no longer a primary server
LoginManager.setPrimary(null);
ssm.disconnect();
System.out.println("----------------------- After disconnect");
}
}
From ServerSessionManager:
public void disconnect() {
logger.log(Level.WARNING, "[ServerSessionManager] Disconnect from " +
getServerURL());
synchronized (connectLock) {
synchronized (this) {
// if we are already disconnected, just return
if (loginControl == null) {
return;
}
// remove the login control immediately so that
// isConnected() will return false during the
// disconnect process
loginControl = null;
}
System.out.println("&&&&&&&&&&&&&&&&&&& - disconnect after sync");
ResourceBundle.clearCache();
// if we are the primary session, send a notification that there
// is no longer a primary session
if (this.equals(LoginManager.getPrimary())) {
LoginManager.setPrimary(null);
}
// disconnect all sessions
for (WonderlandSession session : getAllSessions()) {
session.logout();
}
// clean up all plugins
for (ClientPlugin plugin : plugins) {
plugin.cleanup();
}
// all done, clean things up
plugins.clear();
// notify listeners
fireServerStatus(false);
System.out.println("&&&&&&&&&&&&&&&&&& - disconnect at bottom");
}
}
I do see both pieces of code executing. I am using netbeans 6.9.1 now and it acts differently than the 6.5 that I was using. I had to change because the earlier version started blowing up in the profiling.
My procedure is what you described, ie, do find nearest GC root of this (first line). With the avatar thread issues and with the AudioProblem issue the problem area popped right out and was readily traceable to OWL code. Now, when I do the same thing, I have to go hunt for the GCRoot. This apparently is a netbeans version difference.
When I find the 'first' GCRoot it is now always a $classloader$ with the problem part being 'loadedClassesArray' from ProfilerInterface. Being on the ProfilerInterface make me suspicious.
Down toward the bottom of the list there are ResourceBundle$LoaderReference lines and if I do the find nearest GCRoot on that line it shows a problem but I cannot find a way to get any of these back to OWL code.
So, I'm kinda stuck until I find another loose thread to make it unravel. By the way, I did try teleporting and it fails still.
Morris
Jonathan Kaplan
Oct 13, 2010, 11:57:51 AM10/13/10
to openwon...@googlegroups.com
Morris,
Can you generate a single patch with all your changes? You should be able to use "svn diff" from the command line in your wonderland/ directory, or select the modified files in NetBeans and choose "Team -> Export Diff Patch". Then I can take a look and see if I can get anything more to clear out.
Morris Ford
Oct 13, 2010, 4:29:03 PM10/13/10
to openwon...@googlegroups.com
Sorry for the delay. svn diff includes binary files so that is not useful. Also, I cannot figure out how to get more than one file selected in netbeans for the diff.
Morris Ford
Oct 13, 2010, 6:37:15 PM10/13/10
to openwon...@googlegroups.com
I generated patches for the 5 files I think are all the changed ones. I merged them into one file and then zipped them into another file. Both are attached.
I would really like to know what else you find and how you found it.
Morris
Jonathan Kaplan
Oct 14, 2010, 6:25:59 PM10/14/10
to openwon...@googlegroups.com
Morris,
Thanks for the patches. We are moving in the right direction, but it looks like there is still a ways to go. I was able to find a few more issues with the following method:
1. stop the server
2. remove a bunch of optional modules (like multimesh evolver avatar and others that threw exceptions during logout)
3. restore the empty world
4. log in
5. select File -> Log Out in the Wonderland client
6. connect with the profiler using the minimum settings (monitor only)
7.take a heap dump
I believe this strategy eliminates many of the profiler-related issues you ran into. Once I had the "clean" heap dump, I selected the ScannedClassLoader and looked through its references, ignoring anything that met any of the following conditions:
1. field is "$classloader$"
2. type is "DelegatingClassLoader"
3. type is "Package"
4. type is "WeakHashMap$Entry"
5. type is "ResourceBundle$LoaderReference"
6. type is "ProtectionDomain"
I found the following items that don't fit in those categories:
1. Type is "JmeCellCache": there are at least two paths to the cell cache that need to be cleaned up. One is ProcessorManager holding a reference to AvatarControls, and the other is the static ClientContext.cellCaches variable.
2. Type is "JmeClientSession": sadly, there are a ton of paths to this one. For example MainFrame holds a reference to the TextChatPanel, which holds a reference to the session. There is also a path through the App2D invoker thread, which is never shut down properly. To track down the references to this class, I right clicked and selected "show instance" since there was so much to explore.
Using the same logged out client instance, I also generated more heap dumps, and used "find nearest GC root" to locate a few other stragglers (it turns out the "ProtectionDomain" type isn't entirely safe):
1. the App2D invoker thread is never shut down
2. in the webdav module, the MultiThreadedHttpConnectionManager is not shut down, leaving several threads running
It would be nice to eliminate the JmeCellCache and extra threads before going after the JmeClientSession, which seems like the biggest hairball at this point.
Morris Ford
Oct 14, 2010, 6:31:00 PM10/14/10
to openwon...@googlegroups.com
Ok. I'll start chipping away at it.
On Oct 14, 2010 6:26 PM, "Jonathan Kaplan" <jonat...@gmail.com> wrote:
Morris,
Thanks for the patches. We are moving in the right direction, but it looks like there is still a ways to go. I was able to find a few more issues with the following method:1. stop the server2. remove a bunch of optional modules (like multimesh evolver avatar and others that threw exceptions during logout)3. restore the empty world4. log in5. select File -> Log Out in the Wonderland client6. connect with the profiler using the minimum settings (monitor only)7.take a heap dumpI believe this strategy eliminates many of the profiler-related issues you ran into. Once I had the "clean" heap dump, I selected the ScannedClassLoader and looked through its references, ignoring anything that met any of the following conditions:1. field is "$classloader$"2. type is "DelegatingClassLoader"3. type is "Package"4. type is "WeakHashMap$Entry"5. type is "ResourceBundle$LoaderReference"6. type is "ProtectionDomain"I found the following items that don't fit in those categories:1. Type is "JmeCellCache": there are at least two paths to the cell cache that need to be cleaned up. One is ProcessorManager holding a reference to AvatarControls, and the other is the static ClientContext.cellCaches variable.2. Type is "JmeClientSession": sadly, there are a ton of paths to this one. For example MainFrame holds a reference to the TextChatPanel, which holds a reference to the session. There is also a path through the App2D invoker thread, which is never shut down properly. To track down the references to this class, I right clicked and selected "show instance" since there was so much to explore.Using the same logged out client instance, I also generated more heap dumps, and used "find nearest GC root" to locate a few other stragglers (it turns out the "ProtectionDomain" type isn't entirely safe):1. the App2D invoker thread is never shut down2. in the webdav module, the MultiThreadedHttpConnectionManager is not shut down, leaving several threads running
It would be nice to eliminate the JmeCellCache and extra threads before going after the JmeClientSession, which seems like the biggest hairball at this point.
On Wed, Oct 13, 2010 at 3:37 PM, Morris Ford <morri...@gmail.com> wrote:
>
> I generated patche...
Morris Ford
Oct 17, 2010, 2:47:55 PM10/17/10
to openwon...@googlegroups.com
Jonathan,
It runs every time the cell status is changed. Problem is that after logout there are some of these classes hanging around with references to JmeCellCache. The instances that I am seeing have three elements:
I need a little assistance. I have been working through the references to JmeClientMain. I have resolved a number of them but I am having a problem with one type. In CellCacheBasicImpl the following code appears:
private void changeCellStatus(Cell cell, CellStatus status) {
cacheExecutor.submit(new CellStatusChanger(cell, status));
}
private class CellStatusChanger implements Runnable {
private Cell cell;
private CellStatus cellStatus;
public CellStatusChanger(Cell cell, CellStatus status) {
this.cell = cell;
this.cellStatus = status;
}
public void run() {
System.out.println("!!!!!!!!!!!!!!!!!!!! - CellCacheBasicImpl - Enter run for cell - " + cell + " - status = " + cellStatus);
try {
setCellStatus(cell, cellStatus);
} catch(Throwable t) {
// Report the exception, otherwise it will get swallowed
logger.log(Level.WARNING, "Exception thrown in Cell.setStatus "+t.getLocalizedMessage(), t);
}
System.out.println("!!!!!!!!!!!!!!!!!! - exit - cell = " + cell + " -status = " + cellStatus);
}
}
cell, cellStatus and this$0.
The this$0 is the reference to the cell cache. Problem is that I cannot figure out where that this$0 reference comes from and what is making these classes hang around. Maybe a vestige of the executor call? Any insight greatly appreciated.
Morris
Jonathan Kaplan
Oct 18, 2010, 1:08:15 AM10/18/10
to openwon...@googlegroups.com
Hi Morris,
The easy question is the this$0 reference. All inner classes keep a reference to their parent class (unless the inner class is declared static), which the compiler adds and calls this$0. The parent is used to call methods on the parent. For example, in the code below, the call to setCellStatus() is modified by the compiler to be this$0.setCellStatus().
Why the objects are hanging around is a better question. Try forcing a GC (using the icon on the profiler window) before you take the heap dump -- maybe the objects are eligible for GC and just haven't been cleaned up yet. If that's not it, perhaps we need to do something with the executor to clean them up. I'm assuming they are not active, although you could double check by getting a stack trace and seeing if any calls to CellStatusChanger.run() are outstanding. The cacheExecutor should probably be shut down somewhere in any case. I guess someone needs to destroy the cache on logout.
Morris Ford
Oct 18, 2010, 10:16:48 AM10/18/10
to openwon...@googlegroups.com
Jonathan,
Thanks, that cleared up that dangler. I had gotten into the habit of not doing the GC before the heap dump because it didn't seem to make much difference.
It looks like I have cleared all the dangling references to JmeCellCache. I have learned a huge amount about how that part of OWL functions and how messy java can be under less than optimal conditions. I would like to pose some philosophical questions about this process and the underlying causes.
1) My process for JmeCellCache has been to find the classes that retain references to the cache and adding methods that null out the references at logout time. This appears to allow proper collection of the cache class. Is this an appropriate method?
2) It appears that these dangling classes with references to the cache class are due to the various classes getting references to the cache and then keeping the reference. Would it be 'better' for all these classes that use references to the cache to retrieve the reference each time it is used?
I am now moving on to JmeClientSession as the next renovation candidate.
Morris
Morris Ford
Oct 18, 2010, 4:33:16 PM10/18/10
to openwon...@googlegroups.com
I started looking at the JmeClientSession and right away I ran into this class in ChatManager:
private static class ChatManagerHolder {
private final static ChatManager manager = new ChatManager();
}
ChatManager holds a reference to TextChatConnection
which holds a reference to JmeClientSession.
My inclination is to null out manager in this class to release these references but being final it cannot be changed. This looks like a solid lock to keep this string in permgen. I could null out the session reference in TextChatConnection but it appears that would leave the rest of the linkage. Am I reading this correctly?
Morris
Jonathan Kaplan
Oct 18, 2010, 5:15:06 PM10/18/10
to openwon...@googlegroups.com
Hi Morris,
I think this example is a good one to explore the questions you posed above. Here is how I think about it: the objects instantiated by the module classloader represent this big, interconnected graph that I imagine looks like a huge hairball. The graph is mostly self contained -- most references point to other objects that are part of modules. I think of the hairball as being held up by a few stray hairs, which represent references from objects loaded by the system classloader to an object loaded by the module classloader. If we cut those few strays, the hairball will fall down and get garbage collected, regardless of all the interconnected links on the inside.
In your chat manager example, the fact that the ChatManager object holds a link to the TextChatConnection is no problem. Since the ChatManager is part of the module code,this link is inside the big hairball, and does not prevent garbage collection. You should be able to see this in the profiler -- if you select the TextChatConnection object in the heap walker, and then do a "Show GC root", it shouldn't come up with any roots.
So what are the GC roots that we need to worry about? There are a few common cases:
- code loaded in a module is added to a static field of an object loaded by the system classloader. Since the system object will never be unloaded, anything stored in a static field in that case will never be collected. The most common case here is registering listeners, but I think there were some static collections in ClientContext that module code could get added to and not properly removed. The solution here is to unregister any object that is registered with one of these static fields.
- code loaded in a module is referenced from a non-static object that doesn't go away. The best example here is the UI -- as long as a window is not disposed, objects added to that window won't be collected. There is no generic solution for this, the link just needs to get cleaned up.
- a module creates a new thread -- threads are always GC roots, so any threads started by modules must be shut down.
Usually fixing these problems is simply a matter of making sure that threads get shut down, and that there is a matching "unregister" for every "register" type operation. Once the program gets as complicated as OWL, however, you find lots of new an interesting paths, like GUI elements holding on to resources.
I would definitely recommend a skim through this quick guide to object states and garbage collection:
There are lots of other good references around as well.
Morris Ford
Oct 18, 2010, 7:25:17 PM10/18/10
to openwon...@googlegroups.com
Yes, I understand, at least at some level, how and why GC. I have seen two of the forms of stuck GCRoot that you talk about, ie, the thread (Imi and Evolver avatars) and the UI ( audio problem ). I understand how and why those cause problems and I understand how the other form you talk about causes problems. The difficulty that I have at the moment is how to get from the 'show nearest GCRoot" results, which are almost always a loadedClasses array linked to the profiler interface, to the cause. Where is the traceable linkage back to the underlying problem? It must be there somewhere. If the linkage back to the cause cannot be directly traced, finding a lot of these types of problems will have to be guess work and OWL is a bit large for guess work by someone who did not create all the parts.
Morris
Jonathan Kaplan
Oct 18, 2010, 7:56:18 PM10/18/10
to openwon...@googlegroups.com
Morris,
I don't ever see the profiler interface references when I do 'show nearest GC Root'. I'm using NetBeans 6.9.1 on Windows. I run the binary unmodified (with no profiling enabled or anything like that). I connect, then log out. After I have logged out, I use the dynamic attach option to connect the profiler using the least invasive settings (monitor only). Using these settings, I have not seen invalid GC roots due to profiling.
I agree -- if you are seeing bogus results from Show GC Root, it is going to be nearly impossible to figure out where the real problem linkages are, versus the many other references floating around. If we can't resolve this over email, perhaps we could meet in world and use screen sharer to see what is going on.
Morris Ford
Oct 18, 2010, 8:01:13 PM10/18/10
to openwon...@googlegroups.com
How do you get the option 'monitor only'? I looked for a while and could not find that option.
Morris Ford
Oct 18, 2010, 8:16:30 PM10/18/10
to openwon...@googlegroups.com
Aha!!! That makes all the difference. I found a Thread object right away! I guess the Monitor button was too large to see. I'll be back at it tomorrow.
Thanks,
Morris
Michel DENIS
Oct 20, 2010, 3:19:32 PM10/20/10
to openwon...@googlegroups.com
Hi,
A have a naïve question, seeing the exchange of emails and the subject of the post: is Portal usable for teleporting from world to world ? O:-)
Cheers,
-michel
Morris Ford a écrit :
A have a naïve question, seeing the exchange of emails and the subject of the post: is Portal usable for teleporting from world to world ? O:-)
Cheers,
-michel
Morris Ford a écrit :
Morris Ford
Oct 20, 2010, 4:18:21 PM10/20/10
to openwon...@googlegroups.com
Michel,
Not yet. I am in the process of finding and repairing (with a lot of help from Jonathan) the various code problems that prevent proper garbage collection at teleport time. Until the garbage collection works properly, teleporting will not work correctly.
Morris
Morris Ford
Oct 22, 2010, 10:13:00 AM10/22/10
to openwon...@googlegroups.com
In the process of chasing down GCRoots I found that there are two threads left intact that are related to the Trident animation library used to change the transparency of HUD windows. These two threads appear to be created the first time that a Timeline is run and then they don't exit (I tested this with a small test program). My assumption is that I need to find all the HUDComponents that have been created and properly remove them all in order to get the Trident threads to go away. Anyone have any better insight into what is going on inside the Trident structure? Is removing everyone that has execute a Timeline going to release these threads?
Morris

{kind=link}
jagwire
Oct 22, 2010, 10:39:40 AM10/22/10
to Open Wonderland Forum
If it helps you at all, Morris, I seem to recall that if the gesture
buttons are left on the HUD on a disconnect (let's say a snapshot is
restored), they persist on the canvas where things get rendered and I
believe things to go awry on reconnect. That code might be another
avenue for you to pursue in terms of your work in GC. Then again, it
might just be another link in the hairball as Jonathan mentioned. In
any case…
Happy digging,
jW
On Oct 22, 9:13 am, Morris Ford <morrishf...@gmail.com> wrote:
> In the process of chasing down GCRoots I found that there are two threads
> left intact that are related to the Trident animation library used to change
> the transparency of HUD windows. These two threads appear to be created the
> first time that a Timeline is run and then they don't exit (I tested this
> with a small test program). My assumption is that I need to find all the
> HUDComponents that have been created and properly remove them all in order
> to get the Trident threads to go away. Anyone have any better insight into
> what is going on inside the Trident structure? Is removing everyone that has
> execute a Timeline going to release these threads?
> Morris
>
> >>>>>>>http://java.sun.com/docs/books/performance/1st_edition/html/JPAppGC.f...
> ...
>
> read more »
buttons are left on the HUD on a disconnect (let's say a snapshot is
restored), they persist on the canvas where things get rendered and I
believe things to go awry on reconnect. That code might be another
avenue for you to pursue in terms of your work in GC. Then again, it
might just be another link in the hairball as Jonathan mentioned. In
any case…
Happy digging,
jW
On Oct 22, 9:13 am, Morris Ford <morrishf...@gmail.com> wrote:
> In the process of chasing down GCRoots I found that there are two threads
> left intact that are related to the Trident animation library used to change
> the transparency of HUD windows. These two threads appear to be created the
> first time that a Timeline is run and then they don't exit (I tested this
> with a small test program). My assumption is that I need to find all the
> HUDComponents that have been created and properly remove them all in order
> to get the Trident threads to go away. Anyone have any better insight into
> what is going on inside the Trident structure? Is removing everyone that has
> execute a Timeline going to release these threads?
> Morris
>
> On Wed, Oct 20, 2010 at 4:18 PM, Morris Ford <morrishf...@gmail.com> wrote:
> > Michel,
> > Not yet. I am in the process of finding and repairing (with a lot of help
> > from Jonathan) the various code problems that prevent proper garbage
> > collection at teleport time. Until the garbage collection works properly,
> > teleporting will not work correctly.
> > Morris
>
> > Michel,
> > Not yet. I am in the process of finding and repairing (with a lot of help
> > from Jonathan) the various code problems that prevent proper garbage
> > collection at teleport time. Until the garbage collection works properly,
> > teleporting will not work correctly.
> > Morris
>
> > On Wed, Oct 20, 2010 at 3:19 PM, Michel DENIS <michel.m.de...@gmail.com>wrote:
>
> >> Hi,
>
> >> A have a naïve question, seeing the exchange of emails and the subject of
> >> the post: is Portal usable for teleporting from world to world ? O:-)
>
> >> Cheers,
> >> -michel
>
> >> Morris Ford a écrit :
>
> >> Aha!!! That makes all the difference. I found a Thread object right away!
> >> I guess the Monitor button was too large to see. I'll be back at it
> >> tomorrow.
> >> Thanks,
> >> Morris
>
>
> >> Hi,
>
> >> A have a naïve question, seeing the exchange of emails and the subject of
> >> the post: is Portal usable for teleporting from world to world ? O:-)
>
> >> Cheers,
> >> -michel
>
> >> Morris Ford a écrit :
>
> >> Aha!!! That makes all the difference. I found a Thread object right away!
> >> I guess the Monitor button was too large to see. I'll be back at it
> >> tomorrow.
> >> Thanks,
> >> Morris
>
> >> On Mon, Oct 18, 2010 at 8:05 PM, Jonathan Kaplan <jonathan...@gmail.com>wrote:
>
> >>> On the "Attach Profiler" window, the three options are "Monitor", "CPU"
> >>> or "Memory". I choose "Monitor" and do not check the enable threads
> >>> monitoring checkbox. See the attached screen shot.
>
>
> >>> On the "Attach Profiler" window, the three options are "Monitor", "CPU"
> >>> or "Memory". I choose "Monitor" and do not check the enable threads
> >>> monitoring checkbox. See the attached screen shot.
>
> >>> On Mon, Oct 18, 2010 at 5:01 PM, Morris Ford <morrishf...@gmail.com>wrote:
>
> >>>> How do you get the option 'monitor only'? I looked for a while and could
> >>>> not find that option.
>
> >>>> On Mon, Oct 18, 2010 at 7:56 PM, Jonathan Kaplan <jonathan...@gmail.com
>
> >>>> How do you get the option 'monitor only'? I looked for a while and could
> >>>> not find that option.
>
> >>>> > wrote:
>
> >>>>> Morris,
>
> >>>>> I don't ever see the profiler interface references when I do 'show
> >>>>> nearest GC Root'. I'm using NetBeans 6.9.1 on Windows. I run the binary
> >>>>> unmodified (with no profiling enabled or anything like that). I connect,
> >>>>> then log out. After I have logged out, I use the dynamic attach option to
> >>>>> connect the profiler using the least invasive settings (monitor only). Using
> >>>>> these settings, I have not seen invalid GC roots due to profiling.
>
> >>>>> I agree -- if you are seeing bogus results from Show GC Root, it is
> >>>>> going to be nearly impossible to figure out where the real problem linkages
> >>>>> are, versus the many other references floating around. If we can't resolve
> >>>>> this over email, perhaps we could meet in world and use screen sharer to see
> >>>>> what is going on.
>
>
> >>>>> Morris,
>
> >>>>> I don't ever see the profiler interface references when I do 'show
> >>>>> nearest GC Root'. I'm using NetBeans 6.9.1 on Windows. I run the binary
> >>>>> unmodified (with no profiling enabled or anything like that). I connect,
> >>>>> then log out. After I have logged out, I use the dynamic attach option to
> >>>>> connect the profiler using the least invasive settings (monitor only). Using
> >>>>> these settings, I have not seen invalid GC roots due to profiling.
>
> >>>>> I agree -- if you are seeing bogus results from Show GC Root, it is
> >>>>> going to be nearly impossible to figure out where the real problem linkages
> >>>>> are, versus the many other references floating around. If we can't resolve
> >>>>> this over email, perhaps we could meet in world and use screen sharer to see
> >>>>> what is going on.
>
>
> >>>>>>> There are lots of other good references around as well.
>
> >>>>>>> There are lots of other good references around as well.
>
> >>>>>>> On Mon, Oct 18, 2010 at 1:33 PM, Morris Ford <morrishf...@gmail.com>wrote:
>
> >>>>>>>> I started looking at the JmeClientSession and right away I ran into
> >>>>>>>> this class in ChatManager:
>
> >>>>>>>> private static class ChatManagerHolder {
>
> >>>>>>>> private final static ChatManager manager = new
> >>>>>>>> ChatManager();
> >>>>>>>> }
>
> >>>>>>>> ChatManager holds a reference to TextChatConnection
> >>>>>>>> which holds a reference to JmeClientSession.
>
> >>>>>>>> My inclination is to null out manager in this class to release
> >>>>>>>> these references but being final it cannot be changed. This looks like a
> >>>>>>>> solid lock to keep this string in permgen. I could null out the session
> >>>>>>>> reference in TextChatConnection but it appears that would leave the rest of
> >>>>>>>> the linkage. Am I reading this correctly?
>
> >>>>>>>> Morris
>
> >>>>>>>> On Mon, Oct 18, 2010 at 10:16 AM, Morris Ford <
>
> >>>>>>>> I started looking at the JmeClientSession and right away I ran into
> >>>>>>>> this class in ChatManager:
>
> >>>>>>>> private static class ChatManagerHolder {
>
> >>>>>>>> private final static ChatManager manager = new
> >>>>>>>> ChatManager();
> >>>>>>>> }
>
> >>>>>>>> ChatManager holds a reference to TextChatConnection
> >>>>>>>> which holds a reference to JmeClientSession.
>
> >>>>>>>> My inclination is to null out manager in this class to release
> >>>>>>>> these references but being final it cannot be changed. This looks like a
> >>>>>>>> solid lock to keep this string in permgen. I could null out the session
> >>>>>>>> reference in TextChatConnection but it appears that would leave the rest of
> >>>>>>>> the linkage. Am I reading this correctly?
>
> >>>>>>>> Morris
>
> >>>>>>>> On Mon, Oct 18, 2010 at 10:16 AM, Morris Ford <
>
> read more »
Morris Ford
Oct 22, 2010, 10:46:50 AM10/22/10
to openwon...@googlegroups.com
Thanks. Every bit helps.
Morris
Jonathan Kaplan
Oct 22, 2010, 1:15:20 PM10/22/10
to openwon...@googlegroups.com
The code for the trident threads is in here:
It's a bit hard to tell what is going on. From the looks of it, the Trident threads never shut down. This is not a problem necessarily, since TimelineEngine should be a singleton loaded by the systen classloader, so TimelineEngine will never be unloaded anyway. The problem is if the TimelineEngine holds any references to objects loaded in the module classloader. Is there a path from the Trident threads to the ScannedClassLoader?
From my quick look, the only state trident holds is in the "runningTimelines" variable. A timeline should be removed from the running timelines as soon as it finishes, which in the case of the HUD means when the fade in or fade out is done. It seems like HUD2DObject should call HUDAnimator.cancel() to cleanup (which it doesn't), but unless there is a timeline somehow getting stuck in the running state, I wouldn't expect a memory leak.
Morris Ford
Oct 22, 2010, 1:26:33 PM10/22/10
to openwon...@googlegroups.com
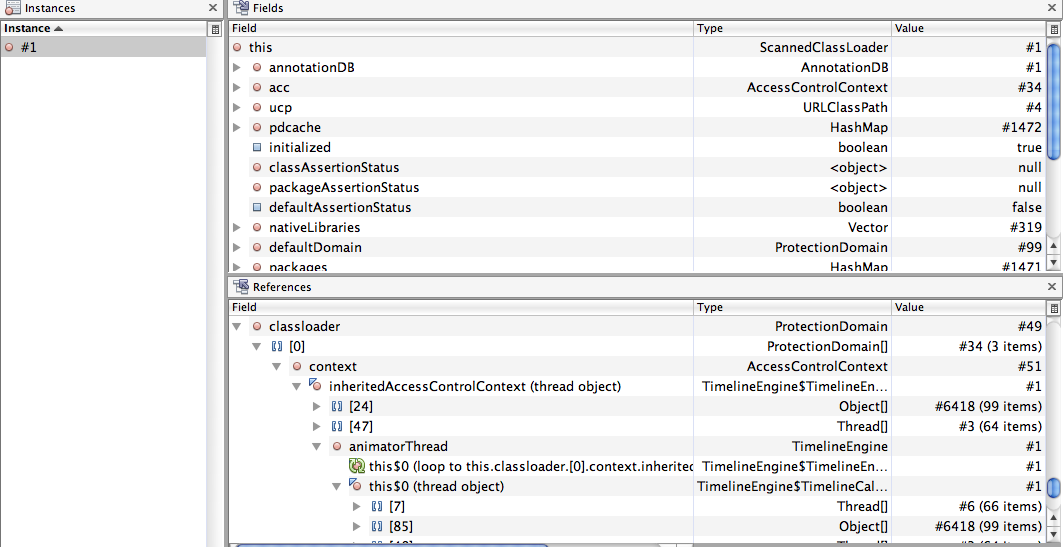
Yes, the TimelineEngine$TimelineCallbackThread and TimelineEngine$TimelineEngineThread are showing up in the 'nearest GCRoot' search. I assume that being a GCRoot implies that they are a memory leak. I cannot find any direct linkage from any of the HUD components but those threads are created because of the transparency animations.
Morris
Morris
Jonathan Kaplan
Oct 22, 2010, 1:29:59 PM10/22/10
to openwon...@googlegroups.com
The fact that they are a GCRoot does mean a memory leak -- what is the path from the thread to the ScannedClassLoader?
{kind=link}
Jonathan Kaplan
Oct 22, 2010, 2:02:26 PM10/22/10
to openwon...@googlegroups.com
Wow, that's a fun one. Here is what is going on: in the HUDObject2D code, we create a new thread to initialize the timeline. The first call to TimelineEngine.getAnimationThread() happens from within this child thread, and therefore the animation thread inherits its AccessControlContext from the child thread [1]. The child thread was started within the module classloader, and its AccessControlContext holds on to a reference to that classloader.
Workarounds that I can think of:
1. since the TimelineEngine is a singleton, make sure it gets initialized first in a thread that is a child of the System classloader. I think this would mean installing a simple Timeline (it doesn't have to do anything) somewhere in the main method or in the initialization code of JmeClientMain. This would cause the engine threads to be created with the system AccessControlContext.
2. wrap the calls to create the Timeline or the HUDObject2D animator thread in a call to AccessController.doPrivileged(), and pass in an AccessControlContext that is created during JmeClientMain initialization. I'm not positive if this will work -- doPrivileged() does some amount of chaining, so may still hold on to the child AccessControlContext. If it works, this is technically the more "correct" solution, but it seems easier to try method one.
[1] For more on AccessControlContext, see http://download.oracle.com/javase/6/docs/technotes/guides/security/spec/security-spec.doc4.html#21495
Morris Ford
Oct 22, 2010, 3:27:42 PM10/22/10
to openwon...@googlegroups.com
I added a simple Timeline to JmeClientMain in the main class. I added the trident library to the core netbeans project to get rid of the errors in the source but 'ant' from 'wonderland' directory won't compile with errors about finding 'Timeline'. I assume this is something very basic but I really don't see it. Help!!
Morris
Morris Ford
Oct 22, 2010, 3:41:42 PM10/22/10
to openwon...@googlegroups.com
Had to change an xml file in core build-scripts. Got it going.
Morris Ford
Oct 22, 2010, 4:20:00 PM10/22/10
to openwon...@googlegroups.com
Looks like putting that simple Timeline in JmeClientMain may have resolved that GCRoot although I'm not absolutely certain. The Trident threads still show up but they don't appear to be attached to anything. The 'show next GCRoot' sometimes shows a different problem even though the prior problem is not resolved so time will tell. Forward to the next dangler.
Morris
Morris Ford
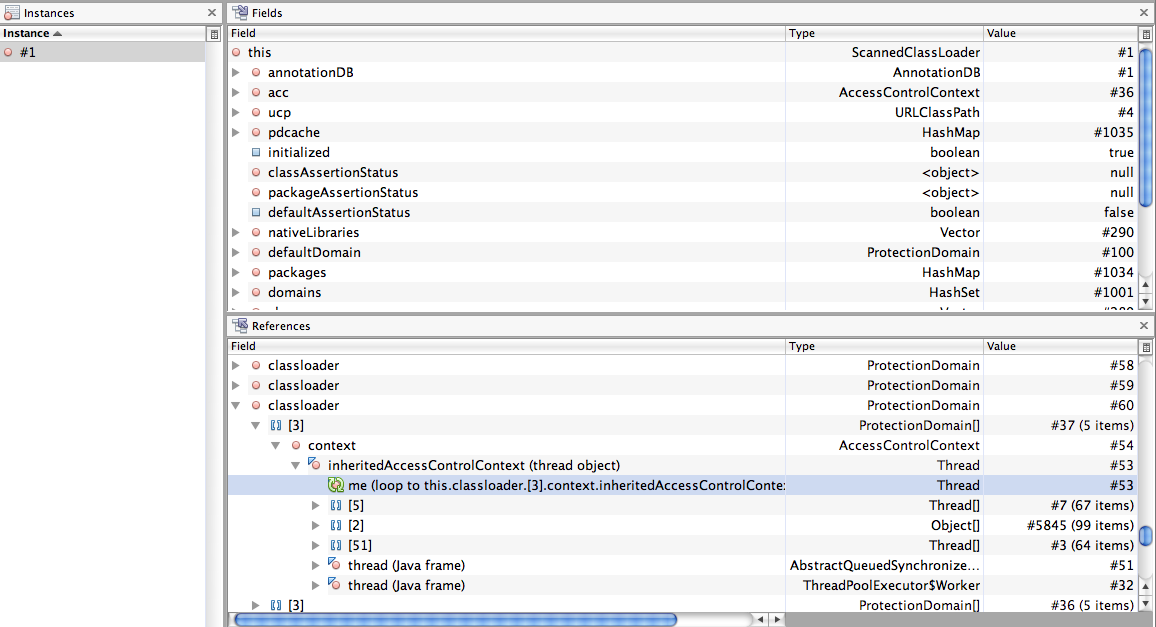
Oct 23, 2010, 4:34:14 PM10/23/10
to openwon...@googlegroups.com
Ok, next question. The next dangler that I am hitting on looks like the invoker thread in App2D. I have attached a screen snap of the profiler. The App2D gets cleaned up but this does not occur until complete client exit. This really doesn't help with the permgen issue cause it's way too late. I thought about putting a session change listener into App2D to do the shutdown but I am not sure if that is appropriate.
Morris
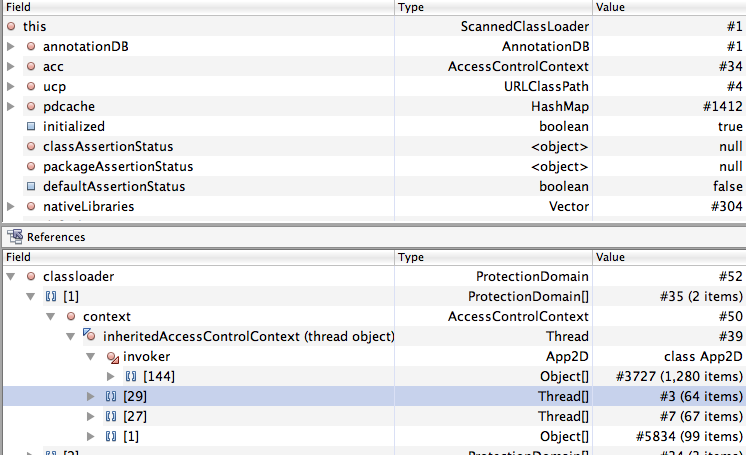{kind=link}
{kind=link}
Jonathan Kaplan
Oct 25, 2010, 3:01:46 PM10/25/10
to openwon...@googlegroups.com
Looking at App2D, I agree with having the shutdown happen when the session is disconnected. Each session will have it's own instance of App2D, and therefore it's own static invoker thread and other static resources. It would also be nice to get rid of that shutdown hook, which sometimes causes problems when someone tries to quit Wonderland.
Jonathan Kaplan
Oct 25, 2010, 3:05:19 PM10/25/10
to openwon...@googlegroups.com
This image shows a thread that is part of an Executor. The thread must be started by a module, presumably with a call to one of the methods in Executors (like the executor we added to AvatarImiJME, although hopefully that one gets cleaned up). Maybe if you explore further up the chain in the ThreadPoolExecutor$Worker link, it will say which executor it is part of? If not, we may need to do a global search of modules for all executors, and check whether they are getting shut down properly (I bet most aren't).
Morris Ford
Oct 25, 2010, 6:52:36 PM10/25/10
to openwon...@googlegroups.com
I put a call to App2D.shutdown() in AppClientPlugin.cleanup(). That was easier than listening for the session close. Shuts the App2D stuff down now at logout. Time will tell if that issue is fully resolved.
I tried unsuccessfully to find out more about the Executor for the other problem. I have the heapdump file if you want to look at it. I went looking for anyone else that is using Executor to see if they are shut down correctly. I found about 10 including the Imi avatar code that use it. Of the ones I have looked at, the Imi code is the only one that shuts off the executor. Problem is that most do not have a straight forward structure for performing shutdown/cleanup actions. I guess that will be a work in progress for a while.
I'm beginning to think that it would be a lot easier to just remove the JmeClientMain and start over with a new one when attempting to portal.
Morris
Jonathan Kaplan
Oct 25, 2010, 8:00:32 PM10/25/10
to openwon...@googlegroups.com
If you can send me the heap file via yousendit or similar, I'm happy to take a look. I agree about shutting down the executors -- it is a slog, but an important part of the cleanup (otherwise we will leak threads in addition to memory). Another thing we may want to look into is combining executors. It would make cleanup much easier if we had a single, system wide thread pool that was used by all these modules. As long as the modules are only submitting short tasks, I can't see any reason to have separate thread pools for each module.
One thing that might be useful at this point is to create a branch for your memory changes. That way you could share the changes easily, and we don't have to worry about a bunch of work getting lost. It also makes it easy to find all the changes you have made. If you are interested, I'll create the branch and send instructions.
Morris Ford
Oct 25, 2010, 8:17:47 PM10/25/10
to openwon...@googlegroups.com
Jonathan,
I would think that having a single Executor thread group would be the right thing to do. I would greatly prefer to do that as to have to fiddle with shutdown in a bunch of places. I will send the heapdump tomorrow if you still want it. If I'm going to fix all the executor instances it amy not be necessary. A couple of questions:
Where would the thread group live?
How would it be referenced?
I think a branch sounds like a good idea. I am currently at 4541 of trunk. I have been reluctant to update with all these changes in progress.
Morris
Morris
Morris Ford
Oct 26, 2010, 10:58:54 AM10/26/10
to openwon...@googlegroups.com
Jonathan,
I have added to ClientContext.java:
private static ExecutorService executor = null;
and
public static ExecutorService getGlobalExecutor() {
if(executor == null || executor.isShutdown())
executor = Executors.newCachedThreadPool();
return executor;
}
I then implemented this global executor in the Imi code that we modified before. It is working ok.
Also, I added to JmeClientMain in logout:
ClientContext.getGlobalExecutor().shutdownNow();
Do you think that is good enough to go ahead and implement everywhere else?
Morris
Jonathan Kaplan
Oct 26, 2010, 1:39:36 PM10/26/10
to openwon...@googlegroups.com
The ClientContext is the right place to put the executor. I think it needs a bit more synchronization, but that's a minor detail.
The question of what to do on logout is a little different. If there is only one system-wide thread pool, it shouldn't be shut down on logout of a particular server, since core tasks that are not server-dependent may need the pool. Assuming all tasks execute in a reasonable amount of time, not shutting down the executor shouldn't cause any memory problems, since memory will be freed once the tasks from a given module complete. We could presumably extend the Executor to take into account the code source of a task, and reject tasks from closed sessions, but that is probably not worthwhile.
One other thing to double check is that executors set the AccessControlContext as we expect. If a module thread schedules a task and there are no available executor threads, a new thread will be created. We have to make sure the executor thread's AccessControlContext is based on the system context, and not the context inherited from the module thread.
Jonathan Kaplan
Oct 26, 2010, 1:41:45 PM10/26/10
to openwon...@googlegroups.com
The branch has been created. To use it:
1. back up your workspace
2. in the wonderland/ directory, execute "svn switch https://openwonderland.googlecode.com/svn/branches/morrisford/teleport"
3. use "svn info" to double check that your workspace is now parented to the branch
4. commit your changes to the branch
The branch is based on rev 4541 of trunk, so there shouldn't be any conflicts when you switch.
Morris Ford
Oct 26, 2010, 2:50:19 PM10/26/10
to openwon...@googlegroups.com
Great. I'll get my workspace committed later.
I assume that setting the AccessControlContext implies getting the global executor allocated on the JmeClientMain.main thread. Is having the ClientContext allocate the executor sufficient or should I allocate it explicitly from JmeClientMain.main? I was struggling with exactly when ClientContext is instantiated in relation to explicitly allocating from main. I will remove the shutdownNow and remove the allocation stuff from the getGlobalExecutor. I will go ahead and start changing over to the global executor everywhere.
Morris
Morris Ford
Oct 26, 2010, 3:24:07 PM10/26/10
to openwon...@googlegroups.com
Question:
CellChannelConnection.java and Throttle.java both use Scheduled executors. Should I create a second global executor or change the scheduled ones to the other type?
Morris
Jonathan Kaplan
Oct 26, 2010, 3:43:49 PM10/26/10
to openwon...@googlegroups.com
I think ScheduledExecutorService is a superset of ExecutorService, so if you change the type of getGlobalExecutor() to a ScheduledExecutorService, you should be able to use it for CellChannelConnection and Throttle.
I'm honestly not sure of the behavior of the executor with respect to AccessControlContext. I would expect the threads created by the executor to all have the AccessControlContext associated with the thread that created the executor. In the case of the ClientContext's static initializer, this will definitely be a system thread. But it is possible that as new threads are spawned by the executor, they have different AccessControlContexts. We should be able to construct a quick experiment to determine if that is the case.
Morris Ford
Oct 26, 2010, 7:28:48 PM10/26/10
to openwon...@googlegroups.com
I set up two globalExecutors (one scheduled) to proceed with changing the various users and it tests ok. I'll proceed with changing to a single one tomorrow.
I am seeing uncaught exceptions coming out of the App2d's with the shutdown via the plugin. It took me a while to figure out that the shutdown was causing the exceptions. Apparently, there is still something still going on after the shutdown or something in the shutdown is causing it. But, this provokes a question about how far 'down' should the shutdown drive the modules. It appears that the current code is bringing the modules right down. My question is what is going to get them back up if JmeClientMain doesn't execute again?
Morris
Jonathan Kaplan
Oct 27, 2010, 11:52:09 AM10/27/10
to openwon...@googlegroups.com
The Wonderland initialization happens in two phases: first the core classes (like JmeClientMain) initialize, and then we load a server and all the corresponding modules. The modules are all initialized when they are loaded into the module classloader during the second phase. For example in the case of App2D, when the appbase module is loaded, the static initializer in the App2D class is executed to recreate the invoker thread. For other modules, the initialize() method of the ClientPlugin is called to set them up.
Since the second phase is repeated whenever we connect to a server, the modules should be reinitialized properly. If we succeed in getting rid of all the stray references, when we go to connect to a second server, we will be in exactly the same state we were in at the end of the first phase during the initial startup.
Morris Ford
Oct 27, 2010, 12:13:53 PM10/27/10
to openwon...@googlegroups.com
Aha. Now I understand better. Thanks.
Morris Ford
Oct 27, 2010, 1:00:23 PM10/27/10
to openwon...@googlegroups.com
Jonathan,
I am currently running with the App2D shutdown enabled. I still get uncaught exceptions on shutdown but I was just trying teleporting between two worlds here and it is actually working. I am going from a 'gardens' world with a few objects to a 'gardens' world with a number of objects. I get the feeling we may actually be making progress but I really don't understand why as I am still finding GCRoots.
After making everything on client side that I can find use the global executors, I am still getting a GCRoot that indicates an Executor thread issue. How do I run down who is causing that? Or do you want to look at the heap dump?
Morris
Morris Ford
Oct 27, 2010, 1:48:49 PM10/27/10
to openwon...@googlegroups.com
The switch didn't go right. Console:
muffin:trunk-20100321 morrisford$ cd wonderland
muffin:wonderland morrisford$ svn switch https://openwonderland.googlecode.com/svn/branches/morrisford/teleport
is not the same repository as
muffin:wonderland morrisford$ svn info
Path: .
Repository Root: http://openwonderland.googlecode.com/svn
Repository UUID: d1a7cd20-233f-11df-bff0-d338b04bc40e
Revision: 4541
Node Kind: directory
Schedule: normal
Last Changed Author: jonathankap
Last Changed Rev: 4541
Last Changed Date: 2010-10-04 17:05:59 -0400 (Mon, 04 Oct 2010)
muffin:wonderland morrisford$ svn switch http://openwonderland.googlecode.com/svn/branches/morrisford/teleport
At revision 4556.
muffin:wonderland morrisford$
muffin:wonderland morrisford$
muffin:wonderland morrisford$
muffin:wonderland morrisford$ svn info
Path: .
Repository Root: http://openwonderland.googlecode.com/svn
Repository UUID: d1a7cd20-233f-11df-bff0-d338b04bc40e
Revision: 4556
Node Kind: directory
Schedule: normal
Last Changed Author: jonathankap
Last Changed Rev: 4556
Last Changed Date: 2010-10-26 12:06:13 -0400 (Tue, 26 Oct 2010)
muffin:wonderland morrisford$ svn commit
svn: Commit failed (details follow):
svn: Server sent unexpected return value (405 Method Not Allowed) in response to MKACTIVITY request for '/svn/!svn/act/ec5fdca9-0da8-4858-9b71-e1fb1941d590'
svn: Your commit message was left in a temporary file:
svn: '/Users/morrisford/trunk-20100321/wonderland/svn-commit.tmp'
muffin:wonderland morrisford$
Jonathan Kaplan
Oct 27, 2010, 2:05:51 PM10/27/10
to openwon...@googlegroups.com
Morris,
You have to have the directory checked out for writing with https. To switch, you can use:
svn switch --relocate http://openwonderland.googlecode.com/svn/branches/morrisford/teleport https://openwonderland.googlecode.com/svn/branches/morrisford/teleport
Morris Ford
Oct 27, 2010, 2:14:16 PM10/27/10
to openwon...@googlegroups.com
Maybe I'm not authorized?
muffin:wonderland morrisford$ svn commit
Authentication realm: <https://openwonderland.googlecode.com:443> Google Code Subversion Repository
Password for 'morrisford':
svn: Commit failed (details follow):
svn: Server sent unexpected return value (500 Internal Server Error) in response to MKACTIVITY request for '/svn/!svn/act/975d47c6-67b6-4e56-82a7-84acaf917e26'
svn: Your commit message was left in a temporary file:
svn: '/Users/morrisford/trunk-20100321/wonderland/svn-commit.3.tmp'
Jonathan Kaplan
Oct 27, 2010, 2:24:38 PM10/27/10
to openwon...@googlegroups.com
Sure enough. You are authorized now.
Morris Ford
Oct 27, 2010, 2:31:44 PM10/27/10
to openwon...@googlegroups.com
Same error.
Jonathan Kaplan
Oct 27, 2010, 2:37:33 PM10/27/10
to openwon...@googlegroups.com
It want "morrishford" as the username, and the googlecode.com password that you can get from the web site. You can add "--username morrishford" to the command line if it defaults to something else.
Morris Ford
Oct 27, 2010, 3:04:12 PM10/27/10
to openwon...@googlegroups.com
I give up. I have tried every combination of logins and passwords.
Jonathan Kaplan
Oct 28, 2010, 1:13:42 PM10/28/10
to openwon...@googlegroups.com
With a bit of poking around I found some indications of where the executor is that is causing the GCRoot that I can't find. Looks like it might be avatar related?? I attached two screen shots. See anything there useful?
Needless to say, the thread pools never get cleaned up. Fortunately the repository is managed in OWL code:
There are two options for dealing with this: we could fix the Repository class to have a shutdown method which we call from AvatarClientPlugin, or we could refactor the Repository so that we could override the thread pools with our own pools. I think the first option would be easier, but the second would get us closer to our goal of a single thread pool on the client. My only concern is that they use the maximum size of the loader pool to control concurrency, while I'm assuming our single pool doesn't have concurrency controls.
Morris Ford
Nov 3, 2010, 3:34:08 PM11/3/10
to openwon...@googlegroups.com
I took option 1 for the Repository. I added a cleanup method that does shutdownNow to both ExecutorService.
Next: In HeaderPanelAllocator was this code:
public void run () {
// This thread runs forever
while (true) {
if (headers.size() < SIZE) {
HeaderPanel header = createHeader();
try {
headers.put(header);
} catch (InterruptedException ex) {
}
}
try {
Thread.sleep(1000);
} catch (InterruptedException ex) {
}
}
}
Looks like an attempt to resolve some issue. I don't know what the problem was. In order to get rid of that hanging thread, I took out the while to make the run go once. Whatever the reason for the forever loop will have to be found and resolved some other way.
On to the next GCRoot.
Morris
Jonathan Kaplan
Nov 3, 2010, 7:18:57 PM11/3/10
to openwon...@googlegroups.com
Morris,
The problem had to do with a deadlock when allocating window headers using SwingUtilities.invokeAndWait(). Here is a version that uses an executor instead -- you can convert it to use the global executor in your branch.
Can you send the diff to Repository? Assuming it just adds the shutdown method, I'll check it in to the avatars project.
Morris Ford
Nov 3, 2010, 7:58:25 PM11/3/10
to openwon...@googlegroups.com
Thanks. Will do tomorrow.
Morris
Morris Ford
Nov 5, 2010, 12:25:38 PM11/5/10
to openwon...@googlegroups.com
Jonathan,
The change to Repository.java is these lines that I put at the bottom of the class:
public void cleanup()
{
genericThreadService.shutdownNow();
loaderService.shutdownNow();
}
Morris
Morris Ford
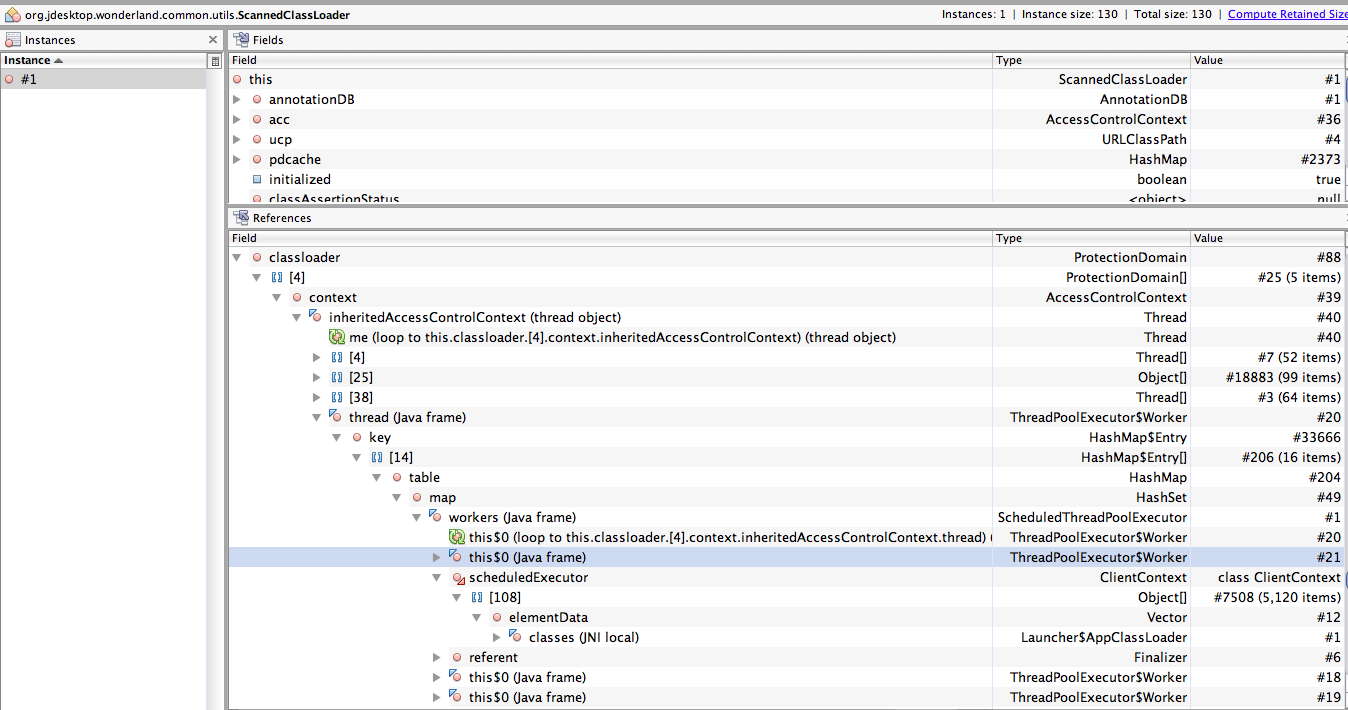
Nov 8, 2010, 8:57:55 AM11/8/10
to openwon...@googlegroups.com
Jonathan,
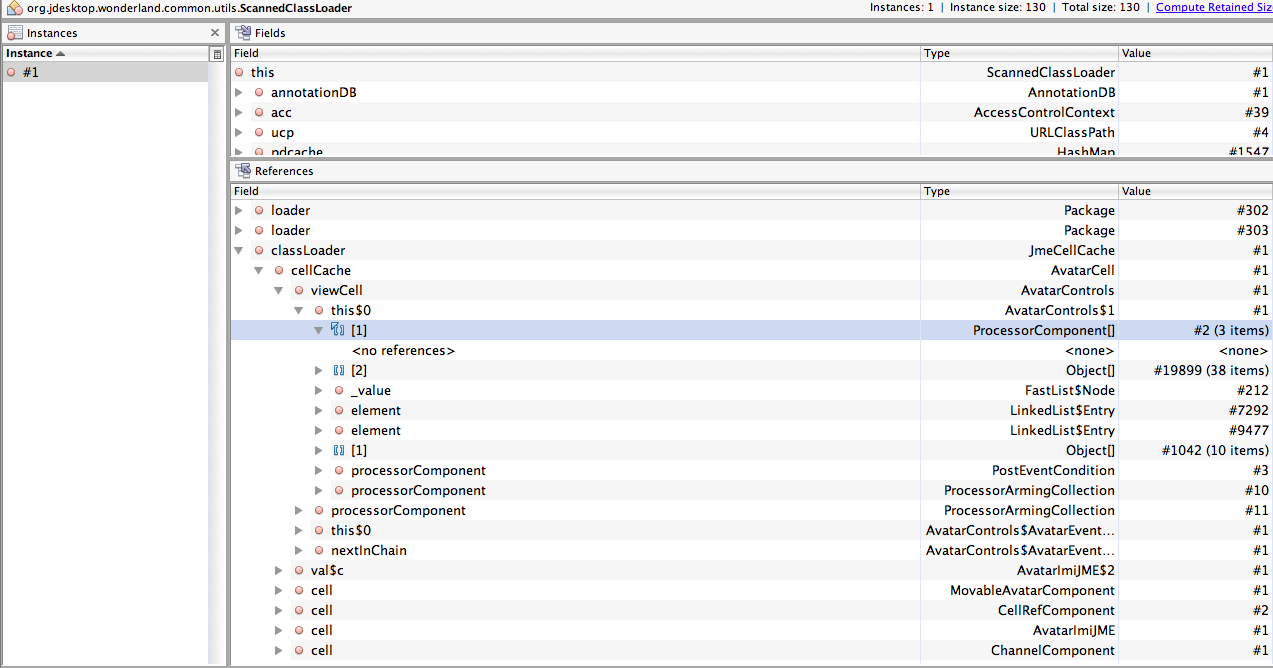
Working on chasing down the next problems. I am getting a type of GCRoot that makes me think that putting the Executors in ClientContext is not doing what we want. Note that there are at the moment two ClientContext based Executors, cached and scheduled. See that attached.
Morris
{kind=link}
{kind=link}
Jonathan Kaplan
Nov 8, 2010, 11:45:30 AM11/8/10
to openwon...@googlegroups.com
Morris,
I agree with your assessment. Try creating the thread pools using a privilegedThreadFactory, something like:
Executors.newScheduledThreadPool(4, Executors.privilegedThreadFactory());
And see if that makes a difference. I can't tell from the documentation whether this will work or not, since it depends on how AccessControlContexts hold on to references internally.
Morris Ford
Nov 8, 2010, 1:55:38 PM11/8/10
to openwon...@googlegroups.com
Complains about that:
Exception in thread "main" java.lang.ExceptionInInitializerError
[java] at org.jdesktop.wonderland.client.assetmgr.AssetDB.setDBSystemDir(AssetDB.java:350)
[java] at org.jdesktop.wonderland.client.assetmgr.AssetDB.<init>(AssetDB.java:97)
[java] at org.jdesktop.wonderland.client.jme.JmeClientMain.checkDBException(JmeClientMain.java:831)
[java] at org.jdesktop.wonderland.client.jme.JmeClientMain.<init>(JmeClientMain.java:171)
[java] at org.jdesktop.wonderland.client.jme.JmeClientMain.main(JmeClientMain.java:640)
[java] Caused by: java.security.AccessControlException: access denied (java.lang.RuntimePermission setContextClassLoader)
[java] at java.security.AccessControlContext.checkPermission(AccessControlContext.java:323)
[java] at java.util.concurrent.Executors$PrivilegedThreadFactory.<init>(Executors.java:564)
[java] at java.util.concurrent.Executors.privilegedThreadFactory(Executors.java:323)
[java] at org.jdesktop.wonderland.client.ClientContext.<clinit>(ClientContext.java:56)
Jonathan Kaplan
Nov 8, 2010, 6:37:02 PM11/8/10
to openwon...@googlegroups.com
Morris,
static class ExecutorThreadFactory implements ThreadFactory {
private static final String namePrefix = "wonderlandpool-thread-";
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final ClassLoader ccl;
private final AccessControlContext acc;
public Thread newThread(final Runnable r) {
return createThread(new Runnable() {
public void run() {
AccessController.doPrivileged(new PrivilegedAction<Object>() {
public Object run() {
Thread.currentThread().setContextClassLoader(ccl);
r.run();
return null;
}
}, acc);
}
});
}
There is a strange check in the PrivilegedThreadFactory constructor that prevents it from working in a static initializer. I'm not sure why the check is where it is -- it seems like they could do a lazy check instead, and that would work more of the time. Below is a version of the ThreadFactory that avoids this check (and names the threads better). Try that out and see if it avoids the original problem with the reference in AccessControlContext.
private static final String namePrefix = "wonderlandpool-thread-";
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final ClassLoader ccl;
private final AccessControlContext acc;
ExecutorThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null)? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
ccl = Thread.currentThread().getContextClassLoader();
acc = AccessController.getContext();
}
public Thread newThread(final Runnable r) {
return createThread(new Runnable() {
public void run() {
AccessController.doPrivileged(new PrivilegedAction<Object>() {
public Object run() {
Thread.currentThread().setContextClassLoader(ccl);
r.run();
return null;
}
}, acc);
}
});
}
private Thread createThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
Morris Ford
Nov 10, 2010, 3:50:26 PM11/10/10
to openwon...@googlegroups.com
First tests after adding that code is showing a different error. I will start looking at that one and if this one pops up again I'll let you know.
Morris
Morris Ford
Nov 10, 2010, 7:20:01 PM11/10/10
to openwon...@googlegroups.com
Jonathan,
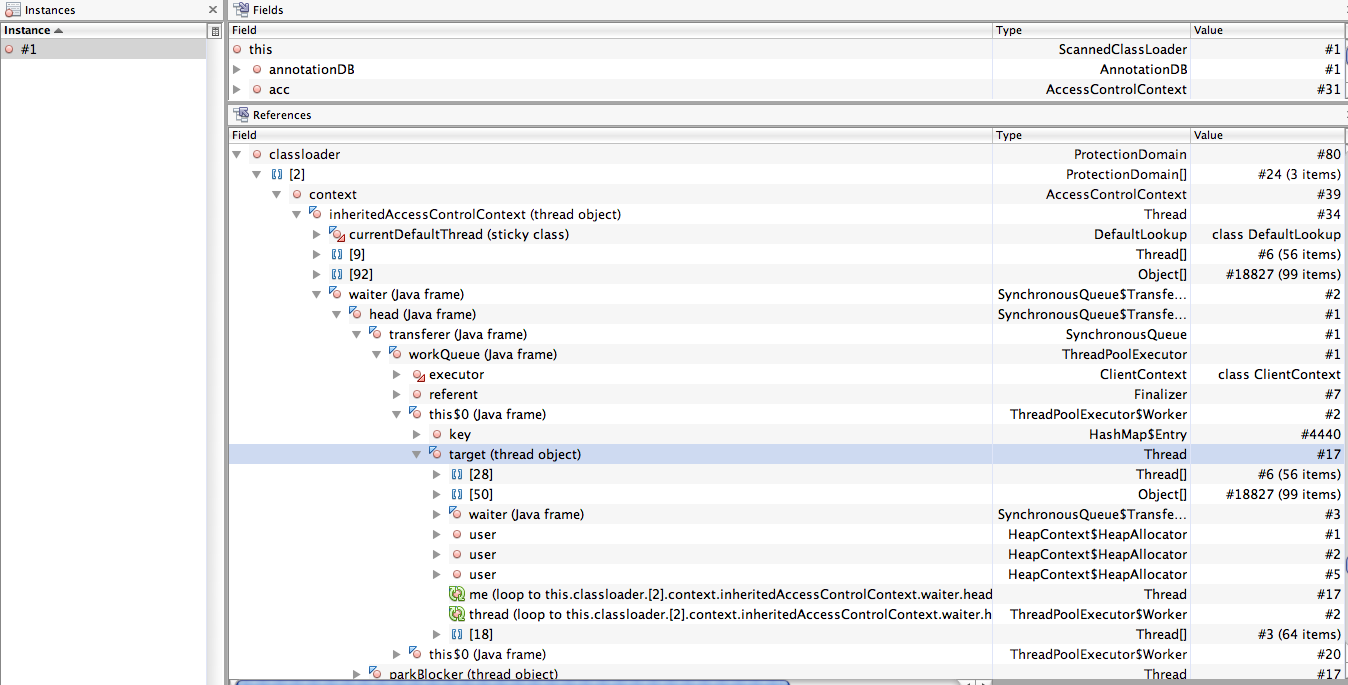
The next one appears to be the first non-thread related one. It looks like AvatarControls is holding onto a ProcessorArmingCollection out of ProcessorComponent. As far as I can tell the collection is nothing but null references so I assume releasing the collection would be in order or dropping the chain of classes down to AvatarControls. Is that reasonable? Attached is the screenshot.
Morris
{kind=link}
Jonathan Kaplan
Nov 10, 2010, 7:49:45 PM11/10/10
to openwon...@googlegroups.com
I think it's the other way around: the MT-Game processor system is holding on to a reference to a Processor which is defined in AvatarControls. Specifically, I think the problem is at line 70 of AvatarControls, where it creates a global event listener which is never released:
ClientContext.getInputManager().addGlobalEventListener(new EventClassListener() {
If you trace it back, event listeners actually descend from ProcessorComponent, and are managed in the system by the MT-Game processor manager. In any case, this listener should be treated like the existing AvatarEventListener, which is properly added and removed during the call to setEnabled().
While you are at it, this is probably a good time to update the branch with the latest fixes.
{kind=link}
Jonathan Kaplan
Nov 11, 2010, 2:38:48 PM11/11/10
to openwon...@googlegroups.com
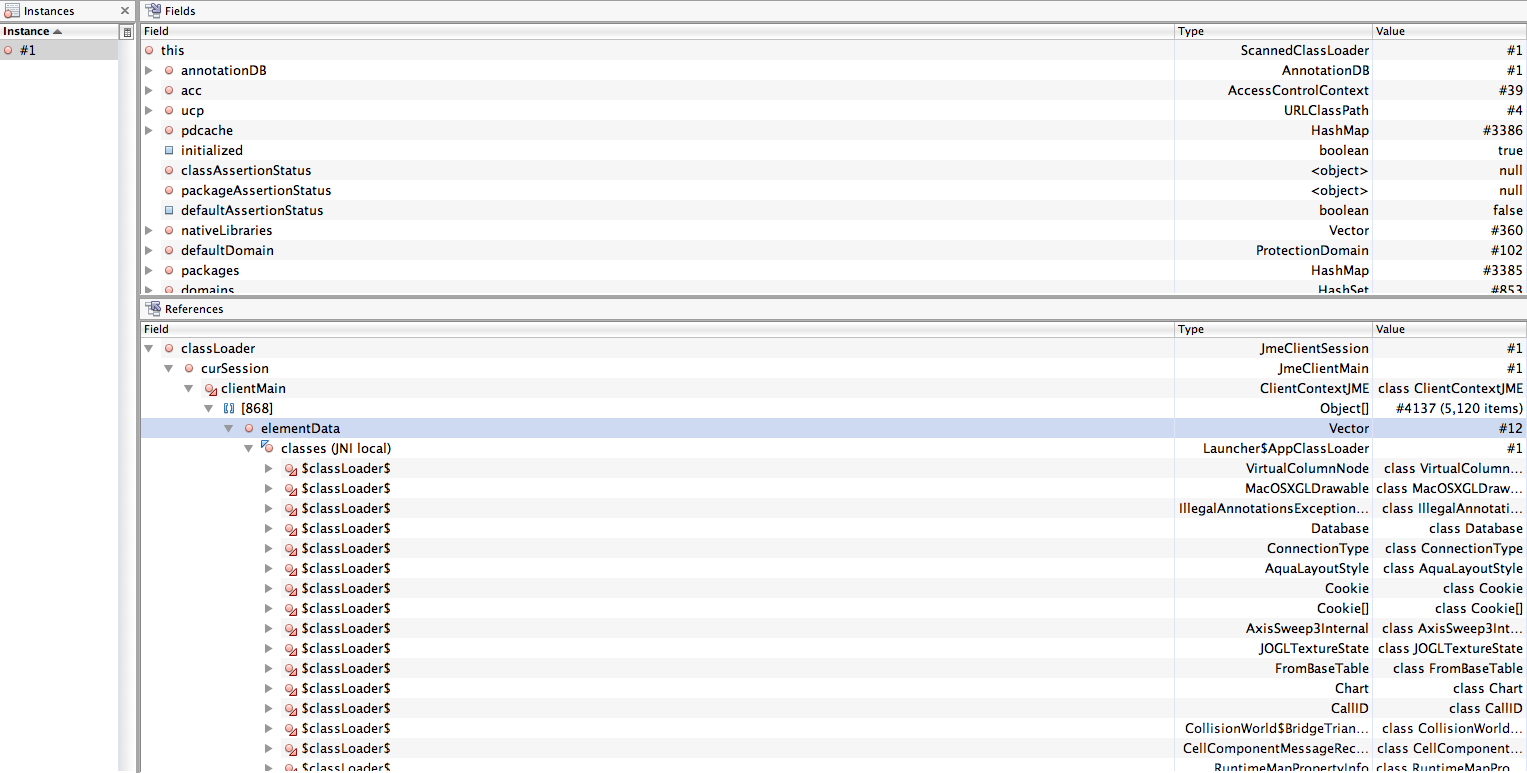
Morris,
That looks like data in the app classloader (which should never be unloaded). Was the ScannedClassLoader still loaded at that point? Was this part of a path to it? It looks like a path to the system class loader.
We will know we have reached the end when the ScannedClassLoader instance is gone. I think we must be getting close at this point :-)
Morris Ford
Nov 11, 2010, 3:03:33 PM11/11/10
to openwon...@googlegroups.com
This was under the ScannedClassLoader as before. It sure would be nice to get to the end, although, it has really been an adventure.
Morris
Jonathan Kaplan
Nov 11, 2010, 3:16:26 PM11/11/10
to openwon...@googlegroups.com
Does that mean that the classloader for JmeClientSession is set to the ScannedClassLoader? I wouldn't expect that -- I would expect the JmeClientSession's classloader to be the system classloader.
Morris Ford
Nov 11, 2010, 3:59:00 PM11/11/10
to openwon...@googlegroups.com
Definitely coming into the constructor of JmeClientSession with ScannedClassLoader. After a quick look around I couldn't figure out where it is coming from. Do you know where it comes from? Or should I keep chasing it down?
Morris
Morris Ford
Nov 11, 2010, 4:19:12 PM11/11/10
to openwon...@googlegroups.com
Looks like 716 in ServerSessionManager.
Jonathan Kaplan
Nov 11, 2010, 4:27:55 PM11/11/10
to openwon...@googlegroups.com
Oh, that's a real reference, not an implicit one. It is expected the the session holds a reference to the session classloader. On logout, we should remove all references to the session. It looks like some of that got commented out in your branch:
Was it breaking things to call curSession.logout()? In any case, setting curSession to null should break that particular chain. Hopefully there aren't too many other references to the JmeClientSession.
Morris Ford
Nov 11, 2010, 4:36:58 PM11/11/10
to openwon...@googlegroups.com
What happened was that setting that session to null was causing problems in disconnect in ServerSessionManager because disconnect runs through all sessions and does session.logout() and it would hit the session that was already null. I think I overlooked nulling the sessions in disconnect. I'll add a session = null there and see what happens. More later.
Morris
Morris Ford
Nov 11, 2010, 4:52:20 PM11/11/10
to openwon...@googlegroups.com
That one disappeared. Next one is a ProcessorThread again.
Morris
Morris Ford
Nov 11, 2010, 5:08:03 PM11/11/10
to openwon...@googlegroups.com
Ok on that one. Moving on.
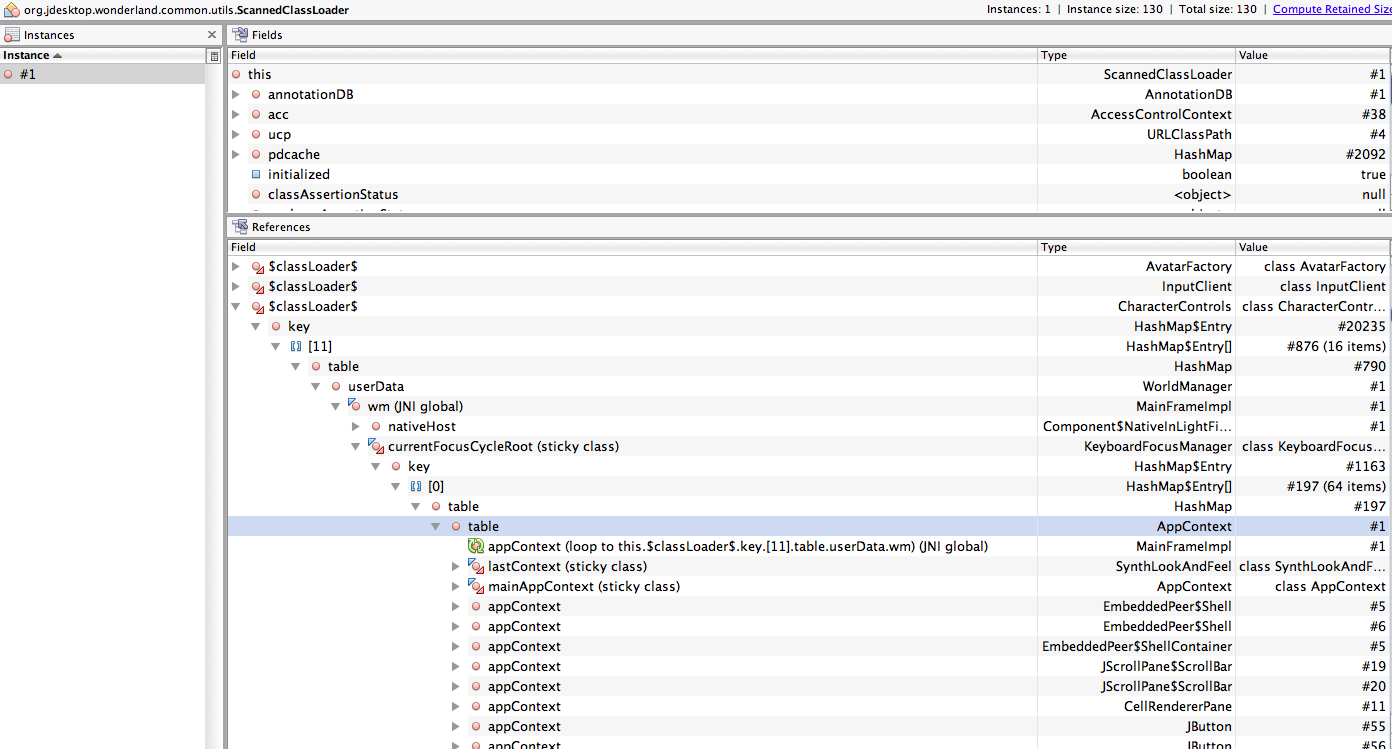{kind=link}
Jonathan Kaplan
Dec 6, 2010, 12:31:22 PM12/6/10
to openwon...@googlegroups.com
Morris,
Welcome back! It looks like that is the CharacterControls, which are getting added in the imi code here:
I'm a little confused about the Wonderland side. It looks like the controls are created in two places:
In either case, I think it is safe to clean this up by adding code to AvatarControls.setEnabled(false) to call:
WorldManager.removeUserData(CharacterControls.class);
It would be slightly cleaner to add a cleanup method in DefaultCharacterControls, and call that from AvatarControls, but it is fine either way. Looking through the IMI code, I see a few other things like InputManagerEntity that are added to the WorldManager, so there may be a few of these lurking around.
Morris Ford
Dec 6, 2010, 1:52:17 PM12/6/10
to openwon...@googlegroups.com
Ok. I put that fix in. Here is another one. For right now I am going to take less time trying to figure out the errors in lieu of speeding up the cycles. I hope you don't mind.
Morris
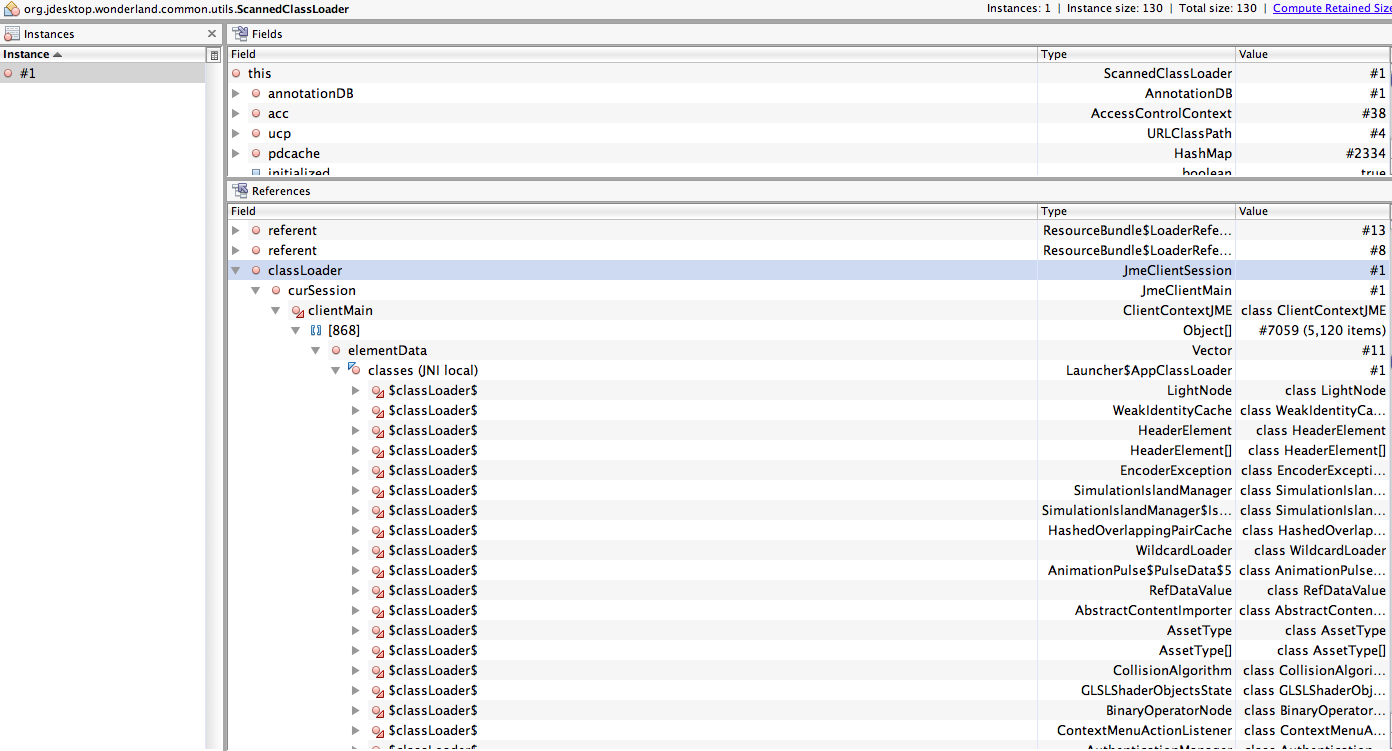{kind=link}
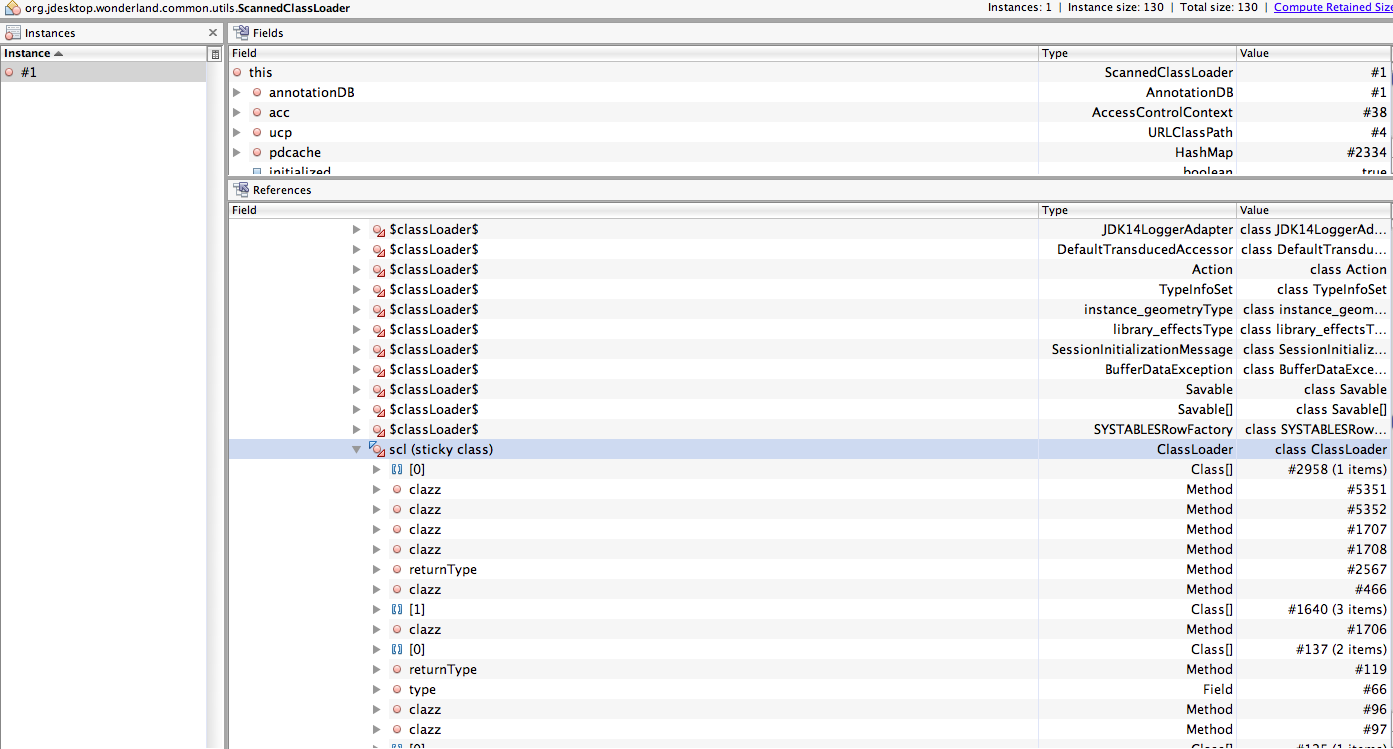{kind=link}
It is loading more messages.
0 new messages