Replace formulas by Pairs?
399 views
Skip to first unread message

Douglas Bates
Feb 1, 2016, 4:18:46 PM2/1/16
to julia-stats
The current formula interface for packages like GLM and MixedModels emulates that of R in that a formula is written like
y ~ 1 + x + z
The difficulty with this form is that the ~ character is used elsewhere in Julia so somewhat nasty tricks need to be used to parse such an expression as a formula.
One way to break away from this R-centric approach is to use a Pair to represent a formula. Because we don't want to evaluate the expressions in a formula at function call it would be necessary to use Pair(Symbol,Expr) or Pair(Expr,Expr) to represent a two-sided formula. The translation of the previous formula would be
:y => :(1 + x + z)
This requires a few extra keystrokes but is not a terrible burden and it would use a native Julia construct. It also serves to visually distinguish a formula in Julia from a formula in R so that we can make other changes in the formula language (e.g. require an explicit 1 for the intercept term) with less confusion for users. Because a formula in Julia looks different from a formula in R it is less confusing that other aspects of the formula syntax are different in Julia and in R.

Milan Bouchet-Valat
Feb 2, 2016, 9:30:21 AM2/2/16
to julia...@googlegroups.com
Using Pairs (and therefore =>) sounds like a good idea to me, as it
conveys exactly the meaning of associating two parts of a formula
together, in a structure designed for that. (Well, the direction of the
arrow isn't very natural, but...)
But maybe to make it nicer to read we could make the whole formula an
expression, i.e.:
:(y => 1 + x + z)
instead of:
a model:
@fit(LinearModel, y => 1 + x + z, data)
(Such a macro, while not strictly necessary, could also allow saving
the full call expression and the name of the dataset used when fitting
the model, to print it to the user as R does.)
Maybe more importantly, it would remove the requirement for the left
hand-side of the formula to be a symbol. Indeed, some models (like PLS
regression) accept several dependent variables, which could be written
like this:
:(y + z => 1 + x)
My two cents
> --
> You received this message because you are subscribed to the Google
> Groups "julia-stats" group.
> To unsubscribe from this group and stop receiving emails from it,
> send an email to julia-stats...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
conveys exactly the meaning of associating two parts of a formula
together, in a structure designed for that. (Well, the direction of the
arrow isn't very natural, but...)
But maybe to make it nicer to read we could make the whole formula an
expression, i.e.:
:(y => 1 + x + z)
instead of:
:y => :(1 + x + z)
That would make the syntax very close to what macros would allow to fit
a model:
@fit(LinearModel, y => 1 + x + z, data)
(Such a macro, while not strictly necessary, could also allow saving
the full call expression and the name of the dataset used when fitting
the model, to print it to the user as R does.)
Maybe more importantly, it would remove the requirement for the left
hand-side of the formula to be a symbol. Indeed, some models (like PLS
regression) accept several dependent variables, which could be written
like this:
:(y + z => 1 + x)
My two cents
> You received this message because you are subscribed to the Google
> Groups "julia-stats" group.
> To unsubscribe from this group and stop receiving emails from it,
> send an email to julia-stats...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
Milan Bouchet-Valat
Feb 2, 2016, 10:16:46 AM2/2/16
to julia...@googlegroups.com
Le mardi 02 février 2016 à 15:30 +0100, Milan Bouchet-Valat a écrit :
> Using Pairs (and therefore =>) sounds like a good idea to me, as it
> conveys exactly the meaning of associating two parts of a formula
> together, in a structure designed for that. (Well, the direction of the
> arrow isn't very natural, but...)
>
> But maybe to make it nicer to read we could make the whole formula an
> expression, i.e.:
> :(y => 1 + x + z)
>
> instead of:
> :y => :(1 + x + z)
>
>
> That would make the syntax very close to what macros would allow to fit
> a model:
> @fit(LinearModel, y => 1 + x + z, data)
>
> (Such a macro, while not strictly necessary, could also allow saving
> the full call expression and the name of the dataset used when fitting
> the model, to print it to the user as R does.)
>
>
> Maybe more importantly, it would remove the requirement for the left
> hand-side of the formula to be a symbol. Indeed, some models (like PLS
> regression) accept several dependent variables, which could be written
> like this:
> :(y + z => 1 + x)
Actually, scratch that, as the two features are orthogonal.
> Using Pairs (and therefore =>) sounds like a good idea to me, as it
> conveys exactly the meaning of associating two parts of a formula
> together, in a structure designed for that. (Well, the direction of the
> arrow isn't very natural, but...)
>
> But maybe to make it nicer to read we could make the whole formula an
> expression, i.e.:
> :(y => 1 + x + z)
>
> instead of:
> :y => :(1 + x + z)
>
>
> That would make the syntax very close to what macros would allow to fit
> a model:
> @fit(LinearModel, y => 1 + x + z, data)
>
> (Such a macro, while not strictly necessary, could also allow saving
> the full call expression and the name of the dataset used when fitting
> the model, to print it to the user as R does.)
>
>
> Maybe more importantly, it would remove the requirement for the left
> hand-side of the formula to be a symbol. Indeed, some models (like PLS
> regression) accept several dependent variables, which could be written
> like this:
> :(y + z => 1 + x)
:(y => 1 + x + z) and :y => :(1 + x + z) both have Symbol as the type
for the LHS. The only difference is whether we have a Pair of
expressions/symbols or a => call with two expression/symbol arguments.
Yet it might be a bit nicer to write
:(y + z => 1 + x)
rather than
:(y + z) => :(1 + x)

Stefan Karpinski
Feb 2, 2016, 10:51:07 AM2/2/16
to julia-stats
I don't have a strong feeling about `~` versus `=>` – although the R tradition of using `~` seems to at least give a hint about what's going on, which is kind of nice. But I do think that it would be good to get rid of the macro business for ~ and start spelling model specifications as `@model y ~ 1 + x + z` or `@model y => 1 + x + z` and returning some kind of Model type instead of using bare expression objects for this kind of thing. Expression objects already have a meaning in Julia code and it is not to specify statistical models – it is to represent Julia expression trees. The fact that those two meanings can usually be disambiguated easily doesn't mean they should be represented the same way.
Milan Bouchet-Valat
Feb 2, 2016, 11:30:27 AM2/2/16
to julia...@googlegroups.com
Le mardi 02 février 2016 à 10:50 -0500, Stefan Karpinski a écrit :
> I don't have a strong feeling about `~` versus `=>` – although the R
> tradition of using `~` seems to at least give a hint about what's
> going on, which is kind of nice. But I do think that it would be good
> to get rid of the macro business for ~ and start spelling model
> specifications as `@model y ~ 1 + x + z` or `@model y => 1 + x + z`
> and returning some kind of Model type instead of using bare
> expression objects for this kind of thing. Expression objects already
> have a meaning in Julia code and it is not to specify statistical
> models – it is to represent Julia expression trees. The fact that
> those two meanings can usually be disambiguated easily doesn't mean
> they should be represented the same way.
That would be a Formula type, rather than a Model (a model includes
> I don't have a strong feeling about `~` versus `=>` – although the R
> tradition of using `~` seems to at least give a hint about what's
> going on, which is kind of nice. But I do think that it would be good
> to get rid of the macro business for ~ and start spelling model
> specifications as `@model y ~ 1 + x + z` or `@model y => 1 + x + z`
> and returning some kind of Model type instead of using bare
> expression objects for this kind of thing. Expression objects already
> have a meaning in Julia code and it is not to specify statistical
> models – it is to represent Julia expression trees. The fact that
> those two meanings can usually be disambiguated easily doesn't mean
> they should be represented the same way.
other details like a link function, and error distribution, etc.).
We could imagine two interfaces:
- @formula(y ~ 1 + x + z) would create a Formula object, which could be
passed to fit(), etc.
- @fit(ModelType, y ~ 1 + x + z, ...) would be a shorthand for
fit(ModelType, @formula(y ~ 1 + x + z), ...)
At that point, the choice of ~ or => doesn't make much of a difference
technically, so we may as well keep ~.

jock....@gmail.com
Feb 2, 2016, 4:46:01 PM2/2/16
to julia-stats
Without considering the technical implications, how about something like E(y | 1 + x + z)?
This is mathematically correct for GLMs, but not when modelling the median via quantile regression for example.
Perhaps @median(y | 1 + x + z) for quantile regression and @mean(y | 1 + x + z) for GLMs?
This is mathematically correct for GLMs, but not when modelling the median via quantile regression for example.
Perhaps @median(y | 1 + x + z) for quantile regression and @mean(y | 1 + x + z) for GLMs?
Milan Bouchet-Valat
Feb 2, 2016, 5:25:17 PM2/2/16
to julia...@googlegroups.com
Le mardi 02 février 2016 à 13:46 -0800, jock....@gmail.com a écrit :
> Without considering the technical implications, how about something
> like E(y | 1 + x + z)?
I think the point is mostly about "technical implications". :-)
> Without considering the technical implications, how about something
> like E(y | 1 + x + z)?
The R convention of using ~ works quite well, so there should be a strong reason to invent something else (e.g. consistency with Julia parsing).
> This is mathematically correct for GLMs, but not when modelling the
> median via quantile regression for example.
> Perhaps @median(y | 1 + x + z) for quantile regression and @mean(y |
> 1 + x + z) for GLMs?
specifying formulas? Currently, the type of model you fit defines
whether the formula describes e.g. the mean, the median, or something
else. Repeating this when creating the formula doesn't add anything
AFAICT, as you cannot fit e.g. a GLM for the median anyways.
That said, we could think about how we could support other kinds of
models like survival models, where the LHS of the formula must take a
time to event and a censoring status, or the start and end of a period
and its censoring status. In R, these are supported by pseudo-functions
in the formula, like this:
Surv(start, stop, event) ~ 1 + x
Maybe that's OK, but maybe we can find something better. A bit off-
topic though.
Regards
jock....@gmail.com
Feb 2, 2016, 5:43:10 PM2/2/16
to julia-stats
True, the approach I suggested conflates formula and model, and indeed repeating the intended model adds nothing.
The main point is that from a modelling point of view (not a parsing point of view) we are considering the dependence of y on x, z, etc.
In probabilistic syntax this is represented generally as Pr(y | x, z), from which a GLM can be expressed as E(y | x, z).
I was merely trying to use this mathematical representation, and use formula-like syntax to remove any ambiguity about the form of the RHS.
I'm not claiming this particular representation is the way to go. Rather, I think this idea merits further brainstorming. E.g., :(y | 1 + x + z).
Put another way, go with convention or explore possible improvements?
The main point is that from a modelling point of view (not a parsing point of view) we are considering the dependence of y on x, z, etc.
In probabilistic syntax this is represented generally as Pr(y | x, z), from which a GLM can be expressed as E(y | x, z).
I was merely trying to use this mathematical representation, and use formula-like syntax to remove any ambiguity about the form of the RHS.
I'm not claiming this particular representation is the way to go. Rather, I think this idea merits further brainstorming. E.g., :(y | 1 + x + z).
Put another way, go with convention or explore possible improvements?

Alex Arslan
May 18, 2016, 1:22:28 AM5/18/16
to julia-stats
I definitely agree with Stefan on this.
Milan, you mentioned that we should have a strong reason to break the convention if we choose to do so. I've always found R's use of `~` to be a bit unfortunate. It's a carryover from S, which introduced `~` for formulas before R was even a thing. But S is also the language that brought us `<-` for assignment, so I tend to be wary of its gifts. ;) At this point I think other languages that offer statistical modeling facilities are using `~` just because R does it. Julia has the opportunity to potentially set a new precedent as it gains traction for stats, so I think we should think carefully about the choices.
Stefan's suggestion of `@model` opens the possibility for just about any kind of separator because it just becomes the `head` in the `Expr` that goes into the macro. But I think the syntax for pairs, i.e. `=>`, would make the most sense in terms of consistency with existing Julia structures because a model is essentially a pair; it's some combination of responses paired with some combination of predictors.
Anyway, just thinking aloud.
-Alex

Alex Williams
May 18, 2016, 2:22:16 AM5/18/16
to julia...@googlegroups.com
+1 for using @model y ~ 1 + x + z
Its clean, has precedent, and evokes the idea of using `~` to describe the distribution of a random variable (which I don't think is entirely wrong in this context).
I really don't like => aesthetically. I can come up with other minor and maybe stupid reasons to not prefer it... e.g. potential confusion with inequalities.
Just my two cents.
-- Alex
Milan Bouchet-Valat
May 18, 2016, 7:24:31 AM5/18/16
to julia...@googlegroups.com
Le mardi 17 mai 2016 à 22:22 -0700, Alex Arslan a écrit :
> I definitely agree with Stefan on this.
>
> Milan, you mentioned that we should have a strong reason to break the
> convention if we choose to do so. I've always found R's use of `~` to
> be a bit unfortunate. It's a carryover from S, which introduced `~`
> for formulas before R was even a thing. But S is also the language
> that brought us `<-` for assignment, so I tend to be wary of its
> gifts. ;) At this point I think other languages that offer
> statistical modeling facilities are using `~` just because R does it.
> Julia has the opportunity to potentially set a new precedent as it
> gains traction for stats, so I think we should think carefully about
> the choices.
>
> Stefan's suggestion of `@model` opens the possibility for just about
> any kind of separator because it just becomes the `head` in the
> `Expr` that goes into the macro. But I think the syntax for pairs,
> i.e. `=>`, would make the most sense in terms of consistency with
> existing Julia structures because a model is essentially a pair; it's
> some combination of responses paired with some combination of
> predictors.
As I said, I find => a good idea too. @model sounds a bit verbose to me
> I definitely agree with Stefan on this.
>
> Milan, you mentioned that we should have a strong reason to break the
> convention if we choose to do so. I've always found R's use of `~` to
> be a bit unfortunate. It's a carryover from S, which introduced `~`
> for formulas before R was even a thing. But S is also the language
> that brought us `<-` for assignment, so I tend to be wary of its
> gifts. ;) At this point I think other languages that offer
> statistical modeling facilities are using `~` just because R does it.
> Julia has the opportunity to potentially set a new precedent as it
> gains traction for stats, so I think we should think carefully about
> the choices.
>
> Stefan's suggestion of `@model` opens the possibility for just about
> any kind of separator because it just becomes the `head` in the
> `Expr` that goes into the macro. But I think the syntax for pairs,
> i.e. `=>`, would make the most sense in terms of consistency with
> existing Julia structures because a model is essentially a pair; it's
> some combination of responses paired with some combination of
> predictors.
(it should really be called @formula anyway), but maybe that's OK if in
practice we can use @fit as a shorthand.
Anyway, I don't really have strong feelings about this either.
Regards
> Anyway, just thinking aloud.
> -Alex
>

Michael Krabbe Borregaard
May 18, 2016, 9:05:13 AM5/18/16
to julia...@googlegroups.com
One might argue that the mathematical symbol ⇒ means something entirely different from what is implied by the formula operator: that the left side leads to the right by material implication . Also, the intuitive interpretation of => (that the left side leads to the right) is wrong.

Matthieu
Aug 15, 2016, 11:33:19 PM8/15/16
to julia-stats
In stata one specifies a formula without ~ or +
y x1 x2
It works pretty well in my experience. How about dropping ~ and +?
y x1 x2
It works pretty well in my experience. How about dropping ~ and +?
Milan Bouchet-Valat
Aug 17, 2016, 10:32:26 AM8/17/16
to julia...@googlegroups.com
visually separated from the dependent variables. ~ is really useful
IMHO.
As regards +, it's needed so that the formula is a valid Julia
expression, which is good for consistency (even if formulas end up
being written as strings). That convention also follows the Wilkinson &
Rodgers notation, so there's a precedent in the literature other than
R.
Regards
Alex Arslan
Aug 17, 2016, 6:34:46 PM8/17/16
to julia...@googlegroups.com
Agreed regarding Stata
formulas.
We could always go the way of SAS and use = to separate the response from predictors, though that could get a tricky and/or confusing due to the similarity with how keyword arguments are specified. Not to mention problematic behavior if used incorrectly...
We could always go the way of SAS and use = to separate the response from predictors, though that could get a tricky and/or confusing due to the similarity with how keyword arguments are specified. Not to mention problematic behavior if used incorrectly...
August 17, 2016 at 7:32 AM
I don't find it particularly clear that in Stata the response isn't
visually separated from the dependent variables. ~ is really useful
IMHO.
As regards +, it's needed so that the formula is a valid Julia
expression, which is good for consistency (even if formulas end up
being written as strings). That convention also follows the Wilkinson &
Rodgers notation, so there's a precedent in the literature other than
R.
Regards
August 15, 2016 at 8:33 PM
In stata one specifies a formula without ~ or +
y x1 x2
It works pretty well in my experience. How about dropping ~ and +?
May 18, 2016 at 6:04 AM
One might argue that the mathematical symbol ⇒ means something entirely different from what is implied by the formula operator: that the left side leads to the right by material implication . Also, the intuitive interpretation of => (that the left side leads to the right) is wrong.
--
You received this message because you are subscribed to a topic in the Google Groups "julia-stats" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/julia-stats/LdozV7o4zuM/unsubscribe.
To unsubscribe from this group and all its topics, send an email to julia-stats...@googlegroups.com.
May 18, 2016 at 4:24 AM

John Myles White
Aug 18, 2016, 9:39:20 AM8/18/16
to julia-stats
Some of the recent work I've been doing to demo out automatic lifting for tables makes me think that the syntax here doesn't matter too much (as long as it's easy to manipulate inside a macro). 0.5 actually offers us the chance to use substantially more interesting semantics than we have had in the past. We could realistically hope to do something like this now:
@model_matrix(y ~ x + log(x) - sin(x^2), data)
--John
To unsubscribe from this group and all its topics, send an email to julia-stats+unsubscribe@googlegroups.com.
-- You received this message because you are subscribed to the Google Groups "julia-stats" group. To unsubscribe from this group and stop receiving emails from it, send an email to julia-stats+unsubscribe@googlegroups.com. For more options, visit https://groups.google.com/d/optout.
Michael Krabbe Borregaard
Aug 18, 2016, 9:54:13 AM8/18/16
to julia...@googlegroups.com
Amazing! :+1:

Tom Breloff
Aug 18, 2016, 10:02:31 AM8/18/16
to julia...@googlegroups.com
As part of the JuliaML org/initiative, I'm working on some experimental stuff in Transformations which may be of interest. The goal is that you can define functions using valid julia syntax and let it be parsed into a backend-agnostic call graph constructor. To simplify: you would create your "formula", which could be scalar or tensor operations, and that builds type(s) with generated constructors/methods in order to calculate values, derivatives, or whatever else. It would know which variables are inputs, constants, functions, or "learnable parameters".
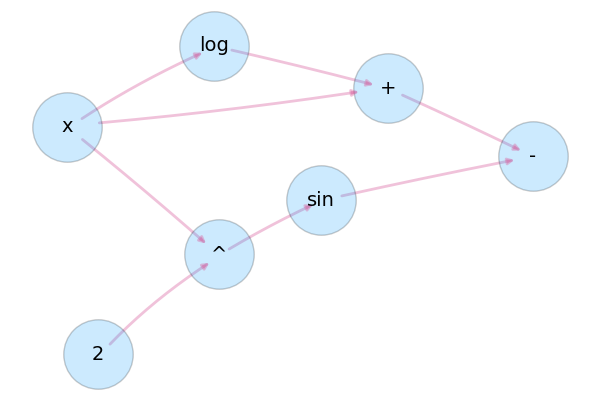
My vision is that one could define a formula once, then optimize/learn the free parameters, or generate probabilistic samples etc, using Optim, TensorFlow, or any other "backends" that may be able to do something useful. It's very similar to the Plots approach, and I see no reason why it wouldn't work here.
For demonstrations sake, I added a recipe for Mike Innes' Flow.jl, which may form the basis of the "parsing":
using Transformations
@flow y(x) = x + log(x) - sin(x^2)
using Plots; plot(ans)
As I said, this is experimental so I don't expect everyone to drop what they're doing and help out. However it would be great to have more people involved if you're interested.
Best,
Tom

Edwin
Aug 19, 2016, 5:37:09 AM8/19/16
to julia-stats
this looks like a convention to me, and julia decided to follow the R convention
(R actually follows the Stata convention in: lm(mydataframe))
one thing where i do find Stata superior is the possibility to use wild cards in formulas (including factors and interactions)
it would be nice if julia's formula interface would allow for that as well
Reply all
Reply to author
Forward
0 new messages