why the bottom_diff of softmax_loss layer should scale with loss
15 views
Skip to first unread message

Justin Ko
Jan 2, 2018, 6:27:57 AM1/2/18
to Caffe Users
In the code SoftmaxWithLossLayer<Dtype>::Backward_cpu
after compute the bottom_diff as bottom_diff[i * dim + label_value * inner_num_ + j] -= 1; there is another operation to scale the gradient :
Dtype loss_weight = top[0]->cpu_diff()[0] /get_normalizer(normalization_, count);caffe_scal(prob_.count(), loss_weight, bottom_diff);But as I know, acoording to the equation of softmax loss , its bottom_diff should be calculated as this (from ufldl deep learning tutorial):in the equation above, bottom_diff only scale with count without the multiply with the loss:top[0]->cpu_diff()[0], so i am curious why caffe implement as this ,is there any other considerations or did I have wrong understanding of the theoryThanks, any reply would be greatly appreciated.
![\begin{align}
\nabla_{\theta_j} J(\theta) = - \frac{1}{m} \sum_{i=1}^{m}{ \left[ x^{(i)} \left( 1\{ y^{(i)} = j\} - p(y^{(i)} = j | x^{(i)}; \theta) \right) \right] }
\end{align}](https://ci3.googleusercontent.com/proxy/2_7FtvN1PZ5eedNQiGc7Uzxa3eYcpxcmTPFQYB-9SisHoUryeniXtCjBpcKqlKdapDBI4XM-D4JGcosCo-U4dfyonn6CeYtsqSy_3hy9qzcrJACT2wiyGj6RxV1trA6rcSHHThqR-VQ=s0-d-e1-ft#http://ufldl.stanford.edu/wiki/images/math/5/9/e/59ef406cef112eb75e54808b560587c9.png)
Justin Ko
Jan 2, 2018, 6:40:46 AM1/2/18
to Caffe Users
The image in the post is in below, sorry to mistake of image
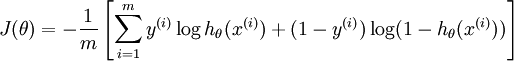
--
You received this message because you are subscribed to a topic in the Google Groups "Caffe Users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/caffe-users/Ry7HWbgSuFE/unsubscribe.
To unsubscribe from this group and all its topics, send an email to caffe-users+unsubscribe@googlegroups.com.
To post to this group, send email to caffe...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/caffe-users/1e22a9b5-630a-4908-be5e-4bcbd01e0661%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Justin Ko
Jan 2, 2018, 7:39:10 PM1/2/18
to Caffe Users
I found that top[0]->cpu_diff()[0] is the loss weight ,not the cpu_data that stores the loss, that makes sense,this question closed, thanks.
Reply all
Reply to author
Forward
0 new messages