UBMS question- how to know if random effect is significant

Emma Buckley
Hi,
I'm a student using Royal-Nicole modelling and N-mixture modelling to estimate detection probability and abundance from a count data I've collected over 11 days. I am wanting to add a random effect, using ubms, to see if this influences my detections. I created an unmarked dataframe with the detections, site and observational variables. I created a model with and without the random effect and manged to get the output summary, but how do you know if the random effect is significant or not?
Another question, I am trying to generate a model selection table of models, similar to the dredge function. Is there a way you can create something similar using ubms incorporating the random effect?
Regards
Emma
Code:
###### Made unmarked data frame to be used by model
###############################################################
#make unmarked data frame
umf_stack <- unmarkedFrameOccu(y = y,
obsCovs = list(mean_temp_air = mean_temp_air,
mean_temp_surface = mean_temp_surface,
mean_temp_subsurface = mean_temp_subsurface,
mean_humidity = mean_humidity
),
siteCovs = data.frame(colony_pres_abs = colony_pres_abs,
canopy_height = canopy_height, total_tree_height = total_tree_height, pair = pair)
)
Models:
#With pair
fit_stack <- stan_occu(~ scale(mean_temp_surface)+
scale(mean_temp_subsurface)+
scale(mean_humidity)
~ scale(colony_pres_abs)+
scale(canopy_height)+
scale(total_tree_height) +
(1|pair),
data = umf_stack , chains=3, iter=2000
)
fit_stack
#Without pair
fit_no_pair <- stan_occu(~ scale(mean_temp_surface)+
scale(mean_temp_subsurface)+
scale(mean_humidity)
~ scale(colony_pres_abs)+
scale(canopy_height)+
scale(total_tree_height),
data = umf_stack , chains=3, iter=2000
)
fit_no_pair
#Fitted two models together and compared them:
fl <- fitList(fit_no_pair, fit_stack)
round(modSel(fl),3)
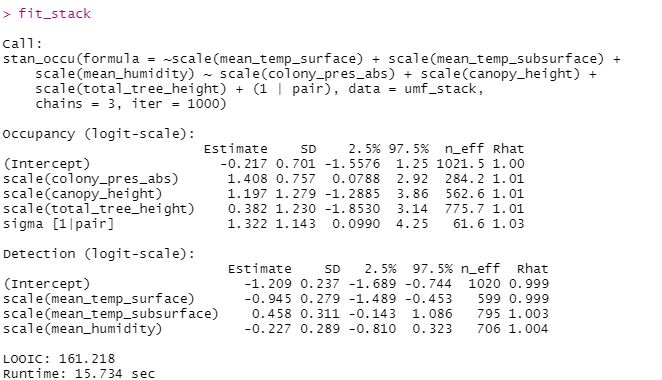
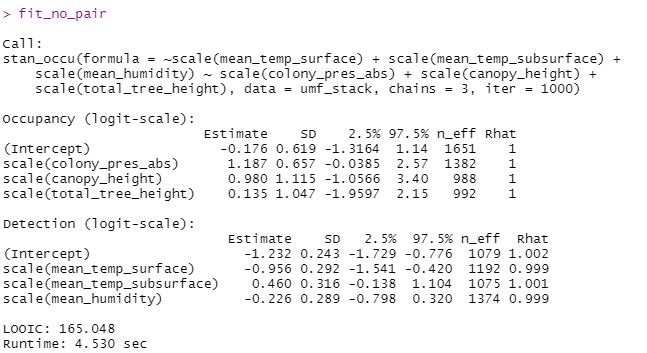


Ken Kellner
It doesn't really make sense to think of a random effect as being "significant". What you can say from your output, based on the model table, is that you have evidence that the model with the random effect performed better. That's because the elpd for fit_stack was greater than for fit_no_pair, and the SE of the difference in elpd between the two models was small relative to the value of the difference.
As far as I know, MuMIn::dredge does not support models from ubms. You could ask the MuMIn community about that, however my opinion is that it is better to compare a curated set of candidate models based specifically on your objectives and hypotheses rather than fitting models for all possible combinations of covariates as dredge does.
Ken
>
>
> [image: Model output with random effect.JPG][image: Model output without
> random effect.JPG][image: Comparing two models.JPG]
>
> *** Three hierarchical modeling email lists ***
> (1) unmarked (this list): for questions specific to the R package unmarked
> (2) SCR: for design and Bayesian or non-bayesian analysis of spatial capture-recapture
> (3) HMecology: for everything else, especially material covered in the books by Royle & Dorazio (2008), Kéry & Schaub (2012), Kéry & Royle (2016, 2021) and Schaub & Kéry (2022)
> ---
> You received this message because you are subscribed to the Google Groups "unmarked" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to unmarked+u...@googlegroups.com.
> To view this discussion on the web visit https://groups.google.com/d/msgid/unmarked/8367ebd5-ade5-4ffb-bd53-a6a60c397610n%40googlegroups.com.

Jim Baldwin
To view this discussion on the web visit https://groups.google.com/d/msgid/unmarked/YsW8zcXHdgt251J3%40COYOTE.
Emma Buckley
Hi all, thanks for the helpful answers
In the study there are 24 trees that have been identified, 12 experimental trees and 12 control trees. Each tree is paired, one control and one experimental tree. I am trying to take into account that the trees are paired by creating them as a random effect called pairs. I am wanting to compare the pairs of trees with the detections to see if there is a difference between the detections based on that the trees are paired. Is there a way to do this using ubms and random effects? Or should I rather use GLM for this?
Regards
Emma

Marc Kery
Yes, you declare the pair a random-effects factor in ubms. Pair is a factor with levels 1-12.
To view this discussion on the web visit https://groups.google.com/d/msgid/unmarked/ae410698-e4dd-4161-a2e2-0b96d3520507n%40googlegroups.com.