The total number of threads and accuracy
176 views
Skip to first unread message

Yamashita Okito
Jun 5, 2012, 2:01:15 AM6/5/12
to mcx-...@googlegroups.com
Dear Dr.Fang
I run your mcx code several times by changing the number of threads to
obtain optimal speed-accuracy tradeoff.
The results for accuracy were what I have not expected. I would be glad
if you let me know the ideas.
Let me explain what I did in details.
Firstly I run three variants of mcx codes (mcx, mcx_cached, mcx_atomic)
for four total threads (1024,2048,4096,8192) using simple one layer
medium (please see the attached text and zip files for more details).
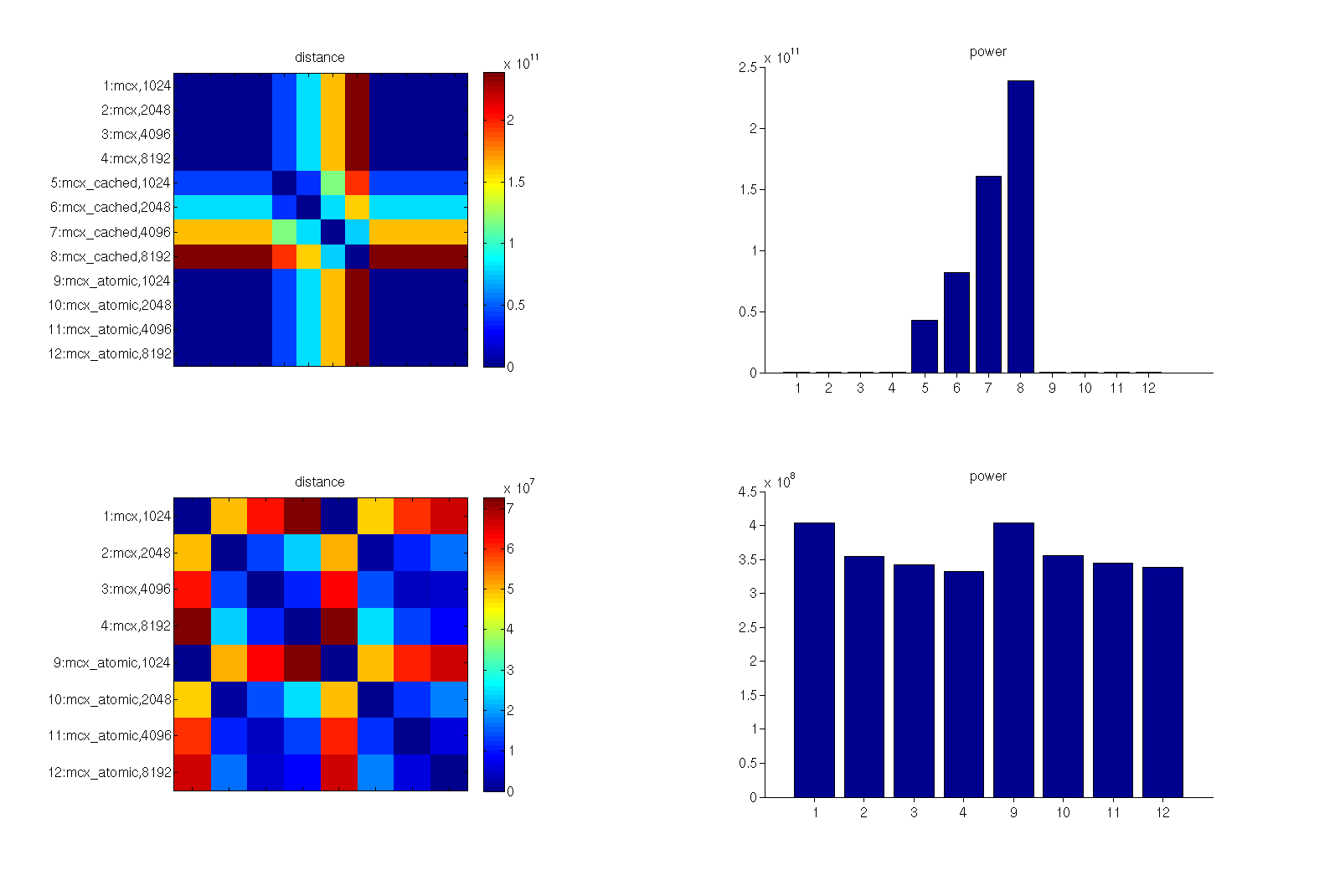
As results I obtained 12 fluence distribution.
Next I computed "distance" of a pair of the simulated flunece
distributions by summing up square of deviation over all voxels. I
computed distance for all pairs. I also computed total "power" by
summing up square of fluence over all voxels. I obtained results as
shown in the attached figure. Panels in top row are "distance" and
"power" from all 12 fluence distributions. In bottom raws, distance and
power for 8 fluence distributions out of 12, which result from mcx and
mcx_atomic, are shown for close visual inspection. Note that the numbers
1-4, 5-8 and 9-12 in two right panels correspond to mcx 1024-8192,
mcx_cached 1024-8192 and mcx_atomic 1024-8192, respectively.
As you can see from the top panels, the distance and power obtained from
mcx_cached are very different from those from mcx and mcx_atomic
irrespective of the number of threads.
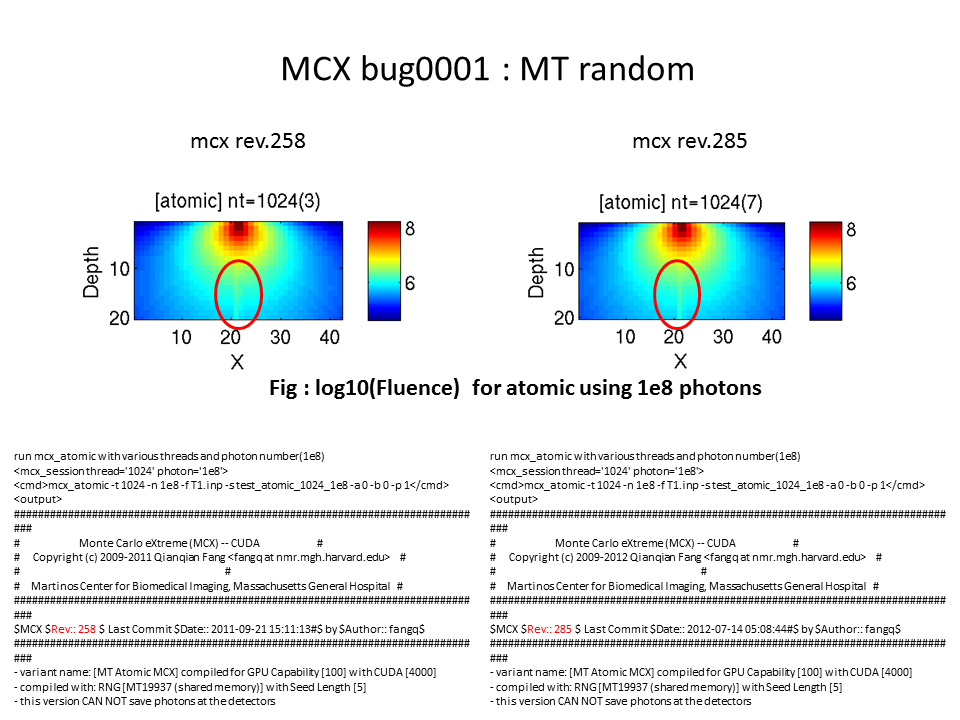
As you can see from the bottom panels, the distance of the number of
threads 1024 differs very much from those obtained from 2048,4096,8192.
In particular, I was surprised at the results of mcx_atomic since I had
expected it returns almost identical results (within monte calro error)
regardless of the number of threads.
Then I have two questions
Q1. What happened to results of mcx_cached ?
Q2. Why does a result of mcx_atomic depend on the number of thread so
much ?
Thank you very much in advance.
Best regards
Okito Yamashita
I run your mcx code several times by changing the number of threads to
obtain optimal speed-accuracy tradeoff.
The results for accuracy were what I have not expected. I would be glad
if you let me know the ideas.
Let me explain what I did in details.
Firstly I run three variants of mcx codes (mcx, mcx_cached, mcx_atomic)
for four total threads (1024,2048,4096,8192) using simple one layer
medium (please see the attached text and zip files for more details).
As results I obtained 12 fluence distribution.
Next I computed "distance" of a pair of the simulated flunece
distributions by summing up square of deviation over all voxels. I
computed distance for all pairs. I also computed total "power" by
summing up square of fluence over all voxels. I obtained results as
shown in the attached figure. Panels in top row are "distance" and
"power" from all 12 fluence distributions. In bottom raws, distance and
power for 8 fluence distributions out of 12, which result from mcx and
mcx_atomic, are shown for close visual inspection. Note that the numbers
1-4, 5-8 and 9-12 in two right panels correspond to mcx 1024-8192,
mcx_cached 1024-8192 and mcx_atomic 1024-8192, respectively.
As you can see from the top panels, the distance and power obtained from
mcx_cached are very different from those from mcx and mcx_atomic
irrespective of the number of threads.
As you can see from the bottom panels, the distance of the number of
threads 1024 differs very much from those obtained from 2048,4096,8192.
In particular, I was surprised at the results of mcx_atomic since I had
expected it returns almost identical results (within monte calro error)
regardless of the number of threads.
Then I have two questions
Q1. What happened to results of mcx_cached ?
Q2. Why does a result of mcx_atomic depend on the number of thread so
much ?
Thank you very much in advance.
Best regards
Okito Yamashita

Qianqian Fang
Jun 6, 2012, 12:06:35 AM6/6/12
to mcx-...@googlegroups.com, Yamashita Okito
On 6/5/2012 2:01 AM, Yamashita Okito wrote:
> Dear Dr.Fang
>
> I run your mcx code several times by changing the number of threads to
> obtain optimal speed-accuracy tradeoff.
> The results for accuracy were what I have not expected. I would be glad
> if you let me know the ideas.
>
> <snip>
> Dear Dr.Fang
>
> I run your mcx code several times by changing the number of threads to
> obtain optimal speed-accuracy tradeoff.
> The results for accuracy were what I have not expected. I would be glad
> if you let me know the ideas.
>
>
> Q1. What happened to results of mcx_cached ?
> Q2. Why does a result of mcx_atomic depend on the number of thread so
> much ?
hi Okito
> Q1. What happened to results of mcx_cached ?
> Q2. Why does a result of mcx_atomic depend on the number of thread so
> much ?
interesting ...
The results from mcx_cached is indeed unexpected. Can you use
a positive number (say 5) with -R ? is the result similar? If it is
still as bad, then I think you found a bug..
For your second question, getting different results from different
thread numbers is not surprising on the GPU. This is because
floating-point operations are not commutative, i.e. for limited
precision math, A+B+C is not the same as A+C+B. On the
GPU. Another possible reason is the difference in seeding.
When running 1024 threads, each thread runs about 1e6
photons from a single seed, the per-thread photon number
is cut by 4 when running with 4096 threads.
The key difference between mcx and mcx_atomic is around the
source where data racing has higher probability. Your distance
and power metrics is not sensitive to the spatial distribution,
so, they are very close.
In the MCX paper, figure 4 was designed to quantify the
difference between mcx and mcx_atomic. The binary was
compiled with a "make racing" command.
Based on my past tests, if your ROI is 5 voxels away from
the source, then the best performance is to run >10000
threads; I used -A parameter to set a large thread
numbers automatically. If you use atomics, more threads
can be very slow. You may already know this from
Fig. 7a in the mcx paper.
I am also interested to see how this behavior changes with
-n. If you set -n 1e8, do you see similar plots?
Let me know
Qianqian
Yamashita Okito
Jun 7, 2012, 10:23:54 PM6/7/12
to mcx-...@googlegroups.com, Qianqian Fang
Dear Dr.Fang
Thank you very much for your reply.
> I am also interested to see how this behavior changes with
> -n. If you set -n 1e8, do you see similar plots?
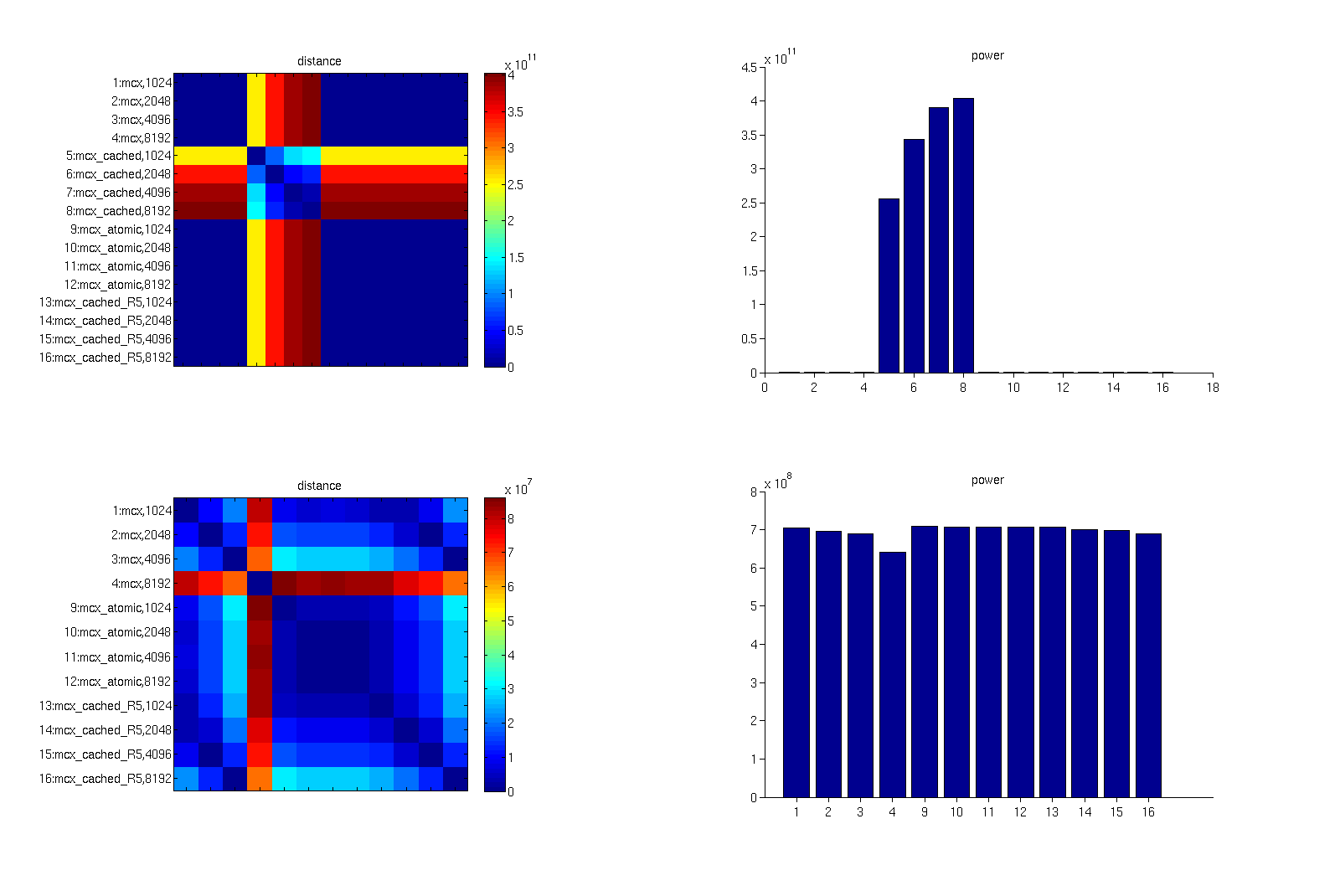
I tried -n 1e8 option for all modes as well as -R for cached.
The result is attached with this e-mail (see distance_fang.png).
For your information, I also attached more detailed version (see
detail_MCX_comparison.pdf)
Now all the results make sense for me like
- the effect of the number of thread is much less in atomic
- cached -R 5 is OK
- mcx is less accurate when the number of thread is large
and so on.
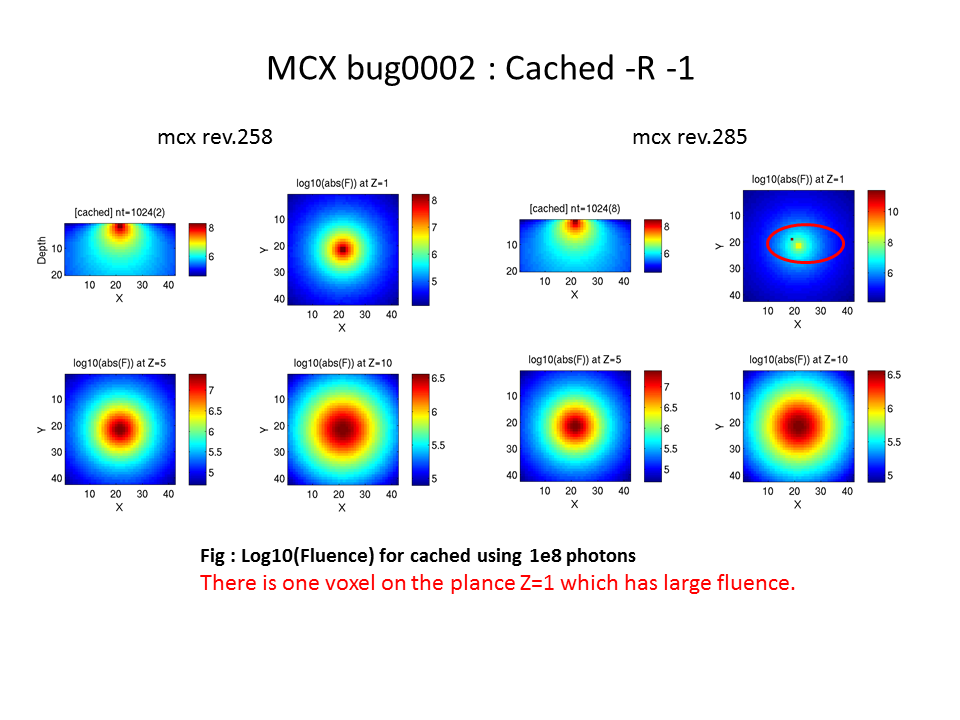
I also found that the zone set by cached -R -1 does not look
appropriate, which causes large error.
But I am now wondering why the number of photons affects results so much
(based on comparison between the previous one with this one).
For example, when we want to use 1e10 photons, which is better, to
simulate with 1e8 photons 100 times or to simulate with 1e10 photons once ?
Would you let me know your opinions ?
Best regards
Okito Yamashita
Thank you very much for your reply.
> I am also interested to see how this behavior changes with
> -n. If you set -n 1e8, do you see similar plots?
The result is attached with this e-mail (see distance_fang.png).
For your information, I also attached more detailed version (see
detail_MCX_comparison.pdf)
Now all the results make sense for me like
- the effect of the number of thread is much less in atomic
- cached -R 5 is OK
- mcx is less accurate when the number of thread is large
and so on.
I also found that the zone set by cached -R -1 does not look
appropriate, which causes large error.
But I am now wondering why the number of photons affects results so much
(based on comparison between the previous one with this one).
For example, when we want to use 1e10 photons, which is better, to
simulate with 1e8 photons 100 times or to simulate with 1e10 photons once ?
Would you let me know your opinions ?
Best regards
Okito Yamashita

{kind=link}
{kind=link}
Qianqian Fang
Jun 9, 2012, 10:34:38 PM6/9/12
to mcx-...@googlegroups.com, Yamashita Okito
On 6/7/2012 10:23 PM, Yamashita Okito wrote:
> Dear Dr.Fang
>
> Dear Dr.Fang
>
> Thank you very much for your reply.
>
>
> I tried -n 1e8 option for all modes as well as -R for cached.
> The result is attached with this e-mail (see distance_fang.png).
> For your information, I also attached more detailed version (see
> detail_MCX_comparison.pdf)
hi Okito
> The result is attached with this e-mail (see distance_fang.png).
> For your information, I also attached more detailed version (see
> detail_MCX_comparison.pdf)
the attached plots and comparisons are quite informative.
However, I am not quite sure about the plots for mcx_cached
shown on pages 4 and 9. When using -R positive_num,
the width of the cached region should be 2*positive_num+1
centered at the source. In your case, the horizontal region
size is 7x7 pixels, vertically is >=10 pixels. Can you confirm
if these plots were generated by -R +num or by -R -1?
My second suggestion is to use absolute difference instead
of the normalized error. From many of the plots, a grain-like
noise can be seen which I believe is due to the stochastic
error amplified by dividing atomic(mcx) solution. If you had
simulated the same number of photons, the absolution
difference should be proportional to the error due to
racing. No need to normalize.
One thing I also want to point out is that the power bar
plot is, in my opinion, an overstatement of the data racing
problem, as you can see the highest difference is highly
localized (use mcx_cached as a proof). Therefore, if ones
interest is not around the source, the dominant portion
of the domain has reasonably accurate solution, despite
the high power loss near the source.
> Now all the results make sense for me like
> - the effect of the number of thread is much less in atomic
> - cached -R 5 is OK
> - mcx is less accurate when the number of thread is large
> and so on.
> I also found that the zone set by cached -R -1 does not look
> appropriate, which causes large error.
-R +/- mcx_cached. For photon numbers, I guess you
drew the conclusion based on the comparisons between
the two distance.png plots (between atomic variants).
I agree this is worrisome.
Your second distance plot makes a lot of sense: the
atomic-vs-atomic are mostly close to 0, except
atomic-1024 vs others. I believe this is related to the
seeding issue I mentioned in the first reply. When
running more photons, I expect this difference
diminishes. However, this is not the case in your
first distance plot.
On thing that may explain this is your relatively small
thread numbers and large photon number. This may cause
issues for random number generator (RNG). For example,
if you run 1e10 photons total with 1024 threads, each
thread needs to run 1e7 photons; assuming each photon
needs ~20 scattering events to terminate, each event needs
5 random numbers (with logistic-lattice-5 RNG), then you
need to produce 1e9 RNGs in a thread sequentially. For a
RNG with period 2^32-1=4.3e9, this maybe ok, but when
scattering coefficient becomes very high, you have the risk
of cycling. For the chaotic RNG I used in MCX, the period
is supposed to be long, but varies depending on the seed.
I suspect for high scattering cases, the limited period can
be an issue.
For this reason, I often suggest running less photons
per kernel call, and use -r to repeat. Also, by default, MCX
uses many more threads (10000-40000), this can also
reduce the effect of RNG quality. MCX can be compiled with
MT19967 RNG, which has a huge period.
>
> But I am now wondering why the number of photons affects results so
> much (based on comparison between the previous one with this one).
> For example, when we want to use 1e10 photons, which is better, to
> simulate with 1e8 photons 100 times or to simulate with 1e10 photons
> once ?
> Would you let me know your opinions ?
if you have any further findings regarding MCX. I will investigate
the offset issues for the cached version when I have time.
Qianqian
addressed. If you believe this e-mail was sent to you in error and the e-mail
contains patient information, please contact the Partners Compliance HelpLine at
http://www.partners.org/complianceline . If the e-mail was sent to you in error
but does not contain patient information, please contact the sender and properly
dispose of the e-mail.
Yamashita Okito
Jun 11, 2012, 5:48:06 AM6/11/12
to Qianqian Fang, mcx-...@googlegroups.com
Dear Dr. Fang
Thank you again for your reply.
> Can you confirm
> if these plots were generated by -R +num or by -R -1?
It was generated by -R -1.
> My second suggestion is to use absolute difference instead
> of the normalized error. From many of the plots, a grain-like
> noise can be seen which I believe is due to the stochastic
> error amplified by dividing atomic(mcx) solution.
If the purpose is to see errors due to racing, your suggestion is very
reasonable.
> One thing I also want to point out is that the power bar
> plot is, in my opinion, an overstatement of the data racing
> problem, as you can see the highest difference is highly
> localized (use mcx_cached as a proof).
I agree with you. The power bar (or distance) plot only tell us that
there is something wrong somewhere.
We can not know where it is. As shown in the detailed plots, most of
errors come from near-source as you said.
Anyway the purpose of the power bar plot is to know whether there is
difference among the simulations ('mcx', 'atomic','cached' x number of
threads) .
My previous result using 1e9 photons suggests not-small difference even
in "within-atomic comparison" and this is true even when MT19967 is used
as RNG (see below).
> For this reason, I often suggest running less photons
> per kernel call, and use -r to repeat. Also, by default, MCX
> uses many more threads (10000-40000), this can also
> reduce the effect of RNG quality. MCX can be compiled with
> MT19967 RNG, which has a huge period.
>
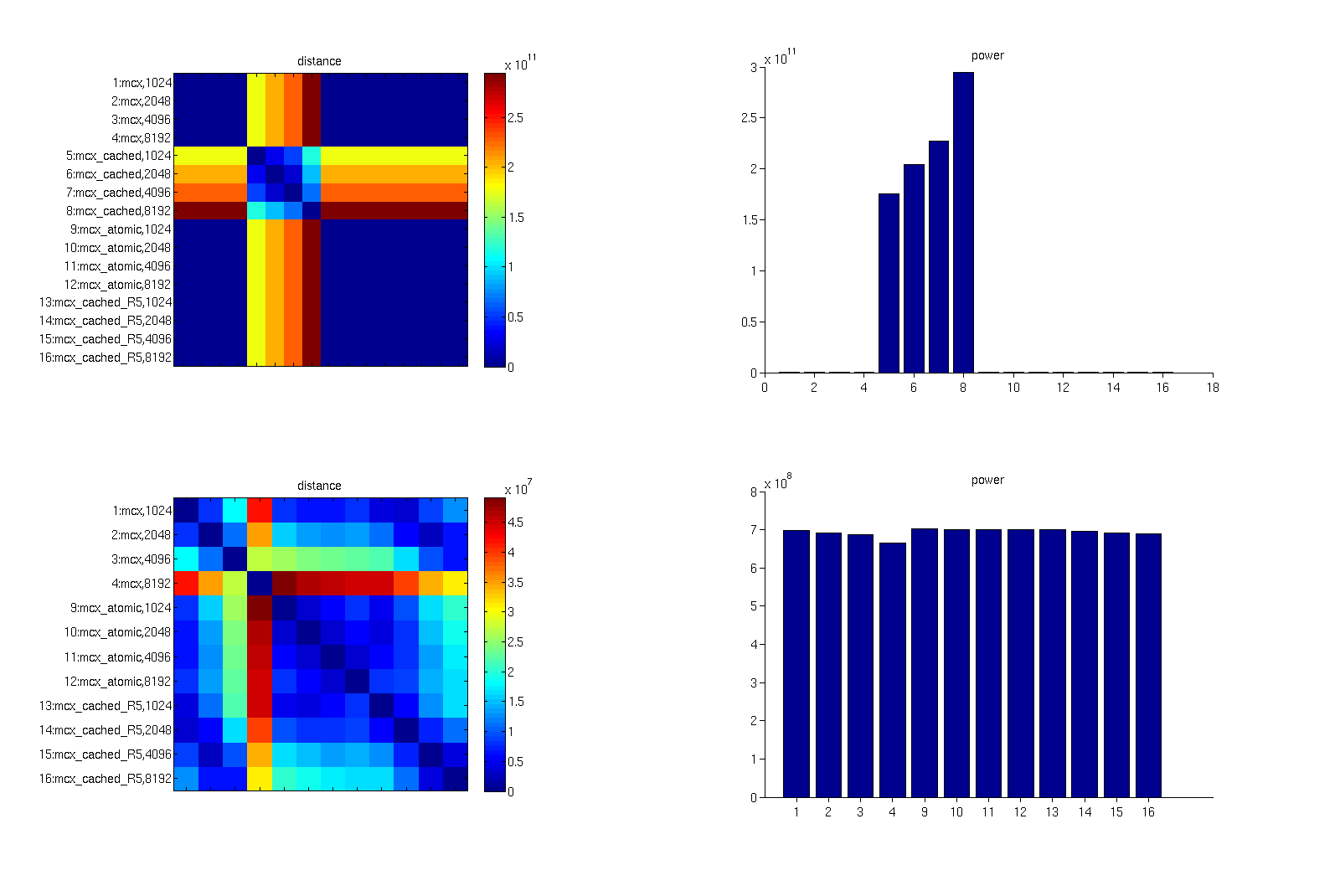
Based on the hypothesis that small periodicity of RNG causes the
problem, we tried MT19967 for the number of photons 1e-8 and 1e-9 (see
distance_mt{1e8,1e9}.png).
The distance and power plots are almost identical with those obtained
with default RNG, suggesting the small periodicity of RNG is NOT a cause
to generate difference in within-atomic comparison.
In addition, I found something wrong happens to MT version. As you can
see in log_abserr_.png (atomic-atomic comparison, log of absolute
difference), the line noise is observed beneath the source.
This is observed irrespective of the number of photons and the number of
threads but was not observed in simulations using the default RNG.
In summary what I found are
1. MT19967 and default RNG give similar results for power and distance
plot, indicating the small periodicity is not a main cause of difference
in within-atomic comparison.
2. however, detailed investigation of MT19967 results suggest something
wrong in beneath the source.
I wonder whether my results, in particular within-atomic comparison, are
reproducible in other computer environment or not.
I would like to know your investigation results. Thanks.
Best regards
Okito Yamashita
Thank you again for your reply.
> Can you confirm
> if these plots were generated by -R +num or by -R -1?
> My second suggestion is to use absolute difference instead
> of the normalized error. From many of the plots, a grain-like
> noise can be seen which I believe is due to the stochastic
> error amplified by dividing atomic(mcx) solution.
reasonable.
> One thing I also want to point out is that the power bar
> plot is, in my opinion, an overstatement of the data racing
> problem, as you can see the highest difference is highly
> localized (use mcx_cached as a proof).
there is something wrong somewhere.
We can not know where it is. As shown in the detailed plots, most of
errors come from near-source as you said.
Anyway the purpose of the power bar plot is to know whether there is
difference among the simulations ('mcx', 'atomic','cached' x number of
threads) .
My previous result using 1e9 photons suggests not-small difference even
in "within-atomic comparison" and this is true even when MT19967 is used
as RNG (see below).
> For this reason, I often suggest running less photons
> per kernel call, and use -r to repeat. Also, by default, MCX
> uses many more threads (10000-40000), this can also
> reduce the effect of RNG quality. MCX can be compiled with
> MT19967 RNG, which has a huge period.
>
problem, we tried MT19967 for the number of photons 1e-8 and 1e-9 (see
distance_mt{1e8,1e9}.png).
The distance and power plots are almost identical with those obtained
with default RNG, suggesting the small periodicity of RNG is NOT a cause
to generate difference in within-atomic comparison.
In addition, I found something wrong happens to MT version. As you can
see in log_abserr_.png (atomic-atomic comparison, log of absolute
difference), the line noise is observed beneath the source.
This is observed irrespective of the number of photons and the number of
threads but was not observed in simulations using the default RNG.
In summary what I found are
1. MT19967 and default RNG give similar results for power and distance
plot, indicating the small periodicity is not a main cause of difference
in within-atomic comparison.
2. however, detailed investigation of MT19967 results suggest something
wrong in beneath the source.
I wonder whether my results, in particular within-atomic comparison, are
reproducible in other computer environment or not.
I would like to know your investigation results. Thanks.
Best regards
Okito Yamashita
{kind=link}
{kind=link}
{kind=link}
Qianqian Fang
Jun 11, 2012, 11:24:06 AM6/11/12
to mcx-...@googlegroups.com, Yamashita Okito
On 6/11/2012 5:48 AM, Yamashita Okito wrote:
> In summary what I found are
>
> 1. MT19967 and default RNG give similar results for power and
> distance plot, indicating the small periodicity is not a main cause of
> difference in within-atomic comparison.
> 2. however, detailed investigation of MT19967 results suggest
> something wrong in beneath the source.
hi Okito
> In summary what I found are
>
> 1. MT19967 and default RNG give similar results for power and
> distance plot, indicating the small periodicity is not a main cause of
> difference in within-atomic comparison.
> 2. however, detailed investigation of MT19967 results suggest
> something wrong in beneath the source.
very good. thanks for your thorough benchmark and testing.
I think these are real issues and are certainly needed to be
fixed. I will try to spend some time after the conference
I am attending, and will update you if I figure out any fixes.
Qianqian
>
> I wonder whether my results, in particular within-atomic comparison,
> are reproducible in other computer environment or not.
> I would like to know your investigation results. Thanks.
>
> Best regards
> Okito Yamashita
>
Qianqian Fang
Jul 13, 2012, 12:55:35 PM7/13/12
to mcx-...@googlegroups.com, Yamashita Okito
Okito san
just want to let you know I am setting up an
experimental bug tracker page for MCX. With
this, I'd like to formally document and track the
status of issues submitted from the user community.
The URL for this page is
http://mcx.sourceforge.net/cgi-bin/index.cgi?MCX_Bug
I uploaded two of the issues you previous discussed
to this page. One of them is fixed a moment ago
(BugID: 0002). You can click on each bug and read
the details, for example:
http://mcx.sourceforge.net/cgi-bin/index.cgi?MCX_Bug/0002
Bug submission by users is not supported yet, please
send your feedback to the mcx-users mailing list, or
post a comment for a bug use the "Post New Message" link.
Qianqian
just want to let you know I am setting up an
experimental bug tracker page for MCX. With
this, I'd like to formally document and track the
status of issues submitted from the user community.
The URL for this page is
http://mcx.sourceforge.net/cgi-bin/index.cgi?MCX_Bug
I uploaded two of the issues you previous discussed
to this page. One of them is fixed a moment ago
(BugID: 0002). You can click on each bug and read
the details, for example:
http://mcx.sourceforge.net/cgi-bin/index.cgi?MCX_Bug/0002
Bug submission by users is not supported yet, please
send your feedback to the mcx-users mailing list, or
post a comment for a bug use the "Post New Message" link.
Qianqian
Qianqian Fang
Jul 13, 2012, 6:17:32 PM7/13/12
to mcx-...@googlegroups.com, Yamashita Okito
hi Okito
I also made a change related to the reported MT19937
RNG issue. See my notes on this page:
http://mcx.sourceforge.net/cgi-bin/index.cgi?MCX_Bug/0001
Let me know if this makes any difference. I also notice
the MT version of MCX gives the best speed when the
blocksize is 1 on my 590. This is different from what I
recall in my older tests. I do remember SVN rev 191
did impact MT-MCX simulation speed significantly.
Qianqian
On 06/11/2012 05:48 AM, Yamashita Okito wrote:
I also made a change related to the reported MT19937
RNG issue. See my notes on this page:
http://mcx.sourceforge.net/cgi-bin/index.cgi?MCX_Bug/0001
Let me know if this makes any difference. I also notice
the MT version of MCX gives the best speed when the
blocksize is 1 on my 590. This is different from what I
recall in my older tests. I do remember SVN rev 191
did impact MT-MCX simulation speed significantly.
Qianqian
On 06/11/2012 05:48 AM, Yamashita Okito wrote:
Qianqian Fang
Jul 16, 2012, 8:40:20 AM7/16/12
to Suresh Paidi, suresh paidi, mcx-...@googlegroups.com
On 07/16/2012 02:24 AM, Suresh Paidi
wrote:
Dear Dr. Fang,
You stated that "I also notice the MT version of MCX gives the best speed when the blocksize is 1 on my 590" Could you please explain in detail?. I have simulated "speedtest" example on TeslaC2075 and I found that log(LL5) compile option was results best speed compared to other options.
sorry about the confusion. yes, LL5 is much faster than MT
in MCX implementations. What I meant was that, among all
MT simulations, blocksize=1 is faster than other configurations.
The cause for the slow simulation using MT19937 is not
fully understood. I suspect this is related to the multiple
_syncthreads() calls.
Is there any detailed documentation for these compilation options in terms of GPU cores simulation? what is the difference between MT and LL5 in terms of GPU core execution?.
The speedtest example is designed for this purpose.
The hardware is constantly improving, so, it is always
a good idea to benchmark with the speedtest script.
Qianqian
Thanks,Suresh Paidi.
--
You received this message because you are subscribed to the Google Groups "mcx-users" group.
To post to this group, send email to mcx-...@googlegroups.com.
To unsubscribe from this group, send email to mcx-users+...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/mcx-users?hl=en.
--
Thanks,
Suresh Paidi
SA - Lab Technician
San Jose State University
Electrical Engineering
One Washington Square
San Jose, CA 95192-0084
Yamashita Okito
Jul 24, 2012, 10:35:19 PM7/24/12
to mcx-...@googlegroups.com, Qianqian Fang, Yamashita Okito
Dear Dr.Fang
Thank you very much for your effort to our problem reports.
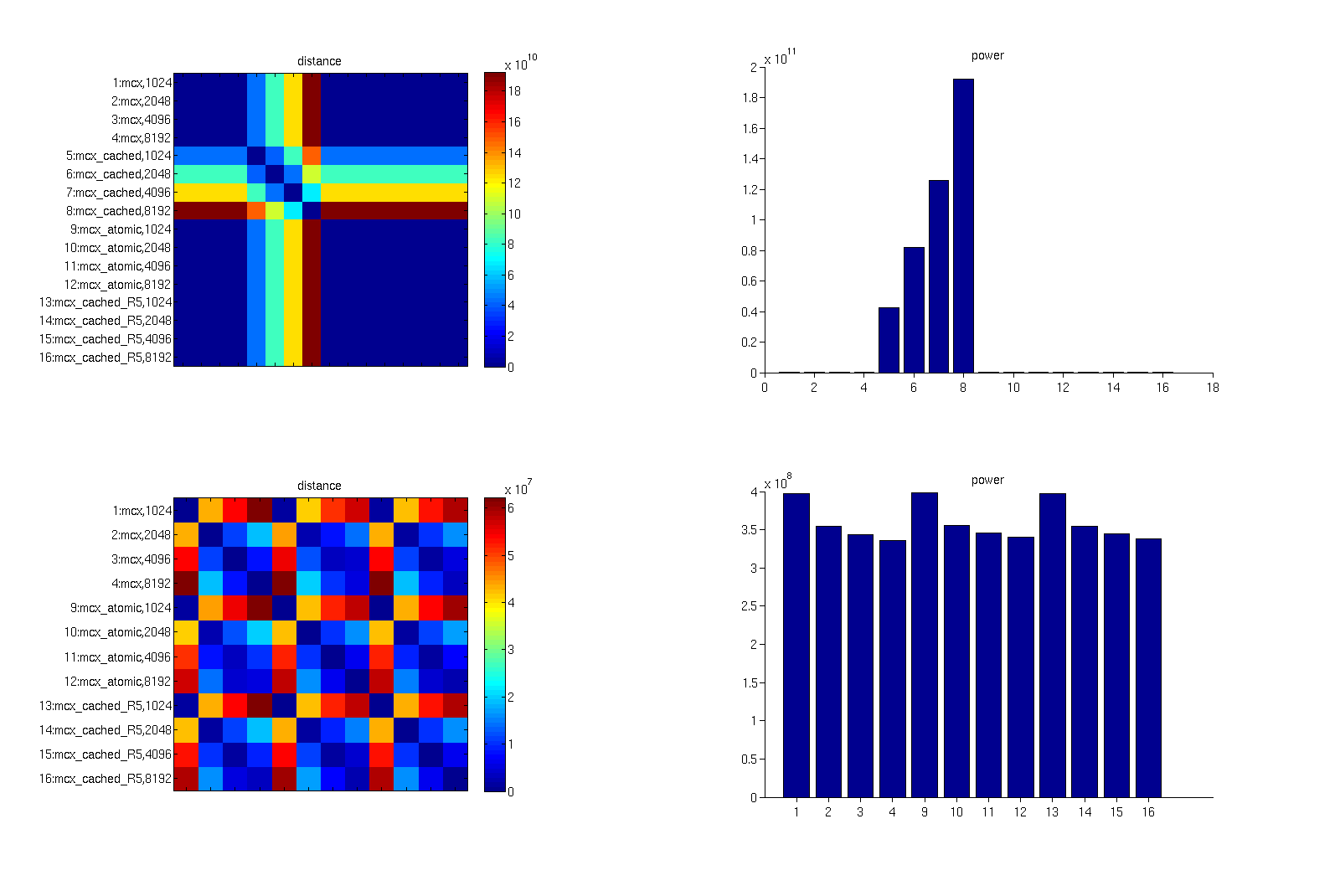
I tried the latest revison of MCX for cached -R -1.
I attach the result figure with this e-mail.
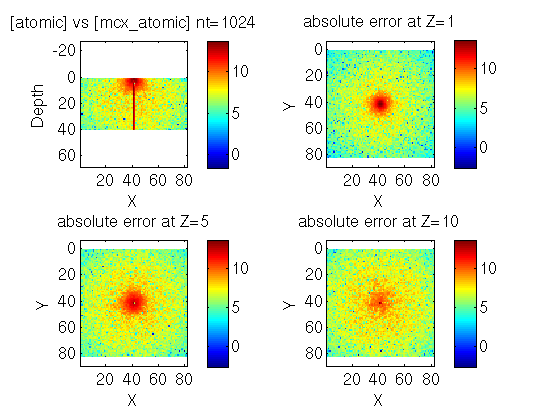
As shown in the figure, there is one voxel on the plane Z=1 which has large fluence.
I should mention that by taking differenece between these two results (no figure here), I confirmed the reserved region moves one voxel as you expect.
Best regards
Okito Yamashita
Thank you very much for your effort to our problem reports.
I tried the latest revison of MCX for cached -R -1.
I attach the result figure with this e-mail.
As shown in the figure, there is one voxel on the plane Z=1 which has large fluence.
I should mention that by taking differenece between these two results (no figure here), I confirmed the reserved region moves one voxel as you expect.
Best regards
Okito Yamashita
{kind=link}
Yamashita Okito
Jul 24, 2012, 10:40:16 PM7/24/12
to mcx-...@googlegroups.com, Qianqian Fang, Yamashita Okito
Dear Dr.Fang
I also checked this issue but your correction does not change results in
my envioronment.
I attach the figure. Please have a look at it.
Best regards
Okito Yamashita
I also checked this issue but your correction does not change results in
my envioronment.
I attach the figure. Please have a look at it.
Best regards
Okito Yamashita
{kind=link}
Qianqian Fang
Jul 25, 2012, 12:57:28 PM7/25/12
to mcx-...@googlegroups.com, Yamashita Okito
On 07/24/2012 10:35 PM, Yamashita Okito
wrote:
Dear Dr.Fang
Thank you very much for your effort to our problem reports.
I tried the latest revison of MCX for cached -R -1.
I attach the result figure with this e-mail.
As shown in the figure, there is one voxel on the plane Z=1 which has large fluence.
I should mention that by taking differenece between these two results (no figure here), I confirmed the reserved region moves one voxel as you expect.
hi Okito
thanks again for the feedback. I tested it on a 121x121x60
volume and was able to repreduce the bug.
after investigation, the issue turned out to be a result
of memory overlap for partial path recording and
share memory fluence cache. Even though mcx_cached
does not support detectors, the issavedet flag is on by
default. Thus, mcx kernel writes partial path info to
the beginning of the cached buffer.
I just committed a fix, and running the updated mcx_cached,
the incorrect voxel is gone. Please let me know if you
can see the same.
http://mcx.svn.sourceforge.net/viewvc/mcx?view=revision&revision=287
Qianqian
thanks again for the feedback. I tested it on a 121x121x60
volume and was able to repreduce the bug.
after investigation, the issue turned out to be a result
of memory overlap for partial path recording and
share memory fluence cache. Even though mcx_cached
does not support detectors, the issavedet flag is on by
default. Thus, mcx kernel writes partial path info to
the beginning of the cached buffer.
I just committed a fix, and running the updated mcx_cached,
the incorrect voxel is gone. Please let me know if you
can see the same.
http://mcx.svn.sourceforge.net/viewvc/mcx?view=revision&revision=287
Qianqian
--
You received this message because you are subscribed to the Google Groups "mcx-users" group.
To post to this group, send email to mcx-...@googlegroups.com.
To unsubscribe from this group, send email to mcx-users+...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/mcx-users?hl=en.
Qianqian Fang
Aug 10, 2012, 1:18:52 PM8/10/12
to Yamashita Okito, mcx-...@googlegroups.com
On 07/24/2012 10:40 PM, Yamashita Okito wrote:
> Dear Dr.Fang
>
> I also checked this issue but your correction does not change results
> in my envioronment.
> I attach the figure. Please have a look at it.
hi Okito
> Dear Dr.Fang
>
> I also checked this issue but your correction does not change results
> in my envioronment.
> I attach the figure. Please have a look at it.
I want to give an update on this issue. My colleagues from
BU, David Giraud and Matt Adams, had also approached
me with a similar issue when running MCX with a large
number of photons (1e9) and high scattering (mus=10).
After looking into this, I realized that this is indeed related
to the stability of the default RNG, i.e. the logistic-lattice
ring-5. A quick test is to append "-DDOUBLE_PREC_LOGISTIC -arch sm_13"
on line 58 and then "make". The double precision RNG seemed
to work reliably even for large photon numbers. However,
it is about 4x slower than single, and requires newer nvidia
cards.
Aside from using -r to split the total photons into smaller
chunks, I recently tested another approach: reseeding
RNG after running for a specified scattering events. These
changes were committed as SVN rev 291-294. After some
tests, the default reseeding event count is set to 1e7.
A frequent reseeding (every 1e4 scattering) seems also
to be fine in terms of statistical noise (see the test script
in rev 293).
I updated the bug report (MCX_Bug/0001) at this link:
http://mcx.sf.net/cgi-bin/index.cgi?MCX_Bug/0001
Please let me know if this fixes the issue you have reported.
David, please also let me know how it works in your case.
The performance of the RNG is a bit under my expectation.
Based on this paper:
http://www.cs.utsa.edu/~wagner/pubs/all.pdf
A single ring-5 lattice should have a much higher period
(in table 3). Likely it is due to the fact that I did not use the
remapped lattice.
Qianqian
Yamashita Okito
Aug 24, 2012, 5:48:02 AM8/24/12
to Qianqian Fang, Yamashita Okito, mcx-...@googlegroups.com
Hi, Fang
I attach the report which summarizes (what I think) the problems in the
current mcx.
Please have a look at it and give me your opinion.
Thanks.
p.s. The David's problem is fixed in my envoironment by rev.297.
Best regards
Okito Yamashita
I attach the report which summarizes (what I think) the problems in the
current mcx.
Please have a look at it and give me your opinion.
Thanks.
p.s. The David's problem is fixed in my envoironment by rev.297.
Best regards
Okito Yamashita
Qianqian Fang
Aug 26, 2012, 11:10:01 PM8/26/12
to mcx-...@googlegroups.com, Yamashita Okito
On 08/24/2012 05:48 AM, Yamashita Okito wrote:
> Hi, Fang
>
> I attach the report which summarizes (what I think) the problems in
> the current mcx.
> Please have a look at it and give me your opinion.
hi Okito
> Hi, Fang
>
> I attach the report which summarizes (what I think) the problems in
> the current mcx.
> Please have a look at it and give me your opinion.
thanks again for your timely feedback. I was just
about to wrap up MCX 0.8.0 final. I am glad you
had double checked these fixes.
For the thread-dependency bug, I agree that it is
still not fixed. I tried mcx atomic with 2048 and
20480 threads, the results were different. Different
from the atomic/non-atomic comparisons where
more threads resulted in less fluence (due to racing),
this case, more threads gave higher fluence.
I am a bit puzzled and not sure where could be
wrong. You've tested with -N 1e5, so it could not
be the short period issue; on the other hand, since
we used mcx_atomic, data racing is out of the
problem.
I will hold the release of 0.8.0 and try to investigate
this further. If you have any new findings that you
think may shed some light, please let me know
as well.
Qianqian
Reply all
Reply to author
Forward
0 new messages