automated species identification

Ken-ichi
I'd like to share something our team and our collaborators have been
working hard on for a few months: automated species identification!
Here'd the demo for you to play with:
https://www.inaturalist.org/computer_vision_demo
What's going on here? We're using technology similar to facial
recognition systems, except we're training it to recognize species
from the photos we all upload to iNat and identify, and we're
incorporating iNat observational data to rank results based on date
and location. Currently we've trained it on species that have Research
Grade observations by 20 or more unique people. That means it can
recognize commonly-observed RG stuff like Turkey Vultures and
California poppies, but it doesn't recognize dogs, cats, humans,
obscure carabid beetles, dumbo octopus, etc. (it actually seems to
think all humans are lizards... b/c so many lizards are photographed
with a human hand in frame, or b/c the TV show V was totally accurate
and the computer knows more than we do).
Right now it's just a demo, with a lot of flaws, but also a lot of
promise, and we're curious: how do you feel about this? Do you think
you'd find this useful? Our guess is that it will be enormously
helpful for folks who are just getting into natural history, because
if we get it working right, it could deliver an instantaneous array of
good options for very common things. In it's current state, it might
not be that useful for experienced naturalists who are identifying
less commonly-observed things, but you can imagine a future when we
have enough data for it to get really good at identifying things like
moths.
Anyway, thoughts? Bugs? Working well in some parts of the world and not others?
-ken-ichi
P.S. The demo works on most mobile browsers, which usually let you
choose an image from the camera, so this already works pretty well
outside if you have good reception. It's only submitting a small
version of the photo you take so it shouldn't eat up too much data.

James Bailey
James Bailey
Ken-ichi
data. It did not do a good job with
http://www.inaturalist.org/observations/5395632, for example, but
*most* poppy observations that go through it are going to be CA
poppies. The Australian issue is tougher. If we get vision
recommendations of species that have never been observed in the
reported location, do we show them as a way to suggest leads, or are
they just confusing? Do we attempt to infer a higher level taxon from
the results and show observation-based results of that? Still figuring
these things out.
> You received this message because you are subscribed to the Google Groups
> "iNaturalist" group.
> To unsubscribe from this group and stop receiving emails from it, send an
> email to inaturalist...@googlegroups.com.
> To post to this group, send email to inatu...@googlegroups.com.
> Visit this group at https://groups.google.com/group/inaturalist.
> For more options, visit https://groups.google.com/d/optout.

Charlie Hohn
I will play with it more, of coures.
Charlie Hohn

krancmm
I really don't like the possibilities from other parts of the world - that, to me, is both confusing and encourages weird IDs. I'd also like to see specified what is considered "seen nearby" - county, country, km/miles...
At least from the ones I added, since the first selection was correct in all but 1 of 10 it seems more useful to "bump" to the next higher taxon AND also "seen nearby" for additional choices.
This probably needs to be tested by users who are maybe taking rather blurry shots from a distance where even cropped may not be sufficient for an ID...ran into a lot of that during the City Nature Challenge.
Monica
Charlie Hohn

Patrick Leary
Charlie Hohn
krancmm
All the ones I uploaded for testing were from within the last week and I got 9 of 10 perfectly IDed. But I also use a dSLR, crop, etc.
In your testing, does the image quality make a huge difference?
Monica

Cullen Hanks
--
James Bailey
Ken-ichi
pointed out in this thread, the appropriate scale is always tricky. If
you're in San Diego you do want to exclude results from India but you
wouldn't want to exclude results from Mexico. You could only show taxa
that have been observed within a given radius of the target
coordinates, but how big should the radius be? It'll take some
tinkering.
Monica, regarding photo quality and cropping, this is still a pretty
big unknown for us, and we haven't done too much quantitative testing
on how much effect camera make and model or blurriness affects the
results. Anecdotally, I'm finding that it doesn't, particular with
taxa that it's very good at like lady beetles. Cropping photos so that
they mostly contain the subject does seem to make a big difference. If
you photograph a lady beetle on a flower, it often identifies the
flower and not the beetle.
Charlie Hohn

Mike Bear

Christopher Tracey
--
You received this message because you are subscribed to the Google Groups "iNaturalist" group.
To unsubscribe from this group and stop receiving emails from it, send an email to inaturalist+unsubscribe@googlegroups.com.

QuestaGame
Charlie Hohn
If you put stuff on the internet, machines and computers can see it. Even if iNat didn't do it someone else would. Which isn't a justification in and of itself of course. but i'd be surprised if anyone else really cares that a computer used a photo to help identify others of the species. Humans do it all the time.
i don't see using inat to support a gamification website (and tossing stuff on inat without talking to people first) as less exploitative than using publically posted photos to identify plants. So it's hard for me to take this too seriously.
That being said i have been told i argue too much on here, so that's all i will add to this post for now.
Ken-ichi
Objection acknowledged! And thanks for the thoughts, I think these are
good topics, even if I disagree with you on some points. If I'm
reading you correctly, you have two specific critiques:
1) Computer vision is not the best way to reduce time to
identification (TTID), and we should instead be adopting techniques
QuestaGame has proven to be more efficient.
First, iNat is not just about reducing time to identification. Our
mission is to connect people to nature through technology. Maybe a
more gamified experience would reduce average TTID to 6 days, but
would it do a better job helping people to connect with what they're
seeing outside? If you're standing in front of a flower and wondering
how you would figure out what it is, do you think to yourself "I need
something like Shazam," or do you think to yourself, "I need something
like Candy Crush"? Personally, I think the CV approach better meets
people's expectations about how their phones will help them learn
about the outdoors. I've watched several people use iNat for the first
time and be let down when they realize it's *not* like Shazam and they
have to wait for people to take a look at their observation. I'm not
asking you to agree with me on what the better approach is, but I hope
you'll agree that it's not obvious how best to help people connect to
nature, and that it isn't necessarily about time to receiving
feedback.
Second, the potential TTID of a CV system is measured in seconds, not
days. If it takes longer than that, you ignore the flower and go back
to playing Pokemon (or, ideally, look at another flower). There are
going to be problems with accuracy, network conditions, technology,
etc, but in the ideal scenario, someone with no background in natural
history should be able to point their phone at a flower and learn its
name in an instant. It probably won't work that well all the time, but
we're talking about a different order of magnitude in terms of TTID,
so I don't think it's fruitful to get hung up on what the faster
approach is.
2) Photographers and identifiers should be credited with training the
model, or at least notified
This is trickier and definitely warrants more discussion. On the
subject of attribution, we obviously can't credit every single person
who contributed to every single classification event since there could
be thousands and the structure of neural networks prevents us from
even knowing what training images contributed to any particular
classification, but I do think there's some potential for
incorporating (and thanking) some of the people most likely to have
contributed to a CV identification. For example, in an app, we could
have something at the bottom that says, "These results brought to you
by susanhewitt, aztekium, greglasley, and others in the iNat
community", and we could get these names from the top identifiers and
observers of taxa in the result set. Something to think about.
On the subject of using people's data for something they didn't
expect, I think that's terra incognita and I look forward to reading
the white paper you guys are working on. Personally I agree with
Charlie, and I don't really care if a computer is looking at my photos
to learn how to identify plants, since humans do it all the time, and
the computer will eventually use that knowledge to help out other
humans in their own learning process. I can see how some people might
be freaked out by it though, so if anyone out there feels that way,
let us know why! Again, we're still developing this, so the more we
know how people feel at the early stages the more we can accommodate
that feedback.
-ken-ichi
> You received this message because you are subscribed to the Google Groups
> "iNaturalist" group.
> To unsubscribe from this group and stop receiving emails from it, send an
QuestaGame
Charlie Hohn
In the world we live in, we are barreling full force into this. Which probably isn't a good thing. That being said, using this annoying intrusive technology to IDENTIFY SPECIES strikes me as almost a countermeasure. Taking something potentially harmful and deriving a great deal of good from it. Increasing public understandng of and connection to nature like Ken-Ichi said. Literally moving towards the 'trichorders' of Star Trek. And on a weird hypothetical scifi note, if we really do someday move towards some sort of 'singularity' where the AI (or AIs) becomes self aware... I'd WANT the AI too to have some sort of connection to and knowledge of the planet and life it is abstracty and distantly but still crucially connected to. I just don't see the downside here.
In terms of image privacy.... make no mistake.. ANY image you post on the Internet is getting combed through by dozens if not thousands of these bots. Your wedding pictures... security camera images on connected devices... landscape shots and scenery, aerial photos, and yes photos of plants and animals. Regardless of if iNat does this other bots will be coming through iNat photos. Is it ethical? maybe not. But that's what the Internet does now. Us not doing it doesn't mean others won't. There's literally no way to prevent it other than not using iNaturalist or ANY other website that has photos of any kind. So along with our spying computers I would rather have a world where Google Street View can identify plants as they drive, and where our smartphone can not only identify a plant but connect someone to a community of many others in the area excited about that plant. From both a conservation data standpoint and a cultural standpoint, the benefits of those far outweigh the costs.
On my other note... I admit I don't fully understand QuestaGame. I am not at all opposed to it connecting to iNat. However my first introduction to it was when a bunch of observations were being posted, then deleted right after they got an ID - a huge breach of etiquette on iNat and not a good faith part of the community. I don't bring this up because I am still mad about it, I don't think it was meant that way. However, I am truly confused as to how allowing an algorithm to see publically posted posters is bad, but accessing an Internet community to get IDs without a detailed introduction posted to the entire community first is good. In terms of AI vs CI scenarios, I am also a bit confused. You are making it sound like QuestaGame as banned from iNaturalist or something and I didn't think that was true. How is any of this getting in the way of you being able to use CI? Why do you feel threatened by this in particular?
To be clear again, I hope QG succeeds, i hope someday it expands to New England or CA plants so I can generate some donations from iNat, etc. But I hope it succeeds as a member of this community who is an active participant and who wants overall growth, rather than something that feels like it needs to 'defend' its own interests from 'competition' from other sources of species ID. I don't think we want that kind of thing. The more observations and accurate IDs the better. I'm not yet compelled by your argument that this is a bad thing. And I find your approach a little pushy. Like I saikd I sometimes get too riled up in here and need to take breaks/step away so I don't annoy people with excessive opinions. But I've been part of this community since 2011. You have been a very detatched part of this community for much less time, and appear to be coming in with very strong opinions that we as a community should not implement this new feature. I am having trouble understanding why, or for what reasons other than self-interest... I believe you have valid concerns, but I can't figure out what they are!
Anyway hopefully this was a better post. Again I don't want to discourage you or QG from being a part of iNat. But I think if you want to have a large influence on policy here, more so than me or any other user, you need to somehow formalize the connection with the site like other data partners do and have a well-written FAQ and description of what you are and what you are doing. I for one am still confused about that.

Scott Loarie
To unsubscribe from this group and stop receiving emails from it, send an email to inaturalist+unsubscribe@googlegroups.com.
To post to this group, send email to inatu...@googlegroups.com.
Visit this group at https://groups.google.com/group/inaturalist.
For more options, visit https://groups.google.com/d/optout.
Scott R. Loarie, Ph.D.
Co-director, iNaturalist.org
California Academy of Sciences
55 Music Concourse Dr
San Francisco, CA 94118
--------------------------------------------------

Paul Bailey
I'm in South Korea and started playing around with the Computer Vision Demo today. Is there a specific way you'd prefer to see feedback -- a certain number of observations to start with, for example?
Outside of a few areas - mainly birds - I really only get help from a couple of iNaturalist users (who I greatly appreciate), so being able to receive feedback from an AI program could be rather helpful. For identifications of things with many different groupings (as a non-expert, beetles come to mind here) it seems like it would be rather useful for creating a narrower range from which to search for more information on my own.

Julien Renoult
Ken-ichi
been addressed.
The California Academy of Sciences, a 501(c)3 non-profit organization
in California, USA.
> 2) What potential negative impacts have been identified ? (Surely there are some)
implied negative outcomes: identifying humans of certain races as
animals and making them feel like the subject of racism (this has
already happened with Google), people eating deadly mushrooms b/c they
were misidentified as edibles, people killing harmless organisms
misidentified as pests, etc. I think these are all avoidable if we are
honest about the limitations of this technology: it is not right 100%
of the time, so we should never present it as some all-knowing oracle.
It's a tool that gives you suggestions based on image similarity, just
like a graphing application can show you a trend in a series of
numbers. Plus, these are all potential problems with our existing
approach to identification.
More specifically, you could imagine a "robots are coming for our
jobs" version of this where we just assume the AI is always right and
let it override human opinions, and gradually push all the humans out
of iNat until it's just a monolithic natural history Skynet. That
would be exploitative, complete mission failure for us (can't connect
people to nature if you drive all the people away), and frankly
counterproductive if we *wanted* a perfect identification robot, for
all the reasons Scott described above, b/c we don't and may never have
enough training data to achieve that goal.
> 3) Who has rights to use it?
such usage right. Effectively that means we, the iNat team, are
granting that right, just as we do with the rest of iNat.
> 4) Who has rights to shut it down if its impacts prove negative ? (Could it even be shut down?)
> 5) Now that our images and expertise have been used to train the computer vision, do we have any rights over the use? Will private companies such as Facebook, Google, Amazon etc get to use it? How do we know? If they can use it, will they reimburse us?
CV model to someone you don't like (a national military, some horrible
ag company, etc), that's totally possible, and an example of the legal
terra incognita I spoke of before. My not-a-lawyer suspicion is that
in the US, if the purveyor of such a service is not actually
re-publishing the creative works that constituted the training data,
then there is no violation of copyright. Other jurisdictions have
different copyright interpretations, but I strongly suspect that this
issue is well ahead of the law in most places. This is certainly
something to consider, but I don't think anything is settled legally,
nor do I think it's a situation where there's a clear right or wrong
way to do it.
Regarding notification and reimbursement, we don't know yet, but
consider that almost every single commercial website and app you use
is already doing something similar by aggregating, analyzing, and
packaging your behavior on their services and selling it to others who
want to understand behavior to better sell things (or run political
campaigns, etc). You get reimbursed by getting to use their services
for free, and you don't get any notification beyond the warnings in
their Privacy Policy and Terms of Service. Andrew, you are using
GMail, so every word you type is being used by Google to sell ads (or
if you've opted out of that, just your usage is being used to sell
ads) and they are not crediting you or reimbursing you with anything
other than their service, yet you continue to use it. Furthermore,
this is a public forum (just like iNat) so who knows who is using our
words or for what purpose.
I have personally been approached in the past by companies seeking to
purchase such data from us, and I have turned them away because I
think that's creepy and I don't think any iNat user thinks that's part
of the deal. To be clear, we don't sell your personal data. Frankly,
though, I think using photos as training data for an AI is
categorically different. It doesn't allow people to discover that
25-year-old women in California who watch Game of Thrones are 50% more
likely than average to vote libertarian or something. Instead it might
show some biases like "photographers in California don't photograph
harvestmen much OR the iNat community is bad at identifying harvestmen
photos to species," which seems relatively harmless. I'm also not
opposed to selling a service like this, not to Monsanto (ew), but
maybe to researchers operating camera trap arrays or something.
> 6) Are there better ways to use AI (I think there are) - e.g. ways to increase the expert pool and people's engagement with nature - and if so, how can we best work to develop these?
the flood of common species so experts can focus on the rarities the
AI hasn't seen enough to know about.
> 7) Have legal and/or ethics experts been consulted by your team? What did they say?
things, or ignoring them because they're inconvenient. Keep in mind
that those of us who work on iNat also use iNat (cue the Hair Club For
Men jokes...), and we have all these same concerns ourselves. For me,
the most important ethical aspect of all this is that we are using the
data naturalists have produced to serve naturalists, or better yet to
recruit new naturalists. We are not exploiting people to get rich or
inflate our egos.
-ken-ichi

jesse rorabaugh
- How long until you can fly a drone over a park to take high resolution photographs and identify and map the vast majority of plants with the click of a button.
- How long until it is released on google street view to find every identifiable picture of an organism?
There are probably some ways to use this to for evil, but it is an inevitable outcome of the absurd power computers these days have so it doesn't seem worth fighting.
Charlie Hohn

AfriBats
Also nice to see that QG rewards iNat's expertise. Looks like there's plenty of room to explore and develop these things together.
Jakob

swhit...@yahoo.com
It correctly identified 23 photos to species (the first suggested species in the results list was correct.)
The correct species was near the top of the list for 3 photos (correct species was 2nd, 4th, and 5th in the results list.)
It correctly identified 1 to genus Plagodis, 1 to family Geometers, 4 to subfamily Ennominae, and 1 to superfamily Owlets and Allies. There were only 2 identified to incorrect moth groups.
That's pretty amazing, especially considering that some of these were tricky or uncommon species.
James Bailey
Scott Loarie
I managed to trip it up with Cassin's vireo from google images. It said it was plumbeous :)
--
You received this message because you are subscribed to the Google Groups "iNaturalist" group.
To unsubscribe from this group and stop receiving emails from it, send an email to inaturalist+unsubscribe@googlegroups.com.
To post to this group, send email to inatu...@googlegroups.com.
Visit this group at https://groups.google.com/group/inaturalist.
For more options, visit https://groups.google.com/d/optout.
QuestaGame
Thanks, Ken-ichi (and others).
Great discussion. Appreciate the answers, responses, participation - all the time you’re taking. (Charlie, you’re up late!).
I know everyone’s busy and the last thing we want these days is more to think about.
I think Scott is spot on with his comments re the CV tool. The philosopher Daniel C. Dennett puts it nicely:
“The real danger [of AI] is that we will over-estimate the comprehension of our latest thinking tools, prematurely ceding authority to them far beyond their competence…”
Personally I see tremendous potential with AI. I love playing around with machine learning tools like TensorFlow; and btw Ken-ichi, GMail believes I’m a 90-year-old mermaid (fun to fool the ad algorithms!).
I’ve also tested at least a half dozen “Shazam for nature” apps before this one. And Scott is right - there's plenty more afoot. They get good publicity. The media laps it up.
In a recent survey, we asked this question to users of one such CV tool - Merlin Bird ID:
“If Merlin Bird ID gave you a choice between (a) training the AI how to identify birds and, (b) in the same manner, with equal ease, training less advanced users how to identify birds, which would you choose?”
Sixty-five percent of the respondents said they’d rather train less advanced users.
Even if we disregard this survey, I think we have to ask - while we’re developing some cool CV, to what degree are we also implementing functionality that encourages people to train people?
In this month alone, private venture funds have invested $363 million In AI/Machine Learning. Each month the amount goes up. That's quite an AI tidal wave on its way.
If AI distracts us from enhancing tech that gets people teaching people about nature, this could be a negative outcome.
Let me be clear - iNat is a major achievement. It's the biggest and most advanced naturalist data collection system in the world. A result of very hard work, by dedicated people. And with this achievement, of course, comes risks and responsibilities - which is why I think the team looks so fit - the growing weight on their shoulders. :-)
There are also people in the iNat community who can probably identify all 13,750 species in Scott’s dataset. (I remember us marvelling, Ken-ichi, over one such person - and Chris, if you think this CV tool is impressive, then experts like this are wonders of the world!).
I think we’re all agreed that iNat - and society in general - would benefit from more people with knowledge like this. No?
Which means we should be careful not to take these minds for granted. With iNat my sense is that CAS is funding coders - would you agree? - but not the experts who are providing the nature knowledge. Or am I wrong? Meanwhile, here we are with scientists marching in the streets. Half the Great Barrier Reef has perished. The highest rate of extinction in 66 million years. The message of iNat's CV investment - to the next generation at least - is that we value coding skills. Whereas CI investment (a drop in the ocean compared to AI) values nature expertise.
The influence of iNat should not be underestimated. Perhaps QGame's tech is a kind of balancing off-set to CV? (A kind of Ed-tech play?). I hadn’t thought of it that way - but it could be the case. And maybe, Charlie, that's my concern: We have 50,000 kids here who are ready and eager to learn how to identify all 13,750 species (I suspect a few of them could do it now). They’re quick learners. It's easy for them. But maybe the message we/iNat/CAS are sending is that learning to code is more valuable than learning to identify species.
I’m not saying that encouraging kids to learn coding can’t also help connect them to nature. But I wonder - and I appreciate your acknowledgment, Scott - that without the CI element, if there's a danger, instead of “connecting humans to nature through technology,” we might end up doing something different, like connecting technology to nature through humans.
P.S. Scott - btw, re http://www.inaturalist.org/pages/identification_quality_experiment - we’re working with the Australian National University and others on a similar project. It could be interesting to test different "crowd" systems - to see what elements of CI, if any, make a difference in speed and accuracy.
Charlie Hohn

snuroo
Charlie Hohn

Ben Phalan
I tried the demo for some species from Brazil, with mixed results - see below. I'm sure this will improve as we get enough observations of these species to train the algorithms. For now, I guess none of the species (and in some cases, probably no species in the genus) has sufficient observations in the database.
For ten birds (the ten for which I have most recently taken good quality photos), it got correct family-level ID for one, correct order-level ID for 4, and did not suggest an ID for 3 (for one of these, the first result had the correct genus; for another, the correct family; and for the third, the right family was represented in the top ten). It suggested one incorrect genus-level ID (for a hummingbird), and one incorrect family-level ID (placing a tyrannulet in the New World Warblers - which is not unreasonable for a newbie to neotropical birds!)
For ten invertebrates (mostly butterflies), it got (as far as I can tell) correct genus-level ID for 4, correct subfamily for 2, and correct order for 2, and did not suggest an ID for 1 (the top result was in the wrong Order, so that was a good call). It got one completely wrong, suggested a jumping spider genus for a photo of a velvet ant.
I'm impressed by how good it is, and it is striking a pretty good balance between overconfidence and overcaution. One suggestion is that it could make use of the taxonomy tree to highlight species it has not learned yet (e.g. when it identifies a Lasaia sp. it could let us know there are 7 Lasaia species in the taxonomy tree, of which it only has enough images to know one).
Another refinement could be for it to "know" which geographic and taxonomic areas iNat has less comprehensive coverage for, perhaps by using species accumulation curves, and to be more cautious in such areas. In the neotropics, observations in iNaturalist represent only a small fraction of the species present, whereas for birds or butterflies in North America, I'd guess that most species are represented by now. It would also be nice to be able to provide feedback by letting the system know when it suggests something wrong.
Very interesting. I look forward to seeing it develop.
Detailed results - birds:
Crescent-chested Puffbird (Malacoptila striata) - “We're not confident enough to make a recommendation, but here are our top 10 results” Top result: White-whiskered Puffbird (Malacoptila panamensis)
Chestnut-capped Blackbird (Chrysomus ruficapillus) - “We're pretty sure this is in the order Perching Birds” Top result: Brown-headed Cowbird (Molothrus ater)
Masked Water-tyrant (Fluvicola nengeta) - “We're pretty sure this is in the order Perching Birds” Top result: Northern Wheatear (Oenanthe oenanthe)
White-eyed Parakeet (Psittacara leucophthalmus) - “We're not confident enough to make a recommendation, but here are our top 10 results” Top result: White-fronted Parrot (Amazona albifrons)
Picazuro Pigeon (Patagioenas picazuro) - “We're pretty sure this is in the family Pigeons and Doves” Top result: Rock Pigeon (Columba livia)
Sapphire-spangled Emerald (Amazilia lactea) - “We're pretty sure this is in the genus Cynanthus” Top result: Broad-billed Hummingbird (Cynanthus latirostris)
Planalto Tyrannulet (Phyllomyias fasciatus) - “We're pretty sure this is in the family New World Warblers” Top result: Orange-crowned Warbler (Oreothlypis celata)
White-barred Piculet (Picumnus cirratus) - “We're not confident enough to make a recommendation, but here are our top 10 results” Top result: Shining Bronze-Cuckoo (Chrysococcyx lucidus) [plus several woodpeckers further down]
Yellow-olive Flycatcher (Tolmomyias sulphurescens) - “We're pretty sure this is in the order Perching Birds” Top result: MacGillivray's Warbler (Geothlypis tolmiei)
Flame-crested Tanager (Lanio cristatus) - “We're pretty sure this is in the order Perching Birds” Top result: Bronzed Cowbird (Molothrus aeneus) [several New Zealand endemic bird species in the top ten]
Invertebrates
Skipper butterfly (species unknown) - “We're pretty sure this is in the genus White-Skippers Top result: Laviana White-Skipper (Heliopetes laviana) [looks like the right genus to me]
Nymphalid butterfly - “We're pretty sure this is in the order Butterflies and Moths”. Top result: Polyphemus Moth (Antheraea polyphemus) [not really similar]
Lycaenid butterfly - “We're pretty sure this is in the order Butterflies and Moths” Top result: Juniper Hairstreak (Callophrys gryneus) [which is the correct family]
Hesperid butterfly - “We're pretty sure this is in the subfamily Spread-wing Skippers” Top result: Glazed Pellicia (Pellicia arina) [not this species, but the subfamily seems correct]
Lycaenid butterfly - “We're pretty sure this is in the genus Hemiargus” Top result: Ceraunus Blue (Hemiargus ceraunus) [genus seems correct]
Metalmark butterfly - “We're pretty sure this is in the genus Lasaia” Top result: Blue Metalmark (Lasaia sula) [not this species, but genus appears to be correct]
Callicore sp. butterfly - “We're pretty sure this is in the subfamily Tropical Brushfoots” Top result: Anna’s Eighty-eight (Diaethria anna) [not this genus, but correct subfamily]
Large centipede (species unknown) - “We're pretty sure this is in the genus Scolopendra” Top result: Vietnamese Centipede (Scolopendra subspinipes) [seems reasonable]
Iridescent green bee (species unknown) - “We're not confident enough to make a recommendation, but here are our top 10 results” Top result: Drone Fly (Eristalis tenax)
Velvet ant (species unknown) - “We're pretty sure this is in the genus Phidippus” Top result: Cardinal Jumper (Phidippus cardinalis). [Wrong Class! But two velvet ants did appear in the top ten results]
I also threw in a (rather poor) photo of a mystery insect. I have no idea even what Order this is from. The system placed it in Diptera, but I don't think it is. Any suggestions from the collective intelligence model gratefully received! https://www.inaturalist.org/observations/3644911
QuestaGame
Charlie - yes, CAS has paid for the coding. It hasn’t paid (as far as I’m aware) for super-botanist Daniel Atha to help Scott's testing in New York, or am I wrong? And if it has, what about all the other super-naturalists on iNat who have helped train the AI? Is it paying for them? One thing I’m confident in - it’s at least as hard to become a super-botanist as a coder of machine learning.
The Aboriginals in Australia learned this lesson the hard way, and are doing all they can to ensure it doesn’t happen again. Come visit us in Oz; we’ll go to AIATSIS (aiatsis.gov.au), and you can see all the regulations that have resulted from centuries of exploiting people’s intellectual rights.
Looks like the rest of us may need to learn the lesson as well. And yes, we can be defeatist about it. All you have to do is compare the two studies going on here - Scott’s ID Quality Experiment vs the Google-sponsored CVPR 2017 - and you can see the massive disparity in financial commitment.
But I’m really encouraged by this discussion. Clearly we humans, being open and inclusive and loving each other, have the ability to think things through and offer creative solutions. It will probably take us at least 10 years to figure out the lessons of what we’re doing now. (Communications scientists, btw, predicted the “Fake News” problem at least a decade before it happened). I'd be happy to draw up some proposed guidelines for people to consider. I hope, if anything, we’re spawning some fresh thinking with this thread.
Thanks again to everyone for sharing and listening.
-Andrew
Charlie Hohn
Charlie Hohn
Paul Bailey
1. http://www.inaturalist.org/observations/4571275
Butterfly: Asian Comma (Polygonia c-aureum)
"We're pretty sure this is in the genus Commas" -- correct genus, but even though I put the location as 'South Korea' I received several North American species as guesses. P. c-aureum was included in 'Top 10'.
2. http://www.inaturalist.org/observations/5673774
Hover fly: Genus Helophilus (possibly Helophilus virgatus)
"We're pretty sure this is in the subfamily Drone Flies." -- correct subfamily. Two of the suggestions were for species found in the Americas. I supposebased on visual cues rather than range.
3. https://www.inaturalist.org/observations/5890690
Jumping spider: Evarcha albaria
"We're pretty sure this is in the genus Phidippus" -- incorrect guess. 9/10 suggestions were jumping spiders. Again, some suggested matches only have a distribution in the Americas.
4. https://www.inaturalist.org/observations/6004396
Unknown species of mayfly / Order Ephemeroptera
"We're pretty sure this is in the genus Muscoid Flies and Allies" -- incorrect guess. Suggestions include tachinid flies, house flies, bottle flies, hover flies, a bush cricket, and a dragonfly. I'm guessing the large eyes make identification a little more difficult for the AI.
5. https://www.inaturalist.org/observations/5990806
Butterfly: Short-tailed Blue (Everes argiades)
"We're pretty sure this is in the genus Cupido" -- incorrect guess, but close. All of the results are Blues and the Short-tailed Blue is fourth in the list of suggestions. And again, lots of North American species listed as suggestions.
6. https://www.inaturalist.org/observations/6003362
Stink bug: Sloe bug (Dolycoris baccarum)
"We're pretty sure this is in the genus Dolycoris" -- correct genus. First result is D. baccarum, with 9/10 of the results being stink bugs.

Michael Ellis
Michael Ellis
James Bailey
On Saturday, April 29, 2017 at 5:53:56 AM UTC-7, Scott Loarie wrote:
interesting, did you include a location? Cassin's vireo, plumbeous vireo and blue-headed vireo used to be all considered the same species "solitary vireo" and were split largely based on range. I would think thats an example where location would help the demo distinguish.
On Fri, Apr 28, 2017 at 9:25 PM, 'James Bailey' via iNaturalist <inatu...@googlegroups.com> wrote:
I managed to trip it up with Cassin's vireo from google images. It said it was plumbeous :)
--
You received this message because you are subscribed to the Google Groups "iNaturalist" group.
To unsubscribe from this group and stop receiving emails from it, send an email to inaturalist...@googlegroups.com.
To post to this group, send email to inatu...@googlegroups.com.
Visit this group at https://groups.google.com/group/inaturalist.
For more options, visit https://groups.google.com/d/optout.
James Bailey
QuestaGame
Hm, I think “guidelines” was wrong word. I didn’t mean “guidelines” in a restrictive sense. I meant a kind of headlamp - not slowing AI down (QGame is fully on board with AI), but trying to shed light on the “terra incognita" that seems to create so much confusion.
Anyway - this is my last post for the thread. I believe there are AI solutions that can get us where we want to go - a society that values nature - quickly and cheaply. We just need to think more openly, objectively, creatively - and include as many different viewpoints as possible. So - onward! :-)
Charlie Hohn

SummitMetroParks-NaturalResources

CW Gan
jesse rorabaugh
There are a lot of species which have been confirmed to genus and are not possible to get to species from almost any photos. If the genus was confirmed by a second person though, it seems like it would be good to train the computer on those photos.
Also, there are species where large numbers of captive individuals have been submitted but not many wild ones. Being able to go around a garden and ID the plants from this system would be a nice application of this. Unless it trains on cucumbers, tomatoes, and other cultivated plants it will be difficult to get there though.
Charlie Hohn

meu...@landcareresearch.co.nz
Scott Loarie
--
You received this message because you are subscribed to the Google Groups "iNaturalist" group.
To unsubscribe from this group and stop receiving emails from it, send an email to inaturalist+unsubscribe@googlegroups.com.
To post to this group, send email to inatu...@googlegroups.com.
Visit this group at https://groups.google.com/group/inaturalist.
For more options, visit https://groups.google.com/d/optout.

janetwright
Charlie Hohn
Cullen Hanks
--
You received this message because you are subscribed to the Google Groups "iNaturalist" group.
To unsubscribe from this group and stop receiving emails from it, send an email to inaturalist...@googlegroups.com.

stanw...@gmail.com

Gonzalo Zepeda
stan & wendy drezek
--
You received this message because you are subscribed to a topic in the Google Groups "iNaturalist" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/inaturalist/17wEweW5zZ4/unsubscribe.
To unsubscribe from this group and all its topics, send an email to inaturalist+unsubscribe@googlegroups.com.
To post to this group, send email to inatu...@googlegroups.com.
Visit this group at https://groups.google.com/group/inaturalist.
For more options, visit https://groups.google.com/d/optout.
James Bailey

Alice Abela
James Bailey
stan & wendy drezek
For ANYTHING non-butterfly or moth, I suggest it defaults to the family for ID (or subfamily if it is really sure, maybe genus in some cases?). At least at this point in time.
--
You received this message because you are subscribed to a topic in the Google Groups "iNaturalist" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/inaturalist/17wEweW5zZ4/unsubscribe.
To unsubscribe from this group and all its topics, send an email to inaturalist+unsubscribe@googlegroups.com.
To post to this group, send email to inatu...@googlegroups.com.
Visit this group at https://groups.google.com/group/inaturalist.
For more options, visit https://groups.google.com/d/optout.
Charlie Hohn
On Tuesday, October 3, 2017 at 3:35:23 PM UTC-4, stan & wendy drezek wrote:
I am not sure what the best default may be. First, I believe the ID is pitched as a suggestion more than a definitive ID. Second, in the case of common plants my experience is it has been excellent in actually identifying correctly about 60% of the species, having another 20% in its list, and blowing only about 20%. Since the person new to nature is going to benefit, it seems to me at least for plants letting it go to species if it "wants".I continue to be amazed at just how good it is. Obviously with many, many genera where the differences among the species are relatively technical and hard if not impossible to see in a photo, the ID tool isn't going to be a lot of help. But I really think for the beginning user it is a great help. But again it should be emphatically pitched as suggestions and not formal IDs.stan
On Tue, Oct 3, 2017 at 2:24 PM, 'James Bailey' via iNaturalist <inatu...@googlegroups.com> wrote:
For ANYTHING non-butterfly or moth, I suggest it defaults to the family for ID (or subfamily if it is really sure, maybe genus in some cases?). At least at this point in time.
--
You received this message because you are subscribed to a topic in the Google Groups "iNaturalist" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/inaturalist/17wEweW5zZ4/unsubscribe.
To unsubscribe from this group and all its topics, send an email to inaturalist...@googlegroups.com.
To post to this group, send email to inatu...@googlegroups.com.
Visit this group at https://groups.google.com/group/inaturalist.
For more options, visit https://groups.google.com/d/optout.
Alice Abela
GanCW
James Bailey

bouteloua

emra...@gmail.com
GanCW
and n
Charlie Hohn
GanCW

Chris Cheatle
jesse rorabaugh
I have been actively trying to push a lot of common arthropods over that twenty limit by resubmitting regularly many underrepresented species. It does seem like at the rate submissions come in three years from now this will not be nearly as much of an issue.
There is also a problem that the algorithm seems not to realize how bad the data set is with arthropods though. It gives a huge number of guesses for genus or family that are way off while stating that it is "pretty sure."
Janet Wright
Chris Cheatle
GanCW
GanCW
Charlie Hohn
AfriBats
AfriBats
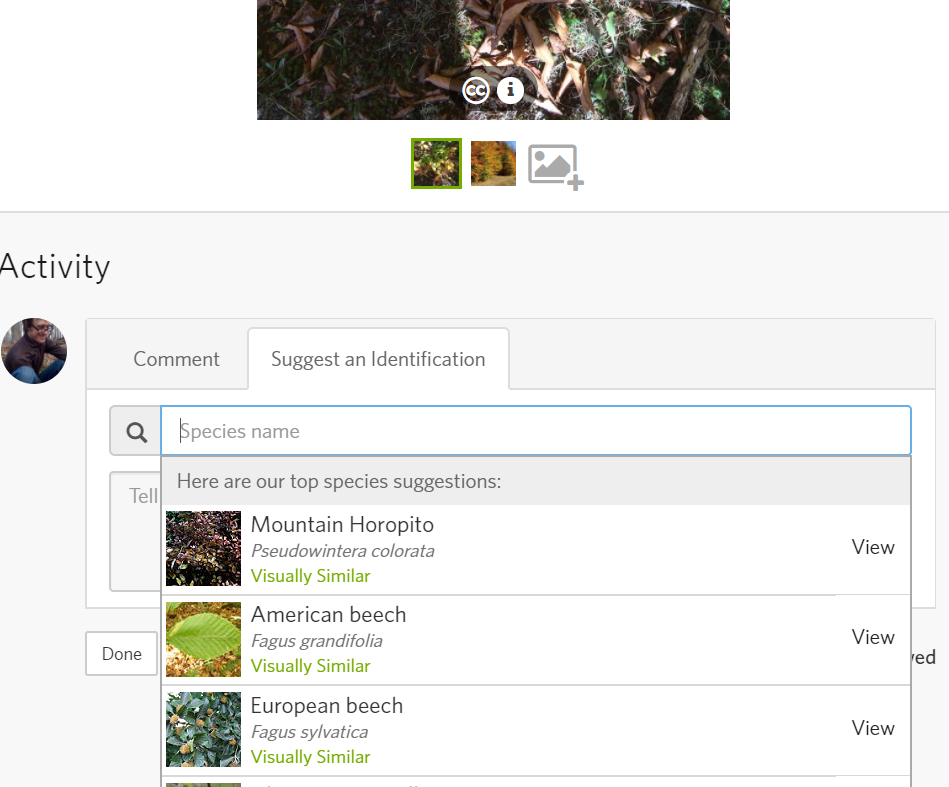
I really think something needs to be changed, as marvellous and useful this new tool is.
Jakob
GanCW
Charlie Hohn
I love the algorithm, I think it is really neat, but if the purpose is to help get things ID'ed to research grade accurately, it's not fulfilling that goal. It's instead making it a lot harder. When I do IDs for so-cal plants i spend a lot of time correcting these. And even still i miss most of the ones that are marked as research grade due to students agreeing with each other when they shouldn't.

Pat Lorch
Charlie Hohn
I also see several other mountain horopito observations in the eastern US... guessing they are all wrong as they are all recent and presumably algorithm fed.

phidippu...@gmail.com
On a different note, as has been suggested before, please make it clear on the interface (especially important to new users) that the suggested ID should be taken carefully and change the phrase 'we're pretty sure' to something less presumptuous :)
GanCW

Ken-ichi Ueda
GanCW
Ken-ichi
--
You received this message because you are subscribed to the Google Groups "iNaturalist" group.
To unsubscribe from this group and stop receiving emails from it, send an email to inaturalist+unsubscribe@googlegroups.com.
Charlie Hohn
To unsubscribe from this group and stop receiving emails from it, send an email to inaturalist...@googlegroups.com.
GanCW
To unsubscribe from this group and stop receiving emails from it, send an email to inaturalist...@googlegroups.com.

David K
1) It's a very computationally intensive process and on our current hardware each training takes a few weeks.

tony rebelo
Ken-ichi
Grade observations, which narrows things down a bit. To my knowledge,
you can't really rebuild a model piecemeal like you suggest, i.e.
carve off the Monarch part of the model but retrain on weird pill bugs
b/c those could use improvement. The system is learning from all
images, so you need to train with the entire dataset.
We haven't reached out beyond iNaturalist for training data, and it's
debatable whether or not that would really improve the system. Photos
from sites like BugGuide almost certainly would, because like iNat
they're also mostly in situ photos taken by (relatively) normal people
with normal camera setups. MPG data might actually really screw the
model up for moths b/c all the in situ photos are from the same angle
and there are tons of images of pinned specimens, which have pretty
different visual properties than the kind of photos that are usually
posted to iNat. On top of all that, we don't really have the right to
access that information, and even if we did, most of these sites don't
make their photo data easily available (EOL does, though).
> You received this message because you are subscribed to the Google Groups
> "iNaturalist" group.
> To unsubscribe from this group and stop receiving emails from it, send an

Alex Rebelo
Very cool, although it can struggle with some African taxa (probably because of the lack of RG training observations).
GanCW

Sam McNally
Thanks,


{kind=link}