Weird Instance Scheduler

Mos
Or does anybody has profound knowledge about it?
Background: My application is unchanged for weeks, configuration not changed and application's traffic is constant.
Traffic: One request per minute from Pingdom and around 200 additional pageviews the day (== around 1500 pageviews the day). The peek is not more then 3-4 request per minute.
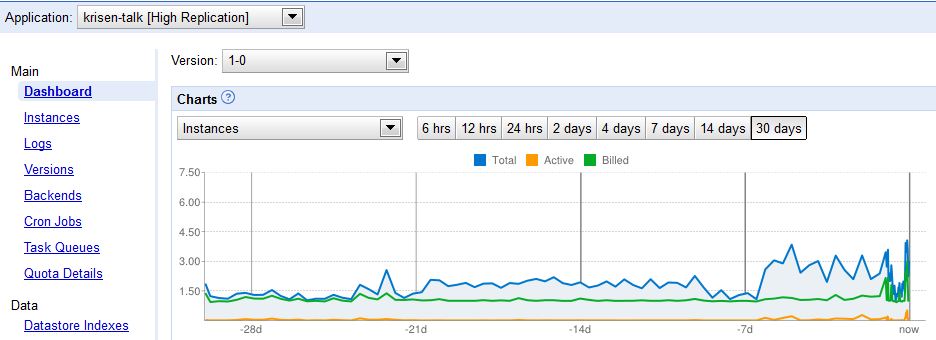
It's very obvious that one instance should be enough for my application. And that was almost the case the last months!
But now GAE creates most of the time 3 instances, whereby on has a long life-time for days and the other ones are restarted around
10 to 30 times the day.
Because load request takes between 30s to 40s and requests are waiting for loading instances, there are many request that
fail (Users and Pingdom agree: A request that takes more then a couple of seconds is a failed request!)
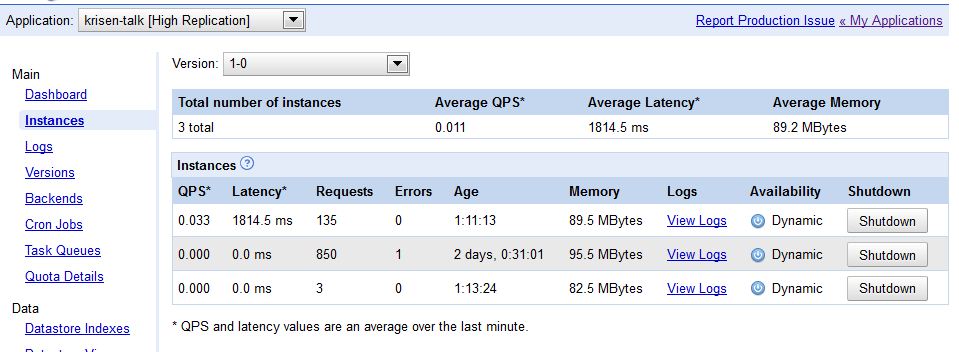
Please check the attached screenshots that show the behavior!
Note:
- Killing instances manually did not help
- Idle Instances were ( Automatic – 2 ) . Changing it to whatever didn't not change anything; e.g. like ( Automatic – 4 )
Thanks and Cheers
Mos
Mos
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 3:16 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 3:16 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 3:34 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 3:35 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 17:44 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 17:45 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 17:57 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 17:58 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 18:17 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 18:18 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 18:34 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 18:35 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 18:43 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 18:44 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 19:02 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 19:03 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 19:05 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 19:05 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 19:41 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 19:42 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 19:51 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 19:52 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 20:02 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 20:05 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 20:10 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 20:12 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 23:03 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 23:04 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 23:10 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 23:10 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN Mi 23:15 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP Mi 23:16 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN 02:48 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP 02:49 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN 03:04 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP 03:06 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN 03:12 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP 03:13 6 KB krisentalk
al...@pingdom.com DOWN alert: krisentalk (www.krisentalk.de) is DOWN 06:25 6 KB krisentalk
al...@pingdom.com UP alert: krisentalk (www.krisentalk.de) is UP 06:26 6 KB krisentalk
Mos
http://code.google.com/p/googleappengine/issues/detail?id=8004

Takashi Matsuo
Does anybody else experience abnormal behavior of the instance-scheduler the last three weeks (the last 7 days it got even worse)? (Java / HRD)
Or does anybody has profound knowledge about it?
Background: My application is unchanged for weeks, configuration not changed and application's traffic is constant.
Traffic: One request per minute from Pingdom and around 200 additional pageviews the day (== around 1500 pageviews the day). The peek is not more then 3-4 request per minute.
It's very obvious that one instance should be enough for my application. And that was almost the case the last months!
But now GAE creates most of the time 3 instances, whereby on has a long life-time for days and the other ones are restarted around
10 to 30 times the day.
Because load request takes between 30s to 40s and requests are waiting for loading instances, there are many request that
fail (Users and Pingdom agree: A request that takes more then a couple of seconds is a failed request!)
Please check the attached screenshots that show the behavior!
Note:
- Killing instances manually did not help
- Idle Instances were ( Automatic – 2 ) . Changing it to whatever didn't not change anything; e.g. like ( Automatic – 4 )
Thanks and Cheers
Mos
--
You received this message because you are subscribed to the Google Groups "Google App Engine" group.
To post to this group, send email to google-a...@googlegroups.com.
To unsubscribe from this group, send email to google-appengi...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/google-appengine?hl=en.
Takashi Matsuo | Developers Advocate | tma...@google.com
Mos
>> It's very obvious that one instance should be enough for my application. And that was almost the case the last months!
> Actually it's not true. In particular, check this log:
In those exceptional cases it could be ok if a second instance starts. (Nevertheless can't one instance not
handle 8 requests a minute?)
As I described: Instances are started and stopped without reason, even if less traffic per minute is available!
--> One attempt to stop GAE to create unnecessary instances.
Please forward http://code.google.com/p/googleappengine/issues/detail?id=8004 to the relevant GAE deparment.
Thanks!
Takashi Matsuo
> A possible explanation could be that the traffic pattern had changed.No. It's the same. Check for example the Request/Seconds statistics of my application for the last 30 days!
That's one expection where one client did 8 request in a minute (+ one pingdom). Nothing else this minute.
>> It's very obvious that one instance should be enough for my application. And that was almost the case the last months!
> Actually it's not true. In particular, check this log:
In those exceptional cases it could be ok if a second instance starts. (Nevertheless can't one instance not
handle 8 requests a minute?)
As I described: Instances are started and stopped without reason, even if less traffic per minute is available!
> * What is the purpose of max-pending-latency = 14.9 setting?" is high App Engine will allow requests to wait rather than start new Instances to process them"
--> One attempt to stop GAE to create unnecessary instances.
> * Can you try automatic-automatic for idle instances setting?I played around with this the last days and nothing changed. As I wrote: I had those configuration for months and it worked fine 3-4 weeks ago!
> * What is the purpose of those pingdom check? What happens if you stop that?To be alerted if GAE is down a again. "What happens if you stop that?" --> I wouldn't be angry anymore because I wouldn't recognize downtime's of my GAE application. ;)
Please forward http://code.google.com/p/googleappengine/issues/detail?id=8004 to the relevant GAE deparment.
Mos
> Actually there were almost 8 requests in a second. So App Engine likely needed more than one instance at this particular moment.
Meaning: Incoming requests may wait up to 15 seconds before starting a new instance. Therefore when 8 requests in one second occur that
should not mean that more instance needs to be started. Especially if there is no other traffic in this minute, as seen in my example.
Otherwise it would be a very bad implementation:
Starting a new instance means around 30s waiting time. Serving 8 parallel requests from one instance, would result in a maximum of
8 seconds for the last request (assuming that each request takes around 1 second).
There is no reason for this concrete example to fire up more instances and let requests wait more then 30 seconds until a new instance is loaded.
> ... here is what you've seen in the past weeks.
> First of all, it seems that you deployed 2 new versions on Aug 1 and Aug 2. Can you describe what kind of changes in those versions?
* One picture upload
* One html change
* One JavaScript change
* One css change
> And, to be fair, we didn't think of any change in our scheduler around 3 weeks ago which can cause this issue.
> More than 3 weeks before, those 2 idle instances might have had longer lives than now, but it was not a concrete behavior. Please think this way: you were just kind of lucky.
> If you want some instances always active, please set min idle instances.
Please accept http://code.google.com/p/googleappengine/issues/detail?id=8004
Thanks
Mos
http://www.mosbase.com
Takashi Matsuo
Hello Takashi,I thought this is why GAE has the concept of "pending-latency" (which we discussed below).
> Actually there were almost 8 requests in a second. So App Engine likely needed more than one instance at this particular moment.
Meaning: Incoming requests may wait up to 15 seconds before starting a new instance. Therefore when 8 requests in one second occur that
should not mean that more instance needs to be started. Especially if there is no other traffic in this minute, as seen in my example.
Otherwise it would be a very bad implementation:
Starting a new instance means around 30s waiting time. Serving 8 parallel requests from one instance, would result in a maximum of
8 seconds for the last request (assuming that each request takes around 1 second).
There is no reason for this concrete example to fire up more instances and let requests wait more then 30 seconds until a new instance is loaded.
> ... here is what you've seen in the past weeks.>>* You have been almost always set 'Automatic-2' idle instance setting.>* More than 3 weeks ago, number of loading requests were very few.> * Recently you have seen more loading requests than before.That, right! To be even more concrete: At the 16. august the problems got significant worse. Please check especially the time area from 16. august until today.
I checked it in our version control. As I wrote no related changes were made! Just Html/Css stuff:
> First of all, it seems that you deployed 2 new versions on Aug 1 and Aug 2. Can you describe what kind of changes in those versions?
* One picture upload
* One html change
* One JavaScript change
* One css changeAnd around the 16th august?
> And, to be fair, we didn't think of any change in our scheduler around 3 weeks ago which can cause this issue.
That shouldn't be luck! If GAE is not able to start Java instances in 5sec to 10 second, there needs be a guarantee that instances have longer lives. Otherwise Java applications on GAE are unusable because user would have a lot of 30seconds wait time (--> "failed requests"). (See also next comment regarding resistant instances)
> More than 3 weeks before, those 2 idle instances might have had longer lives than now, but it was not a concrete behavior. Please think this way: you were just kind of lucky.I tried this some days ago. I had one resistant instance. But that changed nothing. Instances get started and stopped as before. I assumed that requests would go to the resistant instance first. But that was no the case. Resistant instance was idle, but a dynamic instance got started and the request waits 30sec.
> If you want some instances always active, please set min idle instances.
Please check other discussion on this list and issues that reported similar observations.
> As you can see, I'm still not convinced to believe that the scheduler is misbehaving. I understand that you're having experiences which are bit worse than 3 weeks ago, and understand your feeling that you want to tell us 'fix it', but I'd say it's > >still something in the line of 'expected behavior' at least for now.> If you feel differently, please let me know.Yes I do feel differently (please see answers above).
Please accept http://code.google.com/p/googleappengine/issues/detail?id=8004

Kristopher Giesing
Mos
I hope someone from GAE's team takes it serious and elaborate on this.
To view this discussion on the web visit https://groups.google.com/d/msg/google-appengine/-/YIzxpRbmyHMJ.

Jeff Schnitzer
min-idle slider. GAE would route new requests to cold starts rather
than use the idle resident instance. Min-idle seemed like it should
be renamed "always idle" - it made my UX horrible, my bill higher, and
I haven't touched it since.
There may be rational logic to the scheduler behavior, but it feels
broken to just about everyone who experiments with it. I can only
guess at how many people have given up on GAE because of this issue.
Every time this comes up (and it comes up a *lot*), I'm going to repeat:
---> Requests should never be sent to cold instances.
Addressing that one issue seems like it would fix all the other
issues, or at least make them transparent enough that we can figure
out how to tune the scheduler on our own.
Jeff
> https://groups.google.com/d/msg/google-appengine/-/YIzxpRbmyHMJ.
>
Mos
As you know my setting to "Min Pending Latency" was automatic. The expectation is that GAE takes a reasonable default latency if it is "automatic".
And you say: Every parallel request starts a new instance if it is "automatic"? That' would be a "Min Pending Latency" of zero and not "automatic".
> If it doesn't work, try 2 min idle instances then
>> And around the 16th august?
The statistic shows that on this date the instance creation gets crazy. I double checked it with the Pingdom reports.
Starting on this day there were even more downtimes.
> So I'd say please try 2. If you still saw the user-facing loading requests, you need more resident instance to eliminate the user-facing loading requests.
Me and other people are reporting: The settings are broken!
It's very easy to reproduce. Please set up an application, send one request per minute (or second), configure 1 or 2 or 3 min idle instances and check what is happening. You will see that new instances are started although resistant instances are available.
Please take it serious and let somebody of the engineers check this!
Cheers
Mos

Johan Euphrosine
Hi all,
Please review the following thread where the lead engineer working on the scheduler (Jon McAlister) took the time to explain in great detail the behavior of min idle instance.
https://groups.google.com/d/msg/google-appengine/nRtzGtG9790/hLS16qux_04J
Once you read this, we can discuss if what you're experiencing is really a bug, or if you want the scheduler to behave differently from its current implementation, in which case the more constructive way out of this discussion is to fill feature request, and get it starred by your peers.
Mos
As often discussed on the mailing-list before and as Jeff said in this thread.
It's the combination of "Requests should never be sent to cold instances." and(!) the behavior of min idle instance which doesn't make any sense.
Please check the last comment of http://code.google.com/p/googleappengine/issues/detail?id=8004 where wrote down the problems in my point of view.
Senior Java-developers on this list which have many months of experience with GAE stated again again that there is a big issue around instance handling.
I think you have to trust your power-user and assign a team to work on this!
Johan Euphrosine
On Aug 24, 2012 11:28 PM, "Mos" <mos...@googlemail.com> wrote:
>
> Thanks Johan. I read the post some days before.
>
> As often discussed on the mailing-list before and as Jeff said in this thread.
> It's the combination of "Requests should never be sent to cold instances."
Please star this existing feature request:
http://code.google.com/p/googleappengine/issues/detail?id=7865
> and(!) the behavior of min idle instance which doesn't make any sense.
Like Jon explained in the post I linked, the scheduler will favor routing traffic to idle dynamic instance rather than idle reserved idle instance and it will always try to maintain the invariant of N x Min-Idle-Instances by starting new instance if the reserved instances are busy.
If you want another behavior like a new slider for Min-Instances please fill a new feature request.
> Please check the last comment of http://code.google.com/p/googleappengine/issues/detail?id=8004 where wrote down the problems in my point of view.
>
I would suggest starring existing or filling new features of defects for those separate issues you identified rather than aggregating comments on this production issue.
> Senior Java-developers on this list which have many months of experience with GAE stated again again that there is a big issue around instance handling.
> I think you have to trust your power-user and assign a team to work on this!
>
We do trust our power users and recognize their frequent contributions to the App Engine developer community.
But like any developer community, there are preferred ways of making feature requests or reporting bugs and I'm just trying to direct your feedbacks to what is more likely to produce results.
If you fill a feature request and get it starred enough the engineering team will definitely consider it, as each team regularly look at the tracker for the most starred feature request of their respective component.
If you fill a bug and produce a way to reproduce it and get it starred enough, it will get triaged and escalated to the corresponding team as we regularly triage the issue tracker when organizing bug squashing sessions.
That's how things are supposed to work. But sometime we lag, we forget about issues or miss them. You are more than welcome to point us at specific issue tracker entries when this happen so we can correct our mistakes.
Armen Danielyan
Johan Euphrosine
> Hi Mos,
>
> I have experienced very similar issues for the last week. The loading time
> of my website increased from 2-3 seconds to 10-15 seconds all of a sudden.
> When it happened I tried to change the app settings, changed it from F1 to
> F2, increased the idle instances setting but nothing helped.
>
> During the week I was playing with settings with no results. Suddenly the
> issue has been solved by itself today. I want to stress, that yesterday the
> problem was still there, and I haven't changed any settings since then.
>
> It means that the problem was on Google's side, and they solved it silently.
> It's a shame Google doesn't accept their mistakes, and keep saying that it's
> our fault because we didn't configure our applications in a right way. I
> will never deploy any new application on GAE.
>
Are you affected by
http://code.google.com/p/googleappengine/issues/detail?id=7706?
The engineering team is working on improving the high performance
variance for apps that need to load a lot of code on loading request
(typically Java apps with "big" dependency like spring, guice or
depending on a lot of jars).
If you app is hit by this problem, please star this issue and comment
with your application id.
Thanks in advance.
> To post to this group, send email to google-a...@googlegroups.com.
> To unsubscribe from this group, send email to
> google-appengi...@googlegroups.com.
> For more options, visit this group at
> http://groups.google.com/group/google-appengine?hl=en.
--
Developer Programs Engineer
Google Developer Relations
Takashi Matsuo
> Setting Max Pending Latency doesn't force requests to be in the pending queue for the specified time. Please use Min Pending Latency instead.
As you know my setting to "Min Pending Latency" was automatic. The expectation is that GAE takes a reasonable default latency if it is "automatic".
And you say: Every parallel request starts a new instance if it is "automatic"? That' would be a "Min Pending Latency" of zero and not "automatic".
Please check the responses of other user in this thread. This feature is totally broken and can not be used.
> If it doesn't work, try 2 min idle instances then
>> And around the 16th august?> Sigh... isn't it a waist of time? What is the reason you picked that date?Did you see/studied my pictures from the first post of this thread?
The statistic shows that on this date the instance creation gets crazy. I double checked it with the Pingdom reports.
Starting on this day there were even more downtimes.Again: As wrote in my post before that does not work. Check the responses from Kristopher and Jeff on this thread.
> So I'd say please try 2. If you still saw the user-facing loading requests, you need more resident instance to eliminate the user-facing loading requests.
> So what is your expected behavior and actual result? Nobody in our team can do anything if you just keep saying "the setting that used to work doesn't work anymore" without trying mu suggestion.> I think my answer is clear at least for some points. 1) You'd better use 'min pending latency' instead of 'max pending latency' to prevent new instances to spin up as much as possible. 2) If you need longer instance lives, set appropriate number of min idle instances.As I wrote: I tried different settings. As many other people in this group as well.
Me and other people are reporting: The settings are broken!
It's very easy to reproduce. Please set up an application, send one request per minute (or second), configure 1 or 2 or 3 min idle instances and check what is happening. You will see that new instances are started although resistant instances are available.
Please take it serious and let somebody of the engineers check this!
Kristopher Giesing
On Aug 24, 2012 11:28 PM, "Mos" <mos...@googlemail.com> wrote:
>
> Thanks Johan. I read the post some days before.
>
> As often discussed on the mailing-list before and as Jeff said in this thread.
> It's the combination of "Requests should never be sent to cold instances."Please star this existing feature request:
http://code.google.com/p/googleappengine/issues/detail?id=7865
> and(!) the behavior of min idle instance which doesn't make any sense.
Like Jon explained in the post I linked, the scheduler will favor routing traffic to idle dynamic instance rather than idle reserved idle instance and it will always try to maintain the invariant of N x Min-Idle-Instances by starting new instance if the reserved instances are busy.
Kristopher Giesing
Like Jon explained in the post I linked, the scheduler will favor routing traffic to idle dynamic instance rather than idle reserved idle instance and it will always try to maintain the invariant of N x Min-Idle-Instances by starting new instance if the reserved instances are busy.
Kristopher Giesing
Jeff Schnitzer
on the test app?
Jeff

Mobicage
Johan Euphrosine
<kris.g...@gmail.com> wrote:
> On Friday, August 24, 2012 2:59:11 PM UTC-7, Johan Euphrosine (Google)
> wrote:
>>
>>
>> On Aug 24, 2012 11:28 PM, "Mos" <mos...@googlemail.com> wrote:
>> >
>> > Thanks Johan. I read the post some days before.
>> >
>> > As often discussed on the mailing-list before and as Jeff said in this
>> > thread.
>> > It's the combination of "Requests should never be sent to cold
>> > instances."
>>
>> Please star this existing feature request:
>> http://code.google.com/p/googleappengine/issues/detail?id=7865
>
> Done.
>
>>
>> > and(!) the behavior of min idle instance which doesn't make any sense.
>>
>> Like Jon explained in the post I linked, the scheduler will favor routing
>> traffic to idle dynamic instance rather than idle reserved idle instance and
>> it will always try to maintain the invariant of N x Min-Idle-Instances by
>> starting new instance if the reserved instances are busy.
>
> OK, the post by Jon was an interesting read because it explains why Google
> seems to think everything is working as intended. What doesn't seem to be
> penetrating is that it doesn't matter what some definition on a piece of
> paper somewhere says the system is supposed to do, if that definition
> doesn't actually help developers build good products.
What I was trying to point by referring to Jon post was:
- Here is how the scheduler has been designed
- If you disagree with the design, the group is a good place to
discuss this but ultimately we would like to reach the point where
more specific feature requests are filled (like
http://code.google.com/p/googleappengine/issues/detail?id=7865) that
we can escalate to the engineering team.
> The feature starred above absolutely needs to be implemented. I just wish
> there was an easier way of getting customers who are frustrated by the
> instancing behavior to focus on that one feature request, because the naive
> interpretation of the existing GAE tuning parameters suggests it shouldn't
> be necessary.
behavior, care to star this feature request? :)
http://code.google.com/p/googleappengine/issues/detail?id=5826
>
> - Kris
> --
> You received this message because you are subscribed to the Google Groups
> "Google App Engine" group.
> To post to this group, send email to google-a...@googlegroups.com.
> To unsubscribe from this group, send email to
> google-appengi...@googlegroups.com.
> For more options, visit this group at
> http://groups.google.com/group/google-appengine?hl=en.
--
Johan Euphrosine
> Hi
>
> Can somebody explain how it is possible that
> - I have 1 "resident" java appengine instance
> - I didnt send any test requests for 90 minutes
> - When I sent the request, the system had to warm up, although I have 1
> resident java appengine.
>
> What does resident exactly mean?
https://groups.google.com/d/msg/google-appengine/nRtzGtG9790/hLS16qux_04J
"""
Because the scheduler is now treating the reserved instances as
Min-Idle-Instances, what you're describing is expected
behavior. They are intentionally kept idle, and it tries to serve
traffic using the non-reserved instances. Then, if the
non-reserved instances can't keep up, then it will make use of
the reserved instances.
That is, to repeat, the invariant that the scheduler is trying to
maintain here is that your app has at least 3 idle instances.
And if an instance is getting traffic, then it isn't idle. The value
of an idle instance is that it can process requests right-away
if needed, without having to first warmup or do a loading request.
It sounds like what you'd really prefer is something like
Min-Instances, but that's not presently an available option.
"""
The scheduler route traffic to resident idle instance when dynamic
instances can't keep with the traffic and always try to keep Min Idle
Instances in reserve at all times,
I believe it currently need to start at least 1 dynamic instance before
making use of the resident idle capacity.
> You received this message because you are subscribed to the Google Groups
> "Google App Engine" group.
> To view this discussion on the web visit
Johan Euphrosine
Resident instances are used for processing incoming request if there
is no dynamic instance, but it is possible that the scheduler warm up
new dynamic instance to maintain the Min Idle Instance invariant.
carl@ if you can give us your application id, and the last timestamp
of occurence of the event you reported, we can try to figure out why
your test spawned a new dynamic instance.

Carl Schroeder
Kristopher Giesing
Kristopher Giesing
Resident instances are used for processing incoming request if there
is no dynamic instance
Johan Euphrosine
<schroede...@gmail.com> wrote:
> Let me see if I understand this correctly: there is currently no way on app
> engine to ensure that there is an instance ready to process incoming
> requests for an app that has been idle for some period of time. Min idle
> instances (labeled as Resident) sit there and do almost nothing while user
> facing requests are instead sent to cold instance starts. If true, that
> dovetails with what I have seen in the behavior of my app. For python
> runtimes with sub-second spinup times, this is no big deal. For java
> runtimes with spinup times in double digit seconds it is a deal-breaker of a
> "feature".
>
> The problem seems to be that the scheduler thinks sending a request to a
> non-existent dynamic instance is a better idea than using the Resident
> instance for it's intended purpose: to serve requests when dynamic instances
> are unable to. This is probably a corner case born of low traffic conditions
> that allow user request serving dynamic instances to despawn.
That's not what we observed, as I corrected in the previous email:
Resident instances are used for processing incoming request if there
is no dynamic instance, but it is possible that the scheduler warm up
new dynamic instance to maintain the Min Idle Instance invariant.
"""
application id and the timestamp of occurence and we can try to figure
out what happened.
Thanks in advance.
>
> For low traffic apps, "Resident" instances serve almost no purpose. Better
> to do away with them via the slider bars and just set up a script to tickle
> the app just often enough to keep one "Dynamic" instance resident.
>
> So, two features to fix this:
> First, a slider bar labeled "Minimum Dynamic instances" ;)
> Second, a button to enable sending warm-up requests and having them return
> before considering an instance for user facing requests.
>
>
> You received this message because you are subscribed to the Google Groups
> "Google App Engine" group.
> To view this discussion on the web visit
Johan Euphrosine
Can you comment with the appid and timestamps of when this last happened?
Thanks in advance.
>
> - Kris
> --
> You received this message because you are subscribed to the Google Groups
> "Google App Engine" group.
> To view this discussion on the web visit
Carl Schroeder
Carl D'Halluin
To view this discussion on the web visit https://groups.google.com/d/msg/google-appengine/-/ApT6E62dU9QJ.
To post to this group, send email to google-a...@googlegroups.com.
To unsubscribe from this group, send email to google-appengi...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/google-appengine?hl=en.
Carl D'Halluin
Next-generation communication at http://www.rogerthat.net
Email: ca...@mobicage.com
Phone: +32 9 324 25 64
Fax: +32 9 324 25 65
Twitter: @carl_dhalluin
NV MOBICAGE
Antwerpsesteenweg 19
9080 Lochristi
Belgium

Mos
Google has to acknowledge that the current implementation is buggy or the implementation works but doesn't make any sense in practice.
Bye the way - The problem is not restricted to resident instances. From time to time the same happens for dynamic instances:
One or more dynamic instances are running and are almost idle (sometimes really idle==no request or just one request is served).
Request comes and starts a new dynamic instance, it goes through 30-40 seconds of warmup, then request is served.
Mos
Please check the comment, the screenshot and the log-file I filed there.
Dear GAE-Team, what else do you need to fix this? In this thread and in several issues you should have more than enough proof and examples.....
Cheers
Mos
Carl Schroeder
Takashi Matsuo
To view this discussion on the web visit https://groups.google.com/d/msg/google-appengine/-/kb9OyMgMH5wJ.
To post to this group, send email to google-a...@googlegroups.com.
To unsubscribe from this group, send email to google-appengi...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/google-appengine?hl=en.
Jeff Schnitzer
Takashi Matsuo
Jeff Schnitzer
Carl Schroeder
Mos
I can offer you to deploy my Spring MVC application to another app-engine-account for testing purpose (Sure, it shouldn't be public available there.)
Then you can test and configure it like you want....
Or even simpler: My application is for days really unreliable. Many requests take more then 20s or 30 seconds (because of loading requests).
Hence -- it couldn't get much more worse. You are free to change my configuration settings, as long as we arrange a specific time periods
and as long as my bill doesn't go up. (Just contact me directly)
Bye the way: Is a colleague of yours evaluation http://code.google.com/p/googleappengine/issues/detail?id=8004?
Then we should wait, otherwise his evaluation may be disrupted.
> At the same time, I'd like one of you to file an issue on our issue tracker for this particular topic, 'Setting min idle instances doesn't work',
One or more dynamic instances are running and are almost idle (sometimes really idle==no request or just one request is served).
Request comes and starts a new dynamic instance, it goes through 30-40 seconds of warmup, then request is served.
http://code.google.com/p/googleappengine/issues/detail?id=8004#c8
Cheers
Mos
Kristopher Giesing
Mos
(Tried many configuration issues. Nothing helps. My last try : max-idle-instance to one)
Any news on http://code.google.com/p/googleappengine/issues/detail?id=8004 ?
As Kris wrote below the problem exists now for one month!
GOOGLE, PLEASE FIX THE CRITICAL PRODUCTION PROBLEM .. we are loosing every day money and customer as long as GAE/Java works like junk !!
I deeply regret to trust Google/GAE and build our application for this PaaS.
Mos
Takashi Matsuo
I posted a great deal of information in the thread here:In that thread I posted logs that showed that the very first request after setting min instances to 1 will spawn a new instance (in addition to the instance that the min instances setting created). The app ID used in that testing is "titan-game-qa" and the timestamps are in the logs I posted.
At some point I will have enough bandwidth to set up a more specific test, but I feel I've already posted plenty of information for GAE engineers to digest.
To view this discussion on the web visit https://groups.google.com/d/msg/google-appengine/-/ubhrxTXYlC4J.
To post to this group, send email to google-a...@googlegroups.com.
To unsubscribe from this group, send email to google-appengi...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/google-appengine?hl=en.
Kristopher Giesing
Kristopher Giesing
Takashi Matsuo
Does your warmup request initialize the persistent manager, or some libraries you may want to preload beforehand?
--
You received this message because you are subscribed to the Google Groups "Google App Engine" group.
To view this discussion on the web visit https://groups.google.com/d/msg/google-appengine/-/4FGx8YdHUIgJ.

Drake
> So, actually, I am baffled. Any ideas, anyone?
Does your warm up load all your classes?
Warm is kind of relative J
Carl Schroeder
- 2012-09-01 09:36:59.435 /members/sphere/show/527001 200 13821ms 10kb Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.79 Safari/537.1
- 50.131.165.108 - - [01/Sep/2012:09:36:59 -0700] "GET /members/sphere/show/527001 HTTP/1.1" 200 10518 "http://lemurspot.appspot.com/members/sphere/list/Public" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.79 Safari/537.1" "lemurspot.appspot.com" ms=13822 cpu_ms=10594 cpm_usd=0.001175 loading_request=1 instance=00c61b117c2fce802ccb47a4e712b784e3f54e
- I 2012-09-01 09:36:53.878
- [s~lemurspot/3.361443701203144598].<stdout>: Loading core functions for production environment
- I 2012-09-01 09:36:59.434
- This request caused a new process to be started for your application, and thus caused your application code to be loaded for the first time. This request may thus take longer and use more CPU than a typical request for your application.
- ----------------------------------------------------------------------------------------------------------------------------------------------------
- 2012-09-01 09:36:50.272 /_ah/warmup 404 13273ms 0kb
- 0.1.0.3 - - [01/Sep/2012:09:36:50 -0700] "GET /_ah/warmup HTTP/1.1" 404 205 - - "3.361443701203144598.lemurspot.appspot.com" ms=13273 cpu_ms=9662 cpm_usd=0.000023 loading_request=1 instance=00c61b117c0d042247ec72de95d943c6c2be81
- I 2012-09-01 09:36:45.776
- [s~lemurspot/3.361443701203144598].<stdout>: Loading core functions for production environment
- | 2012-09-01 09:36:49.678
- [s~lemurspot/3.361443701203144598].<stdout>: Sep 01, 2012 16:36:49 Warmup request recieved
- I 2012-09-01 09:36:50.271
- This request caused a new process to be started for your application, and thus caused your application code to be loaded for the first time. This request may thus take longer and use more CPU than a typical request for your application.
- ----------------------------------------------------------------------------------------------------------------------------------------------------
Jeff Schnitzer
PersistenceManagerFactory, so that should be "in your code".
That 400ms - is that measured from a filter at the outermost layer?
An interesting thing to try is to set up a handler for the warmup
request which issues an actual query to the datastore. Any query.
Jeff
> You received this message because you are subscribed to the Google Groups
> "Google App Engine" group.
> To view this discussion on the web visit
Kristopher Giesing
Mos
There are just 1 or 2 loading-requests the day. Remember: The weeks before I head hundreds of loading-request and many DeadlineExceededException.
But no status-update from Google on http://code.google.com/p/googleappengine/issues/detail?id=8004 ?
What has happened?
- Just luck ?
- Did some GAE infrastructure / policy changed on 1th September ?
- Did somebody fix the weird instance scheduler? Perhaps after his or her summer holiday ?
- Or did praying help ?
Please Google, be transparent on this issue. I had a downtime of 5h 19m in August (99,29%) in August.
Other people had similar experiences. We need to know if reliability of GAE is fixed durably!
Thanks
Johan Euphrosine
> The last three days the GAE instance scheduler works accurate again.
> There are just 1 or 2 loading-requests the day. Remember: The weeks before I
> head hundreds of loading-request and many DeadlineExceededException.
>
> But no status-update from Google on
> http://code.google.com/p/googleappengine/issues/detail?id=8004 ?
>
> What has happened?
>
> - Just luck ?
> - Did some GAE infrastructure / policy changed on 1th September ?
> - Did somebody fix the weird instance scheduler? Perhaps after his or her
> summer holiday ?
> - Or did praying help ?
>
> Please Google, be transparent on this issue. I had a downtime of 5h 19m in
> August (99,29%) in August.
percentage of (loading) requests taking more than 5 seconds (and
indenfied by *pingdom* as downtime).
The App Engine SLA doesn't have the same definition of downtime
https://developers.google.com/appengine/sla
"""
"Downtime" means more than a ten percent Error Rate for any Eligible
Application.
"Downtime Period" means, for an Application, a period of five
consecutive minutes of Downtime. Intermittent Downtime for a period of
less than five minutes will not be counted towards any Downtime
Periods.
"Error rate" for the Service is defined with the Covered Services.
"""
As of today, the App Engine SLA only covers the following components,
https://developers.google.com/appengine/sla_error_rate.
"""
- Serving Infrastructure (HTTP Request sent to App Engine that results
in an INTERNAL_SERVING_ERROR)
- Datastore (Datastore api call returning one of the following
errors: INTERNAL_ERROR, TIMEOUT, BIGTABLE_ERROR,
COMMITTED_BUT_STILL_APPLYING, TRY_ALTERNATE_BACKEND )
"""
And unfortunately loading request latency is not covered by the SLA yet.
The serving infrastructure team is constantly working on improving the
reliability of loading requests performance, but this is a long term
effort and in the meantime we (and the App Engine community) can help
you to optimize the performance on your application.
Mos
>> http://code.google.com/p/googleappengine/issues/detail?id=8004 ?
> I just updated the issue with more details.
What does "The reliability team performed a maintenance operation, and it seems that most application are back to a normal levels of loading requests." mean?
- Could this happen from time to time again?
- The issue last for weeks! Why do we need to escalate such a critical issue with a 50+ mailing-thread and why isn't GAE able to monitor such bad behavior by itself?
->> Please Google, be transparent on this issue. I had a downtime of 5h 19m in
>> August (99,29%) in August.
> As we discussed before what you refer as downtime is actually a percentage of (loading) requests taking more than 5 seconds (and indenfied by *pingdom* as downtime).
The Google SLA needs a reality-check!
If my users had over and over again to wait more than 30 seconds (in sum over 5h in August) , partly with a DeadlineExceededException,
it isn't acceptable!
Cheers
Mos
Johan Euphrosine
> Hello Johan,
>
>
>>> http://code.google.com/p/googleappengine/issues/detail?id=8004 ?
>> I just updated the issue with more details.
I updated the issue again.
>
> Thanks, but can you please be a bit more specific?
> What does "The reliability team performed a maintenance operation, and it
> seems that most application are back to a normal levels of loading
> requests." mean?
>
> - Could this happen from time to time again?
monitoring the overall platform health and performing maintenance
operation.
"Google I/O 2011: Life in App Engine Production" is a great resource
if you are looking for more details about the reliability team
operation:
http://www.youtube.com/watch?v=rgQm1KEIIuc
> - The issue last for weeks! Why do we need to escalate such a critical
> issue with a 50+ mailing-thread and why isn't GAE able to monitor such bad
> behavior by itself?
>
> ->> Please Google, be transparent on this issue. I had a downtime of 5h 19m
> in
>
>>> August (99,29%) in August.
>
>> As we discussed before what you refer as downtime is actually a percentage
>> of (loading) requests taking more than 5 seconds (and indenfied by *pingdom*
>> as downtime).
>
> That's not correct! Pingdom reports downtime if a request takes more than 30
> seconds.
> The Google SLA needs a reality-check!
SLA by filling feature requests on the public issue tracker or by
contacting premier customer support:
http://code.google.com/p/googleappengine/issues/entry?template=Feature%20request
https://developers.google.com/appengine/docs/premier/
> If my users had over and over again to wait more than 30 seconds (in sum
> over 5h in August) , partly with a DeadlineExceededException,
> it isn't acceptable!
improving loading request reliability, see:
http://code.google.com/p/googleappengine/issues/detail?id=7706
Kristopher Giesing
Kristopher Giesing

Timofey Koolin
PS. This is with default application settings, and for this test I reverted to using front ends instead of backends (since I gather backends don't support channels, that's no longer an option for me).
--
You received this message because you are subscribed to the Google Groups "Google App Engine" group.
To view this discussion on the web visit https://groups.google.com/d/msg/google-appengine/-/-1SggFlu3_sJ.
Kristopher Giesing

{kind=link}
{kind=link}
DFB
On Thursday, August 23, 2012 3:58:44 AM UTC+8, Mos wrote:
Does anybody else experience abnormal behavior of the instance-scheduler the last three weeks (the last 7 days it got even worse)? (Java / HRD)
Or does anybody has profound knowledge about it?
Background: My application is unchanged for weeks, configuration not changed and application's traffic is constant.
Traffic: One request per minute from Pingdom and around 200 additional pageviews the day (== around 1500 pageviews the day). The peek is not more then 3-4 request per minute.
It's very obvious that one instance should be enough for my application. And that was almost the case the last months!
But now GAE creates most of the time 3 instances, whereby on has a long life-time for days and the other ones are restarted around
10 to 30 times the day.
Because load request takes between 30s to 40s and requests are waiting for loading instances, there are many request that
fail (Users and Pingdom agree: A request that takes more then a couple of seconds is a failed request!)
Please check the attached screenshots that show the behavior!
Note:
- Killing instances manually did not help
- Idle Instances were ( Automatic – 2 ) . Changing it to whatever didn't not change anything; e.g. like ( Automatic – 4 )
Thanks and Cheers
Mos