A Proposal for C++ Concurrency
486 views
Skip to first unread message

Mingxin Wang
Apr 21, 2017, 6:35:59 AM4/21/17
to ISO C++ Standard - Future Proposals
In the past two years, I have been trying to conclude the lack of support for various concurrent programming requirements among existing solutions. After 87 times of reconstruction, I have concluded the issue into two major problems and solved them.
The Problems
1. The architecture: how to structure concurrent programs like serial ones as flexible as function calls
“Function” and “Invoke” are the basic concepts of programming, enabling users to wrap their logic into units and decoupling every parts from the whole program. Based on my solution, these concepts can be naturally generalized in concurrent programming, enabling users to structure concurrent programs like serial ones as flexible as function calls.
2. The algorithm: how to implement synchronization requirements to adapt to different runtime environment and performance requirements
void solve_1(std::size_t n) { std::vector<std::future<void>> v; for (std::size_t i = 0; i < n; ++i) { v.emplace_back(std::async(do_something)); } for (auto& f : v) { f.wait(); }}Figure 1
void solve_2(std::size_t n) { std::atomic_size_t task_count(n); std::promise<void> p; for (std::size_t i = 0; i < n; ++i) { std::thread([&] { do_something(); if (task_count.fetch_sub(1u, std::memory_order_release) == 1u) { std::atomic_thread_fence(std::memory_order_acquire); p.set_value(); } }).detach(); } p.get_future().wait();}Figure 2
Suppose there’s a common requirement to implement a model that launch n async tasks and wait for their completion. Implementations
- may maintain n "promises" for each task and perform several Ad-hoc synchronization operations (some other advanced solutions e.g. the “Coroutine” work on the same principle), as is shown in Figure 1, or
- may manage an atomic integer maintaining the unfinished number of tasks (initially, n) with lock-free operations, and let the first (n - 1) finished tasks synchronize with the last finished one, then let the last finished task perform an Ad-hoc synchronization operation to unblock the model (some other advanced solutions such as the “Latch” or the “Barrier” work on the same principle), as is shown in Figure 2.
It is true that "sharing is the root of all contention". The first implementation may introduce more context switching overhead, but the contention is never greater than 2. Although the second implementation has better performance with low concurrency, when concurrency is high, the contention may vary from 1 to n, and may prevent progress. For some performance sensitive requirements, a "compromise" of the two solutions is probably more optimal. With the support of my solution, users are free to choose algorithms for synchronizations based on platform or performance considerations.
Thanks to the Concepts TS, I was able to implement the entire solution in C++ gracefully, making it easier for users to debug their code implemented with my solution. I hope this solution is positive for improving the C++ programming language.
Considerations
Execution Structures
In concurrent programs, executions of tasks always depend on one another, thus the developers are required to control the synchronizations among the executions; these synchronization requirements can be divided into 3 basic categories: “one-to-one”, “one-to-many”, “many-to-one”. Besides, there are “many-to-many” synchronization requirements; since they are usually not “one-shot”, and often be implemented as a “many-to-one” stage and a “one-to-many” stage, they are not fundamental ones.
“Function” and “Invoke” are the basic concepts of programming, enabling users to wrap their logic into units and decoupling every parts from the entire program. Are these concepts able to be generalized in concurrent programming? The answer is YES, and that’s what my work revolves around.
When producing a “Function”, only the requirements (pre-condition), input, output, effects, synchronizations, exceptions, etc. for calling this function shall be considered; who or when to “Invoke” a “Function” is not to be concerned about. When it comes to concurrent programming, there shall be a beginning and an ending for each “Invoke”; in other words, a “Concurrent Invoke” shall begin from “one” and end up to “one”, which forms a “one-to-many-to-one” synchronization.

Figure 3
The most common concurrent model is starting several independent tasks and waiting for their completion. I define this model as "Sync Concurrent Invoke". A typical scenario for the "Sync Concurrent Invoke" model is shown in Figure 3.

Figure 4

Figure 5
Figure 4 is one slide from Herb Sutter's previous talk: "blocking is harmful", and "you can always turn blocking into non-blocking at a cost of occupying a thread". Nonetheless, is there a "more elegant" way to avoid blocking? Yes, there is, just let the execution agent that executes the last finished task in a "Sync Concurrent Invoke" to do the rest of the works (the concept "execution agent" is defined in C++ ISO standard 30.2.5.1: An execution agent is an entity such as a thread that may perform work in parallel with other execution agents). I define this model as "Async Concurrent Invoke". A typical scenario for the "Async Concurrent Invoke" model is shown in Figure 5.

Figure 6
The "Sync Concurrent Invoke" and the "Async Concurrent Invoke" models are the static execution structures for concurrent programming, but not enough for runtime extensions. For example, when implementing a concurrent quick-sort algorithm, it is hard to predict how many subtasks will be generated. So we need a more powerful execution structure that can expand a concurrent invocation, which means, to add other tasks executed concurrently with the current tasks in a same concurrent invocation at runtime. I define this model as "Concurrent Fork". A typical scenario for the "Concurrent Fork" model is shown in Figure 6.

Figure 7

Figure 8
With the concept of the "Sync Concurrent Invoke", the "Async Concurrent Invoke" and the "Concurrent Fork" models, we can easily build concurrent programs with complex dependencies among the executions, meanwhile, stay the concurrent logic clear. Figure 7 shows a typical scenario for a composition of the "Sync Concurrent Invoke" and the "Concurrent Fork" models; Figure 8 shows a more complicated scenario.
From the "Sync Concurrent Invoke", the "Async Concurrent Invoke" and the "Concurrent Fork" models, we can tell that:
- the same as serial invocations, the "Sync Concurrent Invoke" and the "Async Concurrent Invoke" models can be applied recursively, and
- by changing "Sync Concurrent Invoke" into "Async Concurrent Invoke", we can always turn blocking into non-blocking at a cost of managing the execution agents, because it's hard to predict which task is the last finished; users are responsible for the load balance in the entire program when applying the "Async Concurrent Invoke" model, and
- applying the "Concurrent Fork" model requires one concurrent invocation to expand, no matter the invocation is a "Sync" one or an "Async" one.
Synchronizations
One-to-one
The "one-to-one" synchronization requirements are much easier to implement than the other two. Providing there are two tasks named A and B, and B depends on the completion of A, we can simply make a serial implementation (sequentially execute A and B) with no extra context switching overhead. If task A and B are supposed to be executed on different execution agents (maybe because they attach to different priorities), extra overhead for the synchronization is inevitable, we may let another execution agent to execute B after A is completed. Usually we can implement such "one-to-one" synchronization requirements by starting a thread or submitting a task to a threadpool, etc.; besides, many patterns and frameworks provide us with more options, for example, the well-known "Future" pattern.

Figure 9
Currently in C++, the "Future" plays an important role in concurrent programming, which provides Ad-hoc synchronization from one thread to another, as is shown in Figure 9. It is apparent that "one-to-many" and "many-to-one" synchronization requirements can be converted into multiple "one-to-one" ones. Thus the "Future" can be used to deal with any synchronization situation with nice composability.
Besides, there are many primitives supported by various platforms, such as the "Futex" in modern Linux, the "Semaphore" defined in the POSIX standard and the "Event" in Windows. The "work-stealing" strategy is sometimes used for the "one-to-one" synchronization requirements, such as the Click programming language, the "Fork/Join Framework" in the Java programming language and the "TLP" in the .NET framework.
One-to-many
The "one-to-many" synchronization requirements are just as easy as the "one-to-one" ones most of the time. However, when a "one-to-many" synchronization requirement is broken down into too many "one-to-one" ones, it will introduce too much extra overhead.
One solution to this problem is to perform these "one-to-one" synchronization operations concurrently. Suppose we have 10000 tasks to launch asynchronously, we can divide the launching work into 2 phases,
- launch other 100 tasks,
- each task launched in the previous step launches 100 tasks respectively.
So that we can finish launching within 200 (instead of 10000) units of "one-to-one" synchronization time, and that’s the bottle neck for 2 phases. Similarly, if we divide the launching work into 4 phases, we can finish launching within 40 (instead of 200) units of "one-to-one" synchronization time.

Figure 10 - f(x) = x*n^(1/x), for n = 10000
Generally, if we divide a launching work of n tasks into x phases, the minimum unit of time required to finish it is a function of x, f(x) = x*n^(1/x), whose graph is similar with Figure 10. It is apparent that f(0+)->+∞ and f(+∞)->+∞. Let f'(x)=0 and we obtain x=ln(x), where f(x) is minimum. When x=ln(x), the ideal maximum number of tasks that each task may split into is n^(1/ln(n))=e, which is a constant number greater than 2 and less than 3. When the maximum number of tasks that each task may split into is x, the minimum unit of time required to finish the work is a function of n and x, g(n, x)=x*log(x,n), it is apparent that g(n,2)>g(n,3) holds when x is greater than 1, thus when a launching work of n tasks is divided into some phases, and adequate execution resources are provided, it is theoretically optimal to divide each work into 3 smaller ones.
Many-to-one

Figure 11
As mentioned earlier, the most common methods to implement the "many-to-one" synchronization requirements are to break it down into multiple "one-to-one" synchronizations, and to use an atomic integer maintaining with lock-free operations to let the first finished tasks synchronize with the last finished one. The advantages and disadvantages of the two methods complement each other, as is shown in Figure 11.
void solve_2(std::size_t n) { std::atomic_size_t task_count(n - 1u); std::promise<void> p; for (std::size_t i = 0; i < n; ++i) { std::thread([&] { do_something(); if (task_count.fetch_sub(1u, std::memory_order_release) == 0u) { std::atomic_thread_fence(std::memory_order_acquire); p.set_value(); } }).detach(); } p.get_future().wait();}Figure 12
void solve_2(std::size_t n) { std::atomic_size_t task_count(n - 1u); std::promise<void> p; for (std::size_t i = 0; i < n; ++i) { std::thread([&] { do_something(); if (task_count.fetch_sub(1u, std::memory_order_release) == 0u) { std::atomic_thread_fence(std::memory_order_acquire); p.set_value(); } }).detach(); } p.get_future().wait();}Figure 13
Note that the state of "0" for the atomic integers is never utilized, when using atomic integers to maintain the number of unfinished tasks. The number of unfinished tasks is able to map to range [0, n), so that the implementation shown in Figure 2 can be reconstructed, as is shown in Figure 12 and Figure 13.
Inspired from the class "LongAdder" in the Java programming language, I found it helpful to split one atomic integer into many "cells" to decrease contention and increase concurrency in operations on the integers. Unfortunately, although this method can reduce the complexity of writing, it increases the complexity of reading, e.g. if we are to check whether an integer becomes 0 and subtract 1 from it (this is exactly the requirement in the preceding paper), the operations that a "LongAdder" will likely perform are as follows:
- sum up the cells [1, 2, 3] and we get 6,
- check whether 6 equals to 0, and we get [FALSE],
- choose a cell at random [1, 2, 3],
- subtract 1 from the chosen cell [1, 1, 3], and the total complexity is O(number of cells).
Other algorithms and data structures such as the "combining tree" models and the "counting network" models also introduce diverse extra overhead while used to solve this challenge.
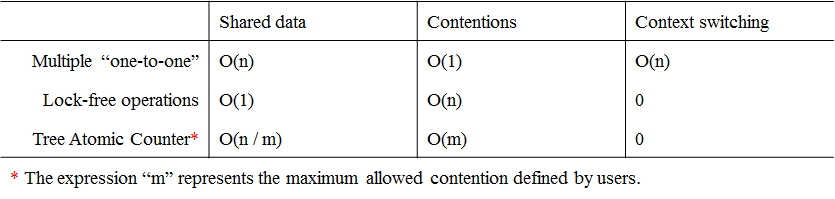
Figure 14
Then I learnt from the class "Phaser" in the Java programming language that instead of splitting an integer into independent "cells", it is better to "tiering them up to form a tree". Since the class "Phaser" has more functions than just "tiering", and it is not convenient to control contentions on each node, I improved the design based on "single responsibility principle" that enables users to set the upper limit of the contention as they expect. I define the new design as "Tree Atomic Counter", whose property is shown in Figure 14.
Similar with other widely used tree-shaped data structures, a "Tree Atomic Counter" is composed of several nodes. Each node holds an atomic integer and a reference to its parent. Each "Tree Atomic Counter" associates with a constant integer MAX_N, which represents the maximum count of its each node, in other words, the count of each node belongs to the interval [0, MAX_N]. This property guarantees that the contention on each node never exceeds (MAX_N + 1). When tiering one node to another, the count of the parent node is increased by 1.
The structure of the "Tree Atomic Counter" has the following properties:
- the count represented by a "Tree Atomic Counter" equals to the sum of the count held by all its nodes,
- the root node holds an invalid reference (e.g. a null pointer).
![]()
Figure 15
Unlike other widely used tree-shaped data structures such as the "Red-black Tree" or the "AVL Tree", the "Tree Atomic Counter" doesn’t require to be balanced. Moreover, the shape of a "Tree Atomic Counter" has no effects on its use or performance. For the initialization of a "Tree Atomic Counter", we can make it either balanced or completely unbalanced, as is shown in Figure 15, just like a forward list!

Figure 16

Figure 17
When increasing a count on a node, there are two strategies:
- directly add the count to the node if the total count on this node won’t exceed MAX_COUNT, as is shown in Figure 16, or
- attach a new tree on the node otherwise, as is shown in Figure 17.
If we are to check whether a "Tree Atomic Counter" becomes 0 and subtract 1 from it with a node, there are three strategies:
- decrease 1 from the node if the count of the node is not 0, or
- recursively perform this operation to the parent node if the parent node is valid and the count of the current node equals to 0, or
- do nothing otherwise.

Jens Maurer
Apr 21, 2017, 8:16:48 AM4/21/17
to std-pr...@isocpp.org
On 04/21/2017 12:35 PM, Mingxin Wang wrote:
> In the past two years, I have been trying to conclude the lack of support for various concurrent programming requirements among existing solutions. After 87 times of reconstruction, I have concluded the issue into two major problems and solved them.
This is the std-proposals mailing list.
> In the past two years, I have been trying to conclude the lack of support for various concurrent programming requirements among existing solutions. After 87 times of reconstruction, I have concluded the issue into two major problems and solved them.
I have skimmed your text, but I'm not seeing proposed additions
to the C++ standard in there. Did I miss them? If not, which
classes or functions do you propose to be added in a future
revision of C++?
Jens
Mingxin Wang
Apr 21, 2017, 8:32:20 AM4/21/17
to ISO C++ Standard - Future Proposals
Actually, I haven't submitted the draft for the solution yet because I followed the first instruction on the "How To Submit a Proposal" page. It says only an initial brief description is needed so far.
Do you mean that the draft is supposed to be submitted at this stage?

Tony V E
Apr 21, 2017, 9:58:06 AM4/21/17
to Standard Proposals
On Fri, Apr 21, 2017 at 8:32 AM, Mingxin Wang <wmx16...@163.com> wrote:
Actually, I haven't submitted the draft for the solution yet because I followed the first instruction on the "How To Submit a Proposal" page. It says only an initial brief description is needed so far.Do you mean that the draft is supposed to be submitted at this stage?
No, he means, of the things you talked about, what, exactly, do you want in the next standard?
Do you want a function called std::solve_2()?
Do you want an "atomic tree counter"? What would that class look like? (And have you looked at Lawrence Crawl's distributed counter papers?)
Can you show me C++17 code that I would need to write today, and then show me how much better that code would look in C++20 if it had your new features in C++20. Specifically - show me what _my_ code might look like, if it used your new features. I don't need to see or know how your new features were implemented, just the interfaces to those features. Mostly, I need to see code that uses the features.
Jens Maurer
Apr 21, 2017, 10:13:45 AM4/21/17
to std-pr...@isocpp.org
On 04/21/2017 02:32 PM, Mingxin Wang wrote:
> Actually, I haven't submitted the draft for the solution yet because I followed the first instruction on the "How To Submit a Proposal <https://isocpp.org/std/submit-a-proposal>" page. It says only an initial brief description is needed so far.
You have given a long description (which I didn't read in detail),
but I'm missing specific (and preferably short) code examples showing
how to solve some specific problem with your proposed extension.
Showing the contrast of how you would solve the same problem without
using your extension often helps convincing, too.
Thanks,
Jens
> Actually, I haven't submitted the draft for the solution yet because I followed the first instruction on the "How To Submit a Proposal <https://isocpp.org/std/submit-a-proposal>" page. It says only an initial brief description is needed so far.
>
> Do you mean that the draft is supposed to be submitted at this stage?
I'm not defining the rules, so I can't comment on "supposed".
> Do you mean that the draft is supposed to be submitted at this stage?
You have given a long description (which I didn't read in detail),
but I'm missing specific (and preferably short) code examples showing
how to solve some specific problem with your proposed extension.
Showing the contrast of how you would solve the same problem without
using your extension often helps convincing, too.
Thanks,
Jens

dgutson .
Apr 21, 2017, 10:21:21 AM4/21/17
to std-proposals
Mingxin, I will echo Jens and Tony. It is evident that you spent a lot of effort to write the email in a level of detail and beauty few times seen in this list. The issue is, as Jens and Tony mention, that the following items are not obvious or missing:
- Problem statement
- Why it is a problem
- How people is dealing with those problems nowadays (workaround?)
- What your solution is (as Tony suggests, a "before and after" your proposed changes in terms of code, and if possible too, in terms of the standard)
Please be as concise and brief as possible. I don't want you to be discouraged of pursuing your idea, specially considering all the effort you spent, so please focus on these observations so people can quickly spot what are you talking about.
This should take no more than few lines.
Daniel.
Thanks,
Jens
--
You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
To unsubscribe from this group and stop receiving emails from it, send an email to std-proposals+unsubscribe@isocpp.org.
To post to this group, send email to std-pr...@isocpp.org.
To view this discussion on the web visit https://groups.google.com/a/isocpp.org/d/msgid/std-proposals/58FA1395.7010107%40gmx.net.
--
Who’s got the sweetest disposition?
One guess, that’s who?
Who’d never, ever start an argument?
Who never shows a bit of temperament?
Who's never wrong but always right?
Who'd never dream of starting a fight?
Who get stuck with all the bad luck?
One guess, that’s who?
Who’d never, ever start an argument?
Who never shows a bit of temperament?
Who's never wrong but always right?
Who'd never dream of starting a fight?
Who get stuck with all the bad luck?
Mingxin Wang
Apr 21, 2017, 10:45:35 AM4/21/17
to ISO C++ Standard - Future Proposals
I suppose I have stated the issues at the beginning of my post. The two problems are about the architecture and the synchronization algorithms respectively. This proposal is designed to solve both problems.
Currently, some advanced solutions focus only on those "one-to-one" synchronization requirements, such as the "Future" and the "Coroutine". Although they have nice composability, they are usually not efficient enough for those "many-to-one" synchronization requirements. And some other solutions concentrate mainly on those "many-to-one" synchronization requirements, such as the "Barrier" and the "Latch". They are usually efficient but have less composability. Besides, it is not easy to control the contention.
On Friday, April 21, 2017 at 10:21:21 PM UTC+8, dgutson wrote:
On Fri, Apr 21, 2017 at 11:13 AM, Jens Maurer <Jens....@gmx.net> wrote:On 04/21/2017 02:32 PM, Mingxin Wang wrote:
> Actually, I haven't submitted the draft for the solution yet because I followed the first instruction on the "How To Submit a Proposal <https://isocpp.org/std/submit-a-proposal>" page. It says only an initial brief description is needed so far.
>
> Do you mean that the draft is supposed to be submitted at this stage?
I'm not defining the rules, so I can't comment on "supposed".
You have given a long description (which I didn't read in detail),
but I'm missing specific (and preferably short) code examples showing
how to solve some specific problem with your proposed extension.
Showing the contrast of how you would solve the same problem without
using your extension often helps convincing, too.
Mingxin, I will echo Jens and Tony. It is evident that you spent a lot of effort to write the email in a level of detail and beauty few times seen in this list. The issue is, as Jens and Tony mention, that the following items are not obvious or missing:
- Problem statement
- Why it is a problem
- How people is dealing with those problems nowadays (workaround?)
- What your solution is (as Tony suggests, a "before and after" your proposed changes in terms of code, and if possible too, in terms of the standard)
Please be as concise and brief as possible. I don't want you to be discouraged of pursuing your idea, specially considering all the effort you spent, so please focus on these observations so people can quickly spot what are you talking about.
This should take no more than few lines.
Daniel.
Thanks,
Jens
--
You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
To unsubscribe from this group and stop receiving emails from it, send an email to std-proposal...@isocpp.org.
To post to this group, send email to std-pr...@isocpp.org.
To view this discussion on the web visit https://groups.google.com/a/isocpp.org/d/msgid/std-proposals/58FA1395.7010107%40gmx.net.
Jens Maurer
Apr 21, 2017, 2:59:05 PM4/21/17
to std-pr...@isocpp.org
On 04/21/2017 04:22 PM, Mingxin Wang wrote:
> Thanks for your explanation! I was not familiar with the course. The solution (together with the implementation and 5 examples) is as attached.
I'm seeing a large-ish PDF with the following
> Thanks for your explanation! I was not familiar with the course. The solution (together with the implementation and 5 examples) is as attached.
- BinarySemaphore (only a concept; not a specific class, it seems)
As-is, this doesn't require that implementations of C++ standard libraries
actually provide a class (under which name?) that satisfies the concept.
While having the concept might be worthwhile, having a specific class
that actually is a binary semaphore also seems worthwhile.
- Atomic Counters
Again, this is just a concept, not actual classes people could use.
Are they supposed to be useful by themselves?
If so, why do we need three layers of abstraction here?
What's the difference / advantage over just using a std::atomic<unsigned long>
as a counter? Is there a useful self-contained abstraction
hidden somewhere here, e.g. a counting semaphore?
- ExecutionAgentPortal
I would much prefer to simply take a zero-argument "f"
(which might be a lambda) than to have a variadic "args..." interface.
The corresponding interface for std::thread was a design mistake.
Is there any advantage for the variadic interface, other than
proliferating more template arguments?
(lots more)
I'm still not seeing helpful examples here, or in the src.zip,
that I could connect to a real-world problem to be solved.
There is an Executors proposal currently under discussion
in SG1
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/p0443r1.html
that also tries to abstract the idea of an execution agent.
Can you solve your problems with that framework? If not, what is
missing?
Jens
Mingxin Wang
Apr 21, 2017, 9:25:28 PM4/21/17
to ISO C++ Standard - Future Proposals
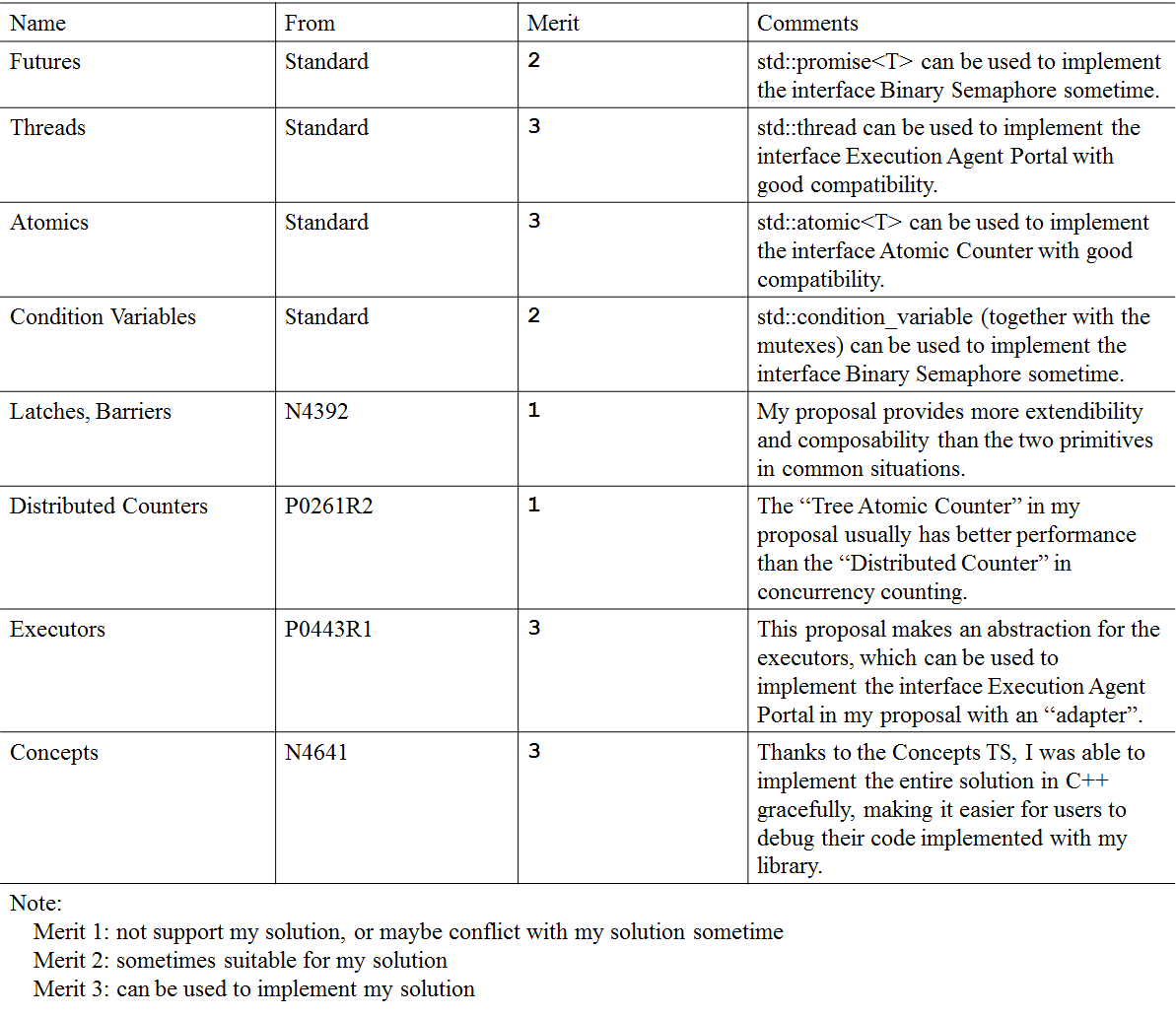
The Binary Semaphores and the Atomic Counters, ect., are required in the core function templates (see the second clause in "solution.pdf"). Some implementation for the requirements are provided in src/solution with .h files, which are not completely documented (see Figure 11 in "solution.pdf"). As is mentioned in the "Intention" parts in the first clause, these implementations may have various mechanisms, including some primitives out of the C++ standard (for example, the "Futex"). These implementations are only recomended, but not all of them are available on every platform.
Examples are prepared to demonstrate basic usage for the library, and the last example named "example_5_application_concurrent_copy.cc" shows an application for concurrent copy algorithm. In order to make the examples easy to understand, more complex applications are not provided, but that not means those applications are not implementable with my solution. For example, concurrent sort algorithms are much easier to implement with "sync_concurrent_invoke" and "concurrent_fork" function templates.
I defined the "Execution Agent Portal" term because I found it helpful to implement concurrent callable units. The "Execution Agent Portal" is more abstract than the "Executor" proposed in this paper ("A Unified Executors Proposal for C++"). "Execution Agent Portal" defined a method to submit an execution task, no matter the task is executed sequentially (with the current thread) or concurrently (with a new thread, a threadpool, ect.), which means any "Executor" is convertible to an "Execution Agent Portal" with a simple "Adapter" like this:
template <class Executor>class ExecutorPortal { public: ExecutorPortal(Executor& executor) : executor_(executor) {}
template <class F, class... Args> void operator()(F&& f, Args&&... args) { executor_.execute(std::forward<F>(f), std::forward<Args>(args)...); // Or maybe post or defer }
private: Executor& executor_;};Mingxin Wang
Apr 21, 2017, 10:27:23 PM4/21/17
to ISO C++ Standard - Future Proposals
I haven't read Lawrence Crawl's distributed counter papers yet, could you please provide a full reference or a link? Thank you.
On Friday, April 21, 2017 at 9:58:06 PM UTC+8, Tony V E wrote:
Tony V E
Apr 21, 2017, 11:26:02 PM4/21/17
to ISO C++ Standard - Future Proposals
Google "Lawrence crawl distributed counter c++"
Sent from my BlackBerry portable Babbage Device
| From: Mingxin Wang Sent: Friday, April 21, 2017 10:27 PM To: ISO C++ Standard - Future Proposals Reply To: std-pr...@isocpp.org Subject: Re: [std-proposals] A Proposal for C++ Concurrency |
--
You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
To unsubscribe from this group and stop receiving emails from it, send an email to std-proposal...@isocpp.org.
To post to this group, send email to std-pr...@isocpp.org.
You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
To unsubscribe from this group and stop receiving emails from it, send an email to std-proposal...@isocpp.org.
To post to this group, send email to std-pr...@isocpp.org.
To view this discussion on the web visit https://groups.google.com/a/isocpp.org/d/msgid/std-proposals/c41c5f33-b923-4ba1-82dc-64f344672170%40isocpp.org.
Mingxin Wang
Apr 22, 2017, 2:19:22 AM4/22/17
to ISO C++ Standard - Future Proposals
Dear Tony,
The paper provided (http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0261r1.html) proposes a design for the distributed counter, which reduces contention in writing but "increases costs to read the counter". The mechanism of the distributed counter is similar with the class "LongAdder" in the Java programming language mentioned earlier in my post (Considerations, many-to-one). Both "LongAdder" and the distributed counter split one atomic integer into many independent units.
As the accurate value of the counter is not required at runtime in my solution, the "Tree Atomic Counter" is more optimal because not only does it reduce the contention, but also remains the complexity of reading always to be O(1), as is shown below.


Vicente J. Botet Escriba
Apr 22, 2017, 10:02:40 AM4/22/17
to std-pr...@isocpp.org
Hi,
I'm not sure you has been following the C++ Concurrency Wroking Group proposals.
I would sugets you to take a look at the Concurrency TS, Parrallel TS1/TS2, Couroutine TS and the papers associated to this working group (if you have not already done it). Look for Concurrency.
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2015/
...
There you will find the current trend. There are a lot of things on going: more on memory model, more on atomics, Continuations, Executors, task blocks, more Parallel Algorithms, Concurrent data structures, TLS, Latches, Barriers, Distributed Counters, Concurrent queues, RCU, Heterogeneous devices, Vectorization, SIMD, Fibers, Light-Weight Execution Agents ...
If you don't find there what you are looking for then I will suggest you to post here a concrete use case and why the current way has problems. I'm not saying that there is nothing missing, sometime we don't know everithing it is going on.
Then, if you believe you have a better solution, as suggested by others, describe how we can solve it with C++17 + the current TS + the proposals and how it could be solved with your prefered solution.
I'll suggest also to follow the schema: Motivation, Problem, proposal with Before/After examples.
Vicente
I'm not sure you has been following the C++ Concurrency Wroking Group proposals.
I would sugets you to take a look at the Concurrency TS, Parrallel TS1/TS2, Couroutine TS and the papers associated to this working group (if you have not already done it). Look for Concurrency.
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2015/
...
There you will find the current trend. There are a lot of things on going: more on memory model, more on atomics, Continuations, Executors, task blocks, more Parallel Algorithms, Concurrent data structures, TLS, Latches, Barriers, Distributed Counters, Concurrent queues, RCU, Heterogeneous devices, Vectorization, SIMD, Fibers, Light-Weight Execution Agents ...
If you don't find there what you are looking for then I will suggest you to post here a concrete use case and why the current way has problems. I'm not saying that there is nothing missing, sometime we don't know everithing it is going on.
Then, if you believe you have a better solution, as suggested by others, describe how we can solve it with C++17 + the current TS + the proposals and how it could be solved with your prefered solution.
I'll suggest also to follow the schema: Motivation, Problem, proposal with Before/After examples.
Vicente
Le 21/04/2017 à 16:45, Mingxin Wang a écrit :
Mingxin Wang
Apr 24, 2017, 3:27:46 AM4/24/17
to ISO C++ Standard - Future Proposals
Motivation
Executions, one-to-one synchronizations, many-to-one synchronizations and one-to-many synchronizations are the basic concurrent programming requirements (see my initial post, Considerations part). What we have for the requirements in C++ is shown below.

My solution is particularly for the missing parts, as
is shown below (items in red represent main content of my solution).

The related proposals are shown below.
Problems
(See my initial post, Problems part)
Proposal
(See solution.pdf attached with my earlier post)
Implementation
(See src.zip/solution attached with my earlier post)

Examples
(See src.zip/examples attached with my earlier post)

For the first example, I have 3 similar implementations without my solution (see my initial post), which have limited extendibility as discussed before, e.g., it is difficult for these implementations to control runtime contention, but easy for implementations with support of my solution using the explicit version for the “Concurrent Invoke” models and the “Tree Atomic Counter”, as is shown below:
void solve(std::size_t n) { std::atomic_size_t task_count(n); std::promise<void> p; for (std::size_t i = 0; i < n; ++i) { std::thread([&] { do_something(); if (task_count.fetch_sub(1u, std::memory_order_release) == 1u) { std::atomic_thread_fence(std::memory_order_acquire); p.set_value(); } }).detach(); } p.get_future().wait();}Implementation before (1)
void solve(std::size_t n) { std::atomic_size_t task_count(n - 1u); std::promise<void> p; for (std::size_t i = 0; i < n; ++i) { std::thread([&] { do_something(); if (task_count.fetch_sub(1u, std::memory_order_release) == 0u) { std::atomic_thread_fence(std::memory_order_acquire); p.set_value(); } }).detach(); } p.get_future().wait();}Implementation before (2)
void solve(std::size_t n) { std::atomic_size_t task_count(n - 1u); std::promise<void> p; for (std::size_t i = 0; i < n; ++i) { std::thread([&] { do_something(); std::atomic_thread_fence(std::memory_order_release); std::size_t cur = task_count.load(std::memory_order_relaxed); do { if (cur == 0u) { std::atomic_thread_fence(std::memory_order_acquire); p.set_value(); break; } } while (!task_count.compare_exchange_weak(cur, cur - 1u, std::memory_order_relaxed)); }).detach(); } p.get_future().wait();}Implementation before (3)
void solve(std::size_t n) { con::sync_concurrent_invoke( [] {}, con::make_concurrent_caller( n, con::make_concurrent_callable( con::ThreadPortal<true>(), con::make_concurrent_procedure(do_something))));}Implementation after (1)
void solve(std::size_t n) { con::sync_concurrent_invoke_explicit( con::TreeAtomicCounter<10u>::Initializer(), con::DisposableBinarySemaphore(), [] {}, con::make_concurrent_caller( n, con::make_concurrent_callable( con::ThreadPortal<true>(), con::make_concurrent_procedure(do_something))));}Implementation after (2)
It is more difficult to implement the other 4 examples above with full considerations in architecture and performance (see my initial post, Considerations part) without my solution.

Oliver Kowalke
Apr 24, 2017, 4:12:13 AM4/24/17
to std-pr...@isocpp.org
What is the difference between utility and structural supports?
I would consider continuations as building blocks for fibers and coroutines. A continuation acts as a ToE like threads.
Continuation (coroutine and fiber) can be used for n-m synchronization too - it is not limited to 1-1 synchronization.I would consider continuations as building blocks for fibers and coroutines. A continuation acts as a ToE like threads.
Mingxin Wang
Apr 24, 2017, 5:41:10 AM4/24/17
to ISO C++ Standard - Future Proposals
Here I mean,
- Utilities: the code we actually have (classes, functions...), and
- Interfaces: the code required for structuring (semantics, requirements, concepts...), and
- Structural supports: how to build a program (methods, patterns, language features...)
For example, for the basic function calls:
- The utilities are the functions in the standard library, and
- The interface is "function" itself, users are required to write code with parameters and return values (and maybe exceptions, etc.), and
- The structural support is "invocation", and users are able to "invoke" functions with specific syntax.
Continuations do be able to be used for n-m synchronization, and so do any other solutions listed in the table. Because as mentioned in my initial post, "'one-to-many' and 'many-to-one' synchronization requirements can be converted into multiple 'one-to-one' ones". Although they can be used to implement the synchronizations and have nice composability, they are usually not optimal in terms of performance. For example, the "Latches" usually have better performance than the "Futures" in many-to-one synchronizations, as is shown below.
void solve(std::size_t n) { std::vector<std::future<void>> v; for (std::size_t i = 0; i < n; ++i) { v.emplace_back(std::async(do_something)); } for (auto& f : v) { f.wait(); }}Solve with the "Futures"
void solve(std::size_t n) { std::experimental::latch lat(n); for (std::size_t i = 0; i < n; ++i) { std::thread([&] { do_something(); lat.count_down(); }).detach(); } lat.wait();}Solve with the "Latches"
Oliver Kowalke
Apr 24, 2017, 7:16:04 AM4/24/17
to std-pr...@isocpp.org
2017-04-24 11:41 GMT+02:00 Mingxin Wang <wmx16...@163.com>:
Although they can be used to implement the synchronizations and have nice composability, they are usually not optimal in terms of performance. For example, the "Latches" usually have better performance than the "Futures" in many-to-one synchronizations, as is shown below.
Solve with the "Latches
I don't see why equivalent code shouldn't be possible with continuations (fibers).
Mingxin Wang
Apr 24, 2017, 12:06:19 PM4/24/17
to ISO C++ Standard - Future Proposals
Thank you for pointing out the problem about the charts!
I am really sorry that the charts in the "Motivation" part were not reasonable in the following aspects:
- The "Continuations" has nothing to do with synchronization, it is a basic, low-level primitive, and
- The "Fibers" is defined as user-mode-scheduled-thread, which has similar features with threads, thus it shall belong to the same category as the "Threads" does, and
- The "Coroutines" is based on the concept of "Functions", which introduces requirements for concurrent programming, thus it is an interface (but it is not related to my solution), and
- All of the "Execution" requirements are "One-to-one synchronization" requirements, and the two rows in the chart shall be merged.
The updated charts are as follows:

Before

After

Related Proposals
Mingxin Wang
Apr 28, 2017, 5:32:08 AM4/28/17
to ISO C++ Standard - Future Proposals
Hello everyone,
Thanks to your suggestions, this proposal is available now.
I hope it is positive for improving the C++ programming language with your instructions!
Sincerely,
Mingxin Wang
Reply all
Reply to author
Forward
0 new messages