"←" or Unicode Arrow 0x2190 to mean the same as "<-"

Anh Hai Trinh
"<-". Makes for beautiful looking code.
--
// aht
http://blog.onideas.ws

MC.Spring
On Feb 3, 11:20 pm, Anh Hai Trinh <anh.hai.tr...@gmail.com> wrote:
> It should be possible to have the operator "←" meaning the same as
> "<-". Makes for beautiful looking code.
I wander how do you type this "←"? I could not find or type this from
my keyboard~
Anh Hai Trinh
> I wander how do you type this "←"? I could not find or type this from
> my keyboard~
>
It is a matter of editors. In acme or sam, this is simply Alt + "<" + "-".
Alternatively, we can make gofmt transform "<-" into "←".

roger peppe
grep for "<-" rather than "<-|←"

ccahoon
> if i'm looking for channel operations in some code, i'd prefer to
> grep for "<-" rather than "<-|←"
If, as aht suggested, gofmt transforms '<-' into "←", would that be
much of an issue? I would still prefer to grep for "<-" in any case,
since for those who aren't using acme or sam, it's more involved to
produce "←".
>
> On 3 February 2010 15:50, Anh Hai Trinh <anh.hai.tr...@gmail.com> wrote:

Philip
editing yourself. Personally, I would stick with ascii chars in the
development tools.

Evan Shaw
- Evan

Brian Stuart
if i'm looking for channel operations in some code, i'd prefer to
grep for "<-" rather than "<-|←"

Peter Bourgon
tens or fifteens.

Thaddée Tyl
only need to type CTRL+K and "<-". Let alone the gofmt suggestion.
I think this is a great idea, and I have to admit Brian Stuart's code
looks marvelous. It would truly modernize code a lot.
On Feb 3, 9:22 pm, Peter Bourgon <peterbour...@gmail.com> wrote:
> I think the number of people using acme or sam must number into the
> tens or fifteens.
>
>
>
> On Wed, Feb 3, 2010 at 10:00 PM, Brian Stuart <blstu...@gmail.com> wrote:

Steven
- It means you need to be using a document editor that supports this stuff. I often test code snippets on the go on my phone. This would make it impossible.
- How far would you go? Not going all the way would be inconsistent, and "worse" than leaving it as a separate system from math. And going all the way would pretty much defeat the purpose of an imperative language.
- There are cases where the mathematical meaning of a symbol and the programming one are irreconcilably different, such as, in math, = is a comparative (frequently asserted to be true, but not always), whereas ≡ is definition (this is opposite to how Brian shows it). This can't be reconciled, because in normal formating, = is not a comparative in Go, nor is it in most main stream imperative programming languages. The formatted symbols are pretty, but they're not really any easier to read, and definitely harder to type (even if you have simple replacements, like != for ≠, you type one thing and see another, which creates a discord)

Nigel Tao
> It should be possible to have the operator "←" meaning the same as
> "<-". Makes for beautiful looking code.
I wouldn't want more than one way to type the <- operator, in go
source code. But if you want beautiful looking code, you could push
the go source code through a pretty-printer and view the pretty
output.
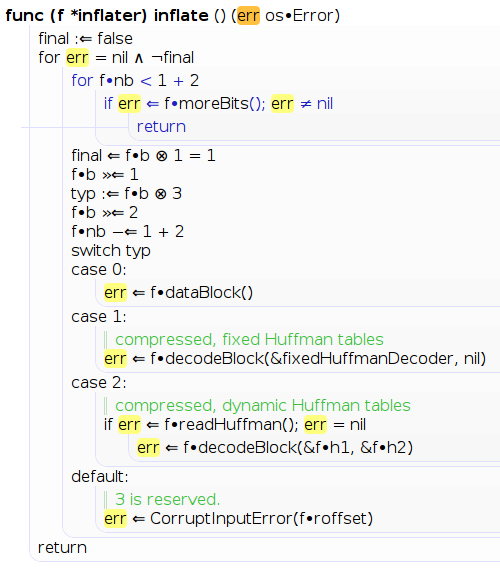
I've dredged up a screenshot of an old experiment with pretty-printing
to HTML+CSS. There's many things going on at once. For example, the
mathematician in me wanting = to mean comparison and not assignment,
symbols like ∧ for &&, a fat centered dot, proportional-width fonts,
{} replaced by CSS indentation and borders (with
break/continue/returns marked), mouse-over a variable (e.g. "err")
highlighting other references...
This was an experiment, and at the end of the day, it really wasn't
better (and instead many ways worse) than just cat
$GOROOT/src/pkg/compress/flate/inflate.go. So I haven't played with it
since. But if anyone else wants to experiment, feel free to use
anything you see here.

Ryanne Dolan
Pretty neat. FORTRESS supposedly does something like that. I think it makes sense to use a pretty printer like this especially when publishing algorithms in academic papers, wikipedia etc. Better than Algol at least, and better in many cases than pseudocode (which very often ends up ambiguous).
It would probably be just as easy to manually write LaTeX or something in these cases, but it would be neat if Go had an official pretty printer to compliment gofmt.
If we had a pretty printer, we'd also want the compiler to recognize the pretty input or at least an un-prettifier so that published code could be useful after a cut-and-paste.
Could be one of those gimmicks that further popularizes Go, even if it isn't very useful.
- from my phone -
On Feb 3, 2010 10:15 PM, "Nigel Tao" <nigel.t...@gmail.com> wrote:
On 4 February 2010 02:20, Anh Hai Trinh <anh.ha...@gmail.com> wrote:
> It should be possible to ...

Russ Cox
> these cases, but it would be neat if Go had an official pretty printer to
> compliment gofmt.
I think a pretty printer would be just the opposite, an insult to gofmt.
Russ

Alexis Shaw
From: Alexis Shaw <alexi...@gmail.com>
Date: Thu, Feb 4, 2010 at 19:15
Subject: Re: [go-nuts] "←" or Unicode Arrow 0x2190 to mean the same as "<-"
To: r...@golang.org
I was just trying to get what has been said in one place.
On Wed, Feb 3, 2010 at 23:39, Alexis Shaw <alexi...@gmail.com> wrote:
> why not
≫⇐ looks awful compared to >>=
i can never remember which is which for ∧ and ∨
= and := look similar intentionally; ⇐ and ≡ do not
√ does not begin with an upper case letter
but most fundamentally, embellishments distract
from the program. you're supposed to be concentrating
on how elegant the code is, not how ornately formatted it is.
russ
Ryanne Dolan
I think a pretty printer would be just the opposite, an insult to gofmt.
Anh Hai Trinh
Go always parses <- as a single operator. That and the fact that -- is
a statement makes the Go version of the infamous "goes to operator"
not quite as innocent:
package main
import "fmt"
func main() {
c := 0
i := 100
for c < - - i {
// some complicated computation
i--
}
fmt.Println(i)
Brian Stuart
It means you need to be using a document editor that supports this stuff. I often test code snippets on the go on my phone. This would make it impossible.
- How far would you go?
Brian Stuart
but most fundamentally, embellishments distract
from the program. you're supposed to be concentrating
on how elegant the code is, not how ornately formatted it is.

Ian Lance Taylor
>> i can never remember which is which for ∧ and ∨
Not sure who wrote that, but there is a quick tip for English
speakers: the one that looks like 'A' is for 'and' (the other one is
for 'or').
(For the similar set operators ∪ and ∩ the one that looks like a 'U'
is for 'union' and the other one is for 'intersection'. And in fact
you can use this to figure out ∧ and ∨ as well, as they are
analogous.)
Ian
Steven
for lack of availability, at this point it's not just tradition that's
preventing Unicode for fundamental parts of a language. Keyboards are
simply made to input ASCII, and that's probably not going to change
soon since it works for most purposes in English, and with little
extension in most western languages.
Also, it actually my be better to keep programming operators as only
crude approximations to mathematical ones, to avoid confusion where
they aren't entirely congruent. And then there are the fundamental
discordancies such as how = is a comparative in math, while ≡ is
definition (along with ≔; look familiar?) The = problem is pretty much
irreconcilable at this point, leading to cludges like ≡ for ==, which
really seems out of place.

Jason Catena
> editing it, I can always set up my environment to transliterate the
> operators on the way in to the editor and the reverse it on the way back
> out.
Personally, I'd maintain and edit the unicode version. For (only)
your own code, you could store and edit *.ℊℴ files (script g and o in
unicode block 2100), and use this mk rule to transform them for the
compiler.
*.go: *.ℊℴ
sed -f deunicop.sed $stem.ℊℴ > $stem.go
where deunicop.sed transforms like this.
s/≠/!=/g
You'll always (every time you compile, at least) have a clean *.go
file, whenever you want to share it with people without your filter.
If you want to be really fancy about it you could write a lex program
to switch states in strings or comments, to preserve non-ascii
operators. Go only accepts letter-type code points in identifiers, so
you don't have to worry about splitting one with an operator.
> BLS
Jason Catena
Jason Catena
%.go: %.ℊℴ
sed -f deunicop.sed $stem.ℊℴ | gofmt > $stem.go

Bob Cunningham
That line takes me back 30 years!
Please excuse my possibly irrelevant recollections, but this situation
brings to mind my early days of programming C under 4BSD UNIX on a
screaming 5 MHz / 1 MIPS VAX 11/780 accessed via a 300 baud modem using
a dumb terminal (glass TTY) with an extremely limited keyboard (letters,
numbers, some punctuation, and little else).
That's right: We had to use C trigraphs for characters missing from the
keyboard. Since cc itself didn't understand trigraphs, they were
converted on the fly by cpp. Fortunately, the dumb terminals we used
could display characters that could not be entered on the keyboard, so
there was no problem editing code that did not use trigraphs.
Trigraphs worked fine for our own code, but nobody wanted to read code
containing trigraphs, so we wanted to save our code without trigraphs
before sharing it. As I recall, we initially used sed (as quoted above)
to convert the trigraphs, until a flag was added to cpp to do this (to
convert trigraphs only).
You'll notice this situation from 30 years ago is amazingly similar to
the current discussion: Entering and working with displayable
characters we can't easily type. The primary difference is that many of
the symbols mentioned in this thread will likely never be present as
individual keys on a keyboard.
I believe the solutions from then apply today:
1. Go should accept appropriate Unicode symbols as language operators.
2. Gofmt should be able to convert both ways between the symbols and
the current two-character forms.
3. Let Go users find and use their own favorite ways to enter the symbols.
For now, the "default" gofmt textual output of language operators should
be ASCII, though the HTTP output could default to the symbolic view (to
help get us used to it).
Eventually, much as is already the case with many languages with
pictographs and diacritical marks, I suspect we'll all become used to
using multiple keystrokes to enter some characters. This is already
becoming necessary in English, as the use of an umlaut is becoming more
common to denote that two adjacent vowels are to be pronounced separately.
Go should not be limited by input device shortcomings, though it should
not require external software (such as sed) to deal with such
limitations. The current two-character symbols should be preserved as
valid input, but eventually deprecated as valid gofmt output (and, at
some point, as Go compiler input).
-BobC
Jason Catena
This initial list transforms from characters not currently recognized
by Go to ones which are. That is to say, I didn't change any of the
current characters, just introduced new ways of saying existing ones.
I like ≝ (equal to by definition) a little better than ≔ for :=.
s,¬,!,g
s,…,...,g
s,←,<-,g
s,⇐,=,g
s,−,-,g
s,∧,\&,g
s,∨,|,g
s,≔,:=,g
s,≝,:=,g
s,≠,!=,g
s,≡,==,g
s,≤,<=,g
s,≥,>=,g
s,⋀,\&\&,g
s,⋁,||,g
Steven

Merlyn Rees
Thaddée Tyl
of reading a single operator is strongly discouraged. What I would
love is to have the ← operator instead of <-, but the Go Authors would
never do such a mistake... firstly, too many people are using Golang
now... secondly, I couldn't even type that in directly from the
keyboard while writing this message. It's unfair for japanese people,
since they never directly type keyboard characters when writing in
their language, so they are already used to having special key
combinations for unicode characters, but it's too late.
> On 6 February 2010 07:43, Steven <steven...@gmail.com> wrote:
> > good environment would highlight this as a keyword (mine does). *≔* is
Jason Catena
the sed script. I collected many of the suggestions here, and mapped
≡ to := instead of ==. ≟ for == is an excellent idea, thank you
Steven and Merlyn. == may be a convention, but it's too easy to omit
one of the =, is non-obvious for beginners, and ≟ expresses the idea
much better. I have multiple mappings for :=, |, and &, since I'm not
going to unilaterally decide which looks best without trying them out
for a while. As much as I like ≝, it uses a combination of letters
specific in meaning to only a few natural languages, so I included all
the other mappings to :=. We should probably just use ≔ here, since
none of the others have a really clear advantage, ≔ doesn't miss the
point in any way I can think of, and ≔ is already in the language. ⊻
is much better for exclusive-or than ^, since ^ looks like the and
symbols.
http://dl.dropbox.com/u/502901/keyboard is a plan 9 /lib/keyboard file
which defines shortcuts for each of the operators, and lists each
operator's unicode value and name.
Some example code with the dressed-up operators.
http://dl.dropbox.com/u/502901/bool.%E2%84%8A%E2%84%B4
http://dl.dropbox.com/u/502901/chan.%E2%84%8A%E2%84%B4
http://dl.dropbox.com/u/502901/isvowel.%E2%84%8A%E2%84%B4
Jason Catena
ascii ones we discussed, the sed script would look like this.
s,¬,!,g
s,…,...,g
s,←,<-,g
s,⇐,=,g
s,−,-,g
s,∧,\&,g
s,∨,|,g
s,≔,:=,g
s,≟,==,g
s,≠,!=,g
s,≤,<=,g
s,≥,>=,g
s,⊻,^,g
s,⋀,\&\&,g
s,⋁,||,g
> Might I also suggest ⋎ ⋏ instead of ∧∨ for & | to avoid ambiguity with 'v'.
I'm not sure what to think about the curly logical or/and. This only
seem to be a problem in sans-serif fonts: In the proportional font in
which I write programs (plan 9's times latin) the letter v with serifs
is more distinct. I see how the curls are visibly different from the
letter v and the operator ⋁, but they're inconsistent with the
straight edges on ⊻. Here's an example of most of them together:
curly and straight bit operations, boolean operations, the exclusive-
or, and the letters v and V. This is deliberately hard to read, since
the point is to see which forms make the most difference while still
making sense.
package main
import "fmt"
func main() {
var v byte ⇐ 0xaa
var V byte ⇐ 0x55
var A byte ⇐ 0xff
fmt.Println(((v ⊻ V) ∧ (v ⊻ V) ≟ A) ⋀ ((v ⊻ V) ⋎ (v ⊻ V) ≟ A))
fmt.Println((v ∨ V ≟ A) ⋁ (v ⋏ V ≟ A))
}
I'm starting to like ≟ enough to propose ?= or =? as a replacement for
==. == is making less and less sense to me at all, beyond an
arbitrary and bad convention. As I mentioned, it is error-prone (it's
easy to leave out one = and fail quietly), non-obvious (there's
nothing about the symbols == that says if or test or question), and
one of ?= or =? expresses the idea test/maybe/if equals/same much
better. Does either form clash with something else in the language?
Ryanne Dolan
== does not fail quietly in go; a = b is not an expression. I agree that == might not make sense tho. I'd propose to accept both = and == for tests:
if a = b {...
Same as:
if a == b {
or maybe even do away with ==, since it is unnecessary in go.
- from my phone -
On Feb 6, 2010 3:36 PM, "Jason Catena" <jason....@gmail.com> wrote:
If I had to pick one alternative unicode operator for each of the
ascii ones we discussed, the sed script would look like this.
s,¬,!,g
s,…,...,g
s,←,<-,g
s,⇐,=,g
s,−,-,g
s,∧,\&,g
s,∨,|,g
s,≔,:=,g
s,≟,==,g
s,≠,!=,g
s,≤,<=,g
s,≥...
Alexis Shaw
&& , ⋏ , ∧ note conflict with &, this is a letter A
Jason Catena
> this as it is suggestive of multiple OR instructions in parallel)
> & , ⋏ , ∧ , ⩕ , ⩓ note conflict with &&, (I prefer this as it is
> suggestive of multiple AND instructions in parallel)
These comments are amusing because the operators have it backward. &&
and || only compare 1 bit, whereas & and | compare many. By this
logic, however, the sed script has it backwards too, and should have
thin little symbols for boolean and the big ones for bitwise. The
exclusive-or operator is thin, however, so the sed script has it the
way it currently is for a consistent thickness across the bitwise
operators. (Design is always a matter of choosing your principles.:)
> I also believe that √ should be added as a unitary operator, This is for the
> reason that it is defined as an essential operator in the IEEE-754
This would be nice and readable, as would many other operators which
are currently named functions. As has been mentioned, Fortress goes
this route, and has two very distinct representations for its source
code, which I think is overkill. I'd draw the line at what is
representable via Unicode, specifically UTF-8, since—regardless of
keyboard limitations—this is Go's character set. As has also been
mentioned, I would not (yet) force people to use the keyboard forms
for the ASCII digraph operators, but I would accept them since
keyboards are changeable, and UTF-8 gives the opportunity to actually
put in the source code the operators hinted at by the C forms. Go is
not C, should not be excessively bound by its conventions, and does
not need a foolish consistency: recognizing only operators which mis-
state intention (^, ==) and are obviously replaceable (<=, >=, <-, !=)
is not becoming. (End rant, I guess.;)
Alexis Shaw
As we need symbols for bit wise AND and bit wise OR, we want them to be similar to the Boolean equivalents, the ⩕ and ⩖ symbols are this.
We usually use monospaced fonts when programming, so the width of the character does not matter, and though I would like consistancy, you can make ͟͟⩖ U+2A50 U+0350 using combining characters, and we can modify a font so that this character sequence looks good. This or an equivalent character sequence would be my preferred bit wise XOR operator, with ⊻being for the Boolean XOR operator, I still do not know how I would write the bit wise NOT operator ,
Jason Catena
> As we need symbols for bit wise AND and bit wise OR, we want them to be
> similar to the Boolean equivalents, the ⩕ and ⩖ symbols are this.
I did misunderstand which characters you meant here. Even for
unicode, though, these are rarities. Neither the plan 9 fixed-unicode
fonts I use, nor Ubuntu's Arab nor DejuVu Sans, knows them. From
looking at the unicode.org charts I see they're overlapping double-and
and double-or, which is nice, but they're even harder to get at than
the ones we've so far proposed.
> We usually use monospaced fonts when programming, so the width of the
> character does not matter, and though I would like consistancy, you can make
> ͟͟⩖ U+2A50 U+0350 using combining characters, and we can modify a font so
> that this character sequence looks good.
Combining characters is not a good feature of Unicode (at least, it's
not done well, there's too much ambiguity), and is omitted from
UTF-8. Any character becomes the sum of an arbitrary number of
possible combinations (e.g. empty spaces can be added to any character
without changing the resulting glyph, and you can "hide" little pixel
flourishes under a fuller glyph), loses a single canonical pixel map,
and no longer corresponds to a single code point in the unicode
charts. As I understand it, this is fully out of the scope of what Go
signed on to with UTF-8.
Fortress might require special fonts for its characters (I don't
really know), but I'd be very surprised if the Go authors want to
limit its usability to those who have one. That way lies the madness
that is APL and J. Russ said on this thread that he at least would
much rather think about elegant code than presentation.
> This or an equivalent character
> sequence would be my preferred bit wise XOR operator, with ⊻being for the
> Boolean XOR operator, I still do not know how I would write the bit wise NOT
> operator ,
What boolean xor operator? Go doesn't have one. You'd probably do
something like this, to make sure each expression was only evaluated
once.
var a bool ⇐ exp1
var b bool ⇐ exp2
axorb ≔ (a ⋀ ¬b) ⋁ (¬a ⋀ b)
So far as a bitwise not operator, just xor your number with the
unsigned maximum value for your type (0xff...).
var v byte ⇐ 0xaa // original value
var V byte ⇐ 0x55 // not original value
var A byte ⇐ 0xff // xor mask
fmt.Println(v ⊻ A ≟ V)
Rob 'Commander' Pike
-rob
Alexis Shaw
Steven
↑1 ⍵∨.^3 4=+/,¯1 0 1∘.⊖¯1 0 1∘.⌽⊂⍵
-rob
The lack of availability of these characters is probably that they are in the supplemental Mathematical operators block. as for font support http://users.teilar.gr/~g1951d/ has a font symbola that supports this block, In future I feel that this block will become better supported.

Charlie Dorian
for a reason. (Wikipedia link: http://en.wikipedia.org/wiki/APL_%28programming_language%29)
Steven

Norman Yarvin
an operator for exponentiation. If it weren't already taken, the ^
character would be appropriate. But that means xor. One can't use
Fortran's **, since that conflicts with pointer dereferencing. It'd be
possible to use ^^, albeit a bit ugly. On the other hand, Unicode has
superscript-2 and superscript-3 characters. So
y = x�
z = x�
could mean what they obviously mean.

Bakul Shah
On Feb 7, 2010, at 12:51 AM, Rob 'Commander' Pike wrote:
> ↑1 ⍵∨.^3 4=+/,¯1 0 1∘.⊖¯1 0 1∘.⌽⊂⍵
Ah, Life in APL!
http://www.youtube.com/watch?v=a9xAKttWgP4
or in high resolution:
http://www.youtube.com/watch?v=a9xAKttWgP4&fmt=18
Has anyone implemented the same in go? How about a Go player in go?
Jason Catena
serious objections or points I missed before I subject this to code
review?
var unitokens = map[Token]string{
SUB: "−",
AND: "∧",
OR: "∨",
XOR: "⊻",
SHL: "≪",
SHR: "≫",
LAND: "⋀",
LOR: "⋁",
ARROW: "←",
EQL: "≟",
NOT: "¬",
NEQ: "≠",
LEQ: "≤",
GEQ: "≥",
DEFINE: "≔",
ELLIPSIS: "…",
}
func (tok Token) String() string {
if str, exists := tokens[tok]; exists {
return str
}
if str, exists = unitokens[tok]; exists {
return str
}
return "token(" + strconv.Itoa(int(tok)) + ")"
}
Jason Catena
files to see if I have it right. Looking at token.String again, it
seems like my change won't change any output, but that's okay since I
would think we want the canonical string for a token to be the
original ones in tokens[]. I probably don't need unitokens[] at all,
since it looks like scanner.Scan has all the knowledge about how to
map literals to Tokens. I'd put the new literals in scanner.Scan's
switch, using the simpler cases for models since—with only one unicode
character each—I don't need to look ahead to check the next character
for a continued literal.
Russ Cox
> So I'm thinking of this change to src/pkg/go/token/token.go. Any
> serious objections or points I missed before I subject this to code
> review?
Yes.
The current tokens are working fine, have meanings that are well
known to programmers coming from a variety of popular languages,
are just as readable (if not more so) than the proposed replacements,
are easier to type, and display correctly and distinctly in a wider variety
of contexts. The tokens being proposed range from almost (but not quite)
plausible (← for <-), to unreadable (≟ for ==), to confusing
(∧, ⋀, ⊻ for &, &&, and ^), to invisibly confusing (− for -).
By all means, feel free to keep having fun with this—I've found this
thread quite entertaining—but please don't send us code reviews.
This may be a fun bike shed discussion to have on a mailing list,
but it's not a tenable change to make in a real language that people
have to use every day.
Russ

Lawrence Bakst
> This may be a fun bike shed discussion to have on a mailing list,
> but it's not a tenable change to make in a real language that people
> have to use every day.
>
> Russ
>
I agree completely with your sentiment with respect to Go. OTOH Sun
has created a language called Fortress that uses Unicode extensively
to allow code to look closer to mathematical notation. That was one of
the goals for their language.
http://projectfortress.sun.com/Projects/Community/
I was initially very skeptical, but after seeing some of their code I
am more open minded about that direction in programming language
design. Look at the Fortress version of the NAS Conjugate Gradient
Parallel Benchmark:
http://projectfortress.sun.com/Projects/Community/wiki/FortressQuestions#InwhatwaysdoesFortresssyntaxresemblemathematicalnotation
Kind of neat, eh?
The problems aren't with reading that kind of code, it's what you have
to do to write it.
I offer the above only as long term food for thought, I don't think
it's appropriate for Go at this time, and certainly not for just a few
operators. It's an "all-in" kind of feature.
--
~leb
Jason Catena
To be clear, I propose that the scanner recognize additional tokens,
not replacements. This is like the case of trigraphs, where the
scanner recognizes multiple forms of the same token: both the multiple-
character and single-character forms. I would never propose that the
language stop recognizing the multiple-character forms in use since C,
since this would be arrogant, as you say they are easier to type, and
they are certainly more familiar. While making the change to the
scanner, I only added cases, and did not take any away.
Your point about the minus sign is taken. I removed it from my
scanner, since it's not worth trying to make it recognize - together
with - for a decrement statement.
I added =? as another equality test, which also maps to token.EQL, to
add more grist to your mill. :)
Will you still recommend I send no code reviews on this topic? If so,
that's fine, I'll just post and maintain my own scanner.Scan for
people to use if they like.
Jason Catena
do to scanner.go, what I really need to change is gc (linked in by
6g), as this shows me.
6g myscanner.go
myscanner.go:8: invalid identifier character 0xac
myscanner.go:8: undefined: ¬false
walkg 'invalid'|grep 'identifier character'
cmd/gc/lex.c:825: yyerror("invalid identifier character 0x%ux",
rune);
The tricky part is that C doesn't work with runes nearly as well as
Go, so the changes will take more work. :)
Steven
Here's a really awful, over the top idea: exchange "for ... range" for "∀ ... ∈". Dreadful :-) Nobody ever, EVER, try to implement it. I'm serious. <.< >.> <.< -.-0 < ∣x – a∣ < δ ⇒ ∣ƒ(x) – ƒ(a)∣ < ɛ
Russ Cox
> not replacements. This is like the case of trigraphs, where the
> scanner recognizes multiple forms of the same token: both the multiple-
> character and single-character forms.
As evidenced by gofmt, we really like having one standard form.
Allowing multiple spellings of each token doesn't really fit with
that philosophy. (You'll also note that 6c doesn't accept trigraphs.)
> I only added cases, and did not take any away.
Oh, that way c++0x lies.
> Will you still recommend I send no code reviews on this topic? If so,
> that's fine, I'll just post and maintain my own scanner.Scan for
> people to use if they like.
Have fun.
Russ
Bob Cunningham
> On Mon, Feb 8, 2010 at 19:10, Jason Catena<jason....@gmail.com> wrote:
>
>> So I'm thinking of this change to src/pkg/go/token/token.go. Any
>> serious objections or points I missed before I subject this to code
>> review?
>>
> Yes.
>
> The current tokens are working fine, have meanings that are well
> known to programmers coming from a variety of popular languages,
>
> are just as readable (if not more so) than the proposed replacements,
>
readable!
> are easier to type,
The threshold of difficulty is quite low: It isn't at all hard to load
keyboard macros and label the keys. It will be a corded press rather
than a single press, but it will still be a single action. And heck, I
still have to look to see which shifted-number key I need to press.
> and display correctly and distinctly in a wider variety
> of contexts.
> The tokens being proposed range from almost (but not quite)
> plausible (← for<-), to unreadable (≟ for ==), to confusing
>
Isn't that precisely the kind of thing a code review will nicely handle?
> By all means, feel free to keep having fun with this—I've found this
> thread quite entertaining—but please don't send us code reviews.
> This may be a fun bike shed discussion to have on a mailing list,
> but it's not a tenable change to make in a real language that people
> have to use every day.
>
should include updates to gofmt and godoc to help handle the conversions
(in both directions - now you see it, now you don't - just like semicolons).
-BobC
Jason Catena
> should include updates to gofmt and godoc to help handle the conversions
> (in both directions - now you see it, now you don't - just like semicolons).
Thank you Bob, you just made this really easy. I don't have to change
gc at all. My change to scanner.go updates gofmt, which translates
the unicode characters to the canonical ones. The go compilers still
see their one true character set, people can use whatever unicode
characters are made available through my scanner, and the only cost is
a trip through gofmt (which is a good thing anyway). Now, it's harder
to cut and paste gofmt output back into your original program, but
after a while coding go you pretty much adopt its style anyway. (I
use it just as a check now.)
All that said, here's my updated scanner.go, for anyone interested.
Just drop it in src/go/scanner (I first saved the official one to
scanner.gold), run src/all.bash, and check that you have 0 unexpected
errors.
http://dl.dropbox.com/u/502901/scanner.go
As a bonus, I added left (≪) and right (≫) shift, and-not (∧¬), and
assignment operators for all the aliased operators which had them.
I'll write up something with all the new forms for reference, and cut-
and-pasting, if you don't yet have shortcuts or don't like the little
character map program. In the meantime you can just take a look at
the new scanner.go for the forms.
I changed my mkfile production rule to just use gofmt instead of the
sed script, and got all my unicode sample programs working (after
switching back to = and -).
%.go: %.ℊℴ
cat $stem.ℊℴ | gofmt > $stem.go
Please mail me privately if something doesn't work with my scanner.go,
to avoid noise on this list, since it's no longer discussing
officially released code. If there's enough interest I'll create a
google code project for a mailing list and to properly serve and
change the code.
Bob Cunningham
> All that said, here's my updated scanner.go, for anyone interested.
Please also post a patch, and the command line to apply it. This may be
around for a long time. Perhaps a page on GitHub or Gitorious? After
all, there will be patches for gofmt and godoc too.
If the Go user community makes extensive use of your changes, I suspect
that will eventually create an invitation for a patch submission and a
code review.
But to reach that level of popularity, it first must become not just
possible, but effortless to enter the new characters. Cut'n'Paste alone
is not going to be sufficient. Just as the Go syntax highlighting
effort yielded many editor configuration files, we need something
similar for this, such as the current Go symbols being interpreted as
abbreviations that are expanded to the Unicode character, and probably
some X11 keyboard macros.
This could, after all, be the first real fork of Go! Forks are often
created for religious or "minor" reasons, then later unified for very
pragmatic reasons. This change needs to be as "pragmatic" as possible!
For verification, I'd like to see all the Go code in the Go repository
converted to the new symbols, and ensure it compiles correctly and
passes all tests. Then we should do our own review to fine-tune the
symbol selections.
-BobC
Peter Bourgon
thinking the same thing, but just to chime in and maybe bring a few
other people out of the woodwork:
I find the ideas in this thread quite terrifying and bad. That '==' is
ambiguous and ≟ clear, or that ⋀ is better than && -- all of this is
absurd and/or laughable to me.
Further, the idea that you're contemplating a fork of Go, and hope to
advocate for it to the point of forcing a reintegration down the line,
is so obviously and completely counter to the stated goals of the
language that I wonder if you've actually written a single Go program
at all. I and many other users and advocates of Go (including the
authors) have stated publicly, many times, that we find the "only one
idiomatic way of doing something" characteristic of the language its
most compelling feature. If you want to corrupt this principle so far
down the stack as to allow for different *symbols*, I'm inclined to
suggest that you take your pet ideas to a project that isn't so
explicitly and foundationally against them. For your sake as well as
ours.
I say this all in good spirits.
Alexis Shaw
Jason Catena
> converted to the new symbols, and ensure it compiles correctly and
> passes all tests.
I'd also never go this far. It's one thing to write a scanner that
allows people to convert from a unicode form to ascii form, and
encourages gofmt use. At this point it's entirely optional and
additional, and the ascii form must be generated and available for the
compilers to accept the program. But to my mind it's quite another to
completely switch over to new symbols, and tilt at the unmaintainable
windmill of a complete repository change à la semicolons, especially
without any support from the core team. Even if the core team did
support and integrate the additional forms, I would expect the package
repository to remain ascii, since the point of this for me is
explicitly not to force anyone to adopt the unicode forms.
> we find the "only one
> idiomatic way of doing something" characteristic of the language its
> most compelling feature.
I don't dig your tyranny, man. That way lies narrow-minded thinking,
the rejection of anything new or noteworthy, and a foolish consistency
that hobbles great minds.
Seriously, the world would have no art or creativity if as soon as you
did something, it became an ironclad convention that no-one's allowed
to break. In addition, you'll never get usage by a lot of people by
continually rejecting their input. You'll only get the tiniest
incremental changes by people with no problem being dictated to. That
describes a lot of things in this world, but not open-source software,
with its malleability and zero marginal cost of distribution. (Sorry
for taking us off track.)
Steven
I don't dig your tyranny, man.
Like, totally, dude.
That way lies narrow-minded thinking,
the rejection of anything new or noteworthy, and a foolish consistency
that hobbles great minds.
Seriously, the world would have no art or creativity if as soon as you
did something, it became an ironclad convention that no-one's allowed
to break.
The beauty of programming is creativity expressed from simple rules. Its kind of like Conway's Game of Life (thanks again for the linker): the beauty doesn't lie (only) in what the cells are doing, it lies in the fact that these complex and elegant behaviors are produced by the combination of only a few simple principals.
In addition, you'll never get usage by a lot of people by
continually rejecting their input.
Yeah, its better to make it a kind of potluck. Everyone, bring yer own style, don't worry about compilation or readability through consistency.
I think the path lies somewhere in between. In this case, a 1-for-1 swap of symbols doesn't really advance the language in any way. Its just fun to think about. :-)
Jason Catena
>
> Like, totally, dude.
Here's a flower. Peace. :)
> these complex and elegant behaviors are produced by the combination of only
> a few simple principals.
The principals being the people who make the rules, all other
perspectives be damned, is sort of my point here.
> > In addition, you'll never get usage by a lot of people by
> > continually rejecting their input.
>
> Yeah, its better to make it a kind of potluck. Everyone, bring yer own
> style, don't worry about compilation or readability through consistency.
I'm not against convention. But humans are hugely variable, and some
of them (not necessarily me) just might be smarter than you, and have
a better idea for all.
> I think the path lies somewhere in between. In this case, a 1-for-1 swap of
> symbols doesn't really advance the language in any way. Its just fun to
> think about. :-)
It's not a swap, in the sense that it's not a replacement which
removes the old symbols. My scanner adds the unicode forms because
they're more intuitive for people without a history of programming. I
mean, it's fine if the only people who will ever use Go are people
already familiar with the C family, but if Go is to be good enough to
be a first language, then it shouldn't present a barrier to
understanding by forcing people to use incorrect (^) and unintuitive
and error-prone (==) symbols that either mistake the meaning or give
no hint to people not yet familiar with the decades-old compromises
that led to current convention. Some conventions are bad, and those
conventions should be fixed, or at least an alternative allowed, to
advance the language past its current problems and rough spots.
I really don't buy that things get decided once and for all, and
adhering to convention is the best course in the face of something
clearly better. Let's say for a moment you don't buy the entire
unicode operator argument: it's still better to recognize =? in
addition to ==, but keep == for easier adaptation of decades of legacy
code. It is a compromise to allow multiple representations of the
same symbol, and translate them down to that standard symbol in source
code viewable to the programmer. It is one of the principles makes
the world actually work: /Paris vaut bien une messe/. If you are
dictatorial about the little things that are wrong, you're going to
have a much harder time getting people to adopt the wonderful new
principles that are right, because people will take one look at
something silly (too many parentheses!) and reject something out of
hand (LISP).
Here's another example. Would you say that the would should give up
all diacritical marks whatsoever because the Latin alphabet doesn't
have any? After all, no-diacritical-marks is the convention of the
Latin alphabet, so why allow in any diacritical marks? Go expanded
the range of the language's identifiers and strings to accept unicode
characters. Why limit the operators to ascii forms? Let people
express themselves as they like, and use gofmt to translate to a
sharable, compilable form. That's something I have no problem
compromising on, because the best unicode alternatives of the
operators are not well decided, and there's no clear convention. ;)
roger peppe
how nice is that?

Graham
Is that the SGML/HTML &name;
Even if it is, it is counter intuitive in my left-to-right world.
> ARROW: "←",
Bob Cunningham
>> For verification, I'd like to see all the Go code in the Go repository
>> converted to the new symbols, and ensure it compiles correctly and
>> passes all tests.
>>
> I'd also never go this far. It's one thing to write a scanner that
> allows people to convert from a unicode form to ascii form, and
> encourages gofmt use. At this point it's entirely optional and
> additional, and the ascii form must be generated and available for the
> compilers to accept the program. But to my mind it's quite another to
> completely switch over to new symbols, and tilt at the unmaintainable
> windmill of a complete repository change à la semicolons, especially
> without any support from the core team. Even if the core team did
> support and integrate the additional forms, I would expect the package
> repository to remain ascii, since the point of this for me is
> explicitly not to force anyone to adopt the unicode forms.
>
If your suggestion is for new Go code only, then it is already DOA with
me. I have no intention of manually updating the Go code I've already
written (maybe 3k lines of dubious quality) to use the new symbols.
If you want your idea to be taken seriously, a two-way conversion tool
is mandatory. (New-to-Current for the compiler, and Current-to-New for
existing code.)
Plus, to really get behind this idea, I'd need to see it applied to lots
of good Go code (far better than mine), so I can compare the two
versions side-by-side. The vast majority of the best Go code I've seen
is in the Go repository, written mainly by the Go Team. That's the code
I'd most like to convert and examine: If the new symbols don't look good
when applied to the best Go code available, then the new symbols are not
going to succeed. But if they do look great, that would be the best
statement of their benefit.
If you aren't willing to plan to ensure the toolchain is capable of
supporting this, then there is little reason to proceed with any work on
it; it will be a toy that goes nowhere. This is your baby: Tell us if
it is a toy or a serious suggestion.
If you do decide to go forward, I suspect the major process steps will
be something like this:
1. Clone the current Go repository (github, gitorious, etc.), and tell
us where it is.
2. Update gofmt to perform conversion from the new symbols to the
current symbols. (This would be the pre-compile tool, so the compiler
need not be modified right away, and allow new code using the new
symbols to be compiled.)
3. Update gofmt to perform conversion from the current symbols to the
new symbols. (This would permit existing code to be converted, which in
turn permits the new symbols to be examined in many contexts.)
4. Update godoc to make it possible to view Go code using either symbol
set. (This will make it easy to look at lots of Go code in both styles.)
5. Fine-tune the symbol selections, with lots of community input.
6. Update all currently available syntax highlighters.
7. Explore ways to simplify symbol input (editor macros, keyboard
macros, X11 input modes, etc.)
8. Figure out how to update your repository from the main Go repository,
so users of your tree will also get the latest Go changes.
That's just off the top of my head. I suspect that list needs some work.
Basically, since you've started this thread, you'll be the project
leader. Get the repository up and apply your current changes. Ask for
help, and I'm certain you'll get some: Even those who aren't in favor
of your changes may be interested in helping, if only to have a reason
to tinker with gofmt, godoc, and some of the other things in the above list.
-BobC
Michael Jones
↑1 ⍵∨.^3 4=+/,¯1 0 1∘.⊖¯1 0 1∘.⌽⊂⍵
-rob
--
Michael T. Jones
Chief Technology Advocate, Google Inc.
1600 Amphitheatre Parkway, Mountain View, California 94043
Email: m...@google.com Mobile: 408-507-8160 Fax: 650-649-1938
Advancing the technology to organize the world's information and make it universally accessible and useful
Jason Catena
installation, and links to my scanner.go and brief program examples.
http://swtools.wordpress.com/2010/02/10/update-go-scanner-to-accept-non-ascii-operators/
Jason Catena
> APL never confused me, and APL => Dictionary APL => "J" learned to do more
> with less symbology. (http://www.jsoftware.com/jwiki/Puzzles/Div9)
One advantage of having those odd symbols in APL is that you may yet
have no idea what an operator does, but you know how many operations
you have to consider. In a sequence like *./@~:"1 I (a rank beginner)
have no idea how many operations are there, since I assume constructs
like {:@$ and {:: are ASCII forms of single operators.
> One plea -- please don't use the congruence symbol to mean equality test,
> assignment, or anything other than congruence. That would make my head hurt.
> ;-)
No problem. We can definitely avoid making incongruous use of this
symbol.
Steven
One plea -- please don't use the congruence symbol to mean equality test, assignment, or anything other than congruence. That would make my head hurt. ;-)
Michael Jones

eekee
have a consistent representation -- a consistent style actually, I was
thinking of indentation -- but should be converted to suit each coder.
Perhaps the conversion should happen in the editor, perhaps on commit
and checkout from the SCM, I don't know, but my feeling is code style
should ideally be adapted to each individual coder rather than be
dictated by the project or, indeed, by the language.
On Feb 6, 12:52 am, Jason Catena <jason.cat...@gmail.com> wrote:
> To try this out, I made *.ℊℴ versions of a few small test programs.
> This initial list transforms from characters not currently recognized
> by Go to ones which are. That is to say, I didn't change any of the
> current characters, just introduced new ways of saying existing ones.
> I like ≝ (equal to by definition) a little better than ≔ for :=.
>
> s,¬,!,g
> s,…,...,g
> s,←,<-,g
> s,⇐,=,g
> s,−,-,g
> s,∧,\&,g
> s,∨,|,g
> s,≔,:=,g
> s,≝,:=,g
> s,≠,!=,g
> s,≡,==,g
> s,≤,<=,g
> s,≥,>=,g
> s,⋀,\&\&,g
> s,⋁,||,g
TomChrome Mitchell
It should be possible to have the operator "←" meaning the same as
"<-". Makes for beautiful looking code.
--
// aht
http://blog.onideas.ws
Jason Catena
> "←"
> $ od -xc /tmp/f
> 0000000 2220 86e2 2290 0a0a
> " 342 206 220 " \n \n
> 0000010
So do this first (may require plan9port's sed):
sed 's/←/<-/g'
From only my point of view: I intended my scanner change to enable
gofmt to preprocess out the non-ASCII symbols before the compiler, or
another human, sees the code (and to encourage gofmt use). So someone
who is comfortable with the non-ASCII characters, and wants to use
them, can, and can also look at a version without the non-ASCII
characters, and send this version to other people and the compiler
without changing how they expect to see Go source text. The scanner
as I changed it accepts both the ASCII and non-ASCII operators, and
translates them both to the same non-ASCII output representation (so I
don't have to also change gc). For many reasons, I (do not speak for
the Go authors) do not feel it's the right time to force anyone to
view Go source text with non-ASCII operators, but it is a good time to
let people use them if they have an environment in which they're
comfortable with them (which I am).
Jason Catena
The scanner as I changed it accepts both the ASCII and non-ASCII
operators, and translates them both to the same *ASCII* output
Nifty niftychrome Mitch
>
> == does not fail quietly in go; a = b is not an expression. I agree
> that == might not make sense tho. I'd propose to accept both = and ==
> for tests:
>
> if a = b {...
>
> Same as:
>
> if a == b {
>
> or maybe even do away with ==, since it is unnecessary in go.
On the issue of == test and = assignment it is not
without precedent to express the test as .eq. and
other comparisons into dot bounded key words .gt., .lt. etc...
--
T o m M i t c h e l l
Found me a new hat, now what?
Jason Catena
> without precedent to express the test as .eq. and
> other comparisons into dot bounded key words .gt., .lt. etc...
Part of me wants to always express it v1.Eq(v2), and make basic
operations on native and custom types both methods, to more broadly
use interfaces. The code would look more like Smalltalk or Lisp than
C, though.

David Lehmann

Johann Höchtl
http://golang.org/doc/go_spec.html#Source_code_representation
thank you very much. But, by any means, please refrain from _forcing_ users to type anything besides pure ASCII.
Johann
Kyle Lemons

{kind=link}
Fisher Wei
Br,
Paul Borman
-Paul