XNAT keeps stalling
153 views
Skip to first unread message

Ben Wagner
Sep 25, 2022, 4:58:52 PM9/25/22
to xnat_discussion
Ok, I've spent a week looking at logs and trying different settings (ram, configurations, etc), but I've not been able to figure this out. Our XNAT is now stalling out after a while. Usually about 3ish hours but with variation. The process seems to be running, but I can't connect. The error for update_ls_xdat_user_login has crept up many times, but I can't tell if it is a cause or effect of something. Same with the Java heap space error in the apache log. Current tomcat/XNAT opts are:
Environment="JAVA_OPTS=-Dxnat.home=${XNAT_HOME} -Djava.awt.headless=true -Xms512m -Xmx1g -XX:+UseConcMarkSweepGC -server"
Environment="CATALINA_OPTS=-XX:+UseConcMarkSweepGC -XX:-OmitStackTraceInFastThrow -Xms1024m -Xmx10240m"
Any suggestions?
Ben
2022-09-25 07:38:39,460 [ajp-nio-127.0.0.1-8008-exec-1] ERROR org.nrg.xft.db.PoolDBUtils - The following query took longer than 1000 ms to complete: 10173 ms (null). This may not indicate an error but could indicate an inefficient query or a performance issue with the database: SELECT update_ls_xdat_user_login(7450526,NULL)
2022-09-25 08:05:36,870 [ajp-nio-127.0.0.1-8008-exec-8] ERROR org.nrg.xft.db.PoolDBUtils - The following query took longer than 1000 ms to complete: 34062 ms (null). This may not indicate an error but could indicate an inefficient query or a performance issue with the database: SELECT update_ls_xdat_user_login(7450534,NULL)
2022-09-25 08:10:58,337 [ajp-nio-127.0.0.1-8008-exec-4] ERROR org.nrg.xft.db.PoolDBUtils - SELECT EXISTS(SELECT relname FROM pg_catalog.pg_class WHERE relname = LOWER('xs_item_cache')) AS cache_exists
2022-09-25 08:35:32,181 [ajp-nio-127.0.0.1-8008-exec-4] ERROR org.nrg.xft.db.PoolDBUtils - An database or SQL error occurred trying to validate or create the XNAT item cache.
org.postgresql.util.PSQLException: The connection attempt failed.
at org.postgresql.core.v3.ConnectionFactoryImpl.openConnectionImpl(ConnectionFactoryImpl.java:296)
at org.postgresql.core.ConnectionFactory.openConnection(ConnectionFactory.java:49)
at org.postgresql.jdbc.PgConnection.<init>(PgConnection.java:211)
at org.postgresql.Driver.makeConnection(Driver.java:459)
at org.postgresql.Driver.connect(Driver.java:261)
at org.apache.commons.dbcp2.DriverConnectionFactory.createConnection(DriverConnectionFactory.java:52)
at org.apache.commons.dbcp2.PoolableConnectionFactory.makeObject(PoolableConnectionFactory.java:374)
at org.apache.commons.pool2.impl.GenericObjectPool.create(GenericObjectPool.java:918)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:431)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:356)
at org.apache.commons.dbcp2.PoolingDataSource.getConnection(PoolingDataSource.java:141)
at org.apache.commons.dbcp2.BasicDataSource.getConnection(BasicDataSource.java:731)
2022-09-25 08:05:36,870 [ajp-nio-127.0.0.1-8008-exec-8] ERROR org.nrg.xft.db.PoolDBUtils - The following query took longer than 1000 ms to complete: 34062 ms (null). This may not indicate an error but could indicate an inefficient query or a performance issue with the database: SELECT update_ls_xdat_user_login(7450534,NULL)
2022-09-25 08:10:58,337 [ajp-nio-127.0.0.1-8008-exec-4] ERROR org.nrg.xft.db.PoolDBUtils - SELECT EXISTS(SELECT relname FROM pg_catalog.pg_class WHERE relname = LOWER('xs_item_cache')) AS cache_exists
2022-09-25 08:35:32,181 [ajp-nio-127.0.0.1-8008-exec-4] ERROR org.nrg.xft.db.PoolDBUtils - An database or SQL error occurred trying to validate or create the XNAT item cache.
org.postgresql.util.PSQLException: The connection attempt failed.
at org.postgresql.core.v3.ConnectionFactoryImpl.openConnectionImpl(ConnectionFactoryImpl.java:296)
at org.postgresql.core.ConnectionFactory.openConnection(ConnectionFactory.java:49)
at org.postgresql.jdbc.PgConnection.<init>(PgConnection.java:211)
at org.postgresql.Driver.makeConnection(Driver.java:459)
at org.postgresql.Driver.connect(Driver.java:261)
at org.apache.commons.dbcp2.DriverConnectionFactory.createConnection(DriverConnectionFactory.java:52)
at org.apache.commons.dbcp2.PoolableConnectionFactory.makeObject(PoolableConnectionFactory.java:374)
at org.apache.commons.pool2.impl.GenericObjectPool.create(GenericObjectPool.java:918)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:431)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:356)
at org.apache.commons.dbcp2.PoolingDataSource.getConnection(PoolingDataSource.java:141)
at org.apache.commons.dbcp2.BasicDataSource.getConnection(BasicDataSource.java:731)
[SNIP]
application.log
2022-09-25 08:00:44,197 [ajp-nio-127.0.0.1-8008-exec-9] ERROR org.hibernate.engine.jdbc.spi.SqlExceptionHelper - The connection attempt failed.
2022-09-25 08:20:20,570 [taskScheduler-4] ERROR org.hibernate.engine.jdbc.spi.SqlExceptionHelper - The connection attempt failed.
2022-09-25 08:10:25,974 [SimpleAsyncTaskExecutor-587] ERROR org.hibernate.engine.jdbc.spi.SqlExceptionHelper - The connection attempt failed.
2022-09-25 08:35:32,201 [SimpleAsyncTaskExecutor-587] ERROR org.springframework.aop.interceptor.SimpleAsyncUncaughtExceptionHandler - Unexpected error occurred invoking async method: public void org.nrg.xnat.eventservice.services.impl.EventServiceImpl.syncReactorRegistrations()
org.springframework.transaction.CannotCreateTransactionException: Could not open Hibernate Session for transaction; nested exception is org.hibernate.exception.JDBCConnectionException: Could not open connection
at org.springframework.orm.hibernate4.HibernateTransactionManager.doBegin(HibernateTransactionManager.java:544)
at org.springframework.transaction.support.AbstractPlatformTransactionManager.getTransaction(AbstractPlatformTransactionManager.java:377)
at org.springframework.transaction.interceptor.TransactionAspectSupport.createTransactionIfNecessary(TransactionAspectSupport.java:464)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:277)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:96)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:672)
at org.nrg.xnat.eventservice.services.impl.EventSubscriptionEntityServiceImpl$$EnhancerBySpringCGLIB$$6f3e8c86.getAllSubscriptions(<generated>)
at org.nrg.xnat.eventservice.services.impl.EventServiceImpl.syncReactorRegistrations(EventServiceImpl.java:581)
at sun.reflect.GeneratedMethodAccessor263.invoke(Unknown Source)
2022-09-25 08:20:20,570 [taskScheduler-4] ERROR org.hibernate.engine.jdbc.spi.SqlExceptionHelper - The connection attempt failed.
2022-09-25 08:10:25,974 [SimpleAsyncTaskExecutor-587] ERROR org.hibernate.engine.jdbc.spi.SqlExceptionHelper - The connection attempt failed.
2022-09-25 08:35:32,201 [SimpleAsyncTaskExecutor-587] ERROR org.springframework.aop.interceptor.SimpleAsyncUncaughtExceptionHandler - Unexpected error occurred invoking async method: public void org.nrg.xnat.eventservice.services.impl.EventServiceImpl.syncReactorRegistrations()
org.springframework.transaction.CannotCreateTransactionException: Could not open Hibernate Session for transaction; nested exception is org.hibernate.exception.JDBCConnectionException: Could not open connection
at org.springframework.orm.hibernate4.HibernateTransactionManager.doBegin(HibernateTransactionManager.java:544)
at org.springframework.transaction.support.AbstractPlatformTransactionManager.getTransaction(AbstractPlatformTransactionManager.java:377)
at org.springframework.transaction.interceptor.TransactionAspectSupport.createTransactionIfNecessary(TransactionAspectSupport.java:464)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:277)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:96)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:672)
at org.nrg.xnat.eventservice.services.impl.EventSubscriptionEntityServiceImpl$$EnhancerBySpringCGLIB$$6f3e8c86.getAllSubscriptions(<generated>)
at org.nrg.xnat.eventservice.services.impl.EventServiceImpl.syncReactorRegistrations(EventServiceImpl.java:581)
at sun.reflect.GeneratedMethodAccessor263.invoke(Unknown Source)
[SNIP]
configuration.log
2022-09-25 08:35:32,201 [taskScheduler-4] ERROR org.nrg.xnat.configuration.SchedulerConfig - Something happened while handling a scheduled task
org.springframework.transaction.CannotCreateTransactionException: Could not open Hibernate Session for transaction; nested exception is org.hibernate.exception.JDBCConnectionException: Could not open connection
at org.springframework.orm.hibernate4.HibernateTransactionManager.doBegin(HibernateTransactionManager.java:544)
at org.springframework.transaction.support.AbstractPlatformTransactionManager.getTransaction(AbstractPlatformTransactionManager.java:377)
at org.springframework.transaction.interceptor.TransactionAspectSupport.createTransactionIfNecessary(TransactionAspectSupport.java:464)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:277)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:96)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:672)
at org.nrg.prefs.services.impl.hibernate.HibernatePreferenceService$$EnhancerBySpringCGLIB$$eaf6dc31.getPreference(<generated>)
at org.nrg.prefs.resolvers.AbstractPreferenceEntityResolver.resolve(AbstractPreferenceEntityResolver.java:36)
at org.nrg.prefs.services.impl.DefaultNrgPreferenceService.getPreference(DefaultNrgPreferenceService.java:140)
at org.nrg.prefs.services.impl.DefaultNrgPreferenceService.getPreferenceValue(DefaultNrgPreferenceService.java:179)
at org.nrg.prefs.services.impl.DefaultNrgPreferenceService.getPreferenceValue(DefaultNrgPreferenceService.java:171)
at org.nrg.prefs.beans.AbstractPreferenceBean.getValue(AbstractPreferenceBean.java:268)
at org.nrg.xdat.preferences.SiteConfigPreferences.getAliasTokenTimeout(SiteConfigPreferences.java:1627)
at org.nrg.xnat.security.alias.ClearExpiredAliasTokens.runTask(ClearExpiredAliasTokens.java:37)
org.springframework.transaction.CannotCreateTransactionException: Could not open Hibernate Session for transaction; nested exception is org.hibernate.exception.JDBCConnectionException: Could not open connection
at org.springframework.orm.hibernate4.HibernateTransactionManager.doBegin(HibernateTransactionManager.java:544)
at org.springframework.transaction.support.AbstractPlatformTransactionManager.getTransaction(AbstractPlatformTransactionManager.java:377)
at org.springframework.transaction.interceptor.TransactionAspectSupport.createTransactionIfNecessary(TransactionAspectSupport.java:464)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:277)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:96)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:672)
at org.nrg.prefs.services.impl.hibernate.HibernatePreferenceService$$EnhancerBySpringCGLIB$$eaf6dc31.getPreference(<generated>)
at org.nrg.prefs.resolvers.AbstractPreferenceEntityResolver.resolve(AbstractPreferenceEntityResolver.java:36)
at org.nrg.prefs.services.impl.DefaultNrgPreferenceService.getPreference(DefaultNrgPreferenceService.java:140)
at org.nrg.prefs.services.impl.DefaultNrgPreferenceService.getPreferenceValue(DefaultNrgPreferenceService.java:179)
at org.nrg.prefs.services.impl.DefaultNrgPreferenceService.getPreferenceValue(DefaultNrgPreferenceService.java:171)
at org.nrg.prefs.beans.AbstractPreferenceBean.getValue(AbstractPreferenceBean.java:268)
at org.nrg.xdat.preferences.SiteConfigPreferences.getAliasTokenTimeout(SiteConfigPreferences.java:1627)
at org.nrg.xnat.security.alias.ClearExpiredAliasTokens.runTask(ClearExpiredAliasTokens.java:37)
[SNIP]
tomcat log:
Exception in thread "ajp-nio-127.0.0.1-8008-Acceptor" Exception in thread "threadPoolExecutorFactoryBean-120" java.lang.OutOfMemoryError: Java heap space
java.lang.OutOfMemoryError: Java heap space
at org.dcm4che2.net.PDUDecoder.<init>(PDUDecoder.java:82)
at org.dcm4che2.net.Association.run(Association.java:880)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
25-Sep-2022 08:10:16.088 SEVERE [ajp-nio-127.0.0.1-8008-exec-3] org.apache.coyote.AbstractProtocol$ConnectionHandler.process Failed to complete processing of a request
java.lang.OutOfMemoryError: Java heap space
25-Sep-2022 08:17:03.178 SEVERE [ajp-nio-127.0.0.1-8008-exec-11] org.apache.coyote.AbstractProtocol$ConnectionHandler.process Failed to complete processing of a request
java.lang.OutOfMemoryError: Java heap space
25-Sep-2022 08:28:58.914 SEVERE [ajp-nio-127.0.0.1-8008-exec-2] org.apache.coyote.AbstractProtocol$ConnectionHandler.process Failed to complete processing of a request
java.lang.OutOfMemoryError: Java heap space
Exception in thread "pool-2-thread-1" java.lang.OutOfMemoryError: Java heap space
java.lang.OutOfMemoryError: Java heap space
at org.dcm4che2.net.PDUDecoder.<init>(PDUDecoder.java:82)
at org.dcm4che2.net.Association.run(Association.java:880)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
25-Sep-2022 08:10:16.088 SEVERE [ajp-nio-127.0.0.1-8008-exec-3] org.apache.coyote.AbstractProtocol$ConnectionHandler.process Failed to complete processing of a request
java.lang.OutOfMemoryError: Java heap space
25-Sep-2022 08:17:03.178 SEVERE [ajp-nio-127.0.0.1-8008-exec-11] org.apache.coyote.AbstractProtocol$ConnectionHandler.process Failed to complete processing of a request
java.lang.OutOfMemoryError: Java heap space
25-Sep-2022 08:28:58.914 SEVERE [ajp-nio-127.0.0.1-8008-exec-2] org.apache.coyote.AbstractProtocol$ConnectionHandler.process Failed to complete processing of a request
java.lang.OutOfMemoryError: Java heap space
Exception in thread "pool-2-thread-1" java.lang.OutOfMemoryError: Java heap space

John Flavin
Sep 26, 2022, 3:07:44 PM9/26/22
to xnat_di...@googlegroups.com
Most of those errors are about connecting to the database. For instance,
2022-09-25 08:35:32,181 [ajp-nio-127.0.0.1-8008-exec-4] ERROR org.nrg.xft.db.PoolDBUtils - An database or SQL error occurred trying to validate or create the XNAT item cache.
org.postgresql.util.PSQLException: The connection attempt failed.
and
org.springframework.transaction.CannotCreateTransactionException: Could not open Hibernate Session for transaction; nested exception is org.hibernate.exception.JDBCConnectionException: Could not open connection
I would start by debugging the database. Are you able to connect to it directly? If you restart it, does XNAT get better?
The out of memory thing looks separate to me (but, then again, maybe it is related, I don't know). That error is coming from the DICOM SCP receiver. Specifically it looks like it has accepted a connection and is about to start reading the incoming stream, but hasn't read it yet. Allocating the memory for the PDUDecoder trips the OutOfMemoryError. That seems like a pretty routine thing to do, so my hypothesis is that is a symptom rather than the cause.
Are you able to get to the monitoring / stats page at <your xnat>/monitoring? That could give you some insights. Maybe you could generate a heap dump and see if something big is taking up a lot of memory.
Backend Team Lead
He/Him

--
You received this message because you are subscribed to the Google Groups "xnat_discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to xnat_discussi...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/53fd8456-be31-4c78-b06e-eff104017506n%40googlegroups.com.

Richard Cole
Sep 27, 2022, 10:11:29 AM9/27/22
to xnat_di...@googlegroups.com
What is your OS / Version?
What are your relevant software versions? (XNAT, Java, Postgres, {apache, nginx} , Tomcat)
How much RAM do you have?
Is this correct or typo added "0" in your "-Xmx10240m" CATALINA_OPTS ?
Memory issues can be very hard to narrow down, so I would recommend installing a more thorough monitoring tool...
I have installed "NJMON" in the past to give me a full picture of what is happening on a server "Linux".
I would start there..
--

Rick Herrick
Sep 27, 2022, 12:13:38 PM9/27/22
to xnat_di...@googlegroups.com
Another thing I’d point out: JAVA_OPTS and CATALINA_OPTS are both used for the particular commands that use CATALINA_OPTS, i.e. they’re additive for the start, run, and debug commands. That means you’re specifying some options twice, specifically:
- -Xms
- -Xmx
- -XX:+UseConcMarkSweepGC
Generally you don’t need those flags in JAVA_OPTS, as the commands that only use that are small and fast, e.g. stop. For the same reason, you don’t want -server in JAVA_OPTS, as that makes the JVM run more quickly but start up more slowly (it does make sense in CATALINA_OPTS. I’d suggest the following changes in your environment variables:
JAVA_OPTS=-Dxnat.home=${XNAT_HOME} -Djava.awt.headless=true
CATALINA_OPTS=-XX:+UseConcMarkSweepGC -XX:-OmitStackTraceInFastThrow -Xms1g -Xmx10g -server
Technically you don’t need -Dxnat.home in JAVA_OPTS (that’s only relevant when starting XNAT), but it doesn’t cause any harm there.
Rick Herrick
Senior Software Developer

------ Original Message ------
From "Richard Cole" <richie...@gmail.com>
Date 9/27/2022 9:11:17 AM
Subject Re: [XNAT Discussion] XNAT keeps stalling
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CAMJTqOeWo6KW_Wxw45U1m%3DRx-bSCUu9U7jhMxnY0WW1LK%3DC7Pg%40mail.gmail.com.
Ben Wagner
Sep 27, 2022, 2:39:21 PM9/27/22
to xnat_di...@googlegroups.com
Hi All,
Thanks for the ideas. Responses below:
Postgres is solid. Which is why the DB errors are odd. But to confirm, I am able to connect through CLI and XNAT instances on other boxes, even when one XNAT is stalled. I've been watching the monitoring page. Problem is it's inaccessible once the instance stalls. But I'll continue to monitor.
Richard:
OS: RHEL 8.6
XNAT: 1.8.5.1; Tomcat: 9.0.65; Java: openjdk-1.8.0.345.b01-1; apache: 2.4.37-47; postgres: 11.17
RAM is 48G with XNAT allowed 10G. Other applications on server are CTP and Posgres
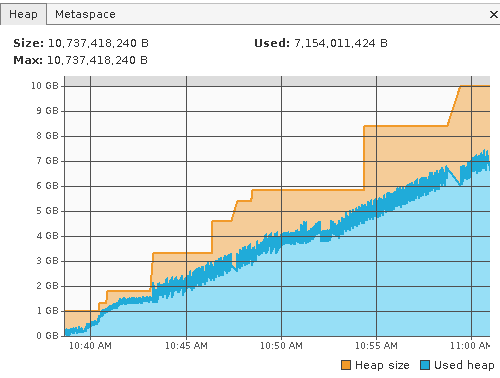
I have many aspects of the server monitored through nagios. Nothing too telling there (poor polling frequency I guess). However, the njmon site led me to VisualVM. Watching the heap with this tool gives a better picture. This is basically from a start to stall. There is a wealth of info in the heap dumps, but I don't know what to do with it. I tried to compare one pre-stall and post-stall and didn't see anything glaringly obvious. I'll continue to look.
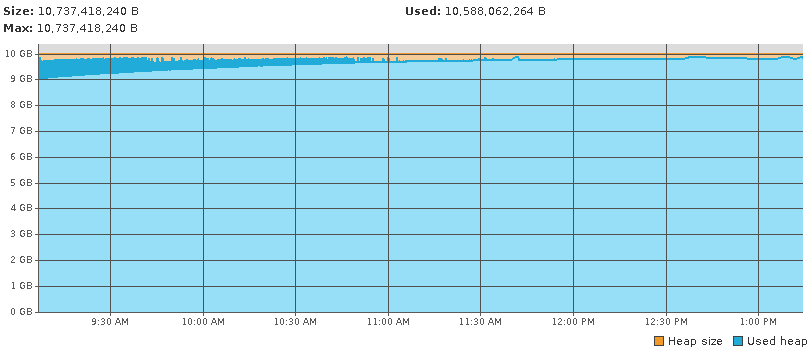
Rick,
I've updated the *_OPTS per recommendation. Theoretically the CATALINA_OPTS should override the JAVA_OPTS on general start and be a wash for changes, but I'm seeing a bit something different in the heap graph (live above). I'll let this run some more and see.
Thanks everyone!
Ben
You received this message because you are subscribed to a topic in the Google Groups "xnat_discussion" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/xnat_discussion/t-3CrU-89ZQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to xnat_discussi...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/emba725eb7-5e32-427a-84f5-a4ba5dfb6cc2%40802d8e03.com.
Ben Wagner
Sep 28, 2022, 4:05:05 PM9/28/22
to xnat_di...@googlegroups.com
Ok, as a last desperate result I replaced the ear file with the 1.8.5 version. Things are going a lot differently now:
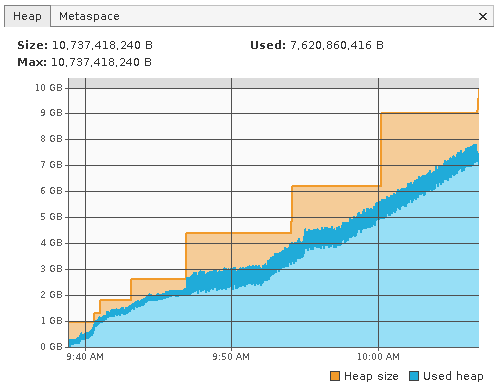
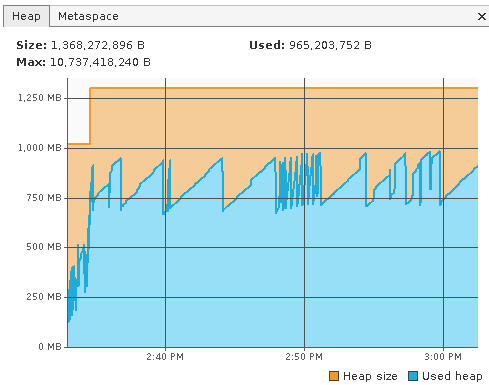
XNAT 1.8.5.1:
XNAT 1.8.5 (not the .1 release):
This is a bit interesting. XNAT devs....any ideas?
Ben
Richard Cole
Sep 28, 2022, 4:29:20 PM9/28/22
to xnat_di...@googlegroups.com
Curious to see if the 1.8.5.1.war you downloaded got corrupt ... maybe try to re-download 1.8.5.1.war again, and see how it performs..
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CADVL1QzxFj8d9T_TUhhaYCoqVQ-jRooskx%2Bx45Fix0juCskctg%40mail.gmail.com.

Charlie Moore
Sep 28, 2022, 4:30:25 PM9/28/22
to xnat_discussion
Hi Ben,
Yikes, that looks pretty bad. I don't have any ideas on why that would happen but could you help give us a big picture view of your XNAT's data? In particular, how many projects do you have, and how many of them are public? Those seem like the most likely variables to interact with what changed in XNAT 1.8.5.1.
Thanks,
Charlie Moore
Richard Cole
Sep 28, 2022, 4:44:26 PM9/28/22
to xnat_di...@googlegroups.com
Charlie, wondering if it might be worthwhile to provide "checksum" files for the pertinate XNAT files
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/3f35e64c-8c5a-4aca-a20c-a32a2714d649n%40googlegroups.com.
Ben Wagner
Sep 28, 2022, 4:50:11 PM9/28/22
to xnat_di...@googlegroups.com
Hi Charlie,
56 projects, 8645 subjects, and 13403 imaging sessions. 55 projects are private. About 20 plugins, but using the same between the two versions. Most are custom. 380 data types listed.
Hi Richard,
I do some slight modifications to the war file (templates, javascript, add a few libraries), but I've been doing that since 1.7. And no changes between the 1.8.5 and 1.8.5.1 additions. However, I did check my base war and it matches a download from today.
Ben
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CAMJTqOeeA5XQREihY9H%2B83rgPD9dbH2DK-i7y3E%3DTdcJ%2Bx%2BB3A%40mail.gmail.com.
Rick Herrick
Sep 28, 2022, 4:59:31 PM9/28/22
to xnat_di...@googlegroups.com
Try this:
- Go to the monitoring page (http://server/monitoring) within XNAT
- Wait until the used heap space starts to climb up (but before XNAT dies, obvs)
- Clicking Execute the garbage collector under System information
You should see the used heap drop. If not, that means references to allocated objects are still being held somewhere. If so, that means that for some reason the garbage collector isn’t getting to run.
------ Original Message ------
From "Ben Wagner" <thewa...@gmail.com>
Date 9/28/2022 3:49:57 PM
Subject Re: Re[2]: [XNAT Discussion] XNAT keeps stalling
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CADVL1Qy-Cgcyrnbq%2Bef1OmbszyBgfWsn7oKRmRiLid7uT-AZRg%40mail.gmail.com.
Ben Wagner
Sep 28, 2022, 5:01:42 PM9/28/22
to xnat_di...@googlegroups.com
Hi Rick,
I did try that multiple times. There was a minor drop, but nothing appreciable.
Ben
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/em256bb995-052f-4411-9d97-2e86ecd7a21d%40f5a781b1.com.
Ben Wagner
Sep 29, 2022, 12:41:51 PM9/29/22
to xnat_di...@googlegroups.com
Hmm, I've been doing some testing today. In my development testbed (1 private project, 16 subjects, 18 sessions) I loaded all the plugins in small groups to see if any of the plugins were misbehaving. I've so far seen no heap creap like on the production instance(s) including when all plugins are active. This leads me to think it's either the public/private project mix (Charlie mentioned) or something is off in the production database elsewhere. I've often wished for a tool to check the sane-ness of the XNAT database (data mainly, not just structure).
Ben

Tim Olsen
Sep 29, 2022, 1:40:01 PM9/29/22
to xnat_di...@googlegroups.com
Ben,
Are your plugins closed source? Any chance you'd be willing to share them (privately) so we could try to reproduce your configuration?
Do you have one user account (or more) that is a member of all of the 56 projects? My first suspiscion is the permissions model. 380 data types x 56 projects adds up. But, then your symptoms look more like a leak of some sort. I'm thinking something about your configuration is poking XNAT in a weak spot. (and the permissions model is definitely a weak sopt)
Are your plugins closed source? Any chance you'd be willing to share them (privately) so we could try to reproduce your configuration?
Do you have one user account (or more) that is a member of all of the 56 projects? My first suspiscion is the permissions model. 380 data types x 56 projects adds up. But, then your symptoms look more like a leak of some sort. I'm thinking something about your configuration is poking XNAT in a weak spot. (and the permissions model is definitely a weak sopt)
Tim
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CADVL1QzoXNXwVZmc_o6%3DaxsUmmKj7g88fpF4jJqF5B9Rrax-rw%40mail.gmail.com.
Ben Wagner
Sep 29, 2022, 1:47:53 PM9/29/22
to xnat_di...@googlegroups.com
Hi Tim,
Send me a location off list, and I'll drop the plugins there. They're not closed source, but I don't want them in the wild either. ;)
My user account is attached to most projects (55 of 56).
Ben
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CAH9skcRNUOcMwR8gYv_BQDnZ2Yp3ieS-wec1ecb35tvmB%3Dns5A%40mail.gmail.com.
Tim Olsen
Sep 29, 2022, 1:56:31 PM9/29/22
to xnat_di...@googlegroups.com
When you do a fresh system restart, is it locking up before it comes all the way up? Or is it after you try to login?
Tim
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CADVL1Qx2fhOtDCUbwSwwbU2YrC62gZyzRGTKtGq5wsatZ5G%2BPw%40mail.gmail.com.
Ben Wagner
Sep 29, 2022, 2:06:31 PM9/29/22
to xnat_di...@googlegroups.com
It would come up and could be interactive for several hours at the 10G level. It would go into a stalled state (hate to call it crashed) with our without me logging in. For example, the xnat service would restart at 3am each day. It was not uncommon for it to have stalled before I started work at 8. The only potential user during that time was a site admin pipeline account.
Ben
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CAH9skcSVnp0jXA66KH-fh1PCmo_L286iZkppyC2FQugysVh7gw%40mail.gmail.com.
Ben Wagner
Sep 29, 2022, 3:21:30 PM9/29/22
to xnat_di...@googlegroups.com
I'll add this in, not sure it's fully related, but maybe tangentially. I've been watching the 1.8.5 instances with the same tool. One is user facing, primarily UI stuff. The other is for our pipeline, so only a pipeline site admin user. The user facing one has crept up to 5G-6G usage while the pipeline facing one has sat steadily at 0.9G-1.3G. So maybe something pre-existing, but amplified in the 1.8.5.1 release.
Ben
Tim Olsen
Sep 29, 2022, 5:07:54 PM9/29/22
to xnat_di...@googlegroups.com
I've gotten your plugins installed on one of our test servers and created 100 projects without issue as a single user. I set them all to private, and still didn't have noticeable issues. I'll leave that server running and see if it creeps up, but I don't see anything suspicious at present.
If I had access to this stuff myself, I would create a test copy of the prod database and start doing some profiling. In particular, I'd take a heap dump snapshot before the issue is bad, and another once its in full swing. Then use a comparison tool (like JProfiler) to compare the two. That would help to identify the objects that are filling things up.
There was some cleanup work in 1.8.5.1 which greatly improved performance (load time) of the public/protected project permissions. We haven't seen any downsides to it, but it could be that something is unique in your configuration that is exposing an issue. Sometimes making one thing faster, adds stress somewhere else.
If I had access to this stuff myself, I would create a test copy of the prod database and start doing some profiling. In particular, I'd take a heap dump snapshot before the issue is bad, and another once its in full swing. Then use a comparison tool (like JProfiler) to compare the two. That would help to identify the objects that are filling things up.
There was some cleanup work in 1.8.5.1 which greatly improved performance (load time) of the public/protected project permissions. We haven't seen any downsides to it, but it could be that something is unique in your configuration that is exposing an issue. Sometimes making one thing faster, adds stress somewhere else.
Do you have tools to do a heap dump comparison?
Tim
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CADVL1QxypYpkK5iLRCPfxLWPUeP5Bq%2B1TukH%2BKN3Dgc0KrJUkQ%40mail.gmail.com.
Ben Wagner
Sep 30, 2022, 1:18:09 PM9/30/22
to xnat_di...@googlegroups.com
Hi Tim,
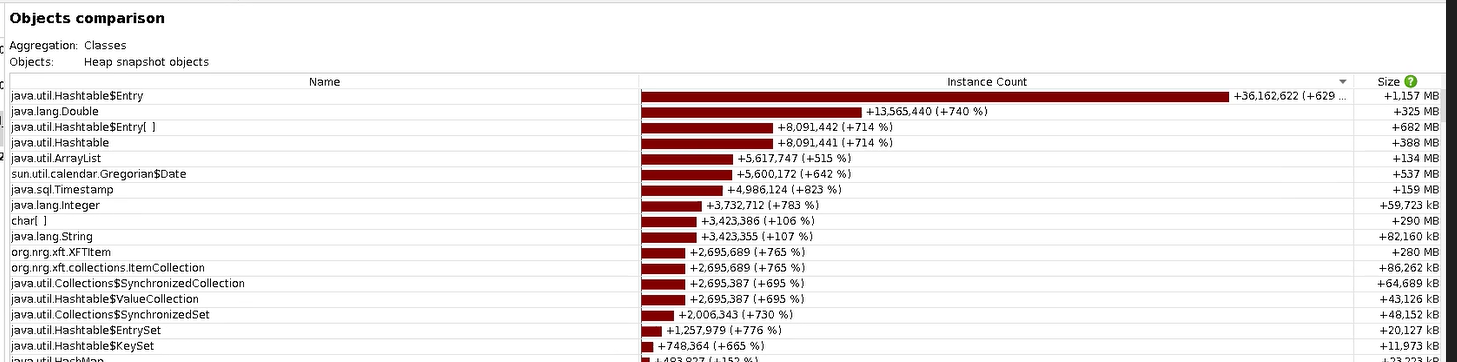
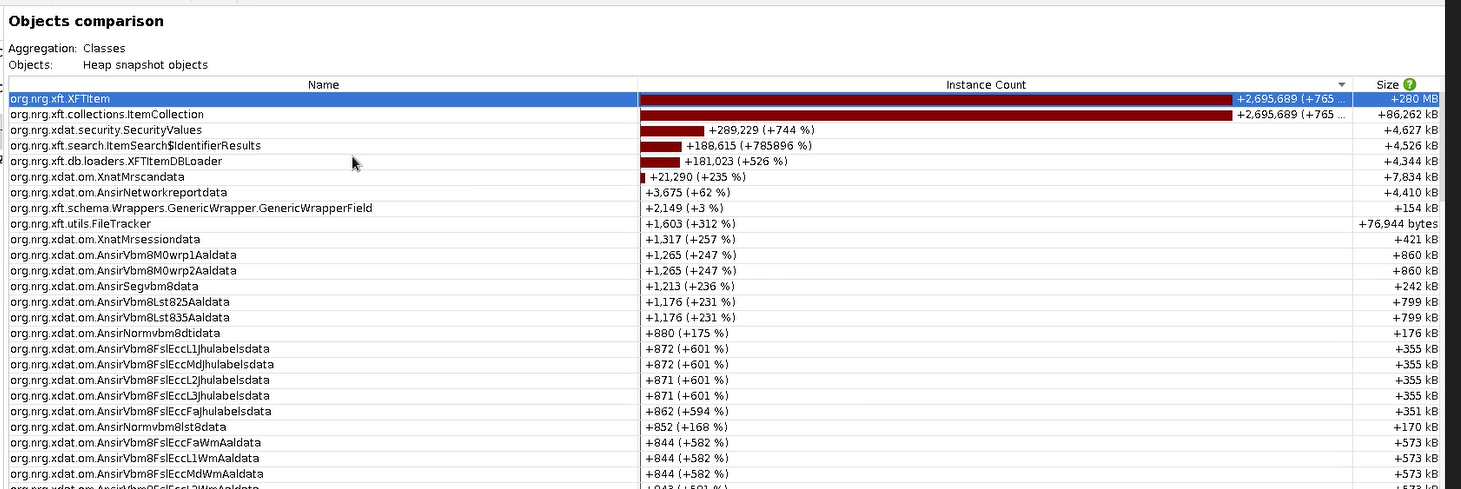
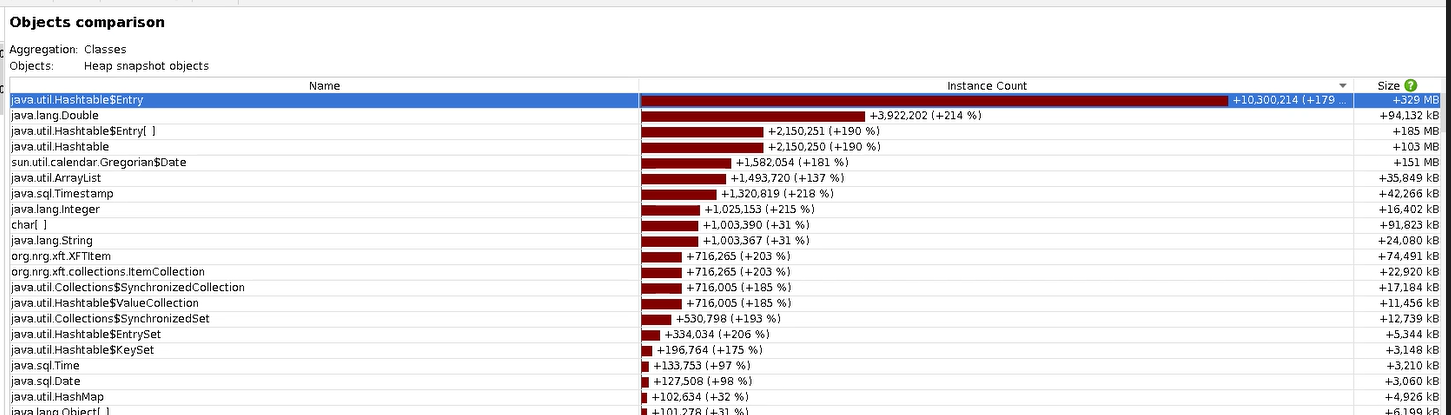
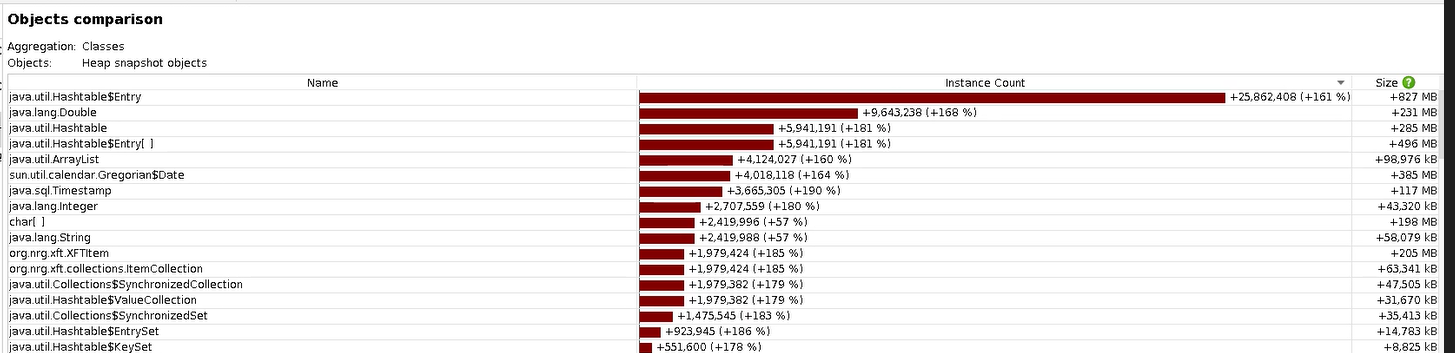
I captured heap dumps at 4, 9 and 20 minutes into 1.8.5.1 running. Using JProfier these are the differences.
This is the difference between the 4 and 20.
Then limited to org.nrg items.
Then just to round things out: 4 to 9 minutes.
And 9 to 20 minutes:
The most that happened on this instance was I logged in to confirm it was 1.8.5.1. I didn't go looking through items.There were also some calls to the JavaMelody monitoring page.All in all, it's usage just exploded.
Let me know if you want the CSV data from the diffs. Hopefully this is helpful.
Ben
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CAH9skcRVRBn6v%3DZ1WdkHj647xzfN4vsgsYx6E0ijYiGPC8Savg%40mail.gmail.com.
John Flavin
Sep 30, 2022, 2:55:55 PM9/30/22
to xnat_di...@googlegroups.com
Ben,
We have formed a hypothesis about what could be happening. We have a couple things we ask you to check which could support or falsify that hypothesis.
Can you run this database query and tell us what status you get?
select status from wrk_workflowdata where pipeline_name = 'Unshare orphaned scans';
As a secondary check, do you see any warning logs in
tasks.log with messages like Shared scan cleanup running on project?To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CADVL1QxfDXA1Uxh9u%2BQRfqH3YueZxRmtUMqyHdEyxoooR-LdCw%40mail.gmail.com.
Ben Wagner
Sep 30, 2022, 3:21:52 PM9/30/22
to xnat_di...@googlegroups.com
Hi John,
I'm getting 0 rows for the SQL query. For the tasks.log there are several likes like this:
2022-09-28 13:41:33,993 [pool-2-thread-1] WARN org.nrg.xnat.initialization.tasks.SharedScanCleanup - Shared scan cleanup running on project CFP
Ben
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CAET4zqcBk3zgNTEO8V2SSJg76SgSK5Bvzo7fOaiu2LMuaorigA%40mail.gmail.com.
John Flavin
Sep 30, 2022, 3:33:52 PM9/30/22
to xnat_di...@googlegroups.com
Ok, thanks. That does provide some supporting evidence for the hypothesis.
If our hypothesis is correct, we should be able to work around the problem you're seeing while we work on fixing the underlying issue. Can you try running this in your database:
insert into wrk_workflowdata values (null,null,null,'Cleanup',null,null,'WEB_SERVICE','DATA','site','ADMIN',null,'ADMIN',null,null,'Complete',null,'Unshare orphaned scans',null,null,CURRENT_TIMESTAMP,null,null,null,DEFAULT);
and then restarting tomcat?
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CADVL1QxooObozhD%3D1KXHjDZy7V0MvPxn_Cwq99Tvx-fJcdRiWQ%40mail.gmail.com.
Ben Wagner
Sep 30, 2022, 3:43:28 PM9/30/22
to xnat_di...@googlegroups.com
Hmm, seem to have some column differences:
xnat_external=# insert into wrk_workflowdata values (null,null,null,'Cleanup',null,null,'WEB_SERVICE','DATA','site','ADMIN',null,'ADMIN',null,null,'Complete',null,'Unshare orphaned scans',null,null,CURRENT_TIMESTAMP,null,null,null,DEFAULT);
ERROR: invalid input syntax for integer: "Complete"
LINE 1: ...ICE','DATA','site','ADMIN',null,'ADMIN',null,null,'Complete'...
ERROR: invalid input syntax for integer: "Complete"
LINE 1: ...ICE','DATA','site','ADMIN',null,'ADMIN',null,null,'Complete'...
xnat_external=# \d wrk_workflowdata
Table "public.wrk_workflowdata"
Column | Type | Collation | Nullable | Default
----------------------------------------------------------+-----------------------------+-----------+----------+---------------------------------------------------------------
executionenvironment_wrk_abstractexecutionenvironment_id | integer | | |
data_type | character varying(255) | | not null |
id | character varying(255) | | not null |
externalid | character varying(255) | | |
current_step_launch_time | timestamp without time zone | | |
current_step_id | character varying(255) | | |
status | character varying(255) | | not null |
pipeline_name | character varying(255) | | not null |
next_step_id | character varying(255) | | |
step_description | character varying(255) | | |
launch_time | timestamp without time zone | | not null |
percentagecomplete | character varying(255) | | |
jobid | character varying(255) | | |
workflowdata_info | integer | | |
wrk_workflowdata_id | integer | | not null | nextval('wrk_workflowdata_wrk_workflowdata_id_seq'::regclass)
comments | text | | |
details | text | | |
justification | text | | |
description | character varying(255) | | |
src | character varying(255) | | |
type | character varying(255) | | |
category | character varying(255) | | |
create_user | character varying(255) | | |
scan_id | character varying(255) | | |
Indexes:
"wrk_workflowdata_pkey" PRIMARY KEY, btree (wrk_workflowdata_id)
"wrk_workflowdata_u_true" UNIQUE CONSTRAINT, btree (id, scan_id, pipeline_name, launch_time)
"wrk_workflowdata_executionenvironment_wrk_abstractexecuti1" btree (executionenvironment_wrk_abstractexecutionenvironment_id)
"wrk_workflowdata_executionenvironment_wrk_abstractexecuti1_hash" hash (executionenvironment_wrk_abstractexecutionenvironment_id)
"wrk_workflowdata_workflowdata_info1" btree (workflowdata_info)
"wrk_workflowdata_workflowdata_info1_hash" hash (workflowdata_info)
"wrk_workflowdata_wrk_workflowdata_id1_hash" hash (wrk_workflowdata_id)
Foreign-key constraints:
"wrk_workflowdata_executionenvironment_wrk_abstractexecutio_fkey" FOREIGN KEY (executionenvironment_wrk_abstractexecutionenvironment_id) REFERENCES wrk_abstractexecutionenvironment(wrk_abstractexecutionenvironment_id) ON UPDATE CASCADE ON DELETE SET NULL
"wrk_workflowdata_workflowdata_info_fkey" FOREIGN KEY (workflowdata_info) REFERENCES wrk_workflowdata_meta_data(meta_data_id) ON UPDATE CASCADE ON DELETE SET NULL
Triggers:
a_u_wrk_workflowdata AFTER DELETE OR UPDATE ON wrk_workflowdata FOR EACH ROW EXECUTE PROCEDURE after_update_wrk_workflowdata()
Table "public.wrk_workflowdata"
Column | Type | Collation | Nullable | Default
----------------------------------------------------------+-----------------------------+-----------+----------+---------------------------------------------------------------
executionenvironment_wrk_abstractexecutionenvironment_id | integer | | |
data_type | character varying(255) | | not null |
id | character varying(255) | | not null |
externalid | character varying(255) | | |
current_step_launch_time | timestamp without time zone | | |
current_step_id | character varying(255) | | |
status | character varying(255) | | not null |
pipeline_name | character varying(255) | | not null |
next_step_id | character varying(255) | | |
step_description | character varying(255) | | |
launch_time | timestamp without time zone | | not null |
percentagecomplete | character varying(255) | | |
jobid | character varying(255) | | |
workflowdata_info | integer | | |
wrk_workflowdata_id | integer | | not null | nextval('wrk_workflowdata_wrk_workflowdata_id_seq'::regclass)
comments | text | | |
details | text | | |
justification | text | | |
description | character varying(255) | | |
src | character varying(255) | | |
type | character varying(255) | | |
category | character varying(255) | | |
create_user | character varying(255) | | |
scan_id | character varying(255) | | |
Indexes:
"wrk_workflowdata_pkey" PRIMARY KEY, btree (wrk_workflowdata_id)
"wrk_workflowdata_u_true" UNIQUE CONSTRAINT, btree (id, scan_id, pipeline_name, launch_time)
"wrk_workflowdata_executionenvironment_wrk_abstractexecuti1" btree (executionenvironment_wrk_abstractexecutionenvironment_id)
"wrk_workflowdata_executionenvironment_wrk_abstractexecuti1_hash" hash (executionenvironment_wrk_abstractexecutionenvironment_id)
"wrk_workflowdata_workflowdata_info1" btree (workflowdata_info)
"wrk_workflowdata_workflowdata_info1_hash" hash (workflowdata_info)
"wrk_workflowdata_wrk_workflowdata_id1_hash" hash (wrk_workflowdata_id)
Foreign-key constraints:
"wrk_workflowdata_executionenvironment_wrk_abstractexecutio_fkey" FOREIGN KEY (executionenvironment_wrk_abstractexecutionenvironment_id) REFERENCES wrk_abstractexecutionenvironment(wrk_abstractexecutionenvironment_id) ON UPDATE CASCADE ON DELETE SET NULL
"wrk_workflowdata_workflowdata_info_fkey" FOREIGN KEY (workflowdata_info) REFERENCES wrk_workflowdata_meta_data(meta_data_id) ON UPDATE CASCADE ON DELETE SET NULL
Triggers:
a_u_wrk_workflowdata AFTER DELETE OR UPDATE ON wrk_workflowdata FOR EACH ROW EXECUTE PROCEDURE after_update_wrk_workflowdata()
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CAET4zqctqdOTE4x3rDiYbNTM39RFxAm_%2BJxAsBRZjoUOk4MB9g%40mail.gmail.com.
Rick Herrick
Sep 30, 2022, 5:06:33 PM9/30/22
to xnat_di...@googlegroups.com
Try this instead:
INSERT INTO public.wrk_workflowdata (justification, type, category, data_type, id, externalid, status, pipeline_name, launch_time)
VALUES ('Cleanup', 'WEB_SERVICE', 'DATA', 'site', 'ADMIN', 'ADMIN', 'Complete', 'Unshare orphaned scans', now());
------ Original Message ------
From "Ben Wagner" <thewa...@gmail.com>
Date 9/30/2022 2:43:07 PM
Subject Re: Re[4]: [XNAT Discussion] XNAT keeps stalling
Hi Tim,Send me a location off list, and I'll drop the plugins there. They're not closed source, but I don't want them in the wild either. 😉
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CADVL1Qxhym-2GXH6oN5ny7d9cW_p-hc%3DDyk3%2BMjYQkeNo2ov9w%40mail.gmail.com.
Ben Wagner
Sep 30, 2022, 6:48:49 PM9/30/22
to xnat_di...@googlegroups.com
Hour 30 in and this is looking promising. What is this magic?
Ben
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/em4b5b2e6c-900e-4454-9a82-bbe49c26f8af%40f59c2279.com.
Tim Olsen
Oct 1, 2022, 10:17:21 AM10/1/22
to xnat_di...@googlegroups.com
There is a process that starts up in 1.8.5.1 that checks a configuration on all the scans in the database to confirm they don't have an issue from a prior bug (a rare case involving scans which were shared into a project and then removed, still showing up in the shared project). It only runs once, and won't run again once that workflow entry exists as 'complete'. It appears it's storing too much in memory which will cause issues like you are seeing on larger instances. Adding the workflow entry manually allows the job to be skipped.
We'll need to change the code to have it do the check in a more memory-friendly way. We'll have it out within a few days. In the meantime, you should be fine to run with that configuration.
Tim
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CADVL1QyEA%2BLKd_fGjUENv5fRaRg2U9Hh9ChrXnPbF64tW%2Bg8cw%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages