anonymising UIDs
314 views
Skip to first unread message

angel.m...@gmail.com
Dec 19, 2021, 10:35:58 PM12/19/21
to xnat_discussion
Hi all, I'm writing an anonymisation script and I want to anonymise UIDs whilst keeping them consistent. This is important because we are hosting DICOM RT datasets where UIDs are referenced to maintain relationships between images of different types (eg RTStruct and CT images). From reading the docs it looks like there are two possible ways of doing this at present.
1) use the hashUID function so that UIDs are changed but consistency is maintained. Problem: It uses sha1 which is not secure.
2) create new random UIDs but then explicitly specify in the script everywhere that the value might need to be replaced with this same ID. I think I would use mapReferencedUIDs[prefix, tagpath-1, tagpath-2, ...] to do this. Description: "Replace the value at all occurrences of the provided tagpaths with a new value composed of the prefix." Problem: This will not always work because referenced IDs will often be in a sequence and the same tag value for different UIDs. For example UIDs from a CT image set will be referenced in a structure set in a Contour Image Sequence that will have an item for each CT image and the tag reference for the UID will be the same ((0008,1155) Referenced SOP Instance UID) for each item.
I'm wondering
- Is this something other people have dealt with?
- How did you handle it?
thanks
Angel

Moore, Charlie
Dec 20, 2021, 11:21:43 AM12/20/21
to xnat_di...@googlegroups.com
Hi Angel,
Sure, SHA-1 is not secure for hashing passwords, but why is that a problem here? For cryptographic hash functions, SHA-1 is no longer secure because you can produce collisions giving the same hash, but anonymization doesn't really care about collision attacks.
The only thing that really matters for it is reversibility, which isn't possible, right?
As for your second point, that function is for letting DicomEdit hash the UIDs for you, not for overwriting UIDs with your own. I think it avoids the problem you're mentioning if I understand you correctly. Here's an example:
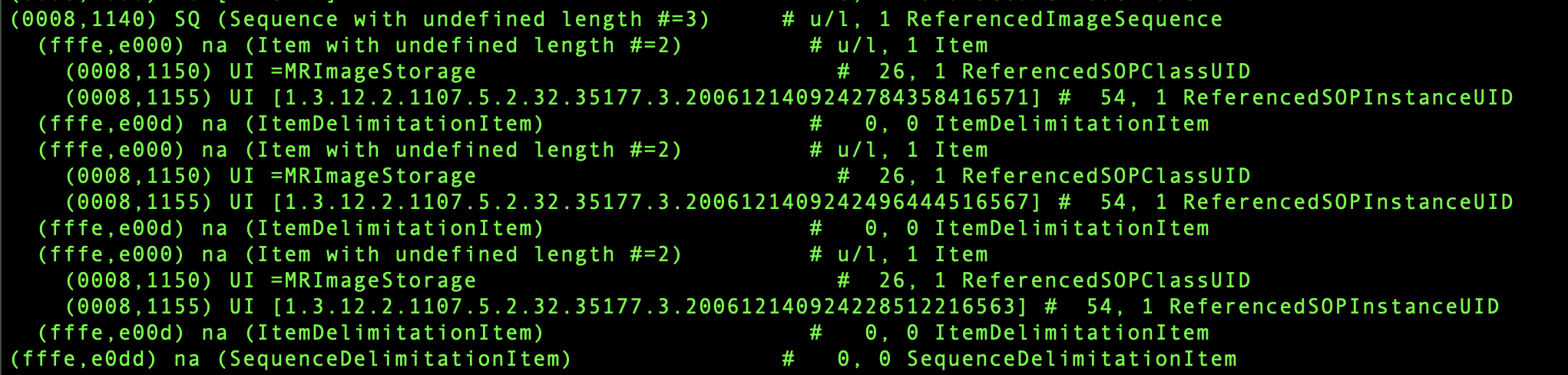
All three UID references are under (0008,1140) > (0008,1155), just on different sequence items. If I run this through the DE6 anon script:
---
version "6.3"
mapReferencedUIDs["9.9.9", "(0008,1140)/(0008,1155)"]
mapReferencedUIDs["9.9.9", "(0008,1140)/(0008,1155)"]
---
Then my final result looks like this:
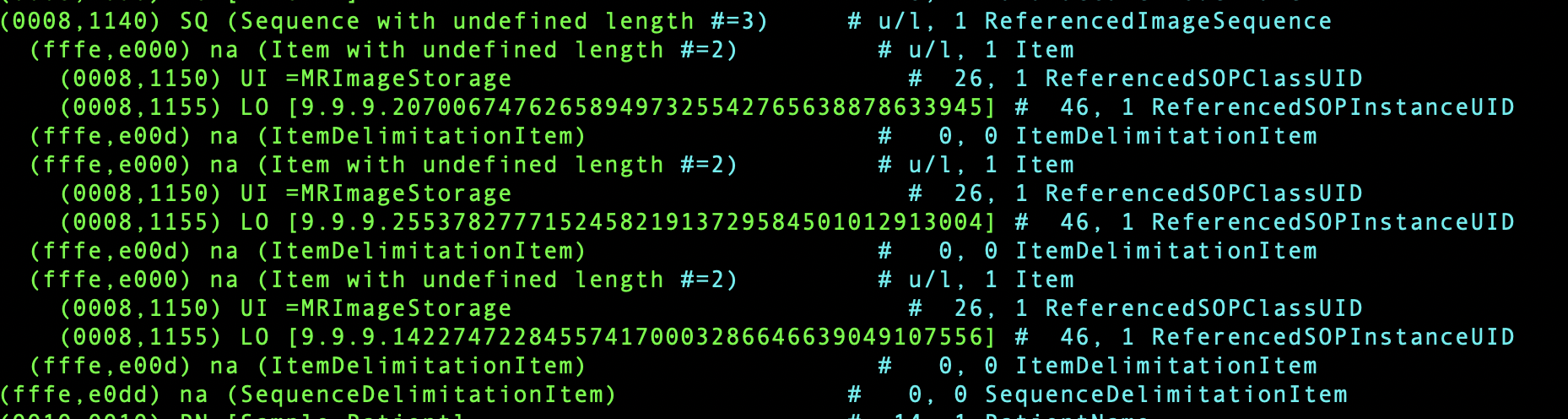
The hashed UIDs are all still unique. Was that your concern, or did I just misunderstand what you meant?
Thanks,
Charlie
From: xnat_di...@googlegroups.com <xnat_di...@googlegroups.com> on behalf of angel.m...@gmail.com <angel.m...@gmail.com>
Sent: Sunday, December 19, 2021 9:35 PM
To: xnat_discussion <xnat_di...@googlegroups.com>
Subject: [XNAT Discussion] anonymising UIDs
Sent: Sunday, December 19, 2021 9:35 PM
To: xnat_discussion <xnat_di...@googlegroups.com>
Subject: [XNAT Discussion] anonymising UIDs
|
* External Email - Caution * |
--
You received this message because you are subscribed to the Google Groups "xnat_discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to xnat_discussi...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/362c68e4-ce90-4f73-999f-19b00415e1e1n%40googlegroups.com.
You received this message because you are subscribed to the Google Groups "xnat_discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to xnat_discussi...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/362c68e4-ce90-4f73-999f-19b00415e1e1n%40googlegroups.com.
The materials in this message are private and may contain Protected Healthcare Information or other information of a sensitive nature. If you are not the intended recipient, be advised that any unauthorized use, disclosure, copying or the taking of any action in reliance on the contents of this information is strictly prohibited. If you have received this email in error, please immediately notify the sender via telephone or return mail.

Jacob Lee
Dec 20, 2021, 12:02:39 PM12/20/21
to xnat_di...@googlegroups.com
Might consider the approach used by NDA, described here:
https://academic.oup.com/jamia/article/17/6/689/843868
Jacobhttps://academic.oup.com/jamia/article/17/6/689/843868
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CH2PR02MB6710C4DA14D6EF8DB6511548FE7B9%40CH2PR02MB6710.namprd02.prod.outlook.com.
Angel Kennedy
Dec 20, 2021, 7:35:06 PM12/20/21
to xnat_di...@googlegroups.com
Thanks Charlie, I was aware that if I use the hashing function then referenced UIDs would continue to match the UID of the object being referenced but I was concerned about the possibility of the original UID being discovered if SHA1 is insecure. I'd misunderstood the weakness of SHA1. It looks like this will be fine for us because as you say the main concern is with collisions and the chance of collisions is low enough that it's extremely unlikely to cause collisions within a dataset.
regards
Angel
To view this discussion on the web visit https://groups.google.com/d/msgid/xnat_discussion/CH2PR02MB6710C4DA14D6EF8DB6511548FE7B9%40CH2PR02MB6710.namprd02.prod.outlook.com.
Reply all
Reply to author
Forward
0 new messages