wxXmlDocument case sensitivity problem (Issue #23026)

Pascal Van Puymbroeck
In Europe we have VIES. A service of the European Union to check given VAT numbers to validate and in return you get the companies name and address. The returning data is an XML form in UTF-8 encoding. Up till now it works, however I encountered a company which has a capital E with ¨ (two dots) on top of it. Clearly a multibyte character, I believe a xC9 in notepad++.
So I use the statements:
if (wxFileExists(sXmlReply)) { XmlDoc.Load(sXmlReply,"UTF-8"); if ( XmlDoc.IsOk() ) {
The file exists, it has been received and is viewable in notepad++. However the XmlDoc.Load fails.
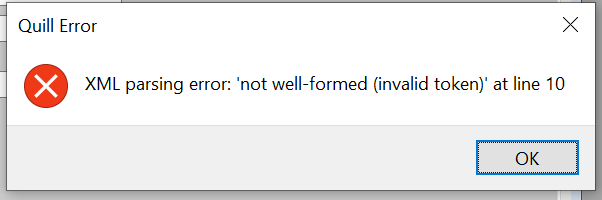
Clearly the location of that special char E. After some testing I found that the problem lies within the encoding, more precisely the case sensitivity of the xml parser on part of determining the encoding. The original file received had a line like:
And the error occurs. Now the moment I changed it into
The XmlDoc.Load method works again.
Now should that line not be parsed without case sensitivity ?
Important information:
WinPro 10 21H2 120.2212.4180.0
Microsoft Visual Studio Community edition 2017 v15.9.50
WxWidgets 3.1.4
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
oneeyeman1
@Softsuit ,
How did you build the library? CVan you reproduce it in a sample provided?
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
VZ
I can't reproduce the problem with the attached XML file, even if I change "UTF-8" to "utf-8" in it, however I suspect you've actually changed it while saving because it contains a U+FFFD, i.e. the "replacement character" in the line
<ns2:name>BV OROS�Y</ns2:name>
and not Ë (U+00CB) or anything like this.
I am also almost certain that the problem has nothing to do with "UTF-8" vs "utf-8", which are both definitely accepted, but it might be due to using decomposed form of this character. However it's really difficult to say without actually having the file that fails to load.
Also, please update to wx 3.2.1. It won't change anything for this problem, but it contains many other bug fixes and there is no reason to use 3.1.4 instead of it.
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
Pascal Van Puymbroeck
I didn't build the library. I simply downloaded the prebuilt VS2017 version.
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
Pascal Van Puymbroeck
I did add a zipfile containing the xml because xml on its own was not supported here to be uploaded. ONreply.zip
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
Pascal Van Puymbroeck
I see what you mean with the file being altered. I receive it over a SOAP protocol with the Chilkat library and write it with the wxFile class to the File ONreply.xml which is then loaded by the wxXmlDocument class.
ccReq.put_HttpVerb("POST"); ccReq.put_SendCharset(false); ccReq.put_ContentType("text/xml"); ccReq.put_Path("/taxation_customs/vies/services/checkVatService"); ccReq.LoadBodyFromFile(sXmlRequest); hResponse = ccHttp.SynchronousRequest("ec.europa.eu",80,false,ccReq); if (hResponse == 0) { Tell("Request error",ccHttp.lastErrorText()); bOk = false; } else { ccXmlResponse.LoadXml(hResponse->bodyStr()); this->pcResult = ccXmlResponse.getXml(); sXmlReply = wxString::Format("%s\\ImpExp\\%s",rApp.pPrefs->GetStartDir(),ONR::REPLYFILE); bOk = hFile.Create(sXmlReply,true); if (bOk) { nBytesWritten = hFile.Write(this->pcResult,strlen(this->pcResult)); hFile.Close();
I'll focus on this to fix the problem.
However, remains the fact that when I alter the the first line of the file from "utf-8" to "UTF-8" I don't get an error and that question mark character appears in my dialog textfield.
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
VZ
My point is that I think you've fixed UTF-8 encoding problem when you saved the file to save your changes from your editor and that any other change (or even absence of changes) would have fixed it too.
Anyhow, the important thing is that we still don't have the file with which you had the problem originally: the file in the ZIP has "UTF-8" so it's not the original file, according to your own description. Please provide the original file you have had the problem with, and not the file edited by you which is not very useful.
P.S. Please note that you need to use triple backticks around code ("fenced") blocks in Markdown, I've edited your comment to make the code in it readable, which wasn't originally the case.
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
github-actions[bot]
This issue has been automatically closed because there has been no response to our request for more information from the original author since 100 days and we're unable to do anything about the problem without more information. Please comment on this issue if you can provide any additional data so that we could investigate it further.
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
github-actions[bot]
Closed #23026 as completed.
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()