ORM (?) : A Revisit, NOT a Rebuttal

Arnon Marcus

Niphlod
From the "technical" standpoint I love (being more a sql guy than a python one) to avoid defining a class when what I know that what I want is a table.
That's more or less the (well specified) difference between an "expression layer" and an "object mapper".
That comes probably because I know already how to design the tables beforehand, having planned the requirements. Elaborating on this, I see a lot of users that are probably "less expert" on the db side that entangle themselves on a really hard "model mapping" and have, in my POV, crazy "query requirements" to fetch some rowset they need. I hardly fall into that situation, so I guess my understanding and "expertise" help me plan beforehand a good "environment" to play with DAL.
That being said, doing a db.define_table() and a class Whatever(model) isn't that much different in terms of what you gain access to.....
db.table has 'fields', every field has its sets of attribute (default, requires, update, type, etc etc etc).
For references, you know already that every single column of a row holds a pointer to the referenced row....
As for "mixins", web2py has table inheritance ....
I guess all that comes up in term of differences is merely technicalities.... as far as my projects went, I rarely had the need to define "real python classes" to interact with "my mind model"....
Doing Record.find(1) is not that different from db.record(1) as far as I'm concerned, and I have a lot more control on what an hypotetical Record.save() does with record.update_record() as far as db queries are concerned (ok, I know that an "expression layer", having a "layer less", helps retaining control on what is happening between your models and your db, but that's why I like it :-) ) .
From the moment callbacks were put in trunk (and I will be thankful until I die for those :-P) I couldn't find anything that can be done with an ORM that is not easily replicable with DAL.
From DAL to SQLA there are of course many differences, but DAL tries to expose the 95% of the features with an homogeneous API. SQLA is more "flexible" but every adapter has its set of features that closely builds on the backend available features.
The only thing I miss from SQLA is the wonderful "session". I guess in your post is described in the lines
It should also facilitate performance-optimizations, by way of a transactionally-aggregating queries and updates/inserts automatically.
What do you miss, specifically, from the DAL standpoint ?

Massimo Di Pierro
Arnon Marcus
What do you miss, specifically, from the DAL standpoint ?
Arnon Marcus
Niphlod
Without you providing an api that you may expect web2py can't figure out your business requirements, and surely you can't expect anyone to code something on top of your ideas without providing a consistent use-case that definitely benefits of an ORM on top of the DAL.
Additionally, there are performance issues that a well-designed ORM can solve - but that may have more to do with the implementation of Units-Of-Work in SQLA more than an ORM, however I still believe that using an ORM model, can help a lot in defining clusters of operations - that would then be ordered and aggregated into a transaction. It may provide orders-of-magnitude of better performance in some cases, and may be the only way out of the N+1 problem.
DAL does everything in one transaction (db transaction) always. If you're referring to some custom pattern as (pseudo-code)
record = Record(1)
record.ordered_items = 1
....
record.ordered_items +=1
record.save()
ending up in a "update record set ordered_items = 2 where id=1"
the same exact thing gets done by
record = db.record(1)
record.ordered_items = 1
.....
record.ordered_items +=1
record.update_record()
by the DAL.
If instead you're talking about DAL "optimizing" whatever you do to the minimum required number of queries...well, that goes very far along the way of AI, e.g.
db(db.record.id == 1).update(ordered_items=1)
....
db(db.record.id == 1).update(ordered_items=2)
....
db(db.record.id == 1).delete()
ending up in "delete from record where id = 1".
DAL issues the queries you instruct in your code: it doesn't force you to use them.
ORMs on the other hand are a little bit more "obscure" in terms of "what will happen when I choose to alter this object".
ORMs can do that kind of "optimization" (up to a certain point) but please note that you're asking the code to be smarter than you.
For example, in one of the threads I read, Massimo gave an example of how an ORM can be emulated using the DAL. This example included a db-query inside a nested for-loop...Now, we recently did a massive profiling of our application, and guess where we found the bottlenecks...This leads me to the subject of hierarchies: Sometimes, there is no way to model a query that scans a tree of records, without resorting to this kind of awful approach... This is a real problem.
Anyways, I can elaborate more on my use-case if you think I should, but I think you get the idea...Basically we are talking about a tree of "production-items", that relate to a table of budget-items, but also that each node in the item-hierarchy has it's own tree of "tasks", and each task has it's own tree of "comments" for collaborative messaging. Additionally, each task may have a tree of file-records representing a CMS of versions of files that are used in the process of executing that task. then there's a status-matrix for representing task-status's pipeline-process...I really don't know how far I should get with this description, but you may get the point - it's a huge tree-of-trees... The most horrible data-model for a relational-database, and one that can benefit a lot from an ORM.I was thinking about moving that data into an ODB such as ZODB, but I still want the data to be stored in the same Postgres DB, in the back-end - so THERE I though I could use an ORM ontop of the DAL, as an adapter for a ZODB back-end...But that was a wild idea - I would much rather solve everything within web2py, and there also, an ORM could really help...
The fact that your model doesn't fit a tabular storage doesn't really matter in "DAL vs ORM" ways of coding such a thing, performance-wise... you have to fetch the data either way, and that's the bottleneck. If your bottleneck is the code to fetch the data, then it will take surely less time with the DAL than with an ORM (given the head-start of having a layer less).
As of choosing the right model to store hierarchies in a database, ink has been wasted on books and blood on posts around the web.... but that deserves another thread alltogether ^_^
<offtopic>
Please note that I'm not saying that DAL fits the bills always: SQLA is by far the most complete "db integration on python" and, from a lot of perspective, may be one of the most mature out there also not "restricting" the perspective to python. Those are piece of code optimized over the years by loads of peoples.
E.g., if I were to manage a database only with a python module, one of the major shortcomings of DAL vs SQLA are:
- no indexes in models
- flaky "schema" support
- no full support for non integer pk
- no full support for multiple-columns pk
Now, if you're talking about those requirements, ok, maybe we need more features in DAL.... but those doesn't "count" for requiring an ORM on top of DAL.
As far as framework goes, a little "dose" of assumptions are meant to be made to make the code less overbloated.... "requiring" every table to have an integer pk is somewhat recommended in every SQL book out there.
Pun intended: I'm assuming nobody creating something has a problem with having column names without spaces, even if they are a possibility in every database engine.
</offtopic>
Arnon Marcus
Arnon Marcus
even with an ORM your code wouldn't be as neat as you might think.
If instead you're talking about DAL "optimizing" whatever you do to the minimum required number of queries..
ORMs on the other hand are a little bit more "obscure" in terms of "what will happen when I choose to alter this object".
ORMs can do that kind of "optimization" (up to a certain point) but please note that you're asking the code to be smarter than you.
Niphlod
On Sunday, April 28, 2013 1:00:17 AM UTC+2, Arnon Marcus wrote:
even with an ORM your code wouldn't be as neat as you might think.Well, SQLA has this cool feature called "relationships", which basically lets you define bidirectional relationships between ORM classes. After you define it, there are events that will take care of updating the relationships for added/removes records for all direction in all relationships defined:* Time-coded link : watch about 7 minutes...p.s: This can also facilitate the build-up and maintenance of tree-structures.
And where did you see a lack in functionality using DAL callbacks ?
But I think the main issue here is different, though - it may have to do with web2py's execution-model - having it "execute" everything for each request - so there is nothing being saved across-requests...However, "modules" are not automatically-reloaded, and it is actually in THIS place where I would expect to put my ORM... This is in fact the main issue that is not considered in web2py...
If instead you're talking about DAL "optimizing" whatever you do to the minimum required number of queries..Hmmm, well, then what would you call SQLA's "eager-loading", then?* Time-coded link - watch about 10-15 minutes from that point
ORMs on the other hand are a little bit more "obscure" in terms of "what will happen when I choose to alter this object".Are they? Really?:* Time-coded link : watch about 2 minutes
ORMs can do that kind of "optimization" (up to a certain point) but please note that you're asking the code to be smarter than you.How about SQLA's lazy-loading?* Time-coded link :watch 1 minute
Same thing as before. You have to tell it upfront, and it's not different from planning what to do with one/two/n DAL queries.
Arnon Marcus
And where did you see a lack in functionality using DAL callbacks ?
Just because the scaffolding app doesn't have any module in it? I use modules all the times if I don't want to reload the code at every request, that's why they are available.
That's just avoiding recursive queries. Again, SQLA doesn't figure out it for you, you have to instruct it to be "eager" upfront. At that point, you can instruct DAL to be eager too with joins.
Yep, really. Whenever I use db(query).select(), .update(), .delete() I know that a query is fired (sort of "explicit is better than implicit"). If I use SQLA I have to remember how the particular model was coded (and optionally do some debugging) to see what's going on under the hood. Please note that this is expected: you want an ORM to have another layer of abstraction on top of database operation, so by default is more implicit.
Same thing as before. You have to tell it upfront, and it's not different from planning what to do with one/two/n DAL queries.
Niphlod
On Sunday, April 28, 2013 8:41:46 PM UTC+2, Arnon Marcus wrote:
And where did you see a lack in functionality using DAL callbacks ?
I am not that familiar with them, honestly.
As I said - It may seem as though I am saying that web2py currently can-not accomplish this - what htis actually means, is that "I don't know of ways in which web2py can accomplish this"
I would be more than happy to find out that I am wrong! :)How can DAL-callbacks be used to emulate this?
Can they auto-infer relationships bi-direction ally from the schema, and supply event-listeners for each end of a each multi-target relationship?
How would I factor such a mechanism into my own classes to link them up?
they don't build up magically by default (though the cascade parameter allows the same flexibility as the one present in your backend) but given that all the six "important" events are available and fired accordingly, you can hook up whatever business logic you like.
Just because the scaffolding app doesn't have any module in it? I use modules all the times if I don't want to reload the code at every request, that's why they are available.
I said that most of our code is in custom-modules, so obviously I know that web2py "supports" this.
What I meant by that, is that it seems as though due to the fact that web2py "executes" the models, and so has implicit-session-management going on on the DAL, it "assumes" a "data-model-session" by default. So, the characteristics and features of the DAL are (obviously) targeted at supporting this mechanism. All other frameworks do not execute the models on each request. You may write a reload(), but that's your business So, SQLA is designed to support this execution model, which is why it has to provide all these wild connection-sessions, transactions, and table-cache-invalidation mechanisms with expiration, dirty-checkings and the like...
Web2py took advantage of it's execution to basically allow itself to completely avoid any of these stuff.
So, if you want to implement a data-model using the DAL "within a non-executed/non-reloaded custom-module", than you are basically on your own for implementing all these crazy bb-sessions and the like.
This is why it seems so odd for web2py users to grasp this notion of an ORM, as it is basically assuming a totally-different execution model for the db-models, compared to how it is currently built in web2py.It is like the different between a statefull system, and a stateless one.SQLA is built for statefull applications.Web2py's DAL is built for stateless ones.It's a very different paradigm, with a different way of thinking.And because of that, it is so wired to try to think about an ORM in web2py, especially if it is going to sit in a "statefull module".
Perhaps I am missing something here, but this is how I currently understand things.
HTTP is (ATM) a stateless world. Yep, cookies are used to store something from different requests, but that's business logic of your app, not a database concern.
Even with SQLA you DON'T want to "keep alive" a session between multiple requests, as you can very easily end up in lockings.
That's just avoiding recursive queries. Again, SQLA doesn't figure out it for you, you have to instruct it to be "eager" upfront. At that point, you can instruct DAL to be eager too with joins.
Obviously, but that's not the point - we are talking about "tools for automating abstractions". He did not write the join himself there...The eager-loading system figured out by itself which joins it should construct in order to eager-load things - all he did is tell the system to do so for that relationship.
And what's different than looping over all the referenced tables and joining them ? Do you really need a 10-lines code snippet to accomplish that in DAL ? This can go in the "please add features to DAL" chapter, as other things mentioned before, but don't really count for an ORM.
Yep, really. Whenever I use db(query).select(), .update(), .delete() I know that a query is fired (sort of "explicit is better than implicit"). If I use SQLA I have to remember how the particular model was coded (and optionally do some debugging) to see what's going on under the hood. Please note that this is expected: you want an ORM to have another layer of abstraction on top of database operation, so by default is more implicit.
No. It's as if you completely missed his point. SQLA's ORM philosophy is different than others. Did you watch the lecture I gave you about that?SQLA is not building your models - you are.SQLA is not "hiding", it is "automating".SQLA is not "obtuse", it is "transparent".SQLA does not lock you into it's defaults - you define it's defaults up-front.
That means exactly what I meant to explain before: you define how it should work beforehand and you need to review the model to understand what is "firing" under the hood.
Same thing as before. You have to tell it upfront, and it's not different from planning what to do with one/two/n DAL queries.
No. It's automatic. You set-up the "relationship" object yourself - yes - but IT figures out whether this is a one-to-many relationship, and to which direction, and constructs an optimized query based on which end of the relationship you are querying. As he said, this is non-trivial in ORMs - Django's ORM (as he alluded...) is NOT doing that...
So, you added a lot of statements and pieces of code in your model to define the relationship, and SQLA replays it figuring out "the most optimized way possible".
My point of "I end up with a nice schema to play with" may be throwing me ahead of road-blocks that you faced, but is it really that difficult to code a relationship and figuring out how to query it ?

Anthony
On Sunday, April 28, 2013 2:41:46 PM UTC-4, Arnon Marcus wrote:
And where did you see a lack in functionality using DAL callbacks ?
I am not that familiar with them, honestly.
As I said - It may seem as though I am saying that web2py currently can-not accomplish this - what this actually means, is that "I don't know of ways in which web2py can accomplish this"
I would be more than happy to find out that I am wrong! :)How can DAL-callbacks be used to emulate this?
Can they auto-infer relationships bi-directionally from the schema, and supply event-listeners for each end of each multi-targetted relationship?
How would I factor such a mechanism into my own classes to link them up?
Just because the scaffolding app doesn't have any module in it? I use modules all the times if I don't want to reload the code at every request, that's why they are available.
I said that most of our code is in custom-modules, so obviously I know that web2py "supports" this.
What I meant by that, is that it seems as though due to the fact that web2py "executes" the models, and so has implicit-session-management going on on the DAL, it "assumes" a "data-model-session" by default. So, the characteristics and features of the DAL are (obviously) targeted at supporting this mechanism. All other frameworks do not execute the models on each request. You may write a reload(), but that's your business So, SQLA is designed to support this execution model, which is why it has to provide all these wild connection-sessions, transactions, and table-cache-invalidation mechanisms with expirations, dirty-checkings and the like...
Web2py took advantage of it's execution to basically allow itself to completely avoid any of these stuff.
So, if you want to implement a data-model using the DAL "within a non-executed/non-reloaded custom-module", than you are basically on your own for implementing all these crazy db-sessions and the like.
This is why it seems so odd for web2py users to grasp this notion of an ORM, as it is basically assuming a totally-different execution model for the db-models, compared to how it is currently built in web2py.It is like the different between a statefull system, and a stateless one.SQLA is built for statefull applications.Web2py's DAL is built for stateless ones.It's a very different paradigm, with a different way of thinking.And because of that, it is so wired to try to think about an ORM in web2py, especially if it is going to sit in a "statefull module".Perhaps I am missing something here, but this is how I currently understand things.
That's just avoiding recursive queries. Again, SQLA doesn't figure out it for you, you have to instruct it to be "eager" upfront. At that point, you can instruct DAL to be eager too with joins.
Obviously, but that's not the point - we are talking about "tools for automating abstractions". He did not write the join himself there...The eager-loading system figured out by itself which joins it should construct in order to eager-load things - all he did is tell the system to do so for that relationship.
Yep, really. Whenever I use db(query).select(), .update(), .delete() I know that a query is fired (sort of "explicit is better than implicit"). If I use SQLA I have to remember how the particular model was coded (and optionally do some debugging) to see what's going on under the hood. Please note that this is expected: you want an ORM to have another layer of abstraction on top of database operation, so by default is more implicit.
No. It's as if you completely missed his point. SQLA's ORM philosophy is different than others. Did you watch the lecture I gave you about that?SQLA is not building your models - you are.SQLA is not "hiding", it is "automating".SQLA is not "obtuse", it is "transparent".SQLA does not lock you into it's defaults - you define it's defaults up-front.
Same thing as before. You have to tell it upfront, and it's not different from planning what to do with one/two/n DAL queries.
Anthony
Arnon Marcus
On Monday, April 29, 2013 3:59:40 AM UTC+3, Anthony wrote:
I think you're arguing against a bit of a straw man here. Past resistance to the idea of an ORM has usually been in the context of suggestions for an ORM instead of a DAL, not as an additional abstraction on top of the DAL for particular use cases. As Massimo noted, there have already been some efforts at the latter, though none generated enough interest to persist. If you can identify a common use case where some kind of abstraction on top of the DAL would make development much easier and/or execution more efficient, and you can clearly articulate the nature of that abstraction, I don't think anyone would object. It might help to see something concrete, though. Let's see an example data model, how it would be easily implemented in SQA or the hypothetical web2py ORM, and how that is a clear improvement over how you would otherwise have to implement it using the DAL
Arnon Marcus
they don't build up magically by default (though the cascade parameter allows the same flexibility as the one present in your backend) but given that all the six "important" events are available and fired accordingly, you can hook up whatever business logic you like.
HTTP is (ATM) a stateless world. Yep, cookies are used to store something from different requests, but that's business logic of your app, not a database concern.
Even with SQLA you DON'T want to "keep alive" a session between multiple requests, as you can very easily end up in lockings.
And what's different than looping over all the referenced tables and joining them ? Do you really need a 10-lines code snippet to accomplish that in DAL ? This can go in the "please add features to DAL" chapter, as other things mentioned before, but don't really count for an ORM.
That means exactly what I meant to explain before: you define how it should work beforehand and you need to review the model to understand what is "firing" under the hood.
So, you added a lot of statements and pieces of code in your model to define the relationship, and SQLA replays it figuring out "the most optimized way possible".
My point of "I end up with a nice schema to play with" may be throwing me ahead of road-blocks that you faced, but is it really that difficult to code a relationship and figuring out how to query it ?
Niphlod
On Monday, April 29, 2013 11:47:41 AM UTC+2, Arnon Marcus wrote:
they don't build up magically by default (though the cascade parameter allows the same flexibility as the one present in your backend) but given that all the six "important" events are available and fired accordingly, you can hook up whatever business logic you like.
That answer is too vague for me... Can you elaborate?What cascade-parameter? What do you mean by "your backend"? What "six important" event?Does this answer my questions?
So, a small recap. Don't take this in the wrong way but:
- I need to watch 2 hours of presentations that you found interesting to be able to reply
- you expect "us" (by us I mean web2py developers) to figure out YOUR business requirement because you liked a presentation about SQLA and you want that feature(s) on top of DAL, without providing your use-case and the possible benefits
- you expect web2py developers to come up with an API that even you can't figure out
- you don't want to raise a finger providing a real usecase scenario cause "you're a user, not a developer"
- you can't take a look at the current DAL implementation to see what are the proposed solutions to your (ATM imaginary) problems
If these are the requirements of your discussion-environment, don't be surprised if nobody provides code for you.
Docs are there. Given that you're using time to look at other python modules/packages, at least be documented on what you want to use as a starting-point (DAL) for comparisons.
Arnon Marcus
--
---
You received this message because you are subscribed to a topic in the Google Groups "web2py-users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/web2py/vyOEkUeCNj4/unsubscribe?hl=en.
To unsubscribe from this group and all its topics, send an email to web2py+un...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.

villas
The fact is that Hierarchical data does not fit at all well into a RDBMS. The main issue is therefore to decide what 'kludge' to use. The best kludge will vary case by case so the ORM would have to be incredibly sophisticated to always choose an optimised kludge without the developer specifying exactly what he wants. I do not know how SQLA achieves this, but I cannot imagine the DAL being developed to cover all cases in the best possible way.
Nevertheless it would indeed be nice to cover at least one common use-case of hierarchical data and I would suggest that someone should propose a specific case. Here is a simple example: geographical areas. I would propose either a nested set (or perhaps simply a materialised path, which I like very much for its simplicity). I think such an example would be very useful.
A few simple functions to manipulate this included in the DAL would be really great. I believe it is only with a specific proposal in mind that this discussion will progress. A theoretical discussion will remain just that and nothing practical will result.
There are truckloads of stuff already written on this topic and I cannot imagine that this thread would add anything new to that.
Arnon Marcus
Arnon Marcus
Anthony
I was disappointed to discover that this example is proorly-formed. The comparison ther, (as well as in other places, like this: http://web2py.com/examples/static/sqla2.html) feels somewhere between ill-informed to disingenuous.
The web2py database Abstraction layer can read most Django models and SQLAlchemy models...This is experimental and needs more testing. This is not recommended nor suggested but it was developed as a convenience tool to port your existing python apps to web2py.
We translated all the examples from the SQLAlchmey tutorial...This is not a feature comparison but more of a legend for new web2py users with SQLAlchemy experience...
villas
Is this thread about...
1. ...storing and manipulating hierarchical trees using the DAL?
If so, please specify an example of your data?
2. ...using the DAL with ORM-like syntax?
If so, it would be interesting to see an example of the syntax you would like. Perhaps the example link provided by Anthony might be a starting point for you?
I suppose an ORM fits better with python objects, but the kludge with the RDBMS does not go away - you simply find it further down the street.
Regards, David
Anthony
If you go through the links I have been pin-pointing here, you would find many concrete examples of data-models and how they are used in SQLA's ORM.
You are basically asking me to get much more proficient in the DAL, as well as in SQLA, and to design the solution myself and present it.
This is a valid expectation in a developers-group, not a users-group. The whole point of sharing ideas and expertise, is that someone can suggest a conceptual/abstract direction, and this entices someone else who is much more proficient, to come-up with a concrete solution.
I am inclined to hoped I would not be needing to become an expert myself, in order to propose an idea for improvement.
Anthony
But what exactly an I expected to propose that would be concrete?
An API?Must I be an API coder in order to propose a feature-set?
And about use-cases - I gave mine, as well as links to others. What else should I do?
Anthony
they don't build up magically by default (though the cascade parameter allows the same flexibility as the one present in your backend) but given that all the six "important" events are available and fired accordingly, you can hook up whatever business logic you like.
That answer is too vague for me... Can you elaborate?What cascade-parameter? What do you mean by "your backend"? What "six important" event?
SQLA's ORM-class-instances are reused across requests.Web2py's DAL instances are not.If I wanted to emulate a SQLA-ORM in web2py, I would have to put it all in custom-modules, that would persist class-instances in memory, and do a lot of these invalidation/dirty-chacking stuff myself. I think a way around this might be to keep the DAL-layer separate, in that instances of ORM-classes may persist in memory across requests in a custom module that is not reloaded, but that they would be dynamically re-linked to DAL instances that would still be re-generated for each request by executing the models as usual.

Cliff Kachinske
Arnon Marcus

Derek
Anthony
<off-topic>Look, I get that in many open-source communities, feature-requests are generally frowned upon. It's like "who this guy thinks he is, telling me what's missing with MY great achievement, hu...?"There is a lot of ego-involved...Sometimes too-much so...
Granted, I don't pay anyone here, so social-legitimacy for requesting "anything" is questionable at-best...But there is a difference between a "request" and a "demand", and a lot of people seem to conflate the two - especially in western-cultures.
But do you really think that there is no place "at all" for feature-requests in FOSS communities? We may be "political" and call them "wish-lists" or "suggestions-for-additions" - that may sound better - but it is still practically the same thing...Someone raises an idea, tries to convince other people that it's cool and shiny, and maybe someone else get's excited about it enough to implement it, and maybe not... But does this make it illegitimate to try?
Arnon Marcus
Massimo Di Pierro
Arnon Marcus

Michele Comitini
--
---
You received this message because you are subscribed to the Google Groups "web2py-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to web2py+un...@googlegroups.com.
Niphlod
Arnon Marcus
The following blog entry shares much of my idea of ORM in real applications with large
My 4 points where I think that DAL can be (and so has to be ;-) ) improved:1. lazy rows being backed by a sql cursor when requested by the user;2. since point 1. is not always the solution, row object instance creation must be way faster;3. a simple way to support db indexes even at a basic level;4. sql view/readonly tables support (this could be related to cacheable tables).
Anthony
Massimo Di Pierro
Michele Comitini
put them on the roadmap ^_^ as for 3. it's just a matter of finding the right syntax for every db engine. I'm not sure about 4., it's available right now with migrate=False ?
Niphlod
or just complain before any insert(), update() is tried on any "read_me_only" fake table (i.e. do those always in a try:except block or do before an "assert is_not_fake" before "write" operations)?
not sure cause I never had that requirement (and I don't have python right now), but wouldn't the same thing being accomplished by writable=False on all columns and using validate_and_update(), validate_and_insert() - as you should if you're unsure about the table model, i.e. you don't know if it's a table or a view ?
I'm a little unsure about the performance penalty on checking this kind of things every time when they can be prevented just knowing that that particular collection of entities is not writable ^_^
PS: some backends allow specially coded views to be updateable and deletable......
Michele Comitini
so just a "read_me_only" kind of check where if you even try to load a record in an edit form web2py complains ?
or just complain before any insert(), update() is tried on any "read_me_only" fake table (i.e. do those always in a try:except block or do before an "assert is_not_fake" before "write" operations)?
not sure cause I never had that requirement (and I don't have python right now), but wouldn't the same thing being accomplished by writable=False on all columns and using validate_and_update(), validate_and_insert() - as you should if you're unsure about the table model, i.e. you don't know if it's a table or a view ?
I'm a little unsure about the performance penalty on checking this kind of things every time when they can be prevented just knowing that that particular collection of entities is not writable ^_^
PS: some backends allow specially coded views to be updateable and deletable.....
On Tuesday, April 30, 2013 5:35:09 PM UTC+2, Michele Comitini wrote:2013/4/30 Niphlod <nip...@gmail.com>put them on the roadmap ^_^ as for 3. it's just a matter of finding the right syntax for every db engine. I'm not sure about 4., it's available right now with migrate=False ?4. migrate False is on the DDL side and you are right about that, but I'd like it also on DML part i.e. in postgresql doing an INSERT on a VIEW is not allowed.
Arnon Marcus
This is nice, but you're still talking about very general features. It would be more helpful if you could explain why we need those features. Perhaps you could show in SQLA how you would specify and interact with a particular data model, and then explain why you think that is better/easier than how you would do it using the DAL.
Anthony
"What are the benefits?" You should ask?
Well, there are performance-improvements with the caching mechanism, and with the aggregation of operations - certain change-operations are only pushed to the transaction-view, when they are actually needed, or at the end of the transaction.
Lastly, the main benefit is automatic-handling of caching and ordering or operations, that the developer no-longer needs to take care of himself.The benefit is not just for simple-data-modes, on the contrary - the more complex the data-mode, the more this becomes beneficial, as the automatic-detection of relationship-dependencies, and auto-cascade of operations, can both save brain-cycles from the developer trying to hold the whole schema in his head and make sure he pushes things in the correct order, and also prevent human-errors that can mess-up the database in cases that constrains are insufficient, and the developer overlooked some relationship-dependencies and was using stale-data without knowing it.
For example, lets take the following code:def setItemName(id, name):row = db.item[id].select()row.update_record(name=name)def getItemByName(name):return db.item(db.item.name==name).select()id = 42...row = db.item[id].select()...
def setItemName(id, 'some other name')....
As you can see, the last function-call would either fail, or silently return something other than what was asked for.
Derek
On Tuesday, April 30, 2013 10:45:04 AM UTC-7, Anthony wrote:
"What are the benefits?" You should ask?Well, there are performance-improvements with the caching mechanism, and with the aggregation of operations - certain change-operations are only pushed to the transaction-view, when they are actually needed, or at the end of the transaction.
I suppose there could be in some cases, but to avoid multiple updates to the same record, you can apply changes to the Row object and then call row.update_record() when finished. On the other hand, there may be cases where you want separate updates in order to trigger separate database triggers or DAL callbacks. Anyway, before investing lots of time building (and subsequently maintaining) a rather sophisticated ORM, it would be nice to know what kind of performance improvements can be expected and in what circumstances. In other words, how often do cases come up where the DAL is much less efficient than SQLA, and how difficult would it be to write equally efficient DAL code in those cases.
Anthony
Arnon Marcus
Arnon Marcus
Arnon Marcus
Massimo Di Pierro
Derek
Anthony
If you take into account what's said in this talk - that basically the ORM and the CORE in SQLA are 2 separate beasts - than if follows what I've been saying here, that the web2py-DAL is equivalent just to the CORE, and has no features that the ORM provides whatsoever.
But it also means something else - that saying that it's benefits are questionable, is akin to saying that a 20k lines-of-code of the coolest ORM in existence, is a useless-piece of software...
Arnon Marcus
Have you not tried just importing sqla in your 0.py model, and writing your models and code as you see fit? You can certainly bypass the DAL if you want.
Arnon Marcus
If you take into account what's said in this talk - that basically the ORM and the CORE in SQLA are 2 separate beasts - than if follows what I've been saying here, that the web2py-DAL is equivalent just to the CORE, and has no features that the ORM provides whatsoever.I'm not sure that follows. The web2py DAL has a lot of features that might otherwise be found in an ORM. I'm not very familiar with SQLA, but I suspect the DAL has some features not present in CORE but similar to functionality included in the ORM.
You might also consider trying SQLA directly in place of the DAL
Anthony
If you take into account what's said in this talk - that basically the ORM and the CORE in SQLA are 2 separate beasts - than if follows what I've been saying here, that the web2py-DAL is equivalent just to the CORE, and has no features that the ORM provides whatsoever.I'm not sure that follows. The web2py DAL has a lot of features that might otherwise be found in an ORM. I'm not very familiar with SQLA, but I suspect the DAL has some features not present in CORE but similar to functionality included in the ORM.I wouldn't be so sure about that...You should really check out the links I've posted in this thread - SQLA-Core is a fully-fledged DAL. Reddit is using it alone, without any of the ORM level...
And again, it may be a matter of semantics, but there is no ORM feature in the DAL - I've been going over the documentation and asking lost of questing talking to Massimo - it's pretty conclussive - iweb2py's DAL is exclusively-stateless...
You might also consider trying SQLA directly in place of the DAL
I know that, but well, you see, there lies the problem - I DON'T want... I love the DAL too much - wouldn't change it for anything! :)(not even SQLA-Core...;) )
Arnon Marcus
I didn't say there were ORM features in the DAL, just that it includes features that you might otherwise expect to find in an ORM
...migrations, automatic file uploads/retrieval, recursive selects, automatic results serialization into HTML, virtual fields, computed fields, validators, field representations, field labels, field comments, table labels, list:-type fields, JSON fields, export to CSV, smart queries, callbacks, record versioning, common fields, multi-tenancy, common filters, GAE support, and MongoDB support?
But if you use an ORM built on top of the DAL, you won't be using the DAL API anyway, so what would you miss? Or are you saying you would still want to use the DAL for a significant portion of code and only move to the ORM for select parts of the application?
Anyway, it may nevertheless be a useful exercise to start by using SQLA for some project just to see if it really delivers on the promises you believe it is making.
Anthony
I didn't say there were ORM features in the DAL, just that it includes features that you might otherwise expect to find in an ORMWell, it seems like a semantic-issue. DAL and ORM are pretty abstract-terms.Here is how interpret them:DAL - A way to construct schemas and queries without writing SQL or DBAPI calls.ORM - A way to construct domain-models using a DAL in a statefull manner.
The ORM is a way of saying:"Hey, here's a bunch of classes and attributes, please wire them up so their instances would communicate their state to each other, optimizing my transaction-operations for me as I use them"
...migrations, automatic file uploads/retrieval, recursive selects, automatic results serialization into HTML, virtual fields, computed fields, validators, field representations, field labels, field comments, table labels, list:-type fields, JSON fields, export to CSV, smart queries, callbacks, record versioning, common fields, multi-tenancy, common filters, GAE support, and MongoDB support?That's a mouth-full...Let's brake it down, shell we?:
The first difference is of scope - Virtual/Computed-fields can only be applied to other fields of the same Table.
In the DAL, Virtual/Computed-fields can NOT generate implicit calls to foreign-table-fields.
The second difference is of statelessness-vs-statfullness - The DAL is stateless, so it can-not give values from a previous query.ORMs are statefull in nature, so:- For output, Virtual-fields can use values already stored in those other-field's cache, and not even query the database.- For input, Computed-Fields can use values already stored in those other-field's cache, and not even insert them to the database.The DAL is stateless in nature, so:- For output, Virtual-fields must query values from those other-field, in order to invoke the functionality of the automated-output.- For input, Computed-Fields must insert values to those other fields, in order to invoke the functionality of the automated-input.* There is also cache for the DAL, but it's time-based, and not transaction-based.
Anyway, it may nevertheless be a useful exercise to start by using SQLA for some project just to see if it really delivers on the promises you believe it is making.Or read the documentation and some SQLA forums... :)
Derek
Michele Comitini
--
Cliff Kachinske
On Saturday, April 27, 2013 9:18:45 AM UTC-4, Arnon Marcus wrote:
I am in the process of researching ways to improve the structure of my web2py-app's code, simplifying usage of certain areas, and enabling RPC-like interface for external programs.I use web2py for over 3 years now, and love every aspect of it - especially the DAL (!)However, as the code grew larger, and as hierarchical domain-model-patterns started to emerge, I started to look for alternative ways of accessing and using the portion of the data-model that is strictly hierarchical in nature.It is a huge controversial issue with relational-data-models which contain hierarchies. I don't intend to open a large discussion about this here. Suffice it to say, that even the most die-hard SQL lover, would admit it's shortcomings when hierarchies are introduces into the data-mode. It is an unsolved (probably "unsolvable") problem in data-model theory.So it is no a matter of looking fot the "best" solution, because there can not exist such a concept - even in theory.It is a matter of looking for the "most-fitting" set of trade-offs for the problem at hand.That said, some projects are large and/or varied enough, that they DO include both highly-relational areas, as well as highly-hierarchical areas - within the same data-model (!)For such use-cases, a more flexible/hybrid approach is beneficial.You don't expect to have to choose either/or relational-models vs. hierarchical-models - you expect your framework to include and facilitate support for both approaches for the same database.You would use the relational-features of the framework for when it is most suited for, and hierarchical-features for when IT makes better sense.Ideally, your framework would be built in an integrated-yet-layered design, that would make it easy for you to accomplish both approaches in a synergetic manner.My research has led me through ZODB and SQLAlchemy, just to get a feel for what an ORM could provide. Aside from reading a lot and watching a lot of lectures about these technologies, as well as general opinions about them, I have also taken the time to really go through tons of threads in this group about these issues. as well as the web2py documentation.Bottom-line, my current feelings about this issue, is that there is still something missing in web2py to facilitate the construction of higher-levels of abstractions, that are more focused on business-logic than database-schema. I also feel that there are "dogmatic" sentiments being thrown from both sides of the fence in this flame-fest fiasco.I think this hurts us - a lot.I think a more constructive approach would be to acknowledge that there are different use-cases that can benefit from different approaches, and that this leads to opposing opinions regarding certain trade-off that are being sought after.I think that web2py has taken an approach that is still too narrow-minded when it comes to supporting multiple-approaches, and that a layered-design could be beneficial here.Case in point, the philosophy and design of SQLAlchemy:Now, just to be clear, I think that the web2py-DAL's API is much cleaner, simpler, and more easy and fun to use than SQA's API, at least for the SQL-Expression layer. But I also think that SQA's is a more flexible approach - it can target a more varied set of use-cases.Contrary to most of what I've read about SQA in this group, it's ORM is NOT mandatory, nor is it a "necessarily" more-restrictive/less-performant way of using the database. I think most criticisms I've seen here of it, are ill-informed, and have a somewhat "prima-facie" smell to them. They mainly attack the ORM concept in it's Active-Record form, which is NOT what SQA has. They also don't consider the layered-architecture of SQA, and compare the DAL with different implementations of ORMs that ARE more restrictive and obtuse, "assuming" that this is probably what SQA does, when in fact it is not. They compare the DAL to SQA's ORM, which is a fundamental mistake(!) The DAL is not comparable to SQA's ORM layer, but to it's SQL-Expression layer(!) These API's are almost identical in what they do - only the interface is different. So I could very well refer to SQA's SQL-Expression layer, as being SQA's DAL.SQA's ORM is something different, that to my knowledge, web2py is lacking. It is a layer "on-top" of it's DAL, while "using" it's DAL, as well as lower-layers, in an integrated fashion.In short, SQA is NOT a single-layer ORM (!)Now, what I think is missing, is something comparable to SQL's ORM in web2py - another layer on-top of it's DAL. Not a set of classes, but a single abstract-class meant to be inherited from. There are many operations that can be automated when constructing an ORM layer on-top of web2py's DAL, using the DAL's already-existing schema information. These could benefit the construction of ORM classes using the DAL.Examples for such benefits could be seen in the second part of this talk:* This is an almost 3-hour talk from PyCon 2013, covering most aspects of SQA that even the most experienced users of it might be unfamiliar with - it is fast-paced and highly condensed, and well-worth the time to sit through.These automations, I predict, would emerge as recurring-patterns for people trying to implement such a thing in web2py, and what I am looking for, is an integration-abstract-layer with tools (in the form of abstract-methods) that would facilitate the design and implementation of ORM classes using the DAL.I don't have a clear conception of how such a thing would look like, I just have a general idea that such a thing would be most beneficial in many use-cases for which that DAL by itself is insufficient.I feel that the fear of having such a layer "restrict" future development by locking-down the business-data-model are unjustified. Refactoring can still occur later-on, and should occur with minimal effort by the developer using web2py - the framework should support and facilitate these kinds of refactoring scenarios, with appropriate auxiliary methods in the form of adapter/proxy design-patterns. If the ORM-abstract-class's design is built up-front using such patterns, than this would facilitate refactoring, and thus avoid scarring-off developers from using it.It should also facilitate performance-optimizations, by way of a transactionally-aggregating queries and updates/inserts automatically.Optionally, this abstract-class would be meant to be "multipally-inheritted-from", using the mix-in pattern. This way, a developer can have a separate class-hierarchic dealing with pure-business logic, to keep separation-of-concerns between database-usage and domain-logic, and also to enable re-use of code for other DAL's if needed (i.e, in a python-client that talks to web2py via rpc).These are all just ideas, and perhaps I am missing some things - maybe such capabilities already exist in some other form that I am unaware of.I would appreciate any references to such uses, if they already exist.(e.g - I am not too clear about lazy-tables and computed-fields, but I think they are an interesting start in this direction - I just haven't used them yet, as we are still using an older version of we2py that does not include them)
Arnon Marcus


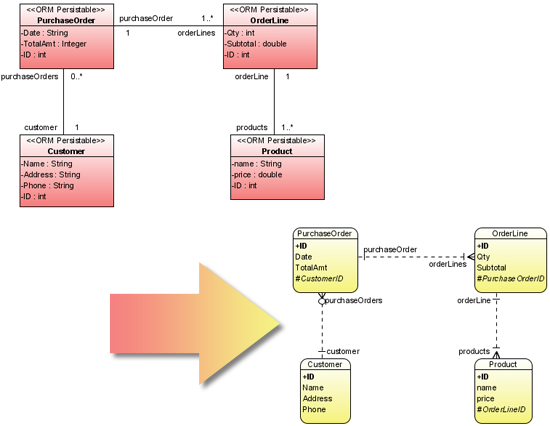
The crucial thing to notice here is that an ORM object-attribute can contain NON-SCALAR values - meaning, a link to a list of other objects, which themselves may contain links to other objects/sequences-of-objects, etc.
As for DAL, here is the part of the wilipedia page, that is relevant to this discussion:
"...Popular use for database abstraction layers are among object-oriented programming languages, which are similar to API level abstraction layers. In an object oriented language like C++ or Java, a database can be represented through an object, whose methods and members (or the equivalent thereof in other programming languages) represent various functionalities of the database. They also share the same advantages and disadvantages as API level interfaces."
As you can see, even wikipedia says that there is more to a DAL than just the SQL translation.
Here is another usage of the same "Three Letter Acronym" (DAL), that represents how an ORM is layered on-top of a DAL:


villas
If I look inside the DAL 'black box', I can just about figure out what's going on. If I look inside an ORM black box, it is already too complex (for me).
If we add the two black boxes together, it would only be maintainable by someone of Massimo's skill level (and even he thought it was too complex for his needs, hence the DAL!). I cannot imagine that anyone would commit themselves to such a project.
Perhaps we should try to list some of the benefits? Otherwise we shall remain theorists in pursuit of a hypothetical abstraction - which never looks good on a CV.
Anthony
The first thing to notice here, is that an ORM object-attribute can contain NON-SCALAR values - meaning, a link to a list of other objects. There is no feature in web2py that generates such an object.The second thing to notice here, is that the attributes of an ORM object usually contain child-objects (plural) that represent fields from a different table than the parent-object. Again, there is no feature in web2py that can generate such an object. A JOIN operation may return row objects, each of which may contain sub-attributes that hold A SINGLE field-value from a foreign-table, but it is a scalar-value - NOT another domain-entity-object (with it's own attributes, etc.), NOR a SEQUENCE of domain-entity objects
...
The crucial thing to notice here is that an ORM object-attribute can contain NON-SCALAR values - meaning, a link to a list of other objects, which themselves may contain links to other objects/sequences-of-objects, etc.
Arnon Marcus
Well, it seems like a semantic-issue. DAL and ORM are pretty abstract-terms.Here is how interpret them:DAL - A way to construct schemas and queries without writing SQL or DBAPI calls.ORM - A way to construct domain-models using a DAL in a statefull manner.I don't think you are understanding me, so let me try to be more clear. Let's say an ORM is a particular design pattern for modeling data, and a DAL is a different design pattern for modeling data. Each of those different design patterns can nevertheless be used to implement similar types of features. For example, you might want to query the database and return a results set. This can be done in an ORM, and it can be done in a DAL. The implementation and the syntax will be different in each case, but they are both implementing a common feature. So, when I say the DAL implements features that might otherwise be found in a typical ORM, I am not saying the DAL implements an ORM design pattern, just that it replicates functionality for which you might otherwise use an ORM.
For example, in an ORM, you can define a method in a class that returns a value calculated from the fields of a database record. In the web2py DAL, this same functionality can be achieved using a virtual field or lazy field.
I don't know if the SQLA CORE has virtual fields, but if it doesn't, I would suppose it leaves this kind of functionality to the ORM.
That looks like the definition of the SQLA ORM, not ORM's in general.
No, let's not. My point is not that any of those items properly belong to either a DAL or an ORM, or that they can only be implemented with either a DAL or an ORM design pattern. Rather, you had claimed that the SQLA CORE is equivalent to the web2py DAL and that all 20,000+ lines of SQLA ORM code must therefore be providing unique functionality not available in the DAL (thus implying that the ORM must be useful). I was just suggesting that the DAL might be doing more than the SQLA CORE (at least in some areas), and that the DAL might possibly be offering some features for which you would otherwise need the SQLA ORM.
The point is, many features found in DAL's and ORM's are not unique or specific to the DAL or ORM design pattern. Each design pattern can be used to implement many common types of functionality (the functionality may not be identical, but at least similar, and used to satisfy the same goals).
Regarding all the features you claim are inherently DAL features and not ORM features, I disagree. Any one of those features could rightly be part of either a DAL or an ORM. They are simply features you might want to implement within any data modeling abstraction, whatever the design pattern.
The first difference is of scope - Virtual/Computed-fields can only be applied to other fields of the same Table.No, they can also be applied to the results of joins (not sure if that's typically as easy to do in an ORM) -- see http://web2py.com/books/default/chapter/29/06#Old-style-virtual-fields.
In the DAL, Virtual/Computed-fields can NOT generate implicit calls to foreign-table-fields.Yes, they can with recursive selects.
The second difference is of statelessness-vs-statfullness - The DAL is stateless, so it can-not give values from a previous query.ORMs are statefull in nature, so:- For output, Virtual-fields can use values already stored in those other-field's cache, and not even query the database.- For input, Computed-Fields can use values already stored in those other-field's cache, and not even insert them to the database.The DAL is stateless in nature, so:- For output, Virtual-fields must query values from those other-field, in order to invoke the functionality of the automated-output.- For input, Computed-Fields must insert values to those other fields, in order to invoke the functionality of the automated-input.* There is also cache for the DAL, but it's time-based, and not transaction-based.I'm not quite sure what you mean here. Even in an ORM, in order to calculate the value of a virtual field, you first have to retrieve the input field values from the database; and when creating a computed field, you still ultimately have to write the computed value to the database.
Also, be careful not to confuse ORM's in general with the SQLA ORM in particular -- some properties you claim for ORM's are unique to SQLA, and they are not necessarily properties that can be implemented only within the ORM design pattern (i.e., they are not limited to ORM's).
Which I'm assuming you have not yet done, as you have yet to show an example of something you can do easily in the SQLA ORM but find difficult or inefficient in the DAL. A real project might help to surface some compelling use cases and provide benchmarks for possible efficiency gains.
Arnon Marcus
On Wednesday, May 1, 2013 4:39:49 PM UTC-7, Anthony wrote:
The first thing to notice here, is that an ORM object-attribute can contain NON-SCALAR values - meaning, a link to a list of other objects. There is no feature in web2py that generates such an object.The second thing to notice here, is that the attributes of an ORM object usually contain child-objects (plural) that represent fields from a different table than the parent-object. Again, there is no feature in web2py that can generate such an object. A JOIN operation may return row objects, each of which may contain sub-attributes that hold A SINGLE field-value from a foreign-table, but it is a scalar-value - NOT another domain-entity-object (with it's own attributes, etc.), NOR a SEQUENCE of domain-entity objects
...
The crucial thing to notice here is that an ORM object-attribute can contain NON-SCALAR values - meaning, a link to a list of other objects, which themselves may contain links to other objects/sequences-of-objects, etc.
Although ORM's may do that, such a feature is not unique to the ORM pattern. In the web2py DAL, for example, in a Row object with a reference to another table, the reference field is actually a DAL.Reference object, not a scalar value (it includes the scalar value but also allows access to related records in the referenced table).
Similarly, a Row object from a table that is referenced by another table includes an attribute that is a DAL.LazySet object (also not a scalar), which allows access to the records in the referencing table that reference the current Row object.
The DAL also has list:-type fields, whose values are lists, including lists of DAL.Reference objects in the case of list:reference fields.
Row objects can also include custom methods (i.e., "lazy" virtual fields) as well as virtual fields, which can contain complex objects.
Anthony
Anthony
So, when I say the DAL implements features that might otherwise be found in a typical ORM, I am not saying the DAL implements an ORM design pattern, just that it replicates functionality for which you might otherwise use an ORM.
No, it does not do that. It implements very different functionality, that may have a similar API and the same terminology used, which honestly I find quite confusing - border-line misleading.
For example, in an ORM, you can define a method in a class that returns a value calculated from the fields of a database record. In the web2py DAL, this same functionality can be achieved using a virtual field or lazy field.
There are no lazy-fields in web2py, and I find the terminology misleading - as I said - lazyness in the context of database-access, is a deferred-query - NOT a deferred-calculation of the results of a query.
Deferred calculations of field-results are generally useless - web-applications are generally I/O-Bound much more than CPU-Bound - so the benefits of deferring is mute in post-query calculations compared to benefits in deferred-queries that are used within the context of transaction-operation-optimizations
which is the context most people would thing of whenever they here the term Lazy thrown about a database-context
I don't know if the SQLA CORE has virtual fields, but if it doesn't, I would suppose it leaves this kind of functionality to the ORM.
That's irellevant to the comparison of SQLA-Core vs. web2py-DAL, since I am not suggesting using the SQLA-Core and dumping it's ORM
- quite the opposite - and since virtual-fields are actually much more beneficial when used within an ORM layer, as opposed to a DAL one.
The only relevance for this point to this discussion, is the comparison of the sized of the code-bases. I get that this was what you meant.
No, let's not. My point is not that any of those items properly belong to either a DAL or an ORM, or that they can only be implemented with either a DAL or an ORM design pattern. Rather, you had claimed that the SQLA CORE is equivalent to the web2py DAL and that all 20,000+ lines of SQLA ORM code must therefore be providing unique functionality not available in the DAL (thus implying that the ORM must be useful). I was just suggesting that the DAL might be doing more than the SQLA CORE (at least in some areas), and that the DAL might possibly be offering some features for which you would otherwise need the SQLA ORM.
You are saying that a lot of web2py's extra-features that extend on-top of the DAL, might not be included in SQLA's Core, but rather may represent a big portion of the 20K lines of code of the ORM, which would then suggest that the features I was excited about may actually represent a much minor portion of the 20K code-base, which would then suggest that they may be small, and therefore legitimate for being considered "useless". You could have said so more clearly (like I just did) and prevent the confusion.
The web2py DAL has a lot of features that might otherwise be found in an ORM. I'm not very familiar with SQLA, but I suspect the DAL has some features not present in CORE but similar to functionality included in the ORM.
I didn't say there were ORM features in the DAL, just that it includes features that you might otherwise expect to find in an ORM (e.g., something like virtual fields). In other words, some of what you get with that 20,000+ lines of ORM code might be functionality that is in fact available in the web2py DAL.
Now, if you would have seen the lecture I gave Massimo the link to watch, you would have seen how complex these features might be, so I doubt they are implemented within a small code-base. But if they do, this would degrade your argument that this is such a "substantial-investment" as you called it...
What I meant, was that the "essence" of an ORM, is NOT these features. Any kind of Access-Layer-API may contain some of these features, yes - I agree - but that was not the point - the point was that the MAIN role an ORM has, is not found in these features - it is in the mapping of relations to domain-model objects - which is not what they are all about (again, check-out my comment to Derek below).
...I found it misleading to allude that by the mear inclusions of such features in web2py, that it somehow get's it closer to providing ORM functionality - this is not the case - as ORM-functionality - at it's core - is the design-pattern of providing domain-model tools - not the existence of convinience-auxiliary features.
I have read this whole DAL section in the book today - I know you can super-impose virtual-fields onto row-objects that result from a JOIN operation - but that's such an edge-case with such marginal-utility, that it can hardly even be considered a "feature"...
I was comparing that to the fact that ORM classes may contain representations of fields from multiple-tables from the get-go - so it can be used for "querying" multiple-tables - NOT for result-manipulations of JOINs (Which has questionable-utility at best)
In the DAL, Virtual/Computed-fields can NOT generate implicit calls to foreign-table-fields.Yes, they can with recursive selects.
I touched on Recursive-selects further along, they are useless for 2 reasons:
1. They are Active-Record-like implementations - using it on a field within a for-loop is a big no-no for DAL usage, as there it would generate tons of queries. In an ORM, because it is statefull, you could do an eager-load for the foreign-table in order to cache it - THEN it would be usefull, as the foreign-table-access would not generate tons of queries.
2. It is only applicable for single-relational fields - which are few and far between in real-life code - for more complex relationship, the backward-relational-inference brakes down. SQLA solves this with the "relationship" object - basically defining relationships on both ends, so that the ORM object-graph contains a bi-directional reference (the creator had to talk to Guido to find-our how to do that, so it would not create a cyclical-object-reference that might become a memory-leak, but eventually they got it working).
I'm not quite sure what you mean here. Even in an ORM, in order to calculate the value of a virtual field, you first have to retrieve the input field values from the database; and when creating a computed field, you still ultimately have to write the computed value to the database.
No. ORMs are statefull - It you have already data loaded from a oreviouse query in those source-fields, than a virtual-field would not have to round-trip to the database at all - it would just use the cached-values in the source-fields.
As for computed-fields, again, the benefit is for storing a computed-value, so it will not have to be re-calculated. So yes, "eventually" the computed-value would be saved to the database, but it doesn't have to occur in the calculation-operation - it can just leave the calculated-value in memory, for further use in subsequent queries within the same transaction.
Additionally, similarly-to-virtual fields, here again the source-fields for the calculation, may already exist in memory from previouse queries - so the calculation would not requier a round-trip to the database.
No - they are not limited to ORMs - but they ARE limited to statefull-frameworks, which most web-frameworks are and web2py is not.
Transitional-scope-persistence may be implemented in a DAL in a statefull web-framework (which again, web2py isn't) - but the utility would still be limited when compared to having that within an ORM domain-class object-graph.
That said, you are right about one thing - if the DAL would get statefulness, many of these features would become immensely more beneficial - almost automatically. It is a matter of statefullness - not or design-pattern of domain-classes.
But still, a statefull-domain-class implementation, would still benefit more out of such features than a web2py's DAL, ans so would still be superior.
I think in this very comment, and the one before, as well as my response to Derek about ORMs, as well as in many lectures I've posted here, there are more than sufficient reasons to see benefits of using SQLA's ORM as opposed to web2py's DAL. It is an architectural-issue, not a use-case one.Given all I've alrady written, insisting on requesting for actual use-cases, when the architectural-issues are obviously already so glaring - it would seem like a picky - borderline straw-men - argument.
Anthony
Although ORM's may do that, such a feature is not unique to the ORM pattern. In the web2py DAL, for example, in a Row object with a reference to another table, the reference field is actually a DAL.Reference object, not a scalar value (it includes the scalar value but also allows access to related records in the referenced table).In this case it does not reference a set of DAL fields.
Similarly, a Row object from a table that is referenced by another table includes an attribute that is a DAL.LazySet object (also not a scalar), which allows access to the records in the referencing table that reference the current Row object.I did not know that - what form of Layziness are we talking about here? Will it generate a query to fill-up the target rows?In any case, it is stil a reference to something the WOULD generate a Rows object - it is not a reference to an already-exising domain-object (which may then have references to othe domain-objects, etc. - all already within memory) object as is in ORMS
The DAL also has list:-type fields, whose values are lists, including lists of DAL.Reference objects in the case of list:reference fields.That's interesting, but that is not exactl the same - list-fields need to be supported in the database, but in any case, it is not comparable to being linked to relation ally-stored primary-keys - which would be how it would be implemented in an ORM.
Row objects can also include custom methods (i.e., "lazy" virtual fields) as well as virtual fields, which can contain complex objects.Relates to the comment I gave you a couple of minutes ago...These are complementary-auxiliary features (with in the web2py-implementation case, have questionable real-world-utility) which while they do go beyond a "simple" value, they are still scalar, as they ultimately result in a reference to a scalar-value - not a reference to a sequence of objects.

Philip Kilner
On 01/05/13 22:07, Michele Comitini wrote:
> Why not write a driver for SQLA that speaks DAL instead of a sql dialect?
--
Regards,
PhilK
'a bell is a cup...until it is struck'
Philip Kilner
On 01/05/13 22:27, Cliff Kachinske wrote:
> I would propose that the best way to get others on board
> would be to channel the energy being burned on this thread into an
> implementable design or even a set of specific software requirements or
> pseudo code.
>
This has been a very interesting thread, but the length (and passion!)
of some of the posts has made it a long hard read, and despite my best
efforts I truly do not understand what problem the DAL fails to solve,
and I don't expect to without some much-less-abstract discussion.
Arnon Marcus
On Thursday, May 2, 2013 5:17:41 AM UTC+3, Anthony wrote:
Although ORM's may do that, such a feature is not unique to the ORM pattern. In the web2py DAL, for example, in a Row object with a reference to another table, the reference field is actually a DAL.Reference object, not a scalar value (it includes the scalar value but also allows access to related records in the referenced table).In this case it does not reference a set of DAL fields.I'm not sure what you mean. A reference field references records, not fields.
Similarly, a Row object from a table that is referenced by another table includes an attribute that is a DAL.LazySet object (also not a scalar), which allows access to the records in the referencing table that reference the current Row object.I did not know that - what form of Layziness are we talking about here? Will it generate a query to fill-up the target rows?In any case, it is stil a reference to something the WOULD generate a Rows object - it is not a reference to an already-exising domain-object (which may then have references to othe domain-objects, etc. - all already within memory) object as is in ORMSAre you saying that when you select a set of records that include reference fields, the ORM automatically selects all the referenced records (and any records they may reference, and so on) and stores them in memory, even if you have not requested that? That sounds inefficient.
The DAL also has list:-type fields, whose values are lists, including lists of DAL.Reference objects in the case of list:reference fields.That's interesting, but that is not exactl the same - list-fields need to be supported in the database, but in any case, it is not comparable to being linked to relation ally-stored primary-keys - which would be how it would be implemented in an ORM.No, list fields do not have to be supported in the database (they are stored as strings) -- they are an abstraction provided by the DAL. list:reference fields do in fact store a list of primary keys (in fact, a list of objects that include the primary keys and know how to retrieve the associated records). web2py also has JSON fields, which I would say does not count as a scalar either.
Row objects can also include custom methods (i.e., "lazy" virtual fields) as well as virtual fields, which can contain complex objects.Relates to the comment I gave you a couple of minutes ago...These are complementary-auxiliary features (with in the web2py-implementation case, have questionable real-world-utility) which while they do go beyond a "simple" value, they are still scalar, as they ultimately result in a reference to a scalar-value - not a reference to a sequence of objects.No, you can define a virtual field whose value is any custom complex Python object you like, with its own methods, that may do or return whatever you like. They need not reference or return a scalar value. This is not a mere "auxiliary" feature but something that allows you to replicate functionality you might otherwise find in an ORM class.
Anthony
Anthony
In this case it does not reference a set of DAL fields.I'm not sure what you mean. A reference field references records, not fields.The operative word in my comment is SET not FIELD. I may have gotten the Field-vs-Record terminology in this sentence, but that is irrelevant to what I was referring to.
My point was that the assertion of wikipedia that ORM can have references to non-scalar values, applies in your example, as the existence of intermediary-objects on the way to get to the value, does not grant the attribute "non-scalar" status - only a reference to a SEQUENCE of objects can do that.
But the flaw in your reasoning is that you are trying to apply a "stateless-mid-set" to a "statefull-system". I'm not sure why you are doing that.
When you say "automatically selects" you are meaning to say "automatically generate queries", because within a stateless system there is no record-cache-management, so any access to an attribute IS a "select" from the database. But that is not the case with statefull-ORMs - they "may" issue selects "if-and-only-if" the requested value is "invalid" (meaning, it was either never queried at all as of yet, or was invalidated by a previous transaction-commit).
You make an object-attribute access, and the ORM is traversing the object-graph that is linked to this attribute, in order to get a value at some point.The ORM is doing the traversal for you.
So saying that any attribute-access would "necessarily-always" generate a "select" is inaccurate.
Also, it is not necessarily inefficient, as the idea in an ORM is that it figures-out the minimal-required database-access in order to get you the data you ask.
No, list fields do not have to be supported in the database (they are stored as strings) -- they are an abstraction provided by the DAL. list:reference fields do in fact store a list of primary keys (in fact, a list of objects that include the primary keys and know how to retrieve the associated records). web2py also has JSON fields, which I would say does not count as a scalar either.It is amazing how far the DAL features have gone to mimic an ROM "on the surface", while not being the real thing underneath....You are basically suggesting "bypassing" the relational-functionality of the database, and do it in the DAL, all just to achieve "appearance" of an ORM...I don't even know where to place that... It's absurd...
An ORM object-graph is a representation of foreign-key relationships in the database - not a relation of sub-values stored in some "string"-type value...An ORM object, may have a value that is a representation of foreign-table-fields that point to it via a foreign key. It is a "real" non-scalar-relation in both the database AND the object-attribute - not some kind of a framework-hack...
These are complementary-auxiliary features (with in the web2py-implementation case, have questionable real-world-utility) which while they do go beyond a "simple" value, they are still scalar, as they ultimately result in a reference to a scalar-value - not a reference to a sequence of objects.No, you can define a virtual field whose value is any custom complex Python object you like, with its own methods, that may do or return whatever you like. They need not reference or return a scalar value. This is not a mere "auxiliary" feature but something that allows you to replicate functionality you might otherwise find in an ORM class.In order to do that, you would have to "replicate" the relations (that already-exist in the database) in code, and construct-that on every assess to that attribute - instead of "using" the relationships that already exist in the database, and have them "automatically" generating an object-graph for you "once", in application-launch time.
Arnon Marcus
According to wikipidia, DAL-object-attributes are not referencing an object-graph in memory, as ORM ones do.
You may say anything to avoid admitting that, but it would sill be the case.
As for lazy-set objects, existing in row-objects and pointing to a backwards-foreign-key records, I dont remember seeing anything about that in the documentation. Can you post a link?
Anthony
According to wikipidia, DAL-object-attributes are not referencing an object-graph in memory, as ORM ones do.
You may say anything to avoid admitting that, but it would sill be the case.
As for lazy-set objects, existing in row-objects and pointing to a backwards-foreign-key records, I dont remember seeing anything about that in the documentation. Can you post a link?
Arnon Marcus
You will see in my comment to him where it defines an ORM to be an object-graph.
I iterpreted the Wikipedia DAL definition, of scalar-vs-non scalar, to mean an absent of an object-graph, since a reference of an object-attribute to a sequence, is a non-scalar reference - and an object-graph may contain such references, in a way a DAL api can-not, according to the scalarity-definition of the DAL. And again, all of this is in the context of my reaction to Derek's claim that the wikipedia-definitions say otherwize.
As to LazySets, no-where in the documentation is that term mentioned. As for Recursive-selects, we've been through this already - twice actually - it is an explicit 'select' statement that generates a query - it is not a reference to a sequence object that exists in memory.
Also, it can't be used for complex relational-graphs, only for single-foreign-key relations.
Anthony
I iterpreted the Wikipedia DAL definition, of scalar-vs-non scalar, to mean an absent of an object-graph, since a reference of an object-attribute to a sequence, is a non-scalar reference - and an object-graph may contain such references, in a way a DAL api can-not, according to the scalarity-definition of the DAL. And again, all of this is in the context of my reaction to Derek's claim that the wikipedia-definitions say otherwize.
As to LazySets, no-where in the documentation is that term mentioned.
As for Recursive-selects, we've been through this already - twice actually - it is an explicit 'select' statement that generates a query - it is not a reference to a sequence object that exists in memory.
db.define_table('person', Field('name'))
db.define_table('dog', Field('name'), Field('owner', 'reference person'))
Bob = db(db.person.name == 'Bob').first()
Bob.dog = Bob.dog.select() # db query here
print Bob.dog # no db query here
Also, it can't be used for complex relational-graphs, only for single-foreign-key relations.
Arnon Marcus
Anthony
db.define_table('Continent', Field('Name', 'string'))
db.define_table('Country', Field('Name', 'string'), Field('Continent', db.Continent))db.define_table('City', Field('Name', 'string'), Field('Country', db.Country))Using an ORM, you could do something like:>>> Country(Name='France').City.list[<City Name:Paris>, <City Name:Nice>]Using the DAL, the best you might get is:>>> [city for city in db.City.Country.select() if city.Country.Name == ''France'][<Row Name:Paris>, <Row Name:Nice>]
>>> db.Country(name='France').City.select()
>>> europe = Continent(Name='Europe')>>> france = Country(Name='France', Continent=europe)>>> paris = City(Name='Paris', Country=france)>>> nice = City(Name='Nice', Country=france)
>>> europe.Country(Name='France').City.list
[<City Name:Paris>, <City Name:Nice>]
>>> europe = db.Continent.insert(Name='Europe')
>>> france = db.Country.insert(Name='France', Continent=europe)
>>> paris = db.City.insert(Name='Paris', Country=france)
>>> nice = db.City.insert(Name='Nice', Country=france)
>>> db.Country(france).City.select()
[<Row Name:Paris>, <Row Name:Nice>]
Of course, you don't get the "is" equivalencies, but your example doesn't actually require that.

Mariano Reingart
> I agree.
>
> Here is a more concrete explanation.
>
> Given the following tables:
>
> db.define_table('Continent', Field('Name', 'string'))
> db.define_table('Country', Field('Name', 'string'), Field('Continent',
> db.Continent))
> db.define_table('City', Field('Name', 'string'), Field('Country',
> db.Country))
>
> Using an ORM, you could do something like:
>>>> Country(Name='France').City.list
> [<City Name:Paris>, <City Name:Nice>]
it is a query? it is pre-fetched or cached?
What about if I need the cities of countries where main language is
not Spanish, and population is above 1 millon?
Please, note that you are mixing a declarative query syntax (DAL),
with an imperative one (ORM)
> Using the DAL, the best you might get is:
>>>> [city for city in db.City.Country.select() if city.Country.Name ==
>>>> ''France']
> [<Row Name:Paris>, <Row Name:Nice>]
[city for db.City.ALL in db.City, db.Country if db.Country.Name ==
'France' and db.Country.id == db.City.country]
Sadly, there is NO possible way to archive a pythonic list
comprenhension syntax that query the objects in the server side AFAIK
Some libraries uses dis (python disassembler) and other internal &
dirty python hacks to do something similar, please, see:
http://www.aminus.net/geniusql/
http://www.aminus.org/blogs/index.php/2008/04/22/linq-in-python?blog=2
http://www.aminus.net/geniusql/chrome/common/doc/trunk/managing.html
Note that web2py is much closer to the "pythonic expressions", but
without the early / late binding and other issues described there ;-)
>
> In an ORM on-top of the DAL, I would like to be able to do something like:
>
> @ORM(db.City)
> class City:
> pass
>
> @ORM(db.Country)
> class Country:
> pass
>
> @ORM(db.Continent)
> class Continent:
> pass
>
>>>> europe = Continent(Name='Europe')
>>>> france = Country(Name='France', Continent=europe)
>>>> paris = City(Name='Paris', Country=france)
>>>> nice = City(Name='Nice', Country=france)
>>>>
>>>> europe.Country(Name='France') is france
> True
memory (something like a singleton), or "is" will not work as you are
expecting (it is for checking "identity")...
That could be also archived hacking "Row", but you should use == in
python for this kind of comparision (equality)
>
> This would be so intuitive and easy to use...
sight, so I prefer the DAL syntax that is a bit verbose but more
uniform
(at least I know what I'm doing in each step, or can get a SQL book
and see how to "pythonize" the expression)
A ORM is not more intuitive and will have a higher learning curve, and
no formal / logical / math justification theory BTW
I think that a more elegant way for web2py would be research how to
put bussiness rules (and not only "tables"), in the models.
This could be done right now to some extent with virtual fields &
predefined queries (we already have represent, field validators, etc).
Implementing "stored procedures" and "triggers" in web2py also could
be interesting (and you could win a lot of speed), for example,
PostgreSQL supports PL/Python for that.
Best regards,
Mariano Reingart
http://www.sistemasagiles.com.ar
http://reingart.blogspot.com
Arnon Marcus
Sorry, but what should do .list() ?
it is a query? it is pre-fetched or cached?
What about if I need the cities of countries where main language is
not Spanish, and population is above 1 millon?
Please, note that you are mixing a declarative query syntax (DAL),
with an imperative one (ORM)
I would like a elegant declarative syntax similar to LINQ, but in python:
[city for db.City.ALL in db.City, db.Country if db.Country.Name ==
'France' and db.Country.id == db.City.country]
Sadly, there is NO possible way to archive a pythonic list
comprenhension syntax that query the objects in the server side AFAIK
Some libraries uses dis (python disassembler) and other internal &
dirty python hacks to do something similar, please, see:
http://www.aminus.net/geniusql/
http://www.aminus.org/blogs/index.php/2008/04/22/linq-in-python?blog=2
http://www.aminus.net/geniusql/chrome/common/doc/trunk/managing.html
Note that web2py is much closer to the "pythonic expressions", but
without the early / late binding and other issues described there ;-)
This would require caching or storing previous queried record in
memory (something like a singleton), or "is" will not work as you are
expecting (it is for checking "identity")...
That could be also archived hacking "Row", but you should use == in
python for this kind of comparision (equality)
For you that are creating it, but I will not understand it in a first
sight, so I prefer the DAL syntax that is a bit verbose but more
uniform
(at least I know what I'm doing in each step, or can get a SQL book
and see how to "pythonize" the expression)
A ORM is not more intuitive and will have a higher learning curve, and
no formal / logical / math justification theory BTW
Arnon Marcus
city.Language is not spanish and city.Population.isGraterThan(1000000)
"Beautiful is better than ugly."
Anthony
The whole point of having an ORM, is for you to not have to worry about the answer to that question - it's gonna do the optimal thing it can, based on the circumstances in which it is called.
The question of how these cache-management is working, and so whether or not you can trust it, is a long and complex question. Suffice it to say, that there has been more than a decade of research into this issue, so it is solved.
What about if I need the cities of countries where main language is
not Spanish, and population is above 1 millon?ORMs allow you to attache filters for that, it really depends on the implementation, but let's think of some options, shell we?
db.define_table('Language', Field('Name', 'String'))db.define_table('Continent', Field('Name', 'string'))db.define_table('Country', Field('Name', 'string'), Field('Continent', db.Continent))db.define_table('City', Field('Name', 'string'), Field('Country', db.Country), Field('Language', db.Language), Field('Population', 'Integer'))
>>> spanish = Language(Name='Spanish')>>> french = Language(Name='French')>>> france.City.Language = french
french = db.Language.insert(Name='French')
db.Country(france).City.update(Language=french)
>>> [city for city in fance.City.list if \city.Language is not spanish and city.Population.isGraterThan(1000000)][<City Name:Paris>]
It almost reads like plain English... Beautiful (!)
>>> france.City.where(Language=not(spanish), Population=moreThan(1000000))
>>> france.City.FilterBy((City.Languase != spanish) & (City.Population > 1000000))
db.Country(france).City(
(db.City.Language != spanish) & (db.City.Population > 1000000)).select()
That could be also archived hacking "Row", but you should use == inpython for this kind of comparision (equality)Not is SQLA :)
Web2py could do that too.
An ORM is MUCH MORE intuitive, as my examples had demonstrated
Anthony
When comparing this:city.Language is not spanish and city.Population.isGraterThan(1000000)With this:
(db.City.Language != spanish) & (db.City.Population > 1000000)
Alex
Am Freitag, 3. Mai 2013 13:44:20 UTC+2 schrieb Arnon Marcus:
Sorry, but what should do .list() ?
it is a query? it is pre-fetched or cached?The whole point of having an ORM, is for you to not have to worry about the answer to that question - it's gonna do the optimal thing it can, based on the circumstances in which it is called.
Here's the problem. In a perfect world you don't have to worry about what's going on behind the scenes. In a real application you need to know what exactly the ORM is doing, otherwise you'll run into problems sooner or later.
I had to work with an ORM (Hibernate) for many years. The ORM is very convenient but the "magic" which is going on in the background will cause you trouble (at least performance-wise). I'm really happy to use web2py and the DAL for my own project, I always know what exactly is going on and I never encountered a strange bug where I could not figure out what's going on. Not so with the ORM where I lost many hours debugging unexcepted behavior.
In my opinion it does not make sense to define how references are fetched on an object level (at least that's how it is done in Hibernate, don't know about SQLA). E.g. when I query a City object I can't say in advance if I always want to access the Country reference as well. In Hibernate single references have eager loading so they are always fetched. That's bad because when you don't need the reference there is unnecessary data fetched (and of course this is recursive, e.g. if Country has a single reference itself this will also be loaded). With lazy loading you often run into the problem that the session or transaction is not active anymore and the references cannot be accessed (just google for "Lazy Loading Exception"). Therefor we often loaded all those references when the object is queried to avoid running into a lazy loading exception later on - which is of course also not very good for performance. With the DAL I say exactly what I need (joining the tables I really need for my use case) and when, that's so much better and easier than depending on some ORM magic.
For me all the added internal complexity of an ORM is not worth the effort. The complexity is just shifted to a different layer. Maybe the videos and presentations of SQLA look nice and promising but you'll only find out about the disadvantages (which are not mentioned in the videos of course) once you develop a real world application.
Alex
Arnon Marcus
Has anyone given you any Kool-Aid to drink recently?
Famous last words.
What does france.City.Language = french do? france.City refers to all cities in France, so does this assign "French" as the language for all cities? Does SQLA employ that syntax?
In web2py, this would be:
db.Country(france).City.update(Language=french)Looks a lot like your example (maybe even a bit more explicit about what's going on).
(Note, Mariano's example actually assumed language to be a country-level field.)>>> [city for city in fance.City.list if \city.Language is not spanish and city.Population.isGraterThan(1000000)][<City Name:Paris>]The problem here is that you are doing all the filtering in Python rather than in the database. Not a big deal in this example, but with a large initial set of records, this is inefficient because you will return many unnecessary records from the database and Python will likely be slower to do the filtering.
It almost reads like plain English... Beautiful (!)There are differing opinions on this. Some prefer symbols like != and > over plain English like "is not" and "isGreaterThan" because it is easier to scan the line and quickly discern the comparisons being made. In particular, I would much prefer both typing and reading ">" rather than ".isGreaterThan()".
>>> france.City.where(Language=not(spanish), Population=moreThan(1000000))>>> france.City.FilterBy((City.Languase != spanish) & (City.Population > 1000000))In web2py, you can already do:
(db.City.Language != spanish) & (db.City.Population > 1000000)).select()So far, for every example you have shown, web2py has fairly similar syntax.
Sure, we can quibble over which is more "beautiful", but I haven't seen anything to justify building a massive ORM.
And the downside of adding an ORM (aside from the time cost of development and maintenance) is that you would then have to learn yet another abstraction and syntax.
Well, if you're actually making such a comparison, you generally would only be interested in "==", not "is" -- it just so happens that "is" would also be True in SQLA because of the identity mapping.
Sure, but it could do it at the DAL level, without an ORM. So far, though, you haven't made a strong case for the utility of such a feature (I don't doubt that it can be helpful -- the question is how helpful).
Maybe I missed an example, but I don't think I saw any that were more intuitive at all, let alone "MUCH MORE" intuitive.
(db.City.Language != spanish) & (db.City.Population >1000000)).select()
Arnon Marcus
I actually find that latter easier to process. The parentheses and & make it easier to see there are two separate conditions, and the != and > are easier to pick out and comprehend than "is not" and ".isGreaterThan()". A non-programmer may have an easier time with the more English-like version (assuming they happen to speak English, of course), but I think it's reasonable to expect even novice programmers to understand the basic boolean operators. Whatever your opinion on the "beauty" of one over the other, though, surely this doesn't justify the massive undertaking of building an ORM, particularly since you would still have to know and use the underlying DAL syntax in addition anyway.
Anthony
Arnon Marcus
Anthony
Has anyone given you any Kool-Aid to drink recently?
I have no idea what you mean by that...
Famous last words.I have no idea what you mean by that either...
db.Country(france).City.update(Language=french)Looks a lot like your example (maybe even a bit more explicit about what's going on).
It is not more explicit - it has the same level of explicitness of what's going on - just less pluming-level explicitness.
But the important distinction is that there is a hidden fundamental difference - in my approach it is actually making object-references (alongside the database insertion) so that can be used further-on in the code,
Again, you have to break-away the stateless mind-set and appreciate statefullness.
This assumes a very different execution-model than what you are used to in web2py. It is something that would happen within a module, not within a controller-action, so it is saved within the module-object across transactions/requests/sessions.
>>> [city for city in fance.City.list if \city.Language is not spanish and city.Population.isGraterThan(1000000)][<City Name:Paris>]The problem here is that you are doing all the filtering in Python rather than in the database. Not a big deal in this example, but with a large initial set of records, this is inefficient because you will return many unnecessary records from the database and Python will likely be slower to do the filtering.
Well, that depends a lot on the context in which this is executed.If you have many queries similar to your example, before/around this line of code, that may reuse the same objects for other purposes (which is not uncommon)It may in fact be slower to do it your way in many circumstances, because every specialized-query you are making is another round-trip to the database, which would be orders-of-magnitude slower than doing an eager-loading up-front, and filtering in python.
Also, you need to keep in mind that this is assuming a long-lasting set of objects that out-live a single transaction-operation.
Also, bare in mind that I am not suggesting to "replace" the DAL, only to "augment" it with a statefull layer on-top.
The benefits/trade-offs are not absolute/constant - they vary circumstantially.
It almost reads like plain English... Beautiful (!)There are differing opinions on this. Some prefer symbols like != and > over plain English like "is not" and "isGreaterThan" because it is easier to scan the line and quickly discern the comparisons being made. In particular, I would much prefer both typing and reading ">" rather than ".isGreaterThan()".
You are right - there are different opinions, but the "Zen of Python" is conclusive. :)
Also, there are both performance AND memory benefits to using "is not". An object-id check is much faster that an equality check, and having the same object referenced by different names instead of having copies of it that need to be equality-tested, may save tons of memory.
>>> france.City.where(Language=not(spanish), Population=moreThan(1000000))>>> france.City.FilterBy((City.Languase != spanish) & (City.Population > 1000000))In web2py, you can already do:
(db.City.Language != spanish) & (db.City.Population > 1000000)).select()So far, for every example you have shown, web2py has fairly similar syntax.
But with radically-different semantics (!!!)
Sure, we can quibble over which is more "beautiful", but I haven't seen anything to justify building a massive ORM.
It is not just more beautiful - it is also faster for long-transactions, and takes less memory.
Also it results in developer code being much more readable and concise and hence much more maintainable.
And the downside of adding an ORM (aside from the time cost of development and maintenance) is that you would then have to learn yet another abstraction and syntax.
This doesn't deter people from using SQLA - how do you account for that?
Sure, but it could do it at the DAL level, without an ORM. So far, though, you haven't made a strong case for the utility of such a feature (I don't doubt that it can be helpful -- the question is how helpful).
So, a smaller memory-footprint, better-performance, readability, conciseness, beauty and ease-of-maintenance for the developers, are all insufficient for your criterion of utility?
Are you seriously suggesting that this:
[city for city in fance.City.list if \city.Language is not spanish and city.Population.isGraterThan(1000000)]
Is not much-more intuitive than this?:
db.Country(france).City(
(db.City.Language != spanish) & (db.City.Population >1000000)).select()
[city for city in db.Country(france).select() if \
city.Language != spanish and city.Population > 1000000]
What more, I believe you don't even know what you're talking about either...
Arnon Marcus
Sadly, there is NO possible way to archive a pythonic list
comprenhension syntax that query the objects in the server side AFAIK
Some libraries uses dis (python disassembler) and other internal &
dirty python hacks to do something similar, please, see:
http://www.aminus.net/geniusql/
http://www.aminus.org/blogs/index.php/2008/04/22/linq-in-python?blog=2
http://www.aminus.net/geniusql/chrome/common/doc/trunk/managing.html
Note that web2py is much closer to the "pythonic expressions", but
without the early / late binding and other issues described there ;-)
Just to clarify, again, the following syntax:
[city for city in fance.City.list if \
city.Language is not spanish and city.Population.isGraterThan(1000000)]
Is not a pie-in-the-sky dream-API - there are implementational details that are viable for each section.
First, the reason the "is not" would work, is that there would exist an implementation of 'Identity Mapping" that would take care of having a singleton for each ORM-object representing each row.
Second, the access to france.City.list is viable, as an attribute-access is totally customization in python, so we can devise anything we want for the access to do.
For example, it could return an iterator, if the "City" attribute of the "france" ORM-object is "valid" (meaning, it is cached and not "invalidated" by a previous transaction-commit), and do a "query" right-there on the spot, and "return" an iterator, if the "City" attribute of the "france" ORM-object is "invalid" at the time of the "list" attribute access.
I think the distinction between:
Customer.select
and
source.Customers
is quite important as the developer may be thinking quite differently in each. In the first, I am thinking that I'm grabbing objects from some store that is linked with the class Customer via an ORM. In the latter, I may think the same way, but I personally like to think of it as "I've got this object that has many customers and now I can play with them". That collection may be backed in a database, or it may just be a collection.
None of this is not already accomplished either in Python (generators or list comprehensions) or via the many community modules that address object-relational mapping or extend what itertools already gives you. However, what I can't find in Python is a unified API regardless of what the underlying mechanism of keeping my data is. To me, it doesn't matter if I'm calling into a for loop or generating a monster SQL statement. I'd rather write the same code regardless of which of these is going to happen under the hood.
Well, that depends a lot on the context in which this is executed.
If you have many queries similar to your example, before/around this line of code, that may reuse the same objects for other purposes (which is not uncommon)
It may in fact be slower to do it your way in many circumstances, because every specialized-query you are making is another round-trip to the database, which would be orders-of-magnitude slower than doing an eager-loading up-front, and filtering in python.
Also, you need to keep in mind that this is assuming a long-lasting set of objects that out-live a single transaction-operation.
Eager-vs-Lazy loading is configurable - both are supported, and you can use each in you core, depending on circumstances.
Anthony
Anthony
Eager-vsLazy loading is configurable - both are supported, and you can use each in you core, depending on circumstances.
As I said in the previouse message (I updated it since you posted this one). it depends - the trande-offs are circumstancial - that's why you need both approaches, and the ability to concigure each object to use one or the other in different circumstances - and that's what SQLA provides.
As for recursive-queries, it does not occur in eager-loading in SQLA.SQLA features what it called a "cascade", which means it "traverses" through the attribute-accesses, and only fetches what you actually asked for (well, it's not really "traversing", there are events that are triggered on each object's attribute-access...) this is for both lazy and eager loading configurations. The cascade makes sure that you only get what you explicitly asked for, no more, no less.
Arnon Marcus
If you're talking about building queries, your point is moot -- the operations happen in the database, not Python.
As for comparisons in Python, in web2py, you wouldn't be testing equality of a whole object/record -- typically it would be a scalar (e.g., the integer ID).
And you wouldn't have multiple copies of records in memory either.
Arnon Marcus
In web2py, we have lazy loading for individual references and referencing sets, and when that is inefficient, we would just do an explicit join. I think an eager loading option on the individual references would be a cool addition, though that wouldn't require an ORM layer.
Lazy loading requires a query for each attribute accessed, just as in web2py.
As for recursive-queries, it does not occur in eager-loading in SQLA. When you eager load in SQLA, it doesn't know ahead of time what attributes you will access, so it fetches everything (though in just one, or possibly two queries, depending on the eager method used).
Anthony
If you're talking about building queries, your point is moot -- the operations happen in the database, not Python.I don't know what you mean by this...For complex-queries, I would still be using web2py's DAL layer, even if I had this ORM on top. I would either use them outside the ORM, or insert them into the ORM.
My example was not meant to show that you should do complex queries in Python - that would obviously be absurd, and you don't even need a relational database for that - any NoSQL one would do fine.
I was giving an example to a case in which I have a simple comparison to make, and want to reuse the ORM objects I already have for it.The DAL is not built for that.
As for comparisons in Python, in web2py, you wouldn't be testing equality of a whole object/record -- typically it would be a scalar (e.g., the integer ID).That would still be much slower than an equality-test - especially for large data-sets.
And you wouldn't have multiple copies of records in memory either.How so?If I do this:row1 = db.Country[1]...row2 = db.Country[1]
Anthony
In web2py, we have lazy loading for individual references and referencing sets, and when that is inefficient, we would just do an explicit join. I think an eager loading option on the individual references would be a cool addition, though that wouldn't require an ORM layer.We've been though this already, Anthony, Laziness in web2py has a different meaning - it uses the same word, but it means something completely different.
Lazy loading requires a query for each attribute accessed, just as in web2py.Is plain false.
There is another mechanism that exists in SQLA that you are not accounting for, and it is statefullness - a caching-mechanism, using the 'Unit of Work' pattern. I don't know how many times and in how many forms I need to say this.
Arnon Marcus
Not sure what you mean here -- you can do simple queries in the db as well as complex filtering in Python -- they are orthogonal considerations.
Now you've really lost me -- what does any of this have to do with RDBMS vs. NoSQL? And why shouldn't you do complex filtering in Python?
Not sure what you mean. The DAL returns a Rows object. You can filter it with any simple or complex comparison you like. It even has a .find() method to simplify the process:db.Country(france).select().find(lambda r: r.Language != spanish and r.Population > 1000000)
OK, please provide some benchmarks. What percentage decrease in CPU usage can we expect if we compare object identities rather than integer equivalencies?
Anthony
RDBMS are built for complex filtering - this is (part) of what SQL is allabout - I wouldn't want to dismiss that - it would be a bad choice all-around.
Conversely, simple-filtering is way too verbose using the DAL - it's an overkill for that, and makes the code much less readable.
For simple filtering, well, I'd rather do it in python and get readability, becuase the performance-benefits are negligible.
Now you've really lost me -- what does any of this have to do with RDBMS vs. NoSQL? And why shouldn't you do complex filtering in Python?See above.
db.Country(france).select().find(lambda r: r.Language != spanish and r.Population > 1000000)That's actully pretty nice - I didn't know I can do that - but what would the "france" and "spanish" objects be in this case? Ids?
OK, please provide some benchmarks. What percentage decrease in CPU usage can we expect if we compare object identities rather than integer equivalencies?Really? You think I need to?
Arnon Marcus
Or, it's plain true. In SQLA, if you specify lazy loading of relationships (which is the default), the query is deferred until the first time you access the attribute, and there is therefore a query for each attribute accessed. This is in contrast to eager loading, which does a single query to populate all attributes (whether or not they are ever accessed).
db.Country(france).City.find(...)person = db.person(id)
for thing in person.thing.select(orderby=db.thing.name):
print person.name, 'owns', thing.nameArnon Marcus
A complex filter on a small set of items might be faster in Python than doing another database hit. And a simple filter might belong in the db if it has to go over lots of records. As I said, these are orthogonal considerations.
Conversely, simple-filtering is way too verbose using the DAL - it's an overkill for that, and makes the code much less readable.
Don't know why you think that.
For simple filtering, well, I'd rather do it in python and get readability, becuase the performance-benefits are negligible.
But I thought you were a fan of achieving negligible performance benefits at great cost (see below).
Still don't know why you would want a NoSQL database or what it has to do with this topic.
Well, you've sure made a lot of claims about what web2py needs without knowing much about what it already has. Anyway, those are ids. If they were rows, then you could just do france.id and spanish.id.
Yes, I think you need to. If this is only going to save a half a second of CPU time per day, I'm not going to build an ORM to get it. The question isn't how much faster the identity check is (and I don't think it's that much faster) -- the question is how much of your overall application CPU time is spent doing this kind of thing?

Philip Kilner
I really don't see that your requirements in this example are not a good
for web2py's DAL. I'd really like to understand what, if anything, I'm
missing here.
I'm originally an RDBMS developer, and what I think of as the
set-oriented approach of web2py's DAL is a much better fit for my mental
model of what my application is doing. Conversely, I find many ORM
solutions (and Active Record, come to that) to be an anti-pattern [1].
FWIW, my data is typically consumed by more than one application (e.g.
not just web2py), and I've tended to let web2py create and manage the
schema in its own way, and work in the db with views etc. to address
more complex or performance-critical functions, so perhaps my concerns
are different to yours. However, the examples you give don't seem to
take best advantage of the DAL to my eye.
Anthony provided some examples as to how one might do that, but you have
not responded directly to that post (apologies if I've missed your
response if it was elsewhere in the thread). I'd like to take the
liberty of quitting Anthony's responses and asking for your take on them.
On 02/05/13 22:20, Arnon Marcus wrote:
> Using the DAL, the best you might get is:
> >>> [city for city in db.City.Country.select() if city.Country.Name ==
> ''France']
> [<Row Name:Paris>, <Row Name:Nice>]
>
>>> db.Country(name='France').City.select()
> >>> europe = Continent(Name='Europe')
> >>> france = Country(Name='France', Continent=europe)
> >>> paris = City(Name='Paris', Country=france)
> >>> nice = City(Name='Nice', Country=france)
> >>>
> >>> europe.Country(Name='France') is france
> True
>>>> france.City(Name='Paris') is paris
> True
> >>> europe.Country(Name='France').City.list
> [<City Name:Paris>, <City Name:Nice>]
>
>>> europe = db.Continent.insert(Name='Europe')
>>> paris = db.City.insert(Name='Paris', Country=france)
>>> db.Country(france).City.select()
>
proposed syntax is any more intuitive or simpler than the web2py
suggestions, which to my eye are clearer by dint of being more explict?
Am I missing something here?
[1] http://seldo.com/weblog/2011/08/11/orm_is_an_antipattern
--
Regards,
PhilK
e: ph...@xfr.co.uk - m: 07775 796 747
'work as if you lived in the early days of a better nation'
- alasdair gray
Anthony
Or, it's plain true. In SQLA, if you specify lazy loading of relationships (which is the default), the query is deferred until the first time you access the attribute, and there is therefore a query for each attribute accessed. This is in contrast to eager loading, which does a single query to populate all attributes (whether or not they are ever accessed).I was interpreting your statement of "every access" to mean "every time you access the same attribute" and not to mean "every attribute you access".
Anthony, your use of language is sometimes ambiguous - it is not the first time I have misunderstood you - please be more specific next time. 10x :)
As for LazyLoading in web2py:We discussed this in the context of virtual-fields, and we've established that Lazyness in that context was NOT a deferred-access to the database, but a deferred-computation of the results within the run-time heap.
Are you now referring to Laziness in web2py within a different context?
Say, like in:
?
but a "Lazy access to the database" can only have meaning within the context of a statefull framework.
person = db.person(id) for thing in person.thing.select(orderby=db.thing.name): print person.name, 'owns', thing.nameWell, again, it IS "implicit", but why call it "Lazy"?
The "so-called" LazySet is in "person.thing" ?
If so, than it isn't "Lazy", just "implicit" and that's a bad choice of name...
- good thing it isn't in the documentation, as it would have generated even more confusion than already exists there...
The way I see it, the only meaning the term "Lazy" has for accessing-the-database, can exist within a statefull framework - which is, "in relation to eager-loading" that can only exist there.
Derek
RDBMS are built for complex filtering - this is (part) of what SQL is allabout - I wouldn't want to dismiss that - it would be a bad choice all-around.
A complex filter on a small set of items might be faster in Python than doing another database hit. And a simple filter might belong in the db if it has to go over lots of records. As I said, these are orthogonal considerations.
Conversely, simple-filtering is way too verbose using the DAL - it's an overkill for that, and makes the code much less readable.
Don't know why you think that.
For simple filtering, well, I'd rather do it in python and get readability, becuase the performance-benefits are negligible.
But I thought you were a fan of achieving negligible performance benefits at great cost (see below).
Now you've really lost me -- what does any of this have to do with RDBMS vs. NoSQL? And why shouldn't you do complex filtering in Python?See above.
Still don't know why you would want a NoSQL database or what it has to do with this topic.
db.Country(france).select().find(lambda r: r.Language != spanish and r.Population > 1000000)
That's actully pretty nice - I didn't know I can do that - but what would the "france" and "spanish" objects be in this case? Ids?
Well, you've sure made a lot of claims about what web2py needs without knowing much about what it already has. Those are ids. If they were rows, then you would just do france.id and spanish.id.
OK, please provide some benchmarks. What percentage decrease in CPU usage can we expect if we compare object identities rather than integer equivalencies?Really? You think I need to?
Yes, I think you need to. If this is only going to save a half a second of CPU time per day, I'm not going to build an ORM to get it. The question isn't how much faster the identity check is (and I don't think it's that much faster) -- the question is how much of your overall application CPU time is spent doing this kind of thing?
Anthony
Anthony
A complex filter on a small set of items might be faster in Python than doing another database hit. And a simple filter might belong in the db if it has to go over lots of records. As I said, these are orthogonal considerations.
Perhaps, but again, we are talking about a context of a statefull system - we might already have some data on our object-graph - so it's more complicated then that...
- If we're talking about the first query of a transaction, we need to think about the context of that whole transaction - will we be using all of the fields in the subsequent attribute-accesses? How about the of the records? Do we need all of them for our access-pattern later on? How should we construct our query so it's optimal for re-use of the results in subsequent attribute-accesses of that same transaction? Such considerations do not even exist in a stateless system like web2py's DAL - it doesn't have the same kind of re-usability of returned data.
For simple filtering, well, I'd rather do it in python and get readability, becuase the performance-benefits are negligible.
But I thought you were a fan of achieving negligible performance benefits at great cost (see below).
Now you're being cynical...
I meant it as a hypothetical-alternative to an imaginary scenario of me doing ALL the filtering in python - for THAT I said "well I might-as-well use NoSql"
Well, you've sure made a lot of claims about what web2py needs without knowing much about what it already has. Those are ids. If they were rows, then you would just do france.id and spanish.id.
I was simply avoiding making assumptions in that example, as there was no context for these variables in it.
you may still benefit from an "Identity Mapper" in an ORM, in terms of memory-efficiency
even if you stick to your ugly "!="s and "=="s....
- it was just an example of readability that can be harnesses