[vim/vim] Added support for underscore digit separator in Python syntax (#8024)

Dominique Pellé
This PR adds support for recognizing Python numbers with underscore digit separator introduced in Python-3.6:
Attached picture shows:
- numbers with correct syntax (
# good), which are all correctly highlighted in Vim - numbers with incorrect syntax (
# bad), which are all not highlighted
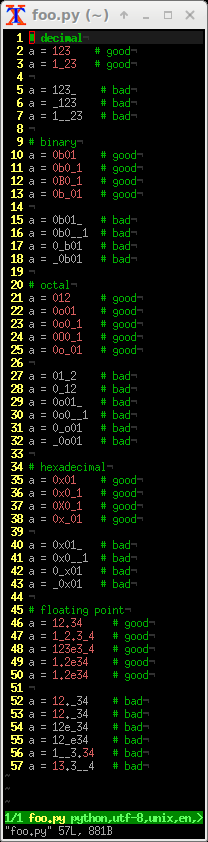
You can view, comment on, or merge this pull request online at:
https://github.com/vim/vim/pull/8024
Commit Summary
- Added support for underscore digit separator in Python syntax
File Changes
- M runtime/syntax/python.vim (25)
Patch Links:
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub, or unsubscribe.![]()
Dominique Pellé
CC @zvezdan who is the maintainer of the runtime/syntax/python.vim file.
codecov[bot]
Codecov Report
Merging #8024 (02c3b91) into master (f49a1fc) will decrease coverage by
86.75%.
The diff coverage isn/a.
❗ Current head 02c3b91 differs from pull request most recent head 99ddd89. Consider uploading reports for the commit 99ddd89 to get more accurate results

@@ Coverage Diff @@ ## master #8024 +/- ## =========================================== - Coverage 89.23% 2.48% -86.76% =========================================== Files 148 146 -2 Lines 165599 160498 -5101 =========================================== - Hits 147779 3990 -143789 - Misses 17820 156508 +138688
| Flag | Coverage Δ | |
|---|---|---|
| huge-clang-none | ? |
|
| huge-gcc-none | ? |
|
| huge-gcc-testgui | ? |
|
| huge-gcc-unittests | 2.48% <ø> (ø) |
Flags with carried forward coverage won't be shown. Click here to find out more.
| Impacted Files | Coverage Δ | |
|---|---|---|
| src/sha256.c | 0.00% <0.00%> (-97.96%) |
⬇️ |
| src/digraph.c | 0.00% <0.00%> (-97.78%) |
⬇️ |
| src/gui_gtk_f.c | 0.00% <0.00%> (-97.54%) |
⬇️ |
| src/match.c | 0.00% <0.00%> (-97.13%) |
⬇️ |
| src/crypt_zip.c | 0.00% <0.00%> (-97.06%) |
⬇️ |
| src/evalbuffer.c | 0.00% <0.00%> (-96.83%) |
⬇️ |
| src/debugger.c | 0.00% <0.00%> (-96.62%) |
⬇️ |
| src/libvterm/src/rect.h | 0.00% <0.00%> (-96.56%) |
⬇️ |
| src/textprop.c | 0.00% <0.00%> (-96.41%) |
⬇️ |
| src/eval.c | 0.10% <0.00%> (-96.13%) |
⬇️ |
| ... and 134 more |
Continue to review full report at Codecov.
Legend - Click here to learn more
Δ = absolute <relative> (impact),ø = not affected,? = missing data
Powered by Codecov. Last update f49a1fc...99ddd89. Read the comment docs.
Zvezdan Petkovic
@zvezdan commented on this pull request.
> @@ -156,18 +156,25 @@ syn match pythonEscape "\\$" " " and so on, as specified in the 'Python Language Reference'. " https://docs.python.org/reference/lexical_analysis.html#numeric-literals +"
As mentioned in #7923 I'm already preparing a lot of other changes including this one.
The support for Python 2 has already been dropped for keywords and builtins in PR #7855 and I am dropping it in my changes for this part as well.
The only difference is that I now have to make a separate PR for just this change because of sudden urgency of underscores in numbers as evidenced by two PRs related to it in last 24 hours. :ili
Zvezdan Petkovic
> if !exists("python_no_number_highlight")
- " numbers (including longs and complex)
- syn match pythonNumber "\<0[oO]\=\o\+[Ll]\=\>"
- syn match pythonNumber "\<0[xX]\x\+[Ll]\=\>"
- syn match pythonNumber "\<0[bB][01]\+[Ll]\=\>"
- syn match pythonNumber "\<\%([1-9]\d*\|0\)[Ll]\=\>"
- syn match pythonNumber "\<\d\+[jJ]\>"
- syn match pythonNumber "\<\d\+[eE][+-]\=\d\+[jJ]\=\>"
+ " Numbers (including longs and complex).
+ syn match pythonNumber "\<0\=\o\+[Ll]\=\>"
This is not a valid syntax any more. I'm removing it in my upcoming change.
> + syn match pythonNumber "\<0[oO]\%(_\=\o\+\)*[Ll]\=\>" + syn match pythonNumber "\<0[xX]\%(_\=\x\+\)*[Ll]\=\>" + syn match pythonNumber "\<0[bB]\%(_\=[01]\+\)*[Ll]\=\>" + syn match pythonNumber "\<\%([1-9]\%(_\=\d\+\)*\|0\)[Ll]\=\>"
In pretty much all the lines, there's no need for a \+ after octal, hex, binary, or decimal digits, because the underscore being optional with _\= already allows for any number of digits repeated without the underscore due to the * after the whole group.
Also, use of \+ followed by * makes the regular expression processing extremely slow and breaks the highlighting on my test files.
> if !exists("python_no_number_highlight")
- " numbers (including longs and complex)
- syn match pythonNumber "\<0[oO]\=\o\+[Ll]\=\>"
- syn match pythonNumber "\<0[xX]\x\+[Ll]\=\>"
- syn match pythonNumber "\<0[bB][01]\+[Ll]\=\>"
- syn match pythonNumber "\<\%([1-9]\d*\|0\)[Ll]\=\>"
- syn match pythonNumber "\<\d\+[jJ]\>"
- syn match pythonNumber "\<\d\+[eE][+-]\=\d\+[jJ]\=\>"
+ " Numbers (including longs and complex).
+ syn match pythonNumber "\<0\=\o\+[Ll]\=\>"
+ syn match pythonNumber "\<0[oO]\%(_\=\o\+\)*[Ll]\=\>"
+ syn match pythonNumber "\<0[xX]\%(_\=\x\+\)*[Ll]\=\>"
+ syn match pythonNumber "\<0[bB]\%(_\=[01]\+\)*[Ll]\=\>"
+ syn match pythonNumber "\<\%([1-9]\%(_\=\d\+\)*\|0\)[Ll]\=\>"
+ syn match pythonNumber "\<\%(_\=\d\+\)*[jJ]\>"
This would highlight invalid literals such as
j
_1j
as valid complex numbers.
My upcoming change does not have that issue.
> syn match pythonNumber - \ "\%(^\|\W\)\zs\d*\.\d\+\%([eE][+-]\=\d\+\)\=[jJ]\=\>" + \ "\%(^\|\W\)\zs\%(_\=\d\+\)*\.\d\%(_\=\d\+\)*\%([eE][+-]\=\d\%(_\=\d\+\)*\)\=[jJ]\=\>"
This would highlight _invalid literal, such as
_1.2j
_1.2e3
as valid numbers.
Again, the upcoming change does not have this issue.
Zvezdan Petkovic
The PR #8033 resolves this same issue.
Can this PR be closed without merging, please?
K.Takata
Closed #8024.
K.Takata
Closing then.