[vim/vim] Search fails for char+combining_char when char is a [class] (Issue #12361)

Peter Kenny
Steps to reproduce
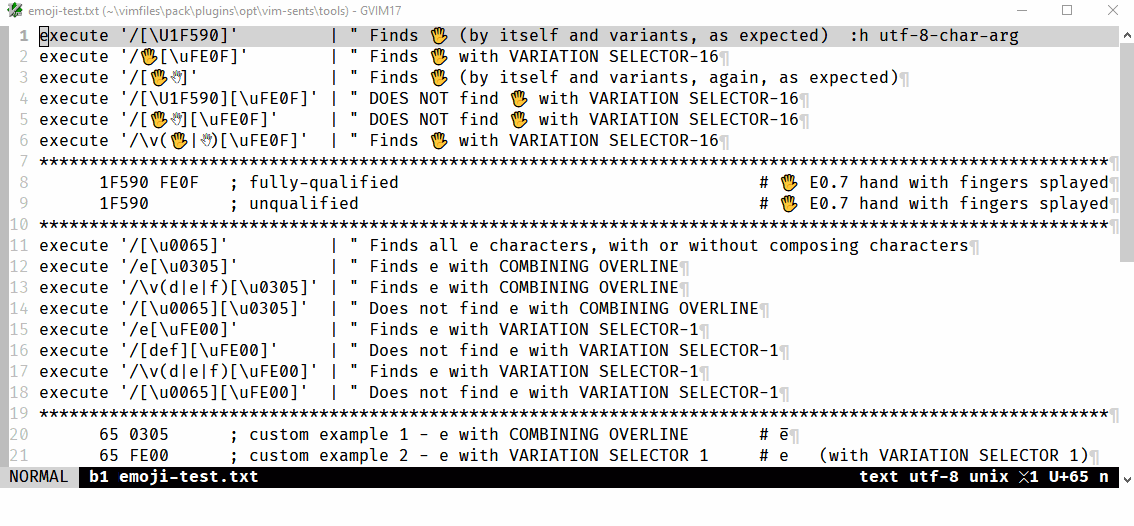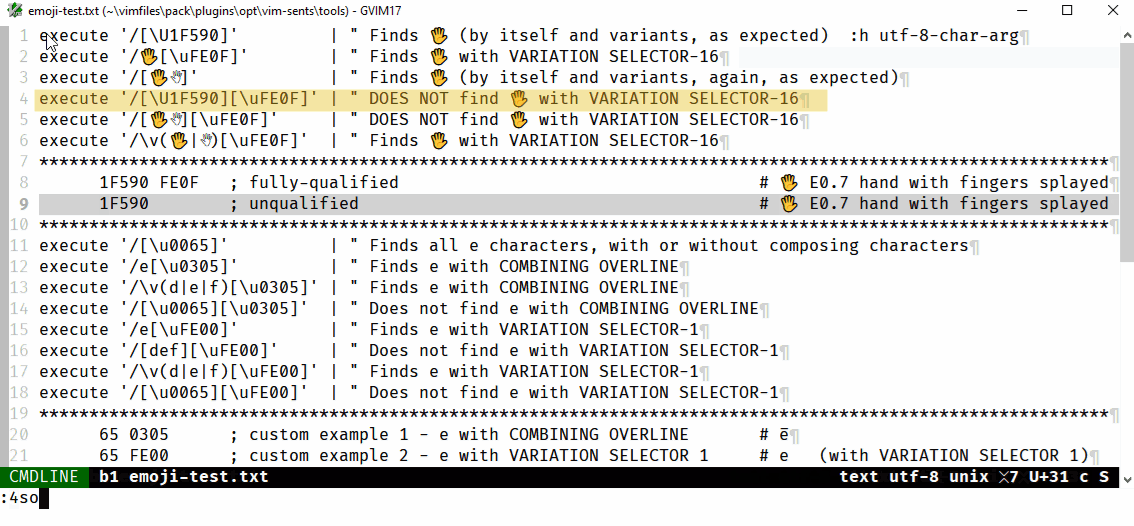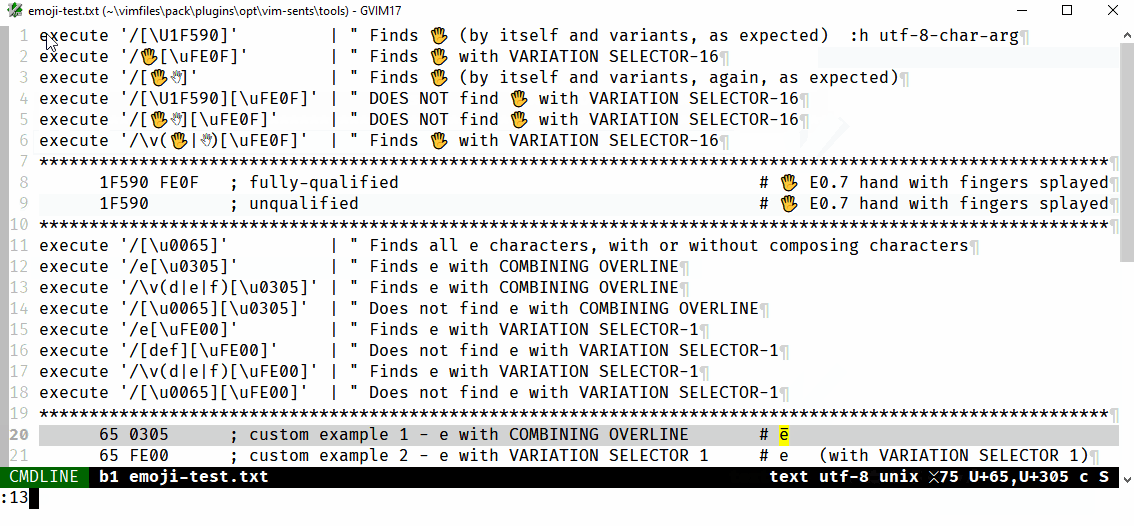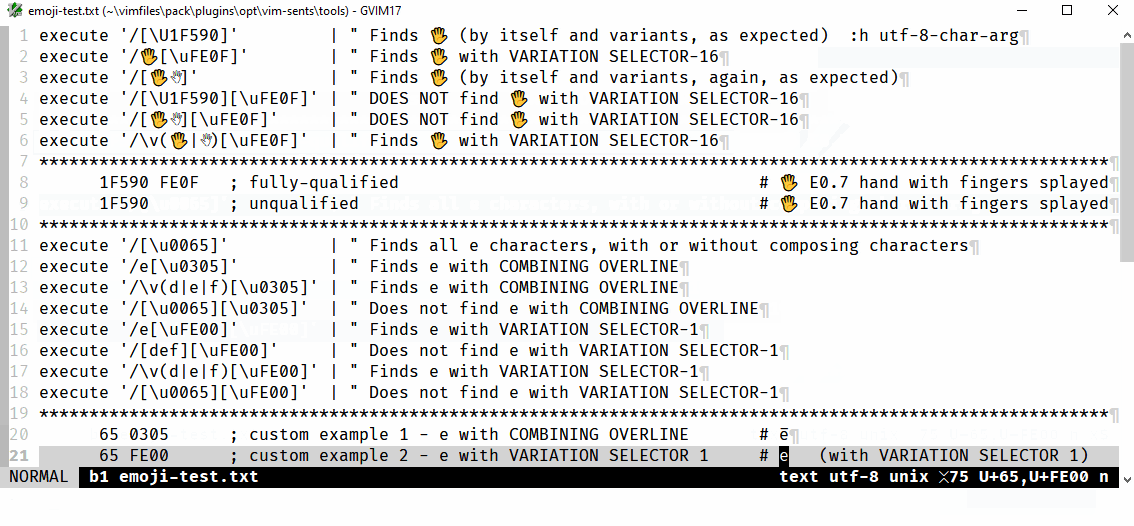
The following will find e̅ (U+0065,U+0305, i.e., a lowercase e plus combining overline):
/e[\u0305]
/\v(d|e|f)[\u0305]
whereas the following do not:
/[\u0065][\u0305]
/[def][\u0305]
This appears to be a specific issue for classes, i.e., where the char is not expressed as the literal character, of char+combining_char searches. Further examples are provided in the .gif that follows, which shows that the same issue occurs for variation selectors, but the examples above sum it up: if there is a [class] for the first/main char it will not find char+combining_char. Note, not shown, \a, instead of [A-Za-z], similarly fails.
Expected behaviour
/[\u0065][\u0305] and /[def][\u0305] should find e̅ just as /e[\u0305] and /\v(d|e|f)[\u0305] do.
Version of Vim
9.0.1488
Environment
Windows 10 gvim, though really the issue is not O/S related (noting the same results occur in WSL running Debian 11 and vim 8.2.5172).
Logs and stack traces
No response
—
Reply to this email directly, view it on GitHub.
You are receiving this because you are subscribed to this thread.![]()
Bram Moolenaar
> ### Steps to reproduce
>
> The following will find **e̅** (U+0065,U+0305, i.e., a lowercase e plus
> combining overline):
>
> `/e[\u0305]`
> `/\v(d|e|f)[\u0305]`
>
> whereas the following do not:
>
> `/[\u0065][\u0305]`
> `/[def][\u0305]`
>
> This appears to be a specific issue for classes, i.e., where the char
> is not expressed as the literal character, of char+combining_char
> searches. Further examples are provided in the .gif that follows,
> which shows that the same issue occurs for variation selectors, but
> the examples above sum it up: if there is a [class] for the first/main
> char it will not find char+combining_char. Note, not shown, \a,
> instead of [A-Za-z], similarly fails.
>
>
>
> ### Expected behaviour
>
> `/[\u0065][\u0305]` and `/[def][\u0305]` should find **e̅** just as
> `/e[\u0305]` and `/\v(d|e|f)[\u0305]` do.
Searching for just "e" doesn't match the character either, which can
also be unexpected.
I doubt this can be changed without causing something else to work in an
unexpected way. There is no universal specification of how patterns
match on combining characters, we can have a very long discussion about
how it should work. And whatever changes we might decide to make, is
not going to be backwards compatible. Therefore I tend to just leave it
alone.
--
When a fly lands on the ceiling, does it do a half roll or
a half loop?
/// Bram Moolenaar -- ***@***.*** -- http://www.Moolenaar.net \\\
/// \\\
\\\ sponsor Vim, vote for features -- http://www.Vim.org/sponsor/ ///
\\\ help me help AIDS victims -- http://ICCF-Holland.org ///
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
Peter Kenny
Is that really expected? I'm not sure what the behavior should be. Searching for just "e" doesn't match the character either, which can also be unexpected. I doubt this can be changed without causing something else to work in an unexpected way. There is no universal specification of how patterns match on combining characters, we can have a very long discussion about how it should work. And whatever changes we might decide to make, is not going to be backwards compatible. Therefore I tend to just leave it alone.
Thanks, though yes, I think most people would expect it to work like that. To illustrate, the alphabetic examples can be worked around with something like this (ugly) substitution, turning those combined characters into to hexadecimal character references:
%s_\v(a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z)([\u0300-\u036F])_\=printf("&#x%04x;&#x%04x;", char2nr(submatch(1)), char2nr(submatch(2)))_gi
However, why should this substitution, which is synonymous, not work?
%s_\v([[:alpha:]])([\u0300-\u036F])_\=printf("&#x%04x;&#x%04x;", char2nr(submatch(1)), char2nr(submatch(2)))_g
As the help says (pattern.txt), "A character class expression is evaluated to the set of characters belonging to that character class", which objectively is not what is happening in the second substitution.
And, although it is an annoyance for alphabetic characters, at least the first one (a|b|c...) can be used, whereas for emoji (https://unicode.org/Public/emoji/15.0/emoji-test.txt) it gets more cumbersome and uglier ...
%s_\v(♨|☘|✈|🛩)([\uFE0F])_\=printf("&#x%04x;&#x%04x;", char2nr(submatch(1)), char2nr(submatch(2)))_g
This does work, and could be extended to work for 100+ emoji that may have a combining VARIATION SELECTOR-16. But including those literally in that first parenthetical grouping seems really inefficient and inconvenient. More importantly, it would be impossible to account for any character that has a variation selector because then you would need tens of thousands of literal characters in that first parenthetical group. The consequence of that is any global replace on characters where they have a variation selector of any form will "break" the combined character, e.g., %sm_\([\U10000-\U10ffff]\)_\=printf("\\U%08x", char2nr(submatch(0)))_g would be fine for substituting non-combined Unicode characters between U+10000 and U+10FFFF but would remove/delete any combining character altogether.
Ideally, where the combining character is in either the range U+0300 to U+036F (https://www.unicode.org/charts/PDF/U0300.pdf) or the range U+FE00 to U+FE0F (https://www.unicode.org/charts/PDF/UFE00.pdf), the first character in the combination should be searchable with a range/class too, not only with literals. However, if that would potentially break something and/or create backwards compatibility issues, I think help on the topic is worth adding, explaining the limitation/exception. That help could even show some workaround examples I have outlined here?
—
Reply to this email directly, view it on GitHub.
You are receiving this because you are subscribed to this thread.![]()
Christian Brabandt
Searching for just "e" doesn't match the character either, which can also be unexpected.
That's why we have the \Z and \%C modifiers for the pattern.
I would also think it's a bug, at least [e][\u0305] should work the same as e[\u305] I think.
—
Reply to this email directly, view it on GitHub.
You are receiving this because you are subscribed to this thread.![]()
Bram Moolenaar
> > Searching for just "e" doesn't match the character either, which can
> > also be unexpected.
>
> That's why we have the `\Z` and `\%C` modifiers for the pattern.
>
> I would also think it's a bug, at least `[e][\u0305]` should work the
> same as `e[\u305]` I think.
combining character? I suspect the implementation checks if there are
no following combining characters to avoid a false match when the
patterns ends after "[e]". Also, having part of the pattern match after
a base character is going to be hard to get right. We don't have a way
to specify part of the pattern must match on the base character and
another part must match a following combining character.
Perhaps it can be improved a little bit, but I doubt it can be made work
in general and without making it very hard to understand.
--
Anyone who is capable of getting themselves made President should on no
account be allowed to do the job.
-- Douglas Adams, "The Hitchhiker's Guide to the Galaxy"
/// Bram Moolenaar -- ***@***.*** -- http://www.Moolenaar.net \\\
/// \\\
\\\ sponsor Vim, vote for features -- http://www.Vim.org/sponsor/ ///
\\\ help me help AIDS victims -- http://ICCF-Holland.org ///
—
Reply to this email directly, view it on GitHub.
You are receiving this because you are subscribed to this thread.![]()
Peter Kenny
Searching for just "e" doesn't match the character either, which can also be unexpected.
That's why we have the
\Zand\%Cmodifiers for the pattern.I would also think it's a bug, at least
[e][\u0305]should work the same ase[\u305]I think.
Agree, though note \%C has challenges too. For example, it works for s/\%Ca/_/gc in not finding a in an a combined with grave, whereas s/\%C[\u0061]/_/gc will find it, which arguably is not right because it is another example of a synonymous search not working consistently. Voilà, my voila is not a "voilà"! ☺️
To illustrate the lengths you have to go to to work around not being able to use the class for both character and composing character, to find all emoji in Unicode 15 that may have variation selector-16 following them:
s_\v(☺|☹|☠|❣|❤|🕳|🗨|🗯|🖐|✌|☝|✍|👁|🕵|🕴|⛷|🏌|⛹|🏋|🗣|🐿|🕊|🕷|🕸|🏵|☘|🌶|🍽|🗺|🏔|⛰|🏕|🏖|🏜|🏝|🏞|🏟|🏛|🏗|🏘|🏚|⛩|🏙|♨|🏎|🏍|🛣|🛤|🛢|🛳|⛴|🛥|✈|🛩|🛰|🛎|⏱|⏲|🕰|🌡|☀|☁|⛈|🌤|🌥|🌦|🌧|🌨|🌩|🌪|🌫|🌬|☂|⛱|❄|☃|☄|🎗|🎟|🎖|⛸|🕹|♠|♥|♦|♣|♟|🖼|🕶|🛍|⛑|🎙|🎚|🎛|☎|🖥|🖨|⌨|🖱|🖲|🎞|📽|🕯|🗞|🏷|✉|🗳|✏|✒|🖋|🖊|🖌|🖍|🗂|🗒|🗓|🖇|✂|🗃|🗄|🗑|🗝|⛏|⚒|🛠|🗡|⚔|🛡|⚙|🗜|⚖|⛓|⚗|🛏|🛋|⚰|⚱|⚠|☢|☣|⬆|↗|➡|↘|⬇|↙|⬅|↖|↕|↔|↩|↪|⤴|⤵|⚛|🕉|✡|☸|☯|✝|☦|☪|☮|▶|⏭|⏯|◀|⏮|⏸|⏹|⏺|⏏|♀|♂|⚧|✖|♾|‼|⁉|〰|⚕|♻|⚜|☑|✔|〽|✳|✴|❇|©|®|™|🅰|🅱|ℹ|Ⓜ|🅾|🅿|🈂|🈷|㊗|㊙|◼|◻|▪|▫|🏳)([\ufe0f])_=printf("\U%08x\u%04x", char2nr(submatch(1)), char2nr(submatch(2)))_g
You can then safely (for these characters anyhow) do a class substitution, including the unqualified variants of these emoji. But you will still "break" any other combined characters with variation selectors FE00 to FE0F. You also cannot use \%C to ignore the combining character in that range, which I guess is because only https://www.unicode.org/charts/PDF/U0300.pdf are ignored? E.g., /\%C[☺]️ finds both the unqualified and fully-qualified emoji, which are different: ☺ is U+236A whereas ☺️ is U+236A,U+FE0F: although they look identical in GitHub (unless put in a code block, oddly), in other applications they are clearly distinguished, e.g., Word:

—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()
Peter Kenny
Hi. This issue has been quiet for a few months. While I was working on something else, I found a fair workaround. That is, preprocessing all combining characters in a buffer to another form (such as hexadecimal character references). That way, substitutions may then be run on classes for one or both the character and/or the combining character(s).
Documentation and plugin - vim-combining2.
Should the issue be closed? There are aspects of it that I still thing are buggy - echoing @chrisbra's point, "I would also think it's a bug, at least [e][\u0305] should work the same as e[\u305]".
But, if it's going nowhere there's no point keeping it open. Thoughts?
—
Reply to this email directly, view it on GitHub.
You are receiving this because you are subscribed to this thread.![]()
agguser
:set re=1, and use /[e]̅ (or /[e]\%u0305, /[e][\u0305], /[def][\u0305]; or /e\%C, /\Ze) to match e̅.
In summary, :set re=1, and:
- match a base character 'b' with
/[b] - match a combining character 'c' with just
/c - match a base character 'b' followed by a combining character 'c' with
/bc(or/[b]cif there may be more combining characters after 'c') - substitute a base character 'b' with
:s/[b]/X/g - substitute a combining character 'c' with
:s/[^c]\?\zs[c]/X/g. Not sure if there is a better or more concise way. And this does not work if c is a second or more combining character. So use an external tool instead (e.g.!sed 's/c/X/g')
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.![]()