[vim/vim] Add the matchfuzzy() function (#6932)

Yegappan Lakshmanan
Add a function for fuzzy matching a string against a list of strings and
return a list of matching strings.
This is ported from the lib_fts library developed by Forrest Smith.
A blog describing the algorithm is at
https://www.forrestthewoods.com/blog/reverse_engineering_sublime_texts_fuzzy_match
The code for this library is at:
https://github.com/forrestthewoods/lib_fts/tree/master/code
You can view, comment on, or merge this pull request online at:
https://github.com/vim/vim/pull/6932
Commit Summary
- Add the matchfuzzy() function
File Changes
- M runtime/doc/eval.txt (16)
- M runtime/doc/usr_41.txt (1)
- M src/evalfunc.c (345)
- M src/testdir/test_functions.vim (9)
Patch Links:
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub, or unsubscribe.![]()
codecov[bot]
Codecov Report
Merging #6932 into master will decrease coverage by
0.00%.
The diff coverage is85.96%.

@@ Coverage Diff @@ ## master #6932 +/- ## ========================================== - Coverage 88.54% 88.54% -0.01% ========================================== Files 148 148 Lines 161169 161283 +114 ========================================== + Hits 142711 142804 +93 - Misses 18458 18479 +21
| Impacted Files | Coverage Δ | |
|---|---|---|
| src/evalfunc.c | 95.90% <85.96%> (-0.36%) |
⬇️ |
| src/netbeans.c | 76.07% <0.00%> (-0.23%) |
⬇️ |
| src/if_xcmdsrv.c | 88.73% <0.00%> (-0.18%) |
⬇️ |
| src/os_unix.c | 70.39% <0.00%> (-0.09%) |
⬇️ |
| src/channel.c | 89.92% <0.00%> (-0.06%) |
⬇️ |
| src/gui.c | 63.40% <0.00%> (-0.05%) |
⬇️ |
| src/gui_gtk_x11.c | 58.93% <0.00%> (ø) |
|
| src/terminal.c | 91.06% <0.00%> (+0.03%) |
⬆️ |
| src/gui_gtk.c | 31.67% <0.00%> (+0.27%) |
⬆️ |
Continue to review full report at Codecov.
Legend - Click here to learn more
Δ = absolute <relative> (impact),ø = not affected,? = missing data
Powered by Codecov. Last update 8b848ca...0086988. Read the comment docs.
Christian Brabandt
Wow, this is very nice!
Bram Moolenaar
Thanks. A few minor comments.
The example should mention what the result is.
I'm wondering if for the method it should pass the list (as it is now) or the string to match?
Which one would be changing most often?
A few practical usage examples would help.
Bram Moolenaar
Oh, and the implementation fits better in search.c than in evalfunc.c (which is already very long)
lacygoill
I'm wondering if for the method it should pass the list (as it is now) or the string to match?
I think it should pass the list. The question is not so much which one would vary, but which one we would get via the output of another function. In practice, I think it would be the list.
A few practical usage examples would help.
I could come up with a few (fuzzy search a buffer name via getbufinfo() + map() + fuzzymatch(); fuzzy search a colorscheme name via getcompletion() + fuzzymatch(); fuzzy search a string in an arbitrary buffer via getbufline() + fuzzymatch(); ...), but the function makes Vim crash too often.
Example:
vim9script ['somebuf', 'anotherone', 'needle', 'yetanotherone'] ->map({_, v -> bufadd(v) + bufload(v)}) echom getbufinfo() ->map({_, v -> v.name}) ->matchfuzzy('ndl')
vim9script echo getbufinfo() ->map({_, v -> v.name}) ->matchfuzzy('fbr')

Yegappan Lakshmanan
Thanks. A few minor comments.
The example should mention what the result is.
I'm wondering if for the method it should pass the list (as it is now) or the string to match?
Which one would be changing most often?
A few practical usage examples would help.
vim-dev ML
Yegappan Lakshmanan
Oh, and the implementation fits better in search.c than in evalfunc.c (which is already very long)
vim-dev ML
Yegappan Lakshmanan
I'm wondering if for the method it should pass the list (as it is now) or the string to match?
I think it should pass the list. The question is not so much which one would vary, but which one we would get via the output of another function. In practice, I think it would be the list.
A few practical usage examples would help.
I could come up with a few (fuzzy search a buffer name via
getbufinfo()+map()+fuzzymatch(); fuzzy search a colorscheme name viagetcompletion()+fuzzymatch(); fuzzy search a string in an arbitrary buffer viagetbufline()+fuzzymatch(); ...), but the function makes Vim crash too often.Example:
vim9script ['somebuf', 'anotherone', 'needle', 'yetanotherone'] ->map({_, v -> bufadd(v) + bufload(v)}) echom getbufinfo() ->map({_, v -> v.name}) ->matchfuzzy('ndl')vim9script echo getbufinfo() ->map({_, v -> v.name}) ->matchfuzzy('fbr')
vim-dev ML
On Fri, Sep 11, 2020 at 7:09 AM lacygoill <vim-dev...@256bit.org> wrote:
> I'm wondering if for the method it should pass the list (as it is now) or
> the string to match?
>
> I think it should pass the list. The question is not so much which one
> would vary, but which one we would get via the output of another function.
> In practice, I think it would be the list.
>
> A few practical usage examples would help.
>
> I could come up with a few (fuzzy search a buffer name via getbufinfo() +
> map() + fuzzymatch(); fuzzy search a colorscheme name via getcompletion()
> + fuzzymatch(); fuzzy search a string in an arbitrary buffer via
> getbufline() + fuzzymatch(); ...), but the function makes Vim crash too
> often.
>
> Example:
>
> vim9script
> ['somebuf', 'anotherone', 'needle', 'yetanotherone']
> ->map({_, v -> bufadd(v) + bufload(v)})
> echom getbufinfo()
> ->map({_, v -> v.name})
> ->matchfuzzy('ndl')
>
> - valgrind log <https://github.com/vim/vim/files/5209510/valgrind.log>
> - asan log <https://github.com/vim/vim/files/5209508/asan.log>
>
>
>
Thanks for reporting this issue. I have fixed it now. Can you check it in
the next update?
Thanks,
Yegappan
lacygoill
BTW, should we call this function matchfuzzy() or fuzzymatch()? Any preferences?
I think it should be matchfuzzy() because it would better fit in the current family of match*() functions. This way, a plugin's writer can more easily find it:
:h match*( C-d
match() matchend() matchaddpos() assert_match() setmatches()
matchadd() matchstr() matchdelete() submatch() clearmatches()
matcharg() matchlist() matchstrpos() getmatches() assert_notmatch()
matchfuzzy()
^----------^
Thanks for reporting this issue. I have fixed it now. Can you check it in the next update?
Thank you for fixing it. I will check when the PR is updated.
—
You are receiving this because you commented.
Dominique Pellé
@dpelle commented on this pull request.
> @@ -7307,6 +7308,22 @@ matchend({expr}, {pat} [, {start} [, {count}]]) *matchend()*
Can also be used as a |method|: >
GetText()->matchend('word')
+matchfuzzy({list}, {str}) *matchfuzzy()*
+ Returns a list with all the strings in {list} that fuzzy
+ matches {str}. The strings in the returned list are sorted
+ based on the matching score. {str} is treated as a literal
+ string and regular expression matching is NOT supported.
+ The maximum supported {str} length is 256.
What happens if {str} length is > 256?
—
You are receiving this because you commented.
Yegappan Lakshmanan
@dpelle commented on this pull request.
> @@ -7307,6 +7308,22 @@ matchend({expr}, {pat} [, {start} [, {count}]]) *matchend()* Can also be used as a |method|: > GetText()->matchend('word') +matchfuzzy({list}, {str}) *matchfuzzy()* + Returns a list with all the strings in {list} that fuzzy + matches {str}. The strings in the returned list are sorted + based on the matching score. {str} is treated as a literal + string and regular expression matching is NOT supported. + The maximum supported {str} length is 256.What happens if {str} length is > 256?
vim-dev ML
> ------------------------------
>
> In runtime/doc/eval.txt
> <https://github.com/vim/vim/pull/6932#discussion_r487144365>:
>
> > @@ -7307,6 +7308,22 @@ matchend({expr}, {pat} [, {start} [, {count}]]) *matchend()*
> Can also be used as a |method|: >
> GetText()->matchend('word')
>
> +matchfuzzy({list}, {str}) *matchfuzzy()*
> + Returns a list with all the strings in {list} that fuzzy
> + matches {str}. The strings in the returned list are sorted
> + based on the matching score. {str} is treated as a literal
> + string and regular expression matching is NOT supported.
> + The maximum supported {str} length is 256.
>
> What happens if {str} length is > 256?
>
>
>
If the length of {str} is > 256, then returns an empty list. I will update
the help.
Regards,
Yegappan

Bram Moolenaar
Yegappan wrote:
> BTW, should we call this function matchfuzzy() or fuzzymatch()?
> Any preferences?
together.
In the past we have not put the most important property first, which
causes related methods to be scattered. So getmatches() sorts far
away from other match functions. matchesget() might have been better,
although it doesn't sounds so good.
--
ARTHUR: No, hang on! Just answer the five questions ...
GALAHAD: Three questions ...
ARTHUR: Three questions ... And we shall watch ... and pray.
"Monty Python and the Holy Grail" PYTHON (MONTY) PICTURES LTD
/// Bram Moolenaar -- Br...@Moolenaar.net -- http://www.Moolenaar.net \\\
/// sponsor Vim, vote for features -- http://www.Vim.org/sponsor/ \\\
\\\ an exciting new programming language -- http://www.Zimbu.org ///
\\\ help me help AIDS victims -- http://ICCF-Holland.org ///
vim-dev ML
Christian Brabandt
Just some minor comments:
BTW, should we call this function matchfuzzy() or fuzzymatch()?
matchfuzzy() mostly because it groups with the other match functions or alternatively searchfuzzy() because it's more or less a search function.
I'm wondering if for the method it should pass the list (as it is now) or the string to match?
I would expect it to be a method of a list and therefore pass the string, similar to how match() works. I just like being consistent here.
If the length of {str} is > 256, then returns an empty list.
Perhaps a test with multibyte characters would be useful as well?
—
You are receiving this because you commented.
Yegappan Lakshmanan
Just some minor comments:
BTW, should we call this function matchfuzzy() or fuzzymatch()?
matchfuzzy() mostly because it groups with the other match functions or alternatively searchfuzzy() because it's more or less a search function.
I'm wondering if for the method it should pass the list (as it is now) or the string to match?
I would expect it to be a method of a list and therefore pass the string, similar to how match() works. I just like being consistent here.
If the length of {str} is > 256, then returns an empty list.
Perhaps a test with multibyte characters would be useful as well?
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Yegappan Lakshmanan
A few practical usage examples would help.
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
+1 for adding fuzzy match.
A bit late to this. But few questions.
How do we use matchfuzzy for a list of dictionary instead of item. Primary reason for this is LSP (language server protocol) makes heavy use of user_data. Can you add an example for sorting a list whose type is dict [ { 'word': 'foo', user_data: 1}, { 'word': 'foobar', user_data: 2}, { 'word': 'bar', user_data: 3} ]. Should we have a 3rd optional parameter that takes a callback?
let completeitems = [ \ { 'word': 'foo', user_data: 1}, \ { 'word': 'foobar', user_data: 2}, \ { 'word': 'bar', user_data: 3} \ ] let filtertedlist = matchfuzzy(completeitems, 'foo', {item->item['word']})
Can we also have this support set completeopt+=matchfuzzy?
—
You are receiving this because you commented.
Yegappan Lakshmanan
+1 for adding fuzzy match.
A bit late to this. But few questions.
How do we use matchfuzzy for a list of dictionary instead of item. Primary reason for this is LSP (language server protocol) makes heavy use of user_data. Can you add an example for sorting a list whose type is dict
[ { 'word': 'foo', user_data: 1}, { 'word': 'foobar', user_data: 2}, { 'word': 'bar', user_data: 3} ]. Should we have a 3rd optional parameter that takes a callback?let completeitems = [ \ { 'word': 'foo', user_data: 1}, \ { 'word': 'foobar', user_data: 2}, \ { 'word': 'bar', user_data: 3} \ ] let filtertedlist = matchfuzzy(completeitems, 'foo', {item->item['word']})
Can we also have this support
set completeopt+=matchfuzzy?
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Bram Moolenaar
Yegappan wrote:
> On Sat, Sep 12, 2020 at 1:09 PM Prabir Shrestha <vim-dev...@256bit.org>
> wrote:
>
> > +1 for adding fuzzy match.
> >
> > A bit late to this. But few questions.
> >
> > How do we use matchfuzzy for a list of dictionary instead of item. Primary
> > reason for this is LSP (language server protocol) makes heavy use of
> > user_data. Can you add an example for sorting a list whose type is dict [
> > { 'word': 'foo', user_data: 1}, { 'word': 'foobar', user_data: 2}, {
> > 'word': 'bar', user_data: 3} ]. Should we have a 3rd optional parameter
> > that takes a callback?
> >
> > let completeitems = [
> > \ { 'word': 'foo', user_data: 1},
> > \ { 'word': 'foobar', user_data: 2},
> > \ { 'word': 'bar', user_data: 3}
> > \ ]
> > let filtertedlist = matchfuzzy(completeitems, 'foo', {item->item['word']})
> >
> >
> That is a good idea. We can add a callback argument that will be called for
> each item if the list item is dictionary.
two (or more) entries, where the first entry is a string, which is used
to sort on? The second item can then be the user data.
> > Can we also have this support set completeopt+=matchfuzzy?
>
> Extending other existing Vim features to use fuzzy matching is a separate
> activity :-)
Sometimes I think the surest sign that intelligent life exists elsewhere
in the universe is that none of it has tried to contact us. (Calvin)
vim-dev ML
Prabir Shrestha
I was suspecting it could be slow due to callback and going to vimscript.
let items = [ {'word': 'foo'}, { 'word': 'foobar'} ] let searchtext = 'foo' let key = 'word' let items = matchfuzzy(items, searchtext, key)
Why about using key which can be any string. this does mean it can only support one level. If someone does want to support multiple level another option is to pass list instead let key = ['a', 'b'] but dont think it will be worth it based on perf.
Usually the user_data is number and it doesn't support object.
There are also other cases I would like matchfuzzy to extend in the future such as highlights. This would be useful when building plugins like ctrlp.
let items = matchfuzzy(items, searchtext, { 'key': 'word', 'highlight': 1 })
Fuzzy search does get expensive so another option is to also have support for async fuzzy search by threads.
call matchfuzzy(items, searchtext, { 'key': 'word', 'highlight': 1, 'on_results': {items->s:log(items)})
might be good to use 3rd params a option which if of type dict so can be extended in future?
—
You are receiving this because you commented.
Yegappan Lakshmanan
Hi,On Sat, Sep 12, 2020 at 1:09 PM Prabir Shrestha <vim-dev...@256bit.org> wrote:+1 for adding fuzzy match.
A bit late to this. But few questions.
How do we use matchfuzzy for a list of dictionary instead of item. Primary reason for this is LSP (language server protocol) makes heavy use of user_data. Can you add an example for sorting a list whose type is dict
[ { 'word': 'foo', user_data: 1}, { 'word': 'foobar', user_data: 2}, { 'word': 'bar', user_data: 3} ]. Should we have a 3rd optional parameter that takes a callback?let completeitems = [ \ { 'word': 'foo', user_data: 1}, \ { 'word': 'foobar', user_data: 2}, \ { 'word': 'bar', user_data: 3} \ ] let filtertedlist = matchfuzzy(completeitems, 'foo', {item->item['word']})That is a good idea. We can add a callback argument that will be called for each itemif the list item is dictionary.
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
K.Takata
You can try the attached diff which implements the above and see how this works with a very large list of dictionaries.
The attached file is here:
https://groups.google.com/d/msg/vim_dev/7VpUqzoQycY/2Q1zWMEnBAAJ
—
You are receiving this because you commented.
Yegappan Lakshmanan
On Sat, Sep 12, 2020 at 1:09 PM Prabir Shrestha <vim-dev...@256bit.org> wrote:+1 for adding fuzzy match.
A bit late to this. But few questions.
How do we use matchfuzzy for a list of dictionary instead of item. Primary reason for this is LSP (language server protocol) makes heavy use of user_data. Can you add an example for sorting a list whose type is dict
[ { 'word': 'foo', user_data: 1}, { 'word': 'foobar', user_data: 2}, { 'word': 'bar', user_data: 3} ]. Should we have a 3rd optional parameter that takes a callback?let completeitems = [ \ { 'word': 'foo', user_data: 1}, \ { 'word': 'foobar', user_data: 2}, \ { 'word': 'bar', user_data: 3} \ ] let filtertedlist = matchfuzzy(completeitems, 'foo', {item->item['word']})That is a good idea. We can add a callback argument that will be called for each itemif the list item is dictionary.You can try the attached diff which implements the above and see how this works with avery large list of dictionaries.
let l = ['abcdef']->repeat(1000000)
let start = reltime()
let m = l->matchfuzzy('bcd')
let secs = start->reltime()->reltimefloat()
echomsg "Elapsed Seconds = " .. secs->string()
endfunc
func MeasureDict()
let l = []
for i in range(1, 1000000)
call add(l, {'text' : 'abcdef', 'idx' : i})
endfor
let start = reltime()
let m = l->matchfuzzy('bcd', {v -> v.text})
let secs = start->reltime()->reltimefloat()
echomsg "Elapsed Seconds = " .. secs->string()
endfunc
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
what happens if you support dict but instead of callback also support string key. For simple we could use string key and for complex objects lambda could be used.
—
You are receiving this because you commented.
Yegappan Lakshmanan
what happens if you support dict but instead of callback also support string key. For simple we could use string key and for complex objects lambda could be used.
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
Was there perf improvements for dictionary when there was million items when using key as string instead of callback? curious if 5.5 seconds went down to 1 sec.
—
You are receiving this because you commented.
Yegappan Lakshmanan
Was there perf improvements for dictionary when there was million items when using key as string instead of callback? curious if 5.5 seconds went down to 1 sec.
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
Great perf improvements. Would love to see the PR with updated doc for this.
—
You are receiving this because you commented.
Prabir Shrestha
Should completeitem have sortText?
This is what lsp defines https://microsoft.github.io/language-server-protocol/specifications/specification-current/#textDocument_completion
/**
* A string that should be used when comparing this item
* with other items. When `falsy` the label is used.
*/
sortText?: string;
Yegappan Lakshmanan
Great perf improvements. Would love to see the PR with updated doc for this.
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Bram Moolenaar
memory and doesn't require hashing for the lookup.
Also, when using a dict the key will be the same and rather meaningless?
I can only imagine this being useful if you already have a list of
dicts. How often does that happen?
Using a list of lists, where the inner list has the text to fuzzy-match
on as the first item and the rest of the list can be anything, would be
the most efficient. Looking up the first item of a list is fast as
well. Only creating this list of lists might take extra time, if you
have an already existing structure.
[['abcd', oneData], ['bcde', twoDta]]->matchfuzzy('cd')
--
Kisses may last for as much as, but no more than, five minutes.
[real standing law in Iowa, United States of America]
vim-dev ML
Prabir Shrestha
Using dict for autocomplete is very popular specially due to lsp. For example you could have [ {word: 'server', user_data:1, kind: 'm', dup: 1}, { word: 'server', user_data: 2, kind: 'v', dup; 1}]. 1 is of type module where CompleteDone would auto import the module while 2 is of type variable which already exists in the scope and will not autoimport.
Another case where it is used is when label in popup and actual filtering is different. For example label for popup could look like start(port_number) but filterText should only include start so it doesnt search for port_number.
LSP provide sorttext and filtertext.
/**
* A string that should be used when comparing this item
* with other items. When `falsy` the label is used.
*/
sortText?: string;
/**
* A string that should be used when filtering a set of
* completion items. When `falsy` the label is used.
*/
filterText?: string;
autocomplete starts getting more complicated when you want to implement other items such as MRU and locality.
While list is performant not sure if many uses it instead of dict for autocomplete except for simple ones. This also means every autocomplete plugins would now have to change their sources to list of filter keys instead of using existing one that is list of dict. I would be curious on perf improvements here but doubt anyone is trying to search 1million autocomplete items. It might make more sense for fuzzy file search in case someone is searching from root.
Another option where I would like to use fuzzy search is for lsp document (current file) symbols and lsp workspace (current project) symbols. In this case symbols looks something like this.
{
'name': '',
'detail': ''
'kind: '',
'deprecated': false,
'location': {
'file': '',
'line: 0,
'col': 0,
},
}
Another random thought for the 3rd param. Might be we could only support callbacks which is a lambda/funcref or even plain string expression but optimize if plain string. This aligns with map, filter functions where we can already have :echo map([ {'name': 'a'}, {'name':'b'}], 'v:val["name"]'). If the 3rd param is string which looks like v:val["key"] we parse out key and then optimize it by using that as a key instead of executing function which is slow. We could do the same for v:val.key or v:val['key']. This way as a user of the function I assume it takes 3rd param as an expression and is not special cased.
I would still like to have dict support even though it might be bit slower since many already uses it and doesnt require me to convert data strucutres. Ok if someone wants to also extend and support [['abcd', oneData], ['bcde', twoDta]]->matchfuzzy('cd'). Having benchmarks for both would really help make this decision.
—
You are receiving this because you commented.
Yegappan Lakshmanan
> For a list, it took around a second to search all the entries and for a
> dict,
> it took around 5.5 seconds.
A list is always going to be more efficient than a dict. It uses less
memory and doesn't require hashing for the lookup.
Also, when using a dict the key will be the same and rather meaningless?
I can only imagine this being useful if you already have a list of
dicts. How often does that happen?
echo getbufinfo()->matchfuzzy('eval', 'name')
Generating a list of buffer names and then search (but the other
echo getbufinfo()->map({_, v -> v.name})->matchfuzzy('quickfix.c')
Generating a list of lists with two elements and then searching using
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Bram Moolenaar
too many entries, the conversion to a list of lists is cumbersome.
Only when you do have a lot of entries (e.g. all files in a directory
tree, with size and date as secondary info) and speed is crucial then
the list of lists may be desired.
The callback is the most flexible and most likely also the slowest.
I suspect it's actually not that complicated to support all of these.
Wen can make the third argument a dict, like we often do for functions
with various options.
--
What do you get when you cross a joke with a rehtorical question?
vim-dev ML
Prabir Shrestha
To make files faster there needs to be other tricks besides just making matchfuzzy faster.
Editors such as VsCode/SublimeText start indexing in the background in different thread. So when you start searching it most likely already has all the list of files and now only need to filter out. It also has filewatcher so can add/remove items without complete reindexing. This is something not possible currently with most of the terminal finders that are embedded in vim since every new instance of fuzzy search starts a new process which in turn starts reindexing.
What we really need is something like command-t vim plugin which does multi-threading search.
Making third argument dict would allows us in the future to have async = 1.
Another is daemon/server mode for external fuzzy search. I had briefly mentioned about this at mattn/gof#18
—
You are receiving this because you commented.
Yegappan Lakshmanan
> >
> > > >> On Sat, Sep 12, 2020 at 1:09 PM Prabir Shrestha <
> > > >> vim-dev...@256bit.org> wrote:
> > > >>
> > > >>> +1 for adding fuzzy match.
> > > >>>
> > > >>> A bit late to this. But few questions.
> > > >>>
> > > >>> How do we use matchfuzzy for a list of dictionary instead of item.
> > > >>>
>
We can make the third argument a dict, like we often do for functions
with various options.
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
Would it be possible to take a dict but instead of using key or callback name it map or something else but make the inner implementation smarter?
let result = matchfuzzy(items, 'search', { 'map': 'v:val["word"]' })
If map is string you can try extracting the key by using regex. Since this regex will happen only once cost wouldn't be that high.
From here https://regex101.com/
Regular Expression: ^v:val\[(\'|\")(.*)(\'|\")\]$
Test String:
v:val['key']
v:val["key"]
Notice how group two contains the key.
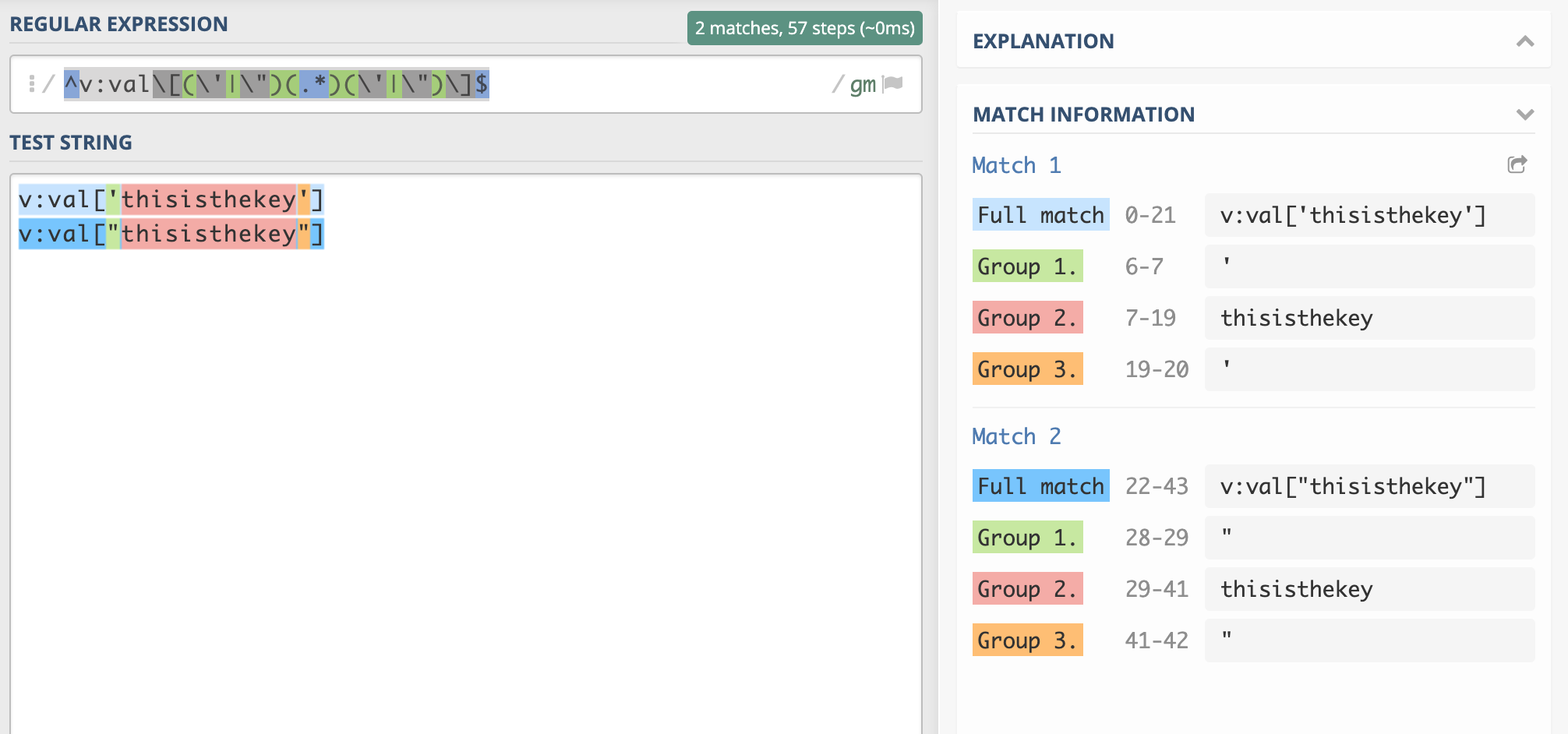
If map is of not of type script it can be a callback.
One could do this.
let result = matchfuzzy(items, 'search', { 'map': {item->item['word'] })
—
You are receiving this because you commented.
Yegappan Lakshmanan
Would it be possible to take a dict but instead of using
keyorcallbackname itmapor something else but make the inner implementation smarter?let result = matchfuzzy(items, 'search', { 'map': 'v:val["word"]' })If
mapis string you can try extracting the key by using regex. Since this regex will happen only once cost wouldn't be that high.
vim-dev ML
On Sun, Sep 13, 2020 at 2:44 PM Prabir Shrestha <vim-dev...@256bit.org>
wrote:
> Would it be possible to take a dict but instead of using key or callback
> name it map or something else but make the inner implementation smarter?
>
> let result = matchfuzzy(items, 'search', { 'map': 'v:val["word"]' })
>
> If map is string you can try extracting the key by using regex. Since
> this regex will happen only once cost wouldn't be that high.
>
It is better to explicitly supply the name of the key to the function.
Using a
regular expression to guess and automatically extract the key name will
lead to
errors.
- Yegappan
From here https://regex101.com/
>
> Regular Expression: ^v:val\[(\'|\")(.*)(\'|\")\]$
>
> Test String:
>
> v:val['key']
> v:val["key"]
>
> Notice how group two contains the key.
>
> [image: Screen Shot 2020-09-13 at 2 40 34 PM]
>
> If map is of not of type script it can be a callback.
>
> One could do this.
>
> let result = matchfuzzy(items, 'search', { 'map': {item->item['word'] })
>
>
>
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
Should it be called map_cb instead of callback to align with channels?
—
You are receiving this because you commented.
Yegappan Lakshmanan
Should it be called map_cb instead of callback to align with channels?
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
I’m good with key_cb.
—
You are receiving this because you commented.
Prabir Shrestha
Actually key_cb won’t make sense since it can be nested key or some computation with function. It is more of value_cb or can use something like filtertext_cb or text_cb to align with lsp.
Yegappan Lakshmanan
Actually key_cb won’t make sense since it can be nested key or some computation with function. It is more of value_cb or can use something like filtertext_cb or text_cb to align with lsp.
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
Looks great too me. Thanks for the changes. Looking forward to start using this method soon.
—
You are receiving this because you commented.
Sergey Vlasov
With the proposed API there is no way to know what portions of the input are matched.
Example: >
:echo matchfuzzy(['clay', 'crow'], "cay")
< results in ['clay']. >
It would be more useful to also return the start position and the end position of the match, similar to matchstrpos():
[
["clay",
["c", 0, 0],
["ay", 2, 3]
]
]
Jimmy Huang
Hi all:
I think this is a very nice function. Thank the author so much.
And I think it would be better:
- To have a callback instead of blocking vim.
- Add an option to let users to set the limitation to the count of results, which can impove performance largely by limitting the sort counts and reducing the time that parsing the C's results to viml's structure.
There are still a lot of thinks to be done to be a real "matchfuzzy".
Jimmy Huang
Hi all:
I think this is a very nice function. Thank the author so much.
And I think it would be better:
1.To do a callback to send results to the users after matching was done, instead of blocking vim. Just like :h timer_start
2.Add an option to let users to set the limitation to the count of results, which can impove performance largely by limitting the sort counts and reducing the time that parsing the C's results to viml's structure.
I can not wait to make some plugins with this new function.
But, there are still a lot of things to be done to be a real "matchfuzzy".
Sincerely.
Jimmy Huang
Bram Moolenaar
Sergey Vlasov wrote:
> With the proposed API there is no way to know what portions of the
> input are matched.
>
> ```
> Example: >
> :echo matchfuzzy(['clay', 'crow'], "cay")
> < results in ['clay']. >
> ```
>
> It would be more useful to also return the start position and the end
> position of the match, similar to `matchstrpos()`:
>
> ```
> [
> ["clay",
> ["c", 0, 0],
> ["ay", 2, 3]
> ]
> ]
That makes it a lot more complex. What is the practical use for the
match positions?
--
A special cleaning ordinance bans housewives from hiding dirt and dust under a
rug in a dwelling.
[real standing law in Pennsylvania, United States of America]
Yegappan Lakshmanan
With the proposed API there is no way to know what portions of the input are matched.
Example: > :echo matchfuzzy(['clay', 'crow'], "cay") < results in ['clay']. >It would be more useful to also return the start position and the end position of the match, similar to
matchstrpos():[ ["clay", ["c", 0, 0], ["ay", 2, 3] ] ]
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Maxim Kim
Internally, the fuzzy_match() function does have this information in an array (matches). But returning this for a large number of matched items will increase the run time of this function. As Bram asked, what is the use case for this?
To be able to show the user what was matched, like fzf, leaderf, vim-clap or ctrlp do:
https://i.imgur.com/FogkBBH.png
—
You are receiving this because you commented.
Sergey Vlasov
Internally, the fuzzy_match() function does have this information in an array (matches).
This information is very crucial to make highlighting of the matches. I don't see how it would be possible to compute the matches positions afterward, without essentially re-implementing fuzzy matcher in vimscript.
There could be an additional function matchfuzzypos() which lines up very nicely with matchstr() and matchstrpos().
But returning this for a large number of matched items will increase the run time of this function.
Vim docs sometimes have Warning: This function can be very slow.
Prabir Shrestha
Highlighting matches could be an explicit opt-in. Since 3rd param is now a dictionary this should be possible.
:echo matchfuzzy(['clay', 'crow'], "cay", { 'highlight': v:true })
[
["clay",
["c", 0, 0],
["ay", 2, 3]
]
]both have use cases. Having simple list for matchfuzzy is also useful.
Bram Moolenaar
> > Internally, the fuzzy_match() function does have this information in
> > items will increase the run time of this function. As Bram asked,
> > what is the use case for this?
>
> To be able to show the user what was matched, like fzf, leaderf, vim-clap or ctrlp do:
>
> https://i.imgur.com/FogkBBH.png
So this would be optional.
I know that in the past we have used the same function and changed the
return type, but with type checking that can be problematic. Thus it
would be better to use a different function name for this.
matchfuzzypos() ?
--
A law to reduce crime states: "It is mandatory for a motorist with criminal
intentions to stop at the city limits and telephone the chief of police as he
is entering the town.
[real standing law in Washington, United States of America]
/// Bram Moolenaar -- Br...@Moolenaar.net -- http://www.Moolenaar.net \\\
/// sponsor Vim, vote for features -- http://www.Vim.org/sponsor/ \\\
\\\ an exciting new programming language -- http://www.Zimbu.org ///
\\\ help me help AIDS victims -- http://ICCF-Holland.org ///

Dominique Pellé
> To be able to show the user what was matched, like fzf, leaderf, vim-clap or ctrlp do:
>
> https://i.imgur.com/FogkBBH.png
string is "pa li" (with a space) and the results
don't contain spaces. They contain slashes as
in "pack/minpac/opt/fzf/LICENSE".
It won't match with the current implementation of matchfuzzy:
:echo matchfuzzy(["pack/minpac/opt/fzf/LICENSE"], "pa li")
[]
However, this would match:
:echo matchfuzzy(["pack/minpac/opt/fzf/LICENSE"], "pa/li")
['pack/minpac/opt/fzf/LICENSE']
So should matchfuzzy() do something special for separators
characters?
Regards
Dominique
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Maxim Kim
In your screenshot example I see that the search string is "pa li" (with a space) and the results don't contain spaces. They contain slashes as in "pack/minpac/opt/fzf/LICENSE".
It is a different implementation of a fuzzy algorithm (fzf) so it can handle spaces and doesn't count them as a char to search for. It is not the case, was just an example to showcase.
Here it is with pali: https://i.imgur.com/vC8EwkA.png
—
You are receiving this because you commented.
Maxim Kim
However, this would match:
:echo matchfuzzy(["pack/minpac/opt/fzf/LICENSE"], "pa/li")
['pack/minpac/opt/fzf/LICENSE']
I would expect :echo matchfuzzy(["pack/minpac/opt/fzf/LICENSE"], "pali") match the same...
So should matchfuzzy() do something special for separators characters?
Probably yes, at least spaces should be treated in a special way, I think.
Yegappan Lakshmanan
> > Internally, the fuzzy_match() function does have this information in
> > an array (matches). But returning this for a large number of matched
> > items will increase the run time of this function. As Bram asked,
> > what is the use case for this?
>
> To be able to show the user what was matched, like fzf, leaderf, vim-clap or ctrlp do:
>
> https://i.imgur.com/FogkBBH.png
OK, that seems useful. But in many cases we just want the result.
So this would be optional.
I know that in the past we have used the same function and changed the
return type, but with type checking that can be problematic. Thus it
would be better to use a different function name for this.
matchfuzzypos() ?
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
matchfuzzypos sounds good to me. Thought I would prefer different type for results.
[
\ ['string1', 'string2'],
\ [ [[0, 2, 4]], [[1,3,5]] ]
\ ]
or
{
\ 'items': ['string1', 'string2'],
\ 'highlights': [ [[0, 2, 4]], [[1,3,5]] ]
\ }
This allows me to avoid loop in vimscript and use c instead. Also allows me to improve rendering perf by virtualizing highlights.
let [items, highlightpos] = matchfuzzypos(['foo', 'foobar', 'bar'], 'foo') call setline(1, items) " calc visible lines and only highlight what is visible in screen
—
You are receiving this because you commented.
Yegappan Lakshmanan
matchfuzzypossounds good to me. Thought I would prefer different type for results.[ \ ['string1', 'string2'], \ [ [[0, 2, 4]], [[1,3,5]] ] \ ]or
{ \ 'items': ['string1', 'string2'], \ 'highlights': [ [[0, 2, 4]], [[1,3,5]] ] \ }This allows me to avoid loop in vimscript and use c instead. Also allows me to improve rendering perf by virtualizing highlights.
vim-dev ML
>
>
>
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
You can avoid expensive loop by using the concept of virtualization.
few links:
https://bvaughn.github.io/react-virtualized/#/components/List
https://dev.to/nishanbajracharya/what-i-learned-from-building-my-own-virtualized-list-library-for-react-45ik
const data = [1, 2, 3, 4, 5];
<List
source={data}
rowHeight={40}
renderItem={({ index, style }) => (
<div key={index} style={style}>
Hello {index}
</div>
)}
/>
This is a react JavaScript example but almost all list whether it is native ios/android phones or desktop mac/linux/win apps do the same. This is how they are good at perf.
Imagine I need to build a fuzzy search plugin similar to CtrlP/Fzf. The height of the window/popup will most likely only most likely be fixed. Let us assume it is 10 lines. If I have 100 result I only need to highlight 10 items. Since I know exactly what is visible I can only highlight those. If I'm showing 40th-50th item, I can get highlights[40] till highlights[50] which means I need to only loop 10 iteration instead of 100 iteration.
I do want to use virtualization and highlights for quickpick.vim.
Here is an example what I meant by fixed height. I currently use setline(1, items) so would like to continue to use that in an easy fashion.

—
You are receiving this because you commented.

Maxim Kim
On 14.09.2020 17:38, Bram Moolenaar wrote:
> Sergey Vlasov wrote:
> ...
>> [
>> ["clay",
>> ["c", 0, 0],
>> ["ay", 2, 3]
>> ]
>> ]
>> ```
> That makes it a lot more complex. What is the practical use for the
> match positions?
like fzf, ctrlp, vim-clap or leaderf plugins do:
https://i.imgur.com/FogkBBH.png
Sergey Vlasov
Any comments about this output format for this new function from others?
vim-ml doesn't relay people's reaction but there are two thumbs up of approval at the moment of writing.
[
\ ['string1', 'string2'],
\ [ [[0, 2, 4]], [[1,3,5]] ]
\ ]
However having the matches and positions in separate arrays is very awkard, especially if the second array cannot be used without the first one, because it only contains the start positions.
[
["clay",
["c", 0, 0],
["ay", 2, 3]
]
]
At least in the initial proposal user can use start and end positions without looking at the matched tokens.
If I'm showing 40th-50th item, I can get highlights[40] till highlights[50] which means I need to only loop 10 iteration instead of 100 iteration.
Wouldn't list slicing results[40:49] work in this cas?
Prabir Shrestha
It is really not about results[39:49] but about the setline.
If you merge you need to do this which means it is doing for loop in vimscript and is slow.
let i = 1 for item in results[39:49] call setline(1, [item[0]]) let i += 1 endfor
vs
if you make it different array i can directly use setline which means for loop runs in c and is lot faster.
call setline(1, results[39:49])
Question really should be about how can I call setline without using for loop in vimscript.
I will most likely just use call setline(1, items) and only use result[39:49] for highlights only. There are two different issues. One is setting the buffer contents and another is highlighting. It is important to do both efficiently and the current proposed result doesn't allow that. Having two separate arrays is a bit akward but seems lot more efficient and faster. I would prefer pref to akwardness here.
Yegappan Lakshmanan
vim-dev ML
—
You are receiving this because you are subscribed to this thread.
Prabir Shrestha
I commented in PR. It is starting to look good. Currently my big concern is about multiple highlights for the same item.
Result should look like this. when using matchfuzzypos(['curl', 'world', 'curl world'], 'rl'). Need to create one more list for each item.
[
[ "curl", "world", "curl world"],
[
[ [2,3] ],
[ [2,3 ] ],
[ [2,3], [7,8] ]
]
]
—
You are receiving this because you commented.