Vault Horizontal Scalability, High Availability & Benchmark
847 views
Skip to first unread message

Yossi Cohen
Apr 30, 2017, 8:05:09 AM4/30/17
to Vault
Hi,
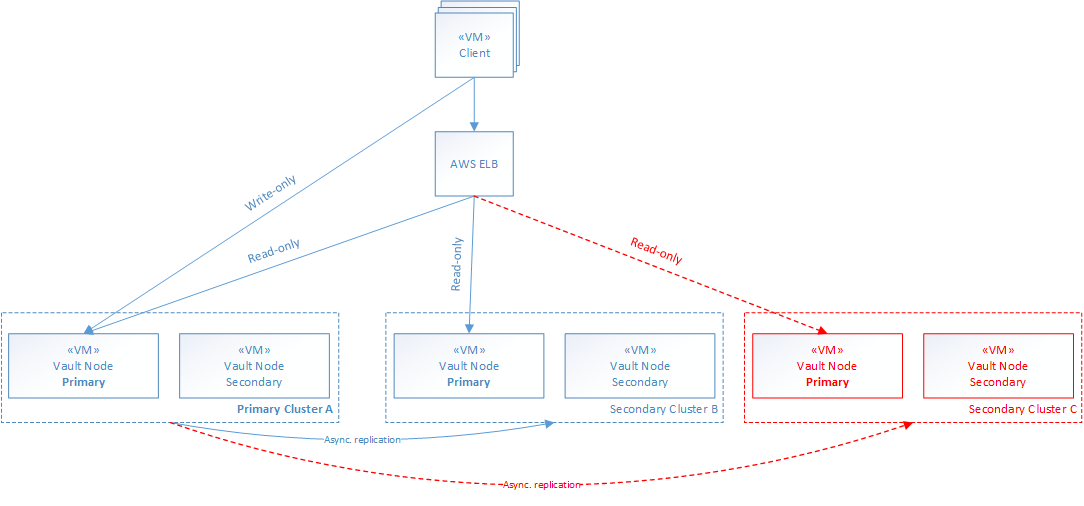
Please refer to the attached diagram first and then the related questions below.
- It appears that Vault may be able to scale out horizontally only when the enterprise feature 'replication' is in use. Is this correct? How to make it work?
- Can a new Cluster C be added dynamically to allow elastic scalability with AWS ELB for instance? Can Cluster C be added without bringing down (/restarting) Cluster A and Cluster B?
- What API of Vault-Transit backend are considered 'write' operation that cannot horizontally scale out?
- How clients shall dynamically discover the cluster address they need to failover to? How clients/ELB “knows” when to failover to another secondary vault cluster vs. to another secondary vault node within the same cluster? What algorithm the client/ELB needs to be aware of if at all? How the ELB becomes of aware of all the primary Vault nodes in all clusters? E.g., how does it cope with Vault failover scenarios?
- Does anyone have detailed benchmark for all the operations of Vault (and the Transit in particular)? What HW/SW configuration was used for the benchmark?
We are running technology evaluation process these days and HA, scalability and performance are heavily weighted in our tool selection criteria.
Thanks,
Yossi, Amdocs

Jeff Mitchell
May 1, 2017, 11:07:33 PM5/1/17
to Vault
Hi Yossi,
1. You are correct, we built replication specifically to enable horizontal scaling. (There will be at least one other replication mode in the future, designed for disaster recovery.)
2. Yes and yes -- you can add another replication cluster C on the fly without bringing down A and B. You can go through ELB and have it round-robin requests, but depending on your workload, you may see better performance by taking advantage of locality -- having a replication cluster close to each geographic location and accessing it directly.
3. For Transit specifically, anything that modifies a key is considered to be a write operation -- so creating a key, rotating it, or changing its configuration parameters. Everything else, including all encryption/decryption/signing/verification operations, can be handled on the secondaries. Note that you don't need to manually send write/read operations on different paths as in your diagram -- secondary clusters will transparently forward such write operations to the primary cluster!
4. That's all highly dependent on your setup -- whether you are using service discovery and how you have that hooked into ELB, health checks you have configured on the ELB, DNS, etc.
5. The Vault team does not generally perform benchmarks because it is so highly dependent on many factors -- not just workload against Vault, but which storage backend is used, the latency/connection to it, sizing of machines/instances, resources of machines/instances, provisioned IOPS (if applicable), tenancy, etc. In other words, as with most applications, benchmarks are not super useful in a general sense; what ends up being far more important is whether the speed you're getting is good enough for your use cases. (In one minor exception to the "we don't run benchmarks" rule, I did once run some benchmarks of Transit between two distinct machines in a highly, highly favorable test environment, and was able to push 37k operations per second. But to illustrate my earlier point, it's an environment that you would never encounter in real life, so it's likely only useful as an idealized upper bound.) That all said, our sales engineers work with customers on proof-of-concepts that I think include ensuring that performance meets needs. Since you're looking into replication you're looking into Vault Enterprise, so I do encourage getting in touch with them at https://www.hashicorp.com/products/vault/
Best,
Jeff
--
This mailing list is governed under the HashiCorp Community Guidelines - https://www.hashicorp.com/community-guidelines.html. Behavior in violation of those guidelines may result in your removal from this mailing list.
GitHub Issues: https://github.com/hashicorp/vault/issues
IRC: #vault-tool on Freenode
---
You received this message because you are subscribed to the Google Groups "Vault" group.
To unsubscribe from this group and stop receiving emails from it, send an email to vault-tool+unsubscribe@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/vault-tool/8ed727f8-0159-4629-a31c-94796e316559%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

{kind=link}
Stephan Stachurski
May 15, 2017, 11:06:43 AM5/15/17
to Vault
Hey sorry if this is obvious, but can anyone please confirm: reads on the transit backend currently do *not* scale out, correct?
Thanks
Thanks
To unsubscribe from this group and stop receiving emails from it, send an email to vault-tool+...@googlegroups.com.
Jeff Mitchell
May 26, 2017, 9:53:46 AM5/26/17
to Vault
Hi Stephen,
If you have replication then yes, they do scale out. If you don't, they don't, since you only have a single active node.
Best,
Jeff
To unsubscribe from this group and stop receiving emails from it, send an email to vault-tool+unsubscribe@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/vault-tool/2207e2da-bef3-4218-8d42-8b87ac6d75ee%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages