parsing rfc2184 - compliant utf-8 text
403 views
Skip to first unread message

Joachim Tuchel
Oct 29, 2020, 5:15:16 AM10/29/20
to VA Smalltalk
I am trying to read an attachment file name from a content-disposition header in a mail message received an fetched using IMAP.
The String in question looks easy. It contains every character in the form of %41 (=$A), so each character is encoded as a percent sign and a hex value.
Decoding seems easy:
char := inStream next.
(char = $%)
ifFalse: [outStream nextPut: char]
ifTrue: [|hex|
hex := inStream next: 2.
outStream nextPut: (Character codepoint: (Integer readFrom: hex base: 16))].
outStream nextPut: (Character codepoint: (Integer readFrom: hex base: 16))].
So far so good. Until special characters come to play....
One of the messages I received has the letter ü encoded as %75%CC%88. Expressed in hex this would be 0x75 0xcc 0x88. Everybody knows this is a German small u umlaut.
Almost everybody, at least.
The algo above converts this to:
And if I try to convertFromCodePage: 'utf-8', this perfectly fails by returning 'u?'.
(BTW: I know for sure it is utf-8, because that is what the header explicitly states)
So, it is time to freely admit I am still not getting all this web and utf-8 stuff.
I know I came along issues like several forms of 'ü' encoded if utf-8 and these could be solved in javascript on the Browser side by normalizing. But I don't think VAST supports any of these normalization functions (NFD, NFC, whatever).
So does anybody know what I can do to get these Strings converted to my local Codepage (iso-8859-1 or -15)? I don't need a complete solution for now, but accented characters form German, French and maybe Czech, Polish etc. should be possible.
Any hints?
Joachim
Joachim Tuchel
Oct 29, 2020, 5:20:38 AM10/29/20
to VA Smalltalk
I just saw that Google Groups showed me an embedded image form my inspector when I edited the message, but it is now missing.
So here is another attempt to show you what my naive algorhithm turns 0x75 0xcc 0x88 into:
'75' -> $u
'CC' -> $Ì
'88' -> $ˆ
'CC' -> $Ì
'88' -> $ˆ
So the question remains: what is the correct way to convert these three characters into an u umlaut in iso-8859-1 ? convertFromCodePage: 'utf-8' is not working on this combination...
Joachim Tuchel
Oct 29, 2020, 6:31:05 AM10/29/20
to VA Smalltalk
So in order to get a step further, I tried using the more or less equivalent (but also a little more deprecated) Content-Type-Header's name parameter in this mail message, which uses an RFC2047 encoding (A kind of variant of QuotedPrintable), in which my beloved ü looks like this: 'U=cc=88'.
The only difference is that here the Character signalling a non-ASCII character is an equal sign instead of percent.
So I have the very same problem here: this ü is a sequence of 0x75 0xcc 0x88, and I don't get anywhere with this other header as long as I don't know how to get this sequence converted to an ü in ISO-8859-1.
I guess this will all be solvable quite easily when VAST integrates ICU, at least when you know what functions to call, but what can I do until then?
Joachim Tuchel
Oct 29, 2020, 7:32:16 AM10/29/20
to VA Smalltalk
I am a step further... I was right about the normalizeation stuff. According to https://www.utf8-chartable.de/unicode-utf8-table.pl
0xcc and 0x88 are the NFD form of combining the previous character with a Diaeresis. Seems like all sequences starting with at least CC and CD combine a character with some "extra" like cedilla, circonflex and whatnot. So I would need to use some normalization function convert this to NFC first and the convertFromCodePage: 'utf-8'.
So what would be needed is either a nice algorithm to normalize at least my subset of characters or a binding to some library like ICU.
The VAST roadmap says there will be a Unicode Support Library in VAST 2021 (scheduled for Q4/2020). I guess this refers to LibICU. So there is probably not much point in investing much time in my own incomplete and buggy implementation if Instantiations ships this next release in a few weeks that'll include exactly what I need in a tested and solid library...?
Is there anything that can be said about this publicly at the moment or do I have to wait for VAST 2021 and be surprised ;-) ?
For now, I'll probably just skip all %cc and the following character and thus vonvert umlauts to their base characters (ü -> u) for such encodings...
Joachim

Hans-Martin Mosner
Nov 4, 2020, 5:36:19 AM11/4/20
to VA Smalltalk
First of all, you need to parse %-encoded hex data in UTF-8 differently. Consecutive %-encoded bytes may form a single code point, in this case %cc%88 -> \u00A8, which is the combining diacritical mark. Perhaps you already do this (when you convert from code page 'utf-8').
This then has to be combined with the previous base character 'u' (\u0075) to yield the final 'ü' character (\u00FC).
Btw, what I get when converting this sequence from UTF8 looks like this:
#[16r75 16rCC 16r88] asString convertFromCodePage: 'utf-8' 'u¨'
so except for combining the diacritical mark with the base it's almost right.
Waiting for Unicode Support is probably the most reasonable choice, as these things tend to get really icky if you try to code them yourself, especially if you're not fully fluent with all the conventions and rules of Unicode.
Cheers,
Hans-Martin
Joachim Tuchel
Nov 5, 2020, 7:13:35 AM11/5/20
to VA Smalltalk
Hans-Martin,
thanks fpr your comments. I am currently decoding the %-encoded charecters first and then I use convertFromCodePage: 'utf-8' on the resultung String. So far this seems to work well for German texts, even fpr umlauts that are not combined diarhesis ones. But your comment sparks an idea that I could try for at least 16rCC's which follow an a,e,o or u. and are follewd by an 16r88. I could implement such a special case handling for at least German umlauts (which form the majority in our user base) and ignore all others. That's probably the lowest hanging fruit I can get and still handle maybe 95% of relevant cases. Nothing to be proud of, more a tsttcpw without annoying most of our users too much.
I already baught myself a bunch of T-shits with 'I ? Unicode' printed on them a while ago, because this unicode stuff is a minefield. One of the few fields that make me envious of other prgramming languages that natively use utf-8.
Joachim

Seth Berman
Dec 6, 2020, 9:47:03 AM12/6/20
to VA Smalltalk
Hello Joachim,
I saw you had some questions about Unicode. In the next week or two I will share some more details regarding it.
VAST 2021 is a massive release (again) and I just decided yesterday that Unicode won't quite be ready without a significant delay to VAST 2021.
There are simply too many subtle design decisions that can end up breaking the product if they go badly (and end up costing the company a lot of money to fix which I'm not going to let happen;)
VAST 2021 is a massive release (again) and I just decided yesterday that Unicode won't quite be ready without a significant delay to VAST 2021.
There are simply too many subtle design decisions that can end up breaking the product if they go badly (and end up costing the company a lot of money to fix which I'm not going to let happen;)
On a positive note, the Unicode support library was very nearly going to make it...and we will follow up with an ECAP or specific-customer program shortly after the release so folks can start working with it and help us make it as useful as possible in a follow on release. This should be in Feb.
No, its not ICU. Our Unicode support in the VM is written almost exclusively in the rust programming language and it has given us an interesting edge and tools for a fast/modern string implementation.
Our UnicodeString, Grapheme and UnicodeScalar abstractions and APIs are highly inspired by the Swift programming language.
As I said, I'll follow up in the next week or two with a post that shows how things work.
- Seth
The VAST roadmap says there will be a Unicode Support Library in VAST 2021 (scheduled for Q4/2020). I guess this refers to LibICU. So there is probably not much point in investing much time in my own incomplete and buggy implementation if Instantiations ships this next release in a few weeks that'll include exactly what I need in a tested and solid library...?
Is there anything that can be said about this publicly at the moment or do I have to wait for VAST 2021 and be surprised ;-) ?
Joachim Tuchel
Dec 7, 2020, 3:59:55 AM12/7/20
to VA Smalltalk
HI Seth,
I am glad you're taking this Unicode thing very serious. It is a minefield that seems neverending ;-) Whenever I think I have finally solved all issues, some new esoteric case comes around the corner. So it is good you take your time to make things work. You think you've got UTF-8 conversion working, but then some file gets uploaded with Umlauts being encoded in some form that convertFromCodePage: (or better iconv() ) doesn't handle, because it requires normalization first.... You get a file with unknown encoding and you need to make sure it is displayed correctly, but it is almost impossible to tell what encoding it might be in, especially if there is no BOM ... and whatnot!
So even if I'd love to have THE solution in my hands rather sooner than later, I prefer a working solution over one that's only half baked today ;-)
I'm looking forward to your updates on this.
Joachim
Seth Berman
Dec 7, 2020, 8:43:41 AM12/7/20
to VA Smalltalk
Hi Joachim,
"...
but then some file gets uploaded with Umlauts being encoded in some form that convertFromCodePage: (or better iconv() ) doesn't handle, because it requires normalization first"
- In our UnicodeString, you don't typically have to think about normalization...unless you wish too. The apis for NFC, NFD, NFKC, NFKD are there if you want them.
A new UnicodeString is logically composed of extended grapheme clusters. Other ways to express that are "user-perceived character" or "those things your cursor hops over as you press the left and right key".
A new UnicodeString is logically composed of extended grapheme clusters. Other ways to express that are "user-perceived character" or "those things your cursor hops over as you press the left and right key".
=, <, hash and so on with our Grapheme will ensure a common normalized form under the hood before performing the operation.
"...You get a file with unknown encoding and you need to make sure it is displayed correctly, but it is almost impossible to tell what encoding it might be in, especially if there is no BOM ... and whatnot!"
I just want to make sure I understand. Is your expectation that a UnicodeString can be reified from data for which the encoding (i.e. UTF-8, UTF-16LE...) is not known?
Something like this? https://unicodebook.readthedocs.io/guess_encoding.html
I suppose you could attempt to first create from utf8, then utf16le, then utf16be and wait for one that works...but an encoding-guesser wasn't something that was going to be part of this.
Or when you say "encoding"...are you referring to normalization?
- Seth
Joachim Tuchel
Dec 18, 2020, 8:09:22 AM12/18/20
to VA Smalltalk
Hi Seth,
sorry for my late reply. I'm having crazy days, but who doesn't ?
Seth Berman schrieb am Montag, 7. Dezember 2020 um 14:43:41 UTC+1:
Hi Joachim,"... but then some file gets uploaded with Umlauts being encoded in some form that convertFromCodePage: (or better iconv() ) doesn't handle, because it requires normalization first"
- In our UnicodeString, you don't typically have to think about normalization...unless you wish too. The apis for NFC, NFD, NFKC, NFKD are there if you want them.
A new UnicodeString is logically composed of extended grapheme clusters. Other ways to express that are "user-perceived character" or "those things your cursor hops over as you press the left and right key".=, <, hash and so on with our Grapheme will ensure a common normalized form under the hood before performing the operation.
Well, I guess you are talking about a class that will be available in VAST 2021?
When all you have is iconv() or better #convertFromCodePage:, you have to deal with normalization. I only learned this year that an ü is not necessarily an ü. We could handle file uploads of files with names including German umlauts just fine. Until our first Mac user came along and uploaded a file where the ü was encoded as a sequence of the two dots and an u. iconv() doesn't work with these. In the end the words 'überweisung" and 'überweisung' were not the same any more... it took some while to understand.
This is not a VAST bug or anything, just a consequence of not having proper unicode support in your IDE. Soon this will be over. Unfortunately, not with 2021.
"...You get a file with unknown encoding and you need to make sure it is displayed correctly, but it is almost impossible to tell what encoding it might be in, especially if there is no BOM ... and whatnot!"I just want to make sure I understand. Is your expectation that a UnicodeString can be reified from data for which the encoding (i.e. UTF-8, UTF-16LE...) is not known?Something like this? https://unicodebook.readthedocs.io/guess_encoding.html
Exactly. This is why I asked for some LibICU functions in VASt some time ago which help with guessing whether a String can be assumed as UTF-8 or UTF-16 or ISO-8859.
This is quite important, because if you send #convertFromCodepage: 'UTF-8' to a String which has already been converted, you risk getting an error code 84 from iconv(). iconv does not check whether the conversion makes sense or not, it simply fails. Which is okay, you just have to deal with it.
So the best thing to do is to try and call convertFromCodePage: a few times inside an exception handler and see if one of the results looks similar to what you'd like to get. So I ended up with a method that tries to guess whether a String is in UTF-8 by converting it from utf-8 to the local codepage and back and if the end result looks like the first string, it seems to be utf-8. If I get an exception on the way, I guess it is already in the local codepage (ISO-8859-1 in my case). It would be good to add some BOM checks and such to this, so that you can already tell if the String is UTF-8 or -16 before calling iconv twice, but then there still are Strings that do not come with a BOM, so I didn't go that extra mile.
Again, I only mention this to explain why I am eagerly waiting for libicu or something equivalent, not to be offensive about VAST.
I suppose you could attempt to first create from utf8, then utf16le, then utf16be and wait for one that works...but an encoding-guesser wasn't something that was going to be part of this.
Well, I don't really care if guessing and conversion are combined in a single call. If I can just say: 'Make this ISO-8859-1, no matter what it is now', I am also happy. I'm not keen on doing this on my own all the time.
AFAIU, libicu cannot do that. So I'm afraid a guesser is something that will be needed pretty soon after the conversion is done.
Or when you say "encoding"...are you referring to normalization?
You know, I actually don't know. In my naive picture, if I want a String converted from UTF-8 to the local codepage, I don't really care how an ü is encoded in the UTF-8 String. I want my ü ;-) OTOH, if I send the String back to a web browser (e.g. in a web app) I have to send it in UTF-8, and it seems there is no way I can ignore that. If I receive an Ü in one normalization scheme from the browser and send it back in another one, I am asking for trouble as soon as there is, say, Javascript code running on the client/Browser that compares the String or such.
I know this is not something that can be solved easily. I'd have to keep track of what normalization scheme the ü was encoded with when I received it from the Browser and when I send it back use that info to re-apply that scheme before sending the String down.
With only iconv() I have no chance to even find out.
So I guess what is needed is a guesser for code page and normalization. Or - at least as likely - I am missing some important information.
The best possible option, however, would be a Smalltalk dialect that speaks UTF-8 natively. I create a String and don't care at all. I guess this is going to remain a dream for a while... ;-)
Joachim
Seth Berman
Dec 18, 2020, 10:21:58 AM12/18/20
to VA Smalltalk
Hello Joachim,
![]()
![]()
Thanks for your thoughts on this, much appreciated.
If I were to sum up your points, I would put them at "handling normalization for me" and "Guess the character encoding of an input string"
"Handling normalization for me"
I'll be honest with you, if having this abstracted away was the measure of "proper Unicode support", then most languages today would fail.
This is one of the reasons that I have chosen to have the basic unit of a UnicodeString at the grapheme level as opposed to answering Unicode scalars by default.
The other major reason is to properly deal with the plethora of API's which a UnicodeString is going to have to support as a result of being way down the
Collection hierarchy. Take something simple like 'reverse'. Try doing that with an NFD form of 'ü' and see what you get...you won't like it.
Most languages...even the so-called ones with "Unicode support" (which by the way is a near meaningless phrase) make you deal with normalization as just part of what you do.
For example, making sure that things are in NFC (or NFD) before you do these kinds of things is always on you to deal with.
I have studied most language's implementations of Unicode at this point and believe Swift and Perl 6 (now Raku) made the appropriate decisions with how they are representing this.
Its certainly far more complexity hoisted onto the implementer to do this, but anything lower level just leads us back to the same conversations regarding normalization.
With what has been developed, 'überweisung' at: 1 in your example answers the grapheme 'ü'. It may be in NFC or NFD...it doesn't really matter for operations like '=' and 'hash'
and '<'. However, we do maintain the original normalization under the hood because, for example, certain filesystems may require the name to be in some
normalized form or it won't find it.
The bottom line in this issue is that you will be dealing with graphemes (@ user-perceived characters) by default. You won't care about normalization until you have some sort of
scenario where ensuring a normalized form is important. And when you do, its easy. We have asNFC, asNFD, asNFKC, asNFKD. And you have the option to do it in-place or make a copy
or even just to test if your unicode string is in some normalized form.
If you want to work with something else, we have the analog of swift "views". For us, these are bi-directional streams that subclass Stream and work on UnicodeString, Grapheme, and UnicodeScalar
You can do the normal next, atEnd, do: inject:into: and I'll be adding string slicing equivalents.
Right now the views are graphemes, unicodeScalars, utf8, utf16, utf32.
You can do the normal next, atEnd, do: inject:into: and I'll be adding string slicing equivalents.
Right now the views are graphemes, unicodeScalars, utf8, utf16, utf32.
These views keep internal bookmarks to the bytes of the underlying implementation (which have nothing to do with how it is being presented to the user) so you get efficient O(n) streaming.
1 byte = 1 char = 1 user-perceived character is absolutely false, and trying to maintain that illusion is what got everybody into that codepage mess in the pre-unicode era.
And, it continues to get people into messes even during the unicode era because 1 Unicode codepoint = 1 character is also absolutely false....as you have found out.
"Guess the character encoding of an input string"
I think if you do some research on this you'll see that, in general, you can't do this in a way that is 100% guaranteed to work.
Anybody that attempts to do this has to provide a confidence level of sorts and you even may have to provide a sufficient amount of input for it to even work.
We implement our Unicode in rust, so if I find a rust 'crate' that exposes this capability, I'll certainly look at wrapping it and would be happy to do so.
You can separately look at wrapping libICUs capability for it: http://userguide.icu-project.org/conversion/detection
As said previously, I plan to do a post to show some examples of where we are at that should be interesting.
Here is a small example. I tend to use emojis because they are complex under the hood.
Part of this effort is to also ensure that workspaces and inspectors have scintilla editors in UTF-8 mode,
Part of this effort is to also ensure that workspaces and inspectors have scintilla editors in UTF-8 mode,
which is why its displaying the emoji and not gibberish.
I used this as my first test case to here https://hsivonen.fi/string-length/
I used this as my first test case to here https://hsivonen.fi/string-length/
The first screenshot is the emoji as UnicodeString and it matches up with the website.
The second screenshot is the first of five unicodeScalars that make up the emoji.
The second screenshot is the first of five unicodeScalars that make up the emoji.
- Seth
Seth Berman
Dec 18, 2020, 10:25:12 AM12/18/20
to VA Smalltalk
Not sure if the pictures showed from the last message, so I'll try attaching a screenshot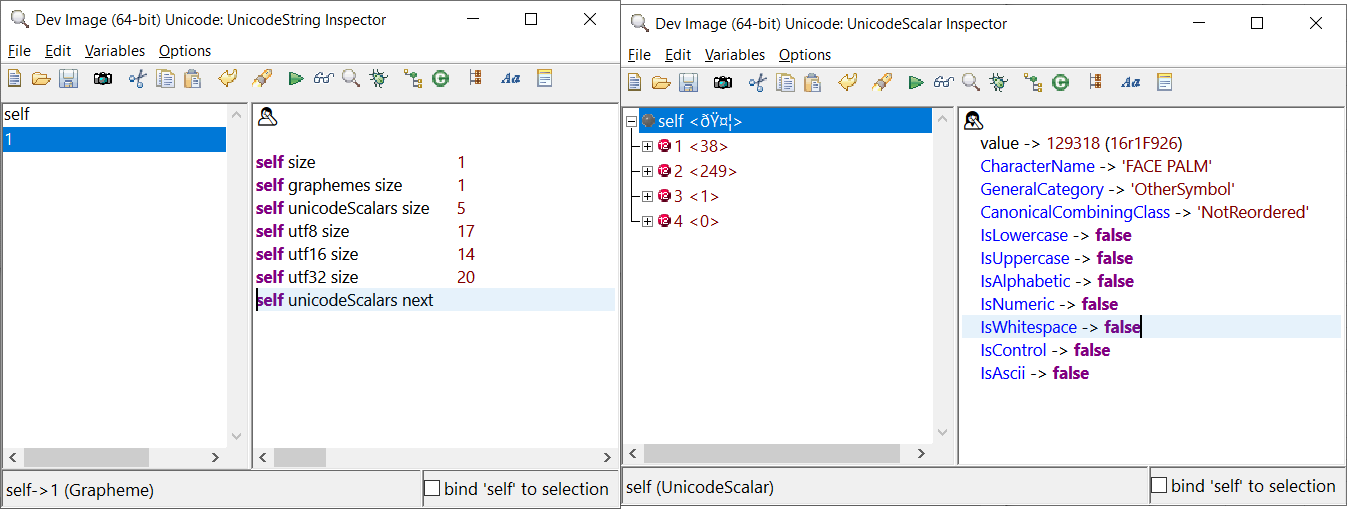

Adriaan van Os
Dec 18, 2020, 12:38:46 PM12/18/20
to VA Smalltalk
I like those images. Keep it coming. 😊
Seth Berman
Dec 18, 2020, 2:14:04 PM12/18/20
to VA Smalltalk
👍
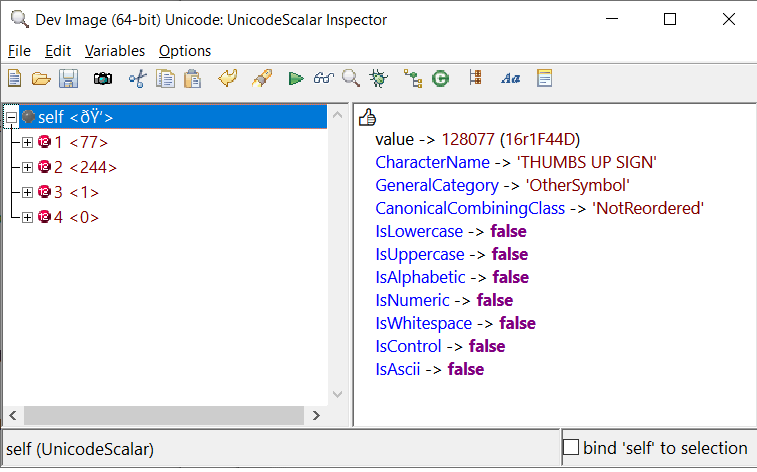
oh wait, I guess now it would be...
Also, the views are still "under construction"...so it will probably answer sizes in terms of code units.
For now utf8, utf16, utf32 views are answering size in terms of bytes which is why you see those numbers in the previous screenshot.
For now utf8, utf16, utf32 views are answering size in terms of bytes which is why you see those numbers in the previous screenshot.
- Seth
Reply all
Reply to author
Forward
0 new messages