pow(0, 0) == NaR
194 views
Skip to first unread message

no-r...@svr2.ghostemail.xyz
Nov 22, 2020, 1:42:48 PM11/22/20
to unum-co...@googlegroups.com
Neither the draft standard nor the software implementations have I found how exponentiation is calculated. I hope the answer is not 1.
You can reply to this message by sending an email to rwatsic...@klepf.com.
If you don't want to receive more messages, you can click here.
If you don't want to receive more messages, you can click here.


John Gustafson
Nov 22, 2020, 6:40:25 PM11/22/20
to rwatsic...@klepf.com, unum-co...@googlegroups.com
The answer is not 1. pow(0,0) should return NaR. From the Standard:
NaR is output when the mathematical result of a function is not a unique real number as a continuous function of the inputs within the function domain, except for functions in Section 5.2.1.
Footnote 7:
7See Section 5.1 for situations that generate NaR. For example, xy is not continuous at x = y = 0, so pow(0, 0) is NaR.
You may be looking at a slightly outdated version of the Standard, but those lines have been in the text since last May. I'm attaching Version 4.9. Right now, we are wrestling with the rules for operations that mix different posit precisions, or that mix posits and floats.
John
rwatsicaa rwatsicaa
Nov 23, 2020, 8:49:04 AM11/23/20
to rwatsic...@klepf.com, unum-co...@googlegroups.com
Dear John,
I read your attached file and some things in it confused me.
- The `fMM` function that evaluates the `posit1 * posit2 * posit3`. The three-argument function is difficult for ISA and hardware. And it will be unusual to see it used in source code. Is this function really necessary?
- According to this table from your file, the posit8, the posit16 and the posit32 has an es=2. I figured it out using a maxPos value and this posit lookup table. Why exactly an es=2 in the standard? Why doesn't the posit16 have an es=1?

In the future, where can I get an up-to-date draft of the posit standard?

John L. Gustafson
Nov 23, 2020, 8:54:01 PM11/23/20
to rwatsicaa rwatsicaa, rwatsic...@klepf.com, unum-co...@googlegroups.com
The last sentence of the Abstract of the Standard says:
A posit compliant system may be realized using software or hardware or any combination.
The functions in Section 5 will almost always be supported with a few in native hardware, but the others will be math library calls. I know CORDIC algorithms have been put into microprocessors (more like a microcode sequence, presented to the user as
a single instruction), but the Working Group certainly isn't suggesting that you have to have a hardware instruction, say, for the arc hyperbolic cosine to be posit compliant!
The fMM (fused multiply-multiply) instruction is envisioned as a library call, performed with integer instructions. A posit-posit multiply, like a float-float multiply, requires
2 decodings into exponent and significand (as integers) (performed concurrently)1 integer summation of exponents and 1 integer product of significands (performed concurrently)1 encoding back to exponent-significand format1 round-to-nearest, tie-to-even
With pipelined hardware, that can be done as quickly as 3 or 4 clock cycles. In SoftPosit, we see it taking about 20 clock cycles on a modern x86 processor. For 32-bit posits (up to 28-bit significands), a 32-by-32 integer multiplier is more than enough.
For fMM, the software would do 3 decodings, 2 summations of exponents, 2 or 3 integer multiplies (3 if the multiplier precision is not sufficient, so that a double-word product is needed), then 1 encoding and 1 rounding. Maybe 30 clock cycles.
The quire allows a program to stay in the "math layer" for billions of summation operations or summation-of-products operations, without rounding or overflow. That restores the associative and commutative property of addition, until of course the sum is
rounded to bring it back to the "compute layer". What the fMM(a,
b, c) operation does is provide a little bit of that same capability for multiplication, since it rounds the
exact value of a × b ×
c. It's especially helpful when either multiply sends the product into the range where posits have low accuracy, yet both products together have a result in the high-accuracy range.
It's not required for programmers to use fMM if their computer can do two rounded multiplies in hardware faster than a math library call to do it exactly in software, and they prefer speed to numerical safety. Speed is what people prefer,
in my experience. Also, compilers are forbidden (in the Posit Standard) from automatically generating fused operations unless explicitly requested in the source code, so you won't get the fMM operation unless you ask for it. Though there is discussion right
now in the Working Group about this.
I should probably post the latest version of the Standard (4.9, the one I attached to a recent email) on
posithub.org, but I have been holding off until we can resolve what seems to be the only remaining issue, which is how to specify when posit rounding happens in a computer language. For example, if a programmer writes
quire q;posit p1, p2;
q += p1 * p2;
should the product p1 * p2 be performed exactly and then added to q with no rounding, or do the productions of the language not include the recognition of that combination of precision and operator and thus p1 * p2 would be rounded to a posit, then that
posit added to the quire. I had really hoped to resolve this, get the Working Group to ratify it, and
then put it up on posithub.org, but it looks like it may be a while longer since we've all got our day jobs!
Yes, the original posits4.pdf paper and the "Beating Floating Point at its Own Game" paper made the guess that the
es value should be 0, 1, 2, 3, for precisions nbits = 8, 16, 32, 64. Since then, well over 100 papers have been written about posit arithmetic, in a wide range of applications and with various strategies for supporting them in
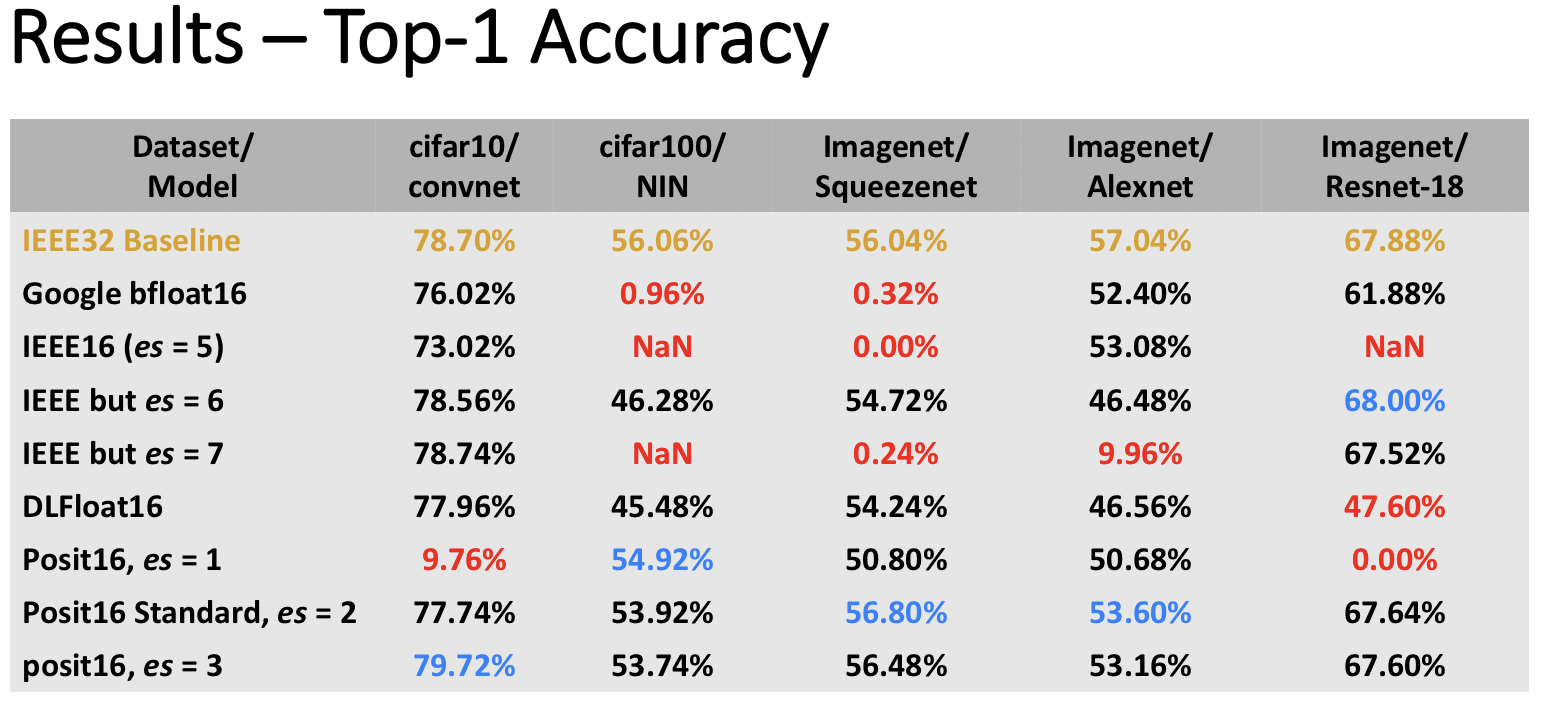
hardware. We learned a lot, and everything seemed to point to making the exponent size always 2, or perhaps always 3. Check out this controlled study of 16-bit float and posit variants for Deep Learning that was recently done by Dr. Himeshi De Silva here
at NUS:
For inference with 8-bit posits, again es = 2 or possibly 3 works best; certainly not
es = 0 because the dynamic range just can't cut it. And reducing the 64-bit posit exponent size to 2 means the quire need only be 1024 bits instead of the even more onerous 2048 (though still far better than the 4664 bits needed for IEEE 754
doubles to accumulate dot products exactly).
So, since last May, the Working Group agreed that it's not too late to make the change and we rewrote everything to assume 2 exponent bits. Which means "es" disappears from the Standard. Notice that the quire is always 16 times as many bits as the posit,
instead of growing as the square of the posit size. That's a huge simplification when you want to reallocate memory after changing precision.
But the best part of all is that changing posit precision is now trivial because it requires
no decoding. To increase precision, pad with zeros on the right. To decrease precision, round the binary, no need to take it apart into sign-regime-exponent-fraction. This makes practical a programming style where many different posit precisions
can be mixed in a program with almost no performance penalty, any more than the performance penalty for converting a 16-bit integer to a 32-bit integer by padding with digits on the left. Zero time cost to raise precision, a single clock cycle cost for rounding
to a lower precision.
John
On Nov 23, 2020, at 9:49 PM, rwatsicaa rwatsicaa <rwat...@ya.ru> wrote:
- External Email -
Dear John,I read your attached file and some things in it confused me.
- The `fMM` function that evaluates the `posit1 * posit2 * posit3`. The three-argument function is difficult for ISA and hardware. And it will be unusual to see it used in source code. Is this function really necessary?
- According to this table from your file, the posit8, the posit16 and the posit32 has an es=2. I figured it out using a maxPos value and this posit lookup table. Why exactly an es=2 in the standard? Why doesn't the posit16 have an es=1?<123.png>
In the future, where can I get an up-to-date draft of the posit standard?
--
You received this message because you are subscribed to the Google Groups "Unum Computing" group.
To unsubscribe from this group and stop receiving emails from it, send an email to unum-computin...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/unum-computing/2084131606138847%40mail.yandex.ru.
Important: This email is confidential and may be privileged. If you are not the intended recipient, please delete it and notify us immediately; you should not copy or use it for any purpose, nor disclose its contents to any other person. Thank you.
no-r...@svr2.ghostemail.xyz
Nov 24, 2020, 3:06:56 PM11/24/20
to unum-co...@googlegroups.com
Dear John,
I read your attached file and some things there confused me.
- The `fMM` function that calculates the `posit1 * posit2 * posit3`. This three-argument function format will be difficult for ISA and hardware. And it will be unusual to see it used in source code. Is this function really necessary?
- According to this table, the posit8, the posit16 and the posit32 have es=2. Why is this so? And why is the es of posit16 not equal to 1?

In the future, where can I get an up-to-date draft of the posit standard?
You can reply to this message by sending an email to shills...@klepf.com.
If you don't want to receive more messages, you can click here.


Tomek Czajka
Jan 9, 2022, 4:47:01 PM1/9/22
to Unum Computing
This will end up being a super annoying edge case for users, especially since there is no pown with an integral exponent.
See https://sortingsearching.com/2020/11/11/zero-power-zero.html for reasons why the 1 value is useful.
See https://sortingsearching.com/2020/11/11/zero-power-zero.html for reasons why the 1 value is useful.
Reply all
Reply to author
Forward
0 new messages