Skip to first unread message

Alexis Neme
Oct 21, 2019, 10:27:06 PM10/21/19
to unitex-...@googlegroups.com
Hi,
- The button "Export all text as POS List" is a Java program and it is very slow
Anybody has a an external fast program in C/Python/ ... with almost the same functionality?
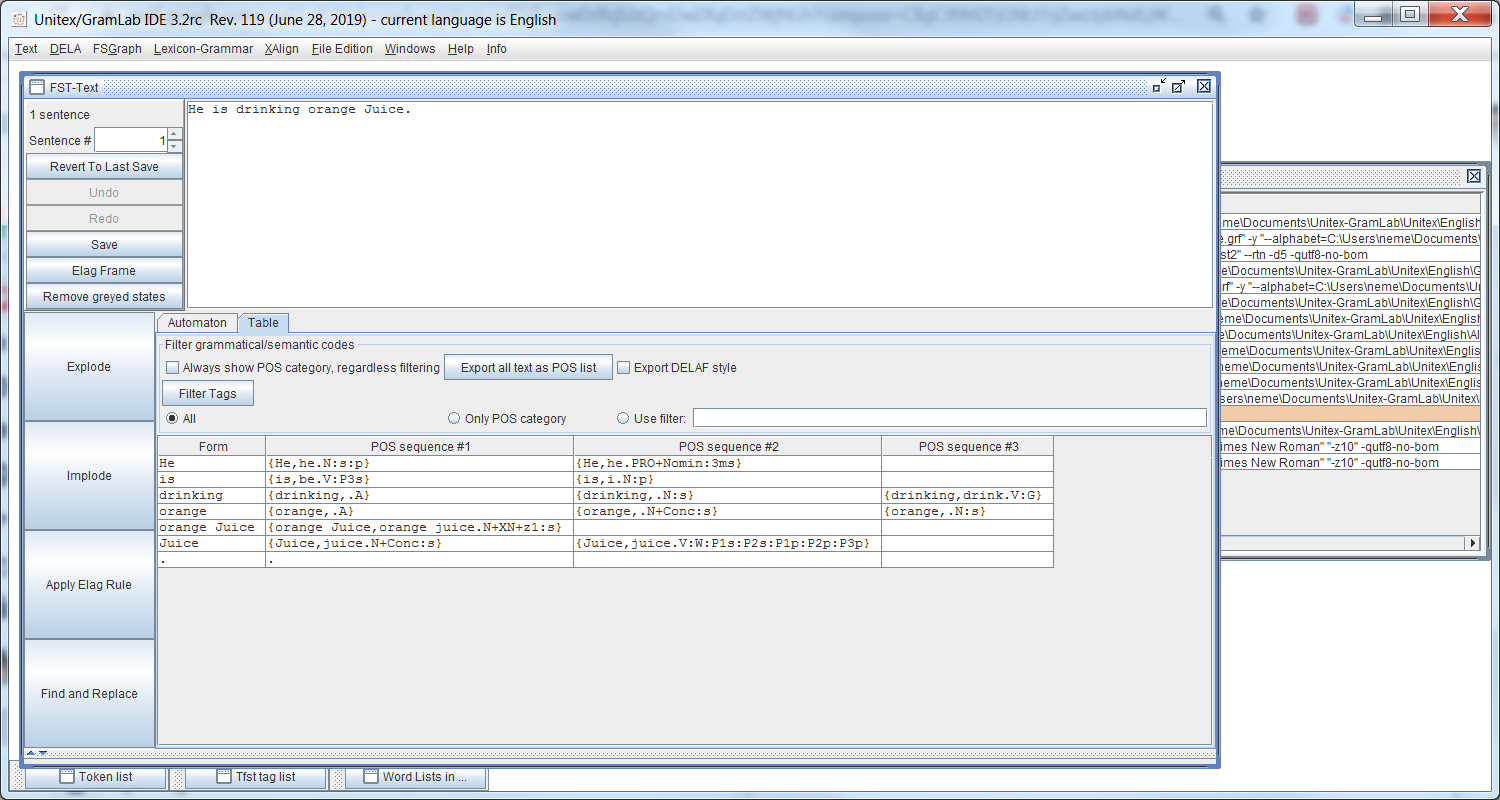
- Script with 5000 x 3 lines
I need to associate to each token: form,lemma.POS:features to each token in a document; so i can extract any of these fields.
for this I need to apply tokenize/Dico/Tfst2Grf to 5000 files or documents. I can make a script with 5000 x 3 lines ... not practical ?!
Is there another ideas than a script for such task ? (maybe such pipeline exists in Gramlab?)
Thanks,
Alexis

eric.laporte
Oct 23, 2019, 3:41:07 AM10/23/19
to Unitex-GramLab
Hi Alexis,
On Tuesday, 22 October 2019 04:27:06 UTC+2, Alexis Neme wrote:
<<
- Script with 5000 x 3 linesI need to associate to each token: form,lemma.POS:features to each token in a document; so i can extract any of these fields.for this I need to apply tokenize/Dico/Tfst2Grf to 5000 files or documents. I can make a script with 5000 x 3 lines ... not practical ?!Is there another ideas than a script for such task ? (maybe such pipeline exists in Gramlab?)
>>
why 5000 times if you have a single document?
Eric
Alexis Neme
Oct 24, 2019, 6:33:36 AM10/24/19
to Unitex-GramLab
Hi Eric,
I have 5000 documents to index by a search engine (for example)
I propose to index the 5000 documents by the lemmata of each document (and some forms ) extracted from a generated text.tfst file
- of course, a solution could be concatenation of the 5000 documents and make tokenize/dico/Tfst2Grf on a huge document and generate a huge text.tfst file.
However we should record the boundaries of each documents while concatenating
and identify similar boundaries in the huge text.tfst file related to each document and extract the lemmata for indexing related to each document.
Any other suggestions?
Thanks Eric
Reply all
Reply to author
Forward
0 new messages