I challenge you to get this 7.7 recognized!
55 views
Skip to first unread message

Daniel Gesua
Nov 16, 2021, 1:13:38 PM11/16/21
to tesseract-ocr
Hi guys,
This seems like a very simple thing, but clearly I'm wrong. Take a look at this image of a the text "7.7":
In this font tesseract completely fails to categorize the sevens. I tried whitelists, patterns, disabling the different dawgs, different segmentation modes, and scaling up and down.
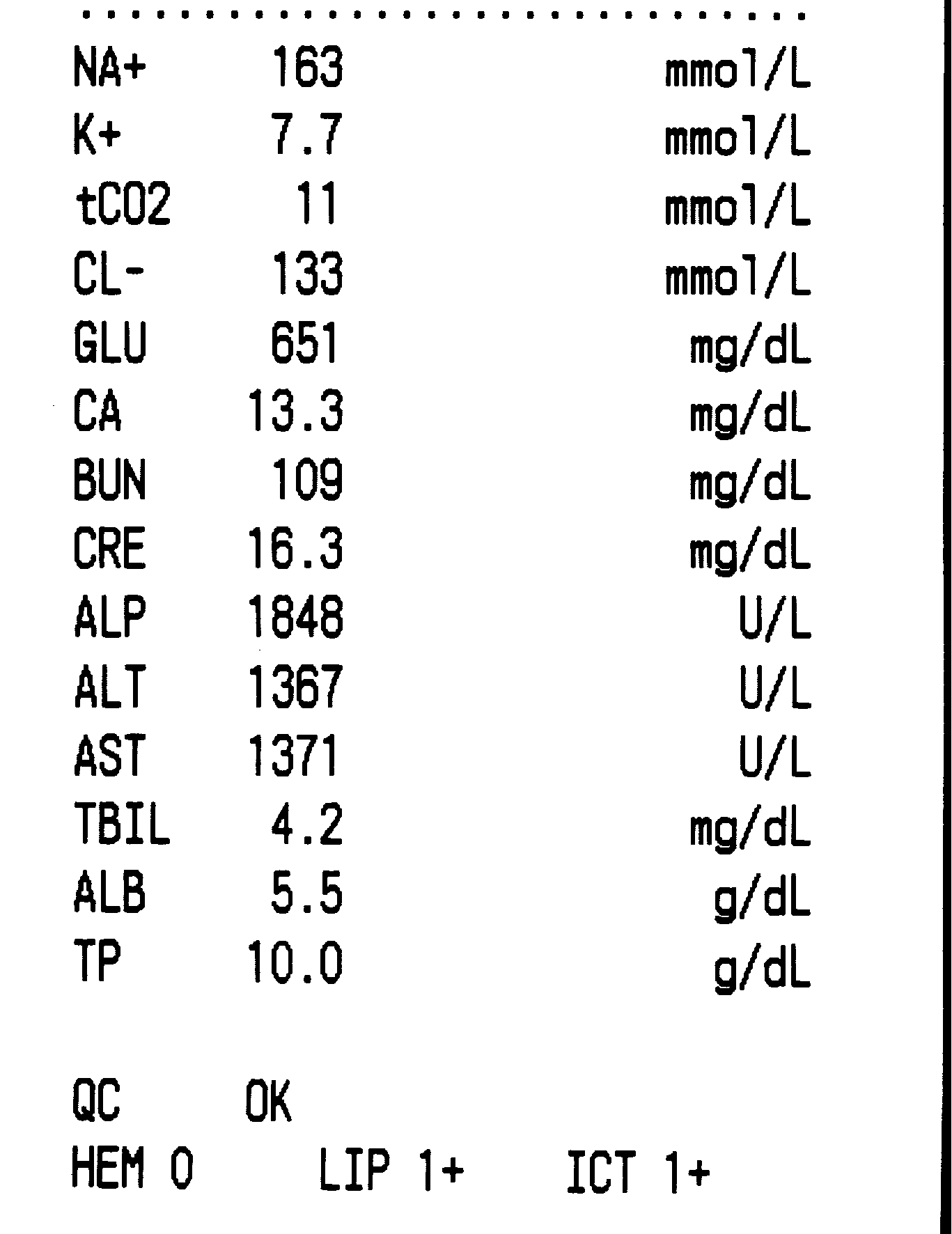
I've attached the different test images I've been using.
If I could figure out how to retrain the model I would try that as well, but there's so much conflictory information in the internet and I have spent days trying to figure it out.
Good luck!
Here's the version data for the build I'm running:
tesseract v5.0.0-rc1.20211030
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found FMA
Found SSE4.1
Found libarchive 3.5.0 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5 libzstd/1.4.5
Found libcurl/7.77.0-DEV Schannel zlib/1.2.11 zstd/1.4.5 libidn2/2.0.4 nghttp2/1.31.0
{kind=link}
{kind=link}
{kind=link}
Reply all
Reply to author
Forward
0 new messages