The pictures captured by the camera did not identify well after preprocessing
99 views
Skip to first unread message

vis li
Sep 16, 2021, 1:59:32 AM9/16/21
to tesseract-ocr
Tesseract Version:4.1.1
Platform:Window10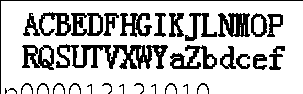
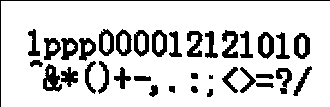
Page.getText():
ACBEDFHGIKJLNHOP
RQSUTV¥WYaZbdcef
1ppp000012121010
&*(O+-,.:; O=%/
like this,the result has some faults.
I know that my image has some defects,but how can i improve this situation?
I have done the binarization of the picture,and try to improve dpi to 300
Because the pictures captured by the camera,I am worried if they can meet the standard for web pictures
I have used LTSM mode ,and my Identified word library file is trained by LTSM and Microsoft Yahei Standard font

Zdenko Podobny
Sep 16, 2021, 2:03:28 AM9/16/21
to tesser...@googlegroups.com
It seems that you do not use tesseract directly (
Page.getText()) so it would be good to describe what and how you do it...
It could be useful to post original images - maybe there is a better way for preprocessing...
Zdenko
št 16. 9. 2021 o 7:59 vis li <liwe...@gmail.com> napísal(a):
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/96ce0479-bc22-477d-9d5b-a6408509121fn%40googlegroups.com.
vis li
Sep 16, 2021, 3:26:41 AM9/16/21
to tesseract-ocr
Thanks for your answer first;
I use tesseract in C#, a client program for a windows.this program use camera to get picture from OLED Led Screen and send to
preprocess and then Call the the tesseract's api of c# version (which encapsulates the tesseract of c++ version) to recognized . So the original image seems that is more diffcult to preprocess.I have tried some ways like Gaussian Blur.
Maybe the preprocessing method I use is not good enough , i can't get a satisfactory result.
the orginal pictures:
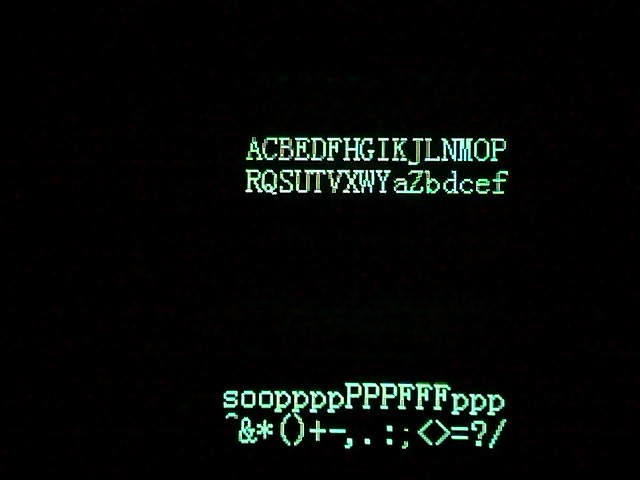
vis li
Sep 16, 2021, 3:55:12 AM9/16/21
to tesseract-ocr
I use this programmer to use camera to moniter and get what happened on these two oled led screens.
In calling tesseract api module, i use tesseract like this:
##
##
var engine = new TesseractEngine(@"./tessdata", "zth", EngineMode.LstmOnly);
var page = engine.Process(img, PageSegMode.SingleBlock);
string result = page.GetText();
##
the "zth" is the library file i trained by LSTM and EngineMode is similar to CLI's "--oem 1"
"PageSegMode.SingleBlock" is CLI's "--PSM 8"
the "zth" is the library file i trained by LSTM and EngineMode is similar to CLI's "--oem 1"
"PageSegMode.SingleBlock" is CLI's "--PSM 8"
在2021年9月16日星期四 UTC+8 下午2:03:28<zdenop> 写道:

Lorenzo Bolzani
Sep 16, 2021, 4:04:36 AM9/16/21
to tesser...@googlegroups.com
Hi Vli,
I think you should test this on something similar to your actual text, not on the alphabet or random strings. With real text you are not going to see () or <> that may be mistaken for a O.
The sequence of characters may influence the output, in other words try it on real text. You can also blacklist the characters you do not need.
To be honest, the result does not seem bad to me. Special characters are the most difficult ones.
Also this font is not easy to read, look at the M letter for example. If you can, change the font or try to capture the image at higher resolution before cleaning it.
What language is zth? This looks like latin text, did you try eng?
Lorenzo
vis li
Sep 16, 2021, 4:31:07 AM9/16/21
to tesseract-ocr
Thanks for your answer,
The text of the picture is a test case ,the reason why i use this test case is that the
actual text is produced by stm32 microcontroller .
it produce text like "E2PROM ADDR6".Text itself may be some abnormal text language ...
'zth' is the library i have trained with Microsoft Yahei Standard font . I have used eng library
it produce text like "E2PROM ADDR6".Text itself may be some abnormal text language ...
'zth' is the library i have trained with Microsoft Yahei Standard font . I have used eng library
which is Official word library file downloaded from the corresponding version of tesseract .
It was not as accurate as I trained myself
Zdenko Podobny
Sep 16, 2021, 10:57:55 AM9/16/21
to tesser...@googlegroups.com
Few hints:
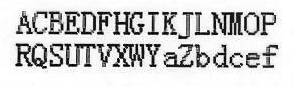

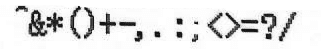
- Use another format than jpg if you want OCR image
- Try to take images with better resolution (e.g. so there is clear space between letters)
- Use greyscale colors.
- Use white (light) background
- For nontextual (not real words e.g. code) information legacy engine works better (LSTM tends to "see words")
- Try to pass tesseract homogeneous block (lines, paragraphs)
In my opinion, you need to expect that OCR results will not be 100% in cases like this. Maybe training would help (for the legacy engine), but I would focus first on about mentions hints.
> tesseract camera_part1.png - --psm 6 --oem 0
ACBEDFHGIKJLNTHOP
RQSUTVXWYaZbdcef
RQSUTVXWYaZbdcef
> tesseract camera_part2a.png - --psm 8 --oem 0
sonppppPPPFFFppp
> tesseract camera_part2b.png - --psm 8 --oem 0
"&*()+—,.:;<>=?/
Zdenko
št 16. 9. 2021 o 10:31 vis li <liwe...@gmail.com> napísal(a):
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/765451c2-7440-4a5c-acf5-41ce4e42daa8n%40googlegroups.com.
vis li
Sep 17, 2021, 2:27:52 AM9/17/21
to tesseract-ocr
Thanks for your suggestions.
I will try some of these suggestions to improve my program and hardware.
The results after image processing look much clearer than I have provided.
This is clearly beneficial for the image to identify the correct results.
Because the picture quality I can provide is not very high, it does not require 100% accuracy;
however hope the identification results are close to the achieved level and stable.
Thank you very much for it seems very late to back and to take some time to verify.
Liwei
Reply all
Reply to author
Forward
0 new messages