Trained data for E13B font
1,073 views
Skip to first unread message

ElGato ElMago
May 29, 2019, 5:48:15 AM5/29/19
to tesseract-ocr
Hi,
I wish to make a trained data for E13B font.
I read the training tutorial and made a base_checkpoint file according to the method in Training From Scratch. Now, how can I make a trained data from the base_checkpoint file?

Shree Devi Kumar
May 29, 2019, 6:14:08 AM5/29/19
to tesser...@googlegroups.com
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/4848cfa5-ae2b-4be3-a771-686aa0fec702%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
____________________________________________________________
भजन - कीर्तन - आरती @ http://bhajans.ramparivar.com
ElGato ElMago
May 29, 2019, 8:35:05 PM5/29/19
to tesseract-ocr
Thanks, Shree.
Yes, I saw the instruction. The steps I made are as follows:
Using tesstrain.sh:src/training/tesstrain.sh --fonts_dir /usr/share/fonts --lang eng --linedata_only \--noextract_font_properties --langdata_dir ../langdata \--tessdata_dir ./tessdata \--fontlist "E13Bnsd" --output_dir ~/tesstutorial/e13beval \--training_text ../langdata/eng/eng.training_e13b_textTraining from scratch:mkdir -p ~/tesstutorial/e13boutputsrc/training/lstmtraining --debug_interval 100 \--traineddata ~/tesstutorial/e13beval/eng/eng.traineddata \--net_spec '[1,36,0,1 Ct3,3,16 Mp3,3 Lfys48 Lfx96 Lrx96 Lfx256 O1c111]' \--model_output ~/tesstutorial/e13boutput/base --learning_rate 20e-4 \--train_listfile ~/tesstutorial/e13beval/eng.training_files.txt \--eval_listfile ~/tesstutorial/e13beval/eng.training_files.txt \--max_iterations 5000 &>~/tesstutorial/e13boutput/basetrain.logTest with base_checkpoint:src/training/lstmeval --model ~/tesstutorial/e13boutput/base_checkpoint \--traineddata ~/tesstutorial/e13beval/eng/eng.traineddata \--eval_listfile ~/tesstutorial/e13beval/eng.training_files.txtCombining output files:src/training/lstmtraining --stop_training \--continue_from ~/tesstutorial/e13boutput/base_checkpoint \--traineddata ~/tesstutorial/e13beval/eng/eng.traineddata \--model_output ~/tesstutorial/e13boutput/eng.traineddatatesseract e13b.png out --tessdata-dir /home/koichi/tesstutorial/e13boutputTest with eng.traineddata:
The training from scratch ended as:
At iteration 561/2500/2500, Mean rms=0.159%, delta=0%, char train=0%, word train=0%, skip ratio=0%, New best char error = 0 wrote best model:/home/koichi/tesstutorial/e13boutput/base0_561.checkpoint wrote checkpoint.
The test with base_checkpoint returns nothing as:
At iteration 0, stage 0, Eval Char error rate=0, Word error rate=0
The test with eng.traineddata and e13b.png returns out.txt. Both files are attached.
Training seems to have worked fine. I don't know how to translate the test result from base_checkpoint. The generated eng.traineddata obviously doesn't work well. I suspect the choice of --traineddata in combining output files is bad but I have no clue.
Regards,
ElMagoElGato
BTW, I referred to your tess4training in the process. It helped a lot.
2019年5月29日水曜日 19時14分08秒 UTC+9 shree:
On Wed, May 29, 2019 at 3:18 PM ElGato ElMago <elmago...@gmail.com> wrote:
--Hi,I wish to make a trained data for E13B font.I read the training tutorial and made a base_checkpoint file according to the method in Training From Scratch. Now, how can I make a trained data from the base_checkpoint file?
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesser...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/4848cfa5-ae2b-4be3-a771-686aa0fec702%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Shree Devi Kumar
May 29, 2019, 9:43:08 PM5/29/19
to tesser...@googlegroups.com
For training from scratch a large training text and hundreds of thousands of iterations are recommended.
If you are just fine tuning for a font try to follow instructions for training for impact, with your font.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/7f29f47e-c6f5-4743-832d-94e7d28ab4e8%40googlegroups.com.
ElGato ElMago
May 30, 2019, 12:08:34 AM5/30/19
to tesseract-ocr
I had about 14 lines as attached. How many lines would you recommend?
Fine tuning gives much better result but it tends to pick other character than in E13B that only has 14 characters, 0 through 9 and 4 symbols. I thought training from scratch would eliminate such confusion.
2019年5月30日木曜日 10時43分08秒 UTC+9 shree:
2019年5月30日木曜日 10時43分08秒 UTC+9 shree:
Shree Devi Kumar
May 30, 2019, 1:39:52 AM5/30/19
to tesser...@googlegroups.com
Look at the files engrestrict*.* and also https://github.com/Shreeshrii/tessdata_shreetest/blob/master/eng.digits.training_text
Create training text of about 100 lines and finetune for 400 lines
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/2c6fe865-911d-41f3-9926-cbfb56db794f%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
ElGato ElMago
May 30, 2019, 2:56:02 AM5/30/19
to tesseract-ocr
Thanks a lot, Shree. I'll look it in.
2019年5月30日木曜日 14時39分52秒 UTC+9 shree:
2019年5月30日木曜日 14時39分52秒 UTC+9 shree:
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/2c6fe865-911d-41f3-9926-cbfb56db794f%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
ElGato ElMago
Jun 6, 2019, 3:39:48 AM6/6/19
to tesseract-ocr
So I did several tests from scratch. In the last attempt, I made a training text with 4,000 lines in the following format,
2019年5月30日木曜日 15時56分02秒 UTC+9 ElGato ElMago:
110004310510< <02 :4002=0181:801= 0008752 <00039 ;0000001000;
and combined it with eng.digits.training_text in which symbols are converted to E13B symbols. This makes about 12,000 lines of training text. It's amazing that this thing generates a good reader out of nowhere. But then it is not very good. For example:
<01 :1901=1386:021= 1111001<10001< ;0000090134;
is a result on the image attached. It's close but the last '<' in the result text doesn't exist on the image. It's a small failure but it causes a greater trouble in parsing.
What would you suggest from here to increase accuracy?
- Increase the number of lines in the training text
- Mix up more variations in the training text
- Increase the number of iterations
- Investigate wrong reads one by one
- Or else?
Also, I referred to engrestrict*.* and could generate similar result with the fine-tuning-from-full method. It seems a bit faster to get to the same level but it also stops at a 'good' level. I can go with either way if it takes me to the bright future.
Regards,
ElMagoElGato
2019年5月30日木曜日 15時56分02秒 UTC+9 ElGato ElMago:
Shree Devi Kumar
Jun 7, 2019, 12:52:10 PM6/7/19
to tesser...@googlegroups.com
Please also search for existing MICR traineddata files.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/5b151e61-5b41-4191-8d26-784809ef8e10%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
ElGato ElMago
Jun 10, 2019, 1:51:44 AM6/10/19
to tesseract-ocr
That'll be nice if there's traineddata out there but I didn't find any. I see free fonts and commercial OCR software but not traineddata. Tessdata repository obviously doesn't have one, either.
2019年6月8日土曜日 1時52分10秒 UTC+9 shree:
2019年6月8日土曜日 1時52分10秒 UTC+9 shree:
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/5b151e61-5b41-4191-8d26-784809ef8e10%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Shree Devi Kumar
Jun 12, 2019, 12:26:06 PM6/12/19
to tesser...@googlegroups.com
You will get output of A B C D for the MICR symbols. If it works well otherwise, I will update it to generate the Unicode text for the symbols.
Trained using font "MICR Encoding"
Shree Devi Kumar
Jun 13, 2019, 12:48:40 PM6/13/19
to tesser...@googlegroups.com
see
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/09d3119c-d093-4269-bf3a-3ddb467ed0ed%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
ElGato ElMago
Jun 14, 2019, 3:56:55 AM6/14/19
to tesseract-ocr
Thanks a lot, shree. It seems you know everything.
2019年6月14日金曜日 1時48分40秒 UTC+9 shree:
I tried the MICR0.traineddata and the first two mcr.traineddata. The last one was blocked by the browser. Each of the traineddata had mixed results. All of them are getting symbols fairly good but getting spaces randomly and reading some numbers wrong.
MICR0 seems the best among them. Did you suggest that you'd be able to update it? It gets tripple D very often where there's only one, and so on.
Also, I tried to fine tune from MICR0 but I found that I need to change the language-specific.sh. It specifies some parameters for each language. Do you have any guidance for it?
2019年6月14日金曜日 1時48分40秒 UTC+9 shree:
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/09d3119c-d093-4269-bf3a-3ddb467ed0ed%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Shree Devi Kumar
Jun 14, 2019, 6:58:49 AM6/14/19
to tesser...@googlegroups.com
I have uploaded my files there.
is the bash script that runs the training.
You can modify as needed. Please note this is for legacy/base tesseract --oem 0.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/856a44a7-5127-45cd-9c7d-b9684eba8089%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Phuc
Jun 17, 2019, 12:40:10 AM6/17/19
to tesseract-ocr
Sorry if I interrupted your conversation.
I have a similar problem which is the .traineddata I exported from checkpoint file did not recognize any character at all although my training showed very good results.
As I understand from you guys' conversation. Is this because Training From Scratch? All I need to do is fine-tuning a model to get better result?
Also, I am quite confused why result using checkpoint file is so different from .traineddata and I would be appreciated if some one can the explain the reason why.
To have more information about my case, you can refer my post here: https://groups.google.com/forum/?utm_medium=email&utm_source=footer#!topic/tesseract-ocr/74xMXlYX6T0
Thank you and have a nice day
Thank you and have a nice day
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/856a44a7-5127-45cd-9c7d-b9684eba8089%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
ElGato ElMago
Jun 17, 2019, 9:04:43 PM6/17/19
to tesseract-ocr
I guess the cotent of training text is important when you add new characters. I had the same issue at first and then shree suggested a larger text and more iterations. I thought variation in the text would matter as well. I'm getting good results after I prepared good training text.
Now, both training from scratch and fine tuning are giving decent results. I'm working on E13B font that existing eng.traineddata never reads. It proves the training really works. My issue is to bring the accuracy to higher level. I'm yet to try the last suggestion from shree but I know that it'll be a long way to go for extreme accuracy.
2019年6月17日月曜日 13時40分10秒 UTC+9 Phuc:
2019年6月17日月曜日 13時40分10秒 UTC+9 Phuc:
ElGato ElMago
Jul 17, 2019, 4:01:29 AM7/17/19
to tesseract-ocr
Hi,
I'll go back to more of training later. Before doing so, I'd like to investigate results a little bit. The hocr and lstmbox options give some details of positions of characters. The results show positions that perfectly correspond to letters in the image. But the text output contains a character that obviously does not exist.
Then I found a config file 'lstmdebug' that generates far more information. I hope it explains what happened with each character. I'm yet to read the debug output but I'd appreciate it if someone could tell me how to read it because it's really complex.
Regards,
ElMagoElGato
2019年6月14日金曜日 19時58分49秒 UTC+9 shree:
2019年6月14日金曜日 19時58分49秒 UTC+9 shree:
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/856a44a7-5127-45cd-9c7d-b9684eba8089%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Claudiu
Jul 17, 2019, 5:26:57 AM7/17/19
to tesser...@googlegroups.com
I’m getting the “phantom character” issue as well using the OCRB that Shree trained on MRZ lines. For example for a 0 it will sometimes add both a 0 and an O to the output , thus outputting 45 characters total instead of 44. I haven’t looked at the bounding box output yet but I suspect a phantom thin character is added somewhere that I can discard .. or maybe two chars will have the same bounding box. If anyone else has fixed this issue further up (eg so the output doesn’t contain the phantom characters in the first place) id be interested.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/97a1fc89-06eb-45f6-865d-fee2c132789d%40googlegroups.com.

Lorenzo Bolzani
Jul 17, 2019, 5:58:31 AM7/17/19
to tesser...@googlegroups.com
Phantom characters here for me too:
Are you using 4.1? Bounding boxes were fixed in 4.1 maybe this was also improved.
I wrote some code that uses symbols iterator to discard symbols that are clearly duplicated: too small, overlapping, etc. But it was not easy to make it work decently and it is not 100% reliable with false negatives and positives. I cannot share the code and it is quite ugly anyway.
Here there is another MRZ model with training data:
Lorenzo
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAGJ7VxFmnQ2_3B825CdsrLYi5%2BWCD8OxEVLC29LwnXGkTx_q6Q%40mail.gmail.com.
ElGato ElMago
Jul 19, 2019, 1:25:34 AM7/19/19
to tesseract-ocr
Hi,
Let's call them phantom characters then.
Was psm 7 the solution for the issue 1778? None of the psm option didn't solve my problem though I see different output.
I use tesseract 5.0-alpha mostly but 4.1 showed the same results anyway. How did you get bounding box for each character? Alto and lstmbox only show bbox for a group of characters.
ElMagoElGato
2019年7月17日水曜日 18時58分31秒 UTC+9 Lorenzo Blz:
2019年7月17日水曜日 18時58分31秒 UTC+9 Lorenzo Blz:
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/97a1fc89-06eb-45f6-865d-fee2c132789d%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesser...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
Shree Devi Kumar
Jul 19, 2019, 1:44:51 AM7/19/19
to tesser...@googlegroups.com
Please check out the recent commits in master branch
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/71f7d6bd-b8a7-4057-b1bf-ab02db544579%40googlegroups.com.
Shree Devi Kumar
Jul 19, 2019, 1:46:01 AM7/19/19
to tesser...@googlegroups.com
Lorenzo Bolzani
Jul 19, 2019, 4:02:53 AM7/19/19
to tesser...@googlegroups.com
PSM 7 was a partial solution for my specific case, it improved the situation but did not solve it. Also I could not use it in some other cases.
The proper solution is very likely doing more training with more data, some data augmentation might probably help if data is scarce.
Also doing less training might help is the training is not done correctly.
There are also similar issues on github:
...
The LSTM engine works like this: it scans the image and for each "pixel column" does this:
M M M M N M M M [BLANK] F F F F
(here i report only the highest probability characters)
In the example above an M is partially seen as an N, this is normal, and another step of the algorithm (beam search I think) tries to aggregate back the correct characters.
I think cases like this:
M M M N N N M M
are what gives the phantom characters. More training should reduce the source of the problem or a painful analysis of the bounding boxes might fix some cases.
I used the attached script for the boxes.
Lorenzo
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/71f7d6bd-b8a7-4057-b1bf-ab02db544579%40googlegroups.com.
ElGato ElMago
Jul 19, 2019, 5:05:54 AM7/19/19
to tesseract-ocr
Lorenzo,
We both have got the same case. It seems a solution to this problem would save a lot of people.
Shree,
I pulled the current head of master branch but it doesn't seem to contain the merges you pointed that have been merged 3 to 4 days ago. How can I get them?
ElMagoElGato
2019年7月19日金曜日 17時02分53秒 UTC+9 Lorenzo Blz:
2019年7月19日金曜日 17時02分53秒 UTC+9 Lorenzo Blz:
Claudiu
Jul 19, 2019, 5:20:55 AM7/19/19
to tesser...@googlegroups.com
Is there any way to pass bounding boxes to use to the LSTM? We have an algorithm that cleanly gets bounding boxes of MRZ characters. However the results using psm 10 are worse than passing the whole line in. Yet when we pass the whole line in we get these phantom characters.
Should PSM 10 mode work? It often returns “no character” where there clearly is one. I can supply a test case if it is expected to work well.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/dbd26585-8969-4677-9bd8-a788fbc82436%40googlegroups.com.
Shree Devi Kumar
Jul 19, 2019, 5:29:20 AM7/19/19
to tesser...@googlegroups.com
>Is there any way to pass bounding boxes to use to the LSTM?
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAGJ7VxHkuWyjWdum43qfFZc7x9M-jRJ4CGLK8VJpWmmVbr0%2B9w%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
Shree Devi Kumar
Jul 19, 2019, 5:31:14 AM7/19/19
to tesser...@googlegroups.com
>I pulled the current head of master branch but it doesn't seem to contain the merges you pointed that have been merged 3 to 4 days ago. How can I get them?
I usually do `git pull origin master` to get all latest changes from the master branch.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/dbd26585-8969-4677-9bd8-a788fbc82436%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
ElGato ElMago
Jul 19, 2019, 5:40:49 AM7/19/19
to tesseract-ocr
Lorenzo,
I haven't been checking psm too much. Will turn to those options after I see how it goes with bounding boxes.
Shree,
I see the merges in the git log and also see that new option lstm_choice_amount works now. I guess my executable is latest though I still see the phantom character. Hocr makes huge and complex output. I'll take some to read it.
2019年7月19日金曜日 18時20分55秒 UTC+9 Claudiu:
2019年7月19日金曜日 18時20分55秒 UTC+9 Claudiu:
Claudiu
Jul 19, 2019, 6:00:10 AM7/19/19
to tesser...@googlegroups.com
Thanks for that link. Should passing a full image and calling SetRectangle have different behavior than passing just the cropped image and not using SetRectangle?
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduUpPFJ_-%3DTXyOn%2Boebu_Zcg_O4gNLft8SFta-7W%3DwkUSg%40mail.gmail.com.
ElGato ElMago
Jul 22, 2019, 8:53:18 PM7/22/19
to tesseract-ocr
Hi,
I read the output of hocr with lstm_choice_mode = 4 as to the pull request 2554. It shows the candidates for each character but doesn't show bounding box of each character. I only shows the box for a whole word.
I see bounding boxes of each character in comments of the pull request 2576. How can I do that? Do I have to look in the source code and manipulate such an output on my own?
2019年7月19日金曜日 18時40分49秒 UTC+9 ElGato ElMago:
2019年7月19日金曜日 18時40分49秒 UTC+9 ElGato ElMago:
2019年6月14日金曜日 1時48分40秒 UTC+9 shree:
To view this discussion on the web visit <a href="https://groups.google.com/d/msgid/tesseract-ocr/09d3119c-d093-4269-bf3a-3ddb467ed0ed%40googlegroups.com?utm_medium=email&utm_source=footer" rel="nofollow" target="_blank" onmousedown="this.href=
Shree Devi Kumar
Jul 22, 2019, 9:56:58 PM7/22/19
to tesser...@googlegroups.com
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/c02fd92c-21fe-48a0-a281-a2c01f5332ca%40googlegroups.com.
ElGato ElMago
Jul 23, 2019, 4:10:36 AM7/23/19
to tesseract-ocr
It's great! Perfect! Thanks a lot!
2019年7月23日火曜日 10時56分58秒 UTC+9 shree:
2019年7月23日火曜日 10時56分58秒 UTC+9 shree:
To unsubscribe from this group and stop receiving emails from it, send an email to tesser...@googlegroups.com.
ElGato ElMago
Jul 24, 2019, 1:10:46 AM7/24/19
to tesseract-ocr
Hi,
I got this result from hocr. This is where one of the phantom characters comes from.
<span class='ocrx_cinfo' title='x_bboxes 1259 902 1262 933; x_conf 98.864532'><</span>
<span class='ocrx_cinfo' title='x_bboxes 1259 904 1281 933; x_conf 99.018097'>;</span>
The firs character is the phantom. It starts with the second character that exists on x axis. The first character only has 3 points width. I attach ScrollView screen shots that visualize this.
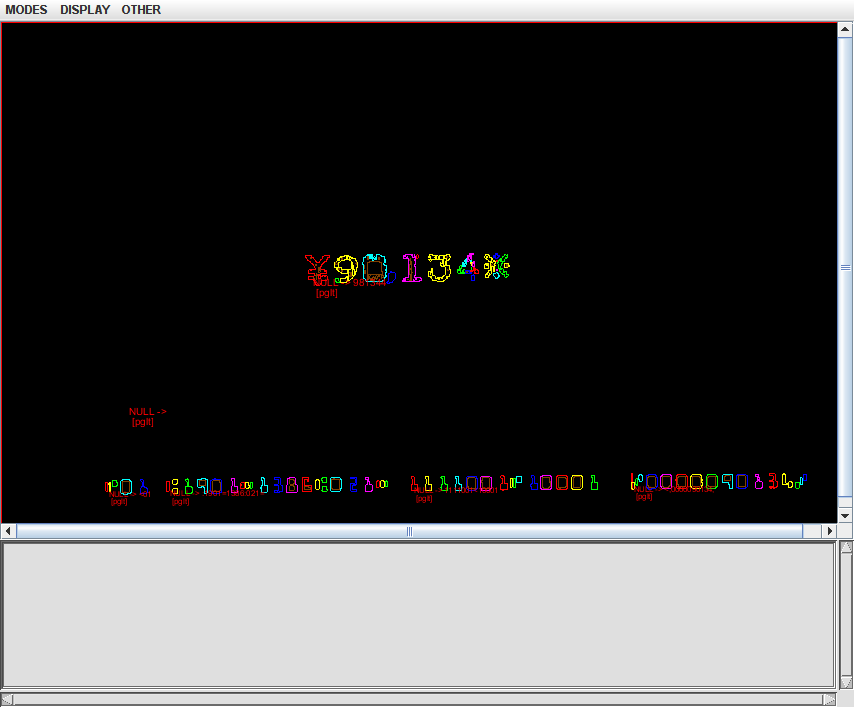
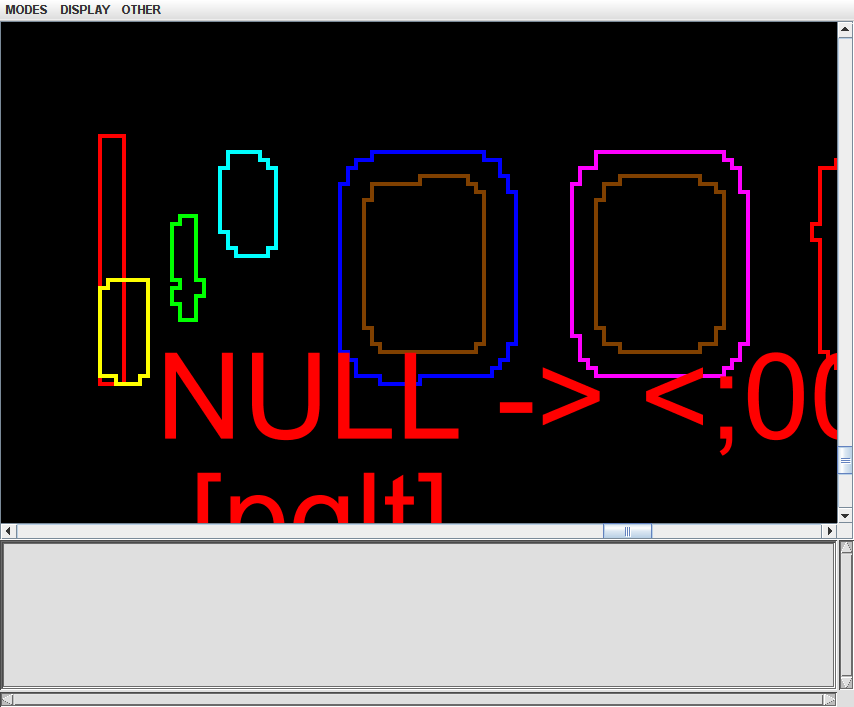
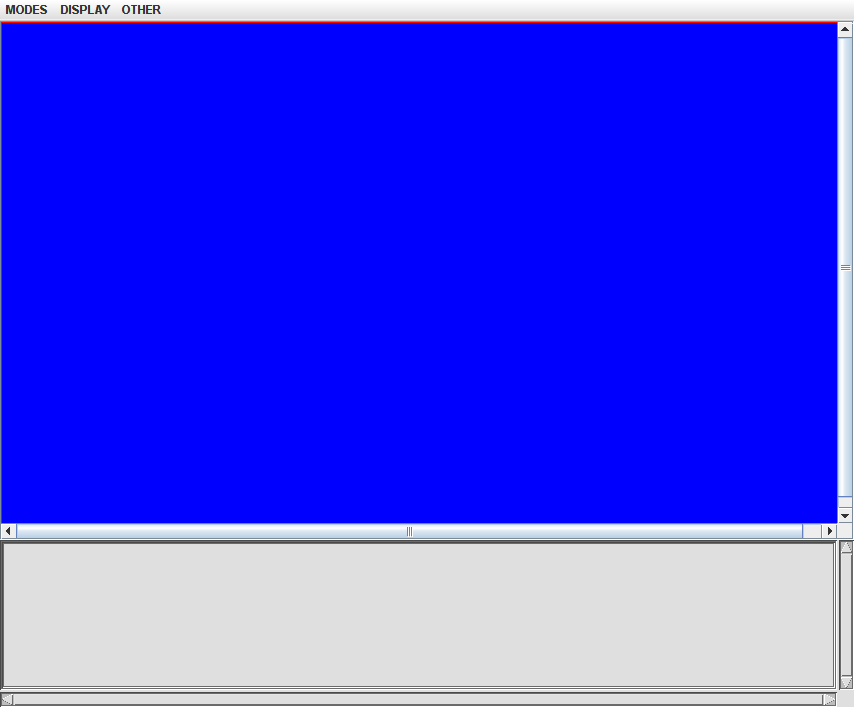
There seem to be some more cases to cause phantom characters. I'll look them in. But I have a trivial question now. I made ScrollView show these displays by accidentally clicking Display->Blamer menu. There is Bounding Boxes menu below but it ends up showing a blue screen though it briefly shows boxes on the way. Can I use this menu at all? It'll be very useful.
2019年7月23日火曜日 17時10分36秒 UTC+9 ElGato ElMago:
ElGato ElMago
Jul 26, 2019, 1:08:06 AM7/26/19
to tesseract-ocr
HI,
Well, I read the description of ScrollView (https://github.com/tesseract-ocr/tesseract/wiki/ViewerDebugging) and it says:
To show the characters, deselect DISPLAY/Bounding Boxes, select DISPLAY/Polygonal Approx and then select OTHER/Uniform display.
It basically works. But for some reason, it doesn't work on my e13b image and ends up with a blue screen. Anyway, it shows each box separately when a character is consist of multiple boxes. I'd like to show the box for the whole character. ScrollView doesn't do it, at least, yet. I'll do it on my own.
ElMagoElGato
2019年7月24日水曜日 14時10分46秒 UTC+9 ElGato ElMago:
2019年7月24日水曜日 14時10分46秒 UTC+9 ElGato ElMago:
2019年6月14日金曜日 1時48分40秒 UTC+9 shree:
To view this discussion on the web visit <a href="https://groups.google.com/d/msgid/tesseract-ocr/2c6fe865-911d-41f3-9926-cbfb56db794f%40googleg
ElGato ElMago
Aug 6, 2019, 4:11:40 AM8/6/19
to tesseract-ocr
Hi,
FWIW, I got to the point where I can feel happy with the accuracy. As the images of the previous post show, the symbols, especially on-us symbol and amount symbol, were causing mix-up each other or to another character. I added much more more symbols to the training text and formed words that start with a symbol. One example is as follows:
9;:;=;<;< <0<1<3<4;6;8;9;:;=;
I randomly made 8,000 lines like this. In fine-tuning from eng, 5,000 iteration was almost good. Amount symbol still is confused a little when it's followed by 0. Fine tuning tends to be dragged by small particles. I'll have to think of something to make further improvement.
Training from scratch produced a bit more stable traineddata. It doesn't get confused with symbols so often but tends to generate extra spaces. By 10,000 iterations, those spaces are gone and recognition became very solid.
I thought I might have to do image and box file training but I guess it's not needed this time.
ElMagoElGato
2019年7月26日金曜日 14時08分06秒 UTC+9 ElGato ElMago:
2019年7月26日金曜日 14時08分06秒 UTC+9 ElGato ElMago:
2019年6月14日金曜日 1時48分40秒 UTC+9 shree:
For more options, visit <a href="https://groups.google.com/d/optout"

Mamadou
Aug 6, 2019, 7:20:02 PM8/6/19
to tesseract-ocr
Hello,
Are you planning to release the dataset or models?I'm working on the same subject and planning to share both under BSD terms
2019年6月14日金曜日 1時48分40秒 UTC+9 shree:
2019年5月29日水曜日 19時14分08秒 UTC+9 shree:
____________________________________________________________
भजन - कीर्तन - आरती @ <a href="http://bhajans.ramparivar.com" rel="nofollow" target="_blank" onmousedown="this.href='http://www.google.com/url?q\x3dh
ElGato ElMago
Aug 6, 2019, 8:36:52 PM8/6/19
to tesseract-ocr
HI,
I'm thinking of sharing it of course. What is the best way to do it? After all this, the contribution part of mine is only how I prepared the training text. Even that is consist of Shree's text and mine. The instructions and tools I used already exist.
ElMagoElGato
2019年8月7日水曜日 8時20分02秒 UTC+9 Mamadou:
2019年8月7日水曜日 8時20分02秒 UTC+9 Mamadou:
2019年6月14日金曜日 1時48分40秒 UTC+9 shree:
2019年5月29日水曜日 19時14分08秒 UTC+9 shree:
</blockquote
Mamadou
Aug 7, 2019, 8:11:01 AM8/7/19
to tesseract-ocr
On Wednesday, August 7, 2019 at 2:36:52 AM UTC+2, ElGato ElMago wrote:
HI,I'm thinking of sharing it of course. What is the best way to do it? After all this, the contribution part of mine is only how I prepared the training text. Even that is consist of Shree's text and mine. The instructions and tools I used already exist.
If you have a Github account just create a repo and publish the data and instructions.
2019年6月14日金曜日 1時48分40秒 UTC+9 shree:
2019年5月29日水曜日 19時14分08秒 UTC+9 shree:
I read the training tutorial and made a base_checkpoint file according to the method in Training From Scratch. Now, how can I make a trained data from the base_checkpoint file?</di
ElGato ElMago
Aug 7, 2019, 8:35:17 PM8/7/19
to tesseract-ocr
OK, I'll do so. I need to reorganize naming and so on a little bit. Will be out there soon.
2019年8月7日水曜日 21時11分01秒 UTC+9 Mamadou:
2019年8月7日水曜日 21時11分01秒 UTC+9 Mamadou:
</d
ElGato ElMago
Aug 9, 2019, 1:31:03 AM8/9/19
to tesseract-ocr
Here's my sharing on GitHub. Hope it's of any use for somebody.
2019年6月14日金曜日 1時48分40秒 UTC+9 shree:
2019年5月29日水曜日 19時14分08秒 UTC+9 shree:see <a style="font-family: Arial,Helvetica,sans-serif; font-size: small;" onmousedown="this.href='https://www.google.com/url?q\x3dhttps%3A%2F%2Fgithub.com%2Ftesseract-ocr%2Ftesseract%2Fwiki%2FTrainingTesseract-4.00%23combining-the-output-files\x26sa\x3dD\x26sntz\x3d1\x26usg\x3dAFQjCNE52zlo1Ag3z7wNDKcmFL3rMf5LXQ';return true;" onclick="this.href='https://www.google.com/url?q\x3dhttps%3A%2F%2Fgithub.com%2Ftesseract-ocr%2Ftesseract%2Fwiki%2FTrainingTesseract-4.00%23combining-the-output-files\x26sa\x3dD\x26sntz\x3d1\x26usg\x3dAFQjCNE52zlo1Ag3z7wNDKcmFL3rMf5LXQ';retur
Mamadou
Aug 9, 2019, 3:17:41 AM8/9/19
to tesseract-ocr
On Friday, August 9, 2019 at 7:31:03 AM UTC+2, ElGato ElMago wrote:
Here's my sharing on GitHub. Hope it's of any use for somebody.
Thanks for sharing your experience with us.
Is it possible to share your Tesseract model (xxx.traineddata)?
We're building a dataset using real life images like what we have already done for MRZ (https://github.com/DoubangoTelecom/tesseractMRZ/tree/master/dataset).
Your model would help us to automated the annotation and will speedup our devs. Off course we'll have to manualy correct the annotations but it will be faster for us.
Also, please add a license to your repo so that we know if we have right to use it
ElGato ElMago
Aug 9, 2019, 4:40:15 AM8/9/19
to tesseract-ocr
I added eng.traineddata and LICENSE. I used my account name in the license file. I don't know if it's appropriate or not. Please tell me if it's not.
2019年8月9日金曜日 16時17分41秒 UTC+9 Mamadou:
2019年8月9日金曜日 16時17分41秒 UTC+9 Mamadou:
Mamadou
Aug 9, 2019, 10:38:31 AM8/9/19
to tesseract-ocr
On Friday, August 9, 2019 at 10:40:15 AM UTC+2, ElGato ElMago wrote:
I added eng.traineddata and LICENSE. I used my account name in the license file. I don't know if it's appropriate or not. Please tell me if it's not.
It's ok.
Thanks. I'll share our dataset (real life samples) in the coming days.
Shree Devi Kumar
Aug 9, 2019, 11:35:14 AM8/9/19
to tesseract-ocr
I suggest to rename the traineddata file from eng. to e13b or another similar descriptive name and also add a link to it in the data file contributions wiki page.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/77754ce0-ecac-4ec1-9d35-3acaac29508d%40googlegroups.com.
ElGato ElMago
Aug 12, 2019, 10:51:01 PM8/12/19
to tesseract-ocr
So I did both renaming and adding a link in the wiki page.
2019年8月10日土曜日 0時35分14秒 UTC+9 shree:
2019年8月10日土曜日 0時35分14秒 UTC+9 shree:
To unsubscribe from this group and stop receiving emails from it, send an email to tesser...@googlegroups.com.

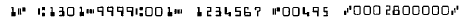{kind=link}
{kind=link}
Mamadou
Sep 17, 2019, 1:44:59 AM9/17/19
to tesseract-ocr
Hello,
Thanks again for sharing your E-13B traineddata, it was helpful. We’ve managed to get good accuracy for E-13B with Tesseract but failed with CMC-7. So, we ended using TensorFlow for both fonts. I’m curious to know which level of accuracy you’ve reached. You can check our accuracy for Tesseract using app at https://github.com/DoubangoTelecom/tesseractMICR#the-recognizer-app. For Tensorflow at https://www.doubango.org/webapps/micr/.
Also, have you tried with real life samples (e.g. random images from Google search)? Why are you including the SPACE in your charset and training data? It makes the convergence harder. As promised, the dataset is hosted at https://github.com/DoubangoTelecom/tesseractMICR
ElGato ElMago
Sep 19, 2019, 3:14:06 AM9/19/19
to tesseract-ocr
Hello,
CMC-7 is totally a different font than E13B. It's only E13B around myself. I've never seen CMC-7 in person.
I had about 100 sample checks and used a check reading machine, one of those at banks. Thus they're in the same image quality and character quality.
Although it's a small sample, there was no phantom character, no wrong-reading on symbols, nor on numerics in the end. There was one isolated word with two characters that had been skipped. Number of spaces between words tend to be shorter than real, which causes no problem in parsing.
I'm sort of done at the moment. Not going for extensive training. I'd think you could improve the training text for CMC-7. The training with neural network (LSTM) works like a magic but it somewhat depends on how the training text is prepared. I analyzed bad boxing with hocr output and put those patterns more in the training text.
Hope this helps.
ElMagoElGato
2019年9月17日火曜日 14時44分59秒 UTC+9 Mamadou:
2019年9月17日火曜日 14時44分59秒 UTC+9 Mamadou:
Reply all
Reply to author
Forward
0 new messages