Tesseract makes different predictions on seemingly equal images. How to make it more robust?
133 views
Skip to first unread message

MysteriousGuy
Jul 14, 2020, 10:04:49 AM7/14/20
to tesseract-ocr
I am using Tesseract to extract text from images attached. For some reason, even though the images are nearly identical, tesseract makes a mistake in one of them: for 'bad.png' the output is ELHADIJ, whereas for 'good.png' it is ELHADJ
Here is what I have and done:
- tesseract version: 4.0.0-beta.1
- leptonica version: 1.75.3
- I use English .traineddata file from here: https://github.com/tesseract-ocr/tessdata_best/blob/master/eng.traineddata
- I tried these page segmentation modes: 3, 7, 8, 13 - the mistake is always there.
So the commands I ran were
tesseract good.png output1 -l eng --psm 8
tesseract bad.png output2 -l eng --psm 8
and similarly for other PSMs
My question is: how do I make tesseract more robust? Why does it make a mistake in one case but not in the other?

Zdenko Podobny
Jul 14, 2020, 10:13:40 AM7/14/20
to tesser...@googlegroups.com
Try to use the latest version of tesseract.
Zdenko
ut 14. 7. 2020 o 16:04 MysteriousGuy <gyt...@gmail.com> napísal(a):
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/81a83479-b266-4686-a2d8-fae2d5916831o%40googlegroups.com.
MysteriousGuy
Jul 15, 2020, 3:01:14 AM7/15/20
to tesseract-ocr
Hi. Latest stable version (4.1.1) produces the same error
2020 m. liepa 14 d., antradienis 17:13:40 UTC+3, zdenop rašė:
Try to use the latest version of tesseract.Zdenko
ut 14. 7. 2020 o 16:04 MysteriousGuy <gyt...@gmail.com> napísal(a):
--I am using Tesseract to extract text from images attached. For some reason, even though the images are nearly identical, tesseract makes a mistake in one of them: for 'bad.png' the output is ELHADIJ, whereas for 'good.png' it is ELHADJHere is what I have and done:
- tesseract version: 4.0.0-beta.1
- leptonica version: 1.75.3
- I use English .traineddata file from here: https://github.com/tesseract-ocr/tessdata_best/blob/master/eng.traineddata
- I tried these page segmentation modes: 3, 7, 8, 13 - the mistake is always there.
So the commands I ran weretesseract good.png output1 -l eng --psm 8tesseract bad.png output2 -l eng --psm 8and similarly for other PSMsMy question is: how do I make tesseract more robust? Why does it make a mistake in one case but not in the other?
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesser...@googlegroups.com.

Tuan Ardouin
Jul 15, 2020, 5:08:33 AM7/15/20
to tesseract-ocr
You need to apply some pre-processing to your image.
MysteriousGuy
Jul 15, 2020, 2:55:09 PM7/15/20
to tesseract-ocr
This seems like an ad-hoc approach. I am already converting images to grayscale. If I apply blurring, binarisation, etc. then I will solve this case but I will prompt another case to fail as a result. There is something with tesseract that fails to generalize on clearly near-identical images, and I am interested in what is it.

{kind=link}
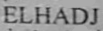{kind=link}
Lorenzo Bolzani
Jul 15, 2020, 3:31:15 PM7/15/20
to tesser...@googlegroups.com
I think the reason is that your input is bad so the model is confused and a few pixels are enough to see an extra letter.
Your input is "bad" because it is different from the one used to train the neural network. The difference between the two images is small but the difference from the training data for both is big.
If you improve your image with zero borders, less noise and a much stronger contrast, maybe even straighten the text this kind of problem should become much less common.
If you want to understand a little more why this is possible read something about how an LSTM ocr works. This is likely something in the step that tries to decide the letters from the neural network output (beam search, CTC). Not a bug just how it works.
I do not think there is much you can do, parameters, etc., other than improve your image or tesseract. Sometimes it happens even with fine tuned models.
Lorenzo
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/d6df0771-04e5-4e78-9109-28d91e2c2f2do%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages