How can I do the training using my own image in Tesseract 4.0
5,220 views
Skip to first unread message

chen...@huawei.com
Jan 17, 2017, 6:31:54 PM1/17/17
to tesseract-ocr
I have a bunch of images, containing English words.
I would like to generate training data by these images, and do the training.
How should I do?
Thanks a lot.

Kay-Michael Würzner
Feb 7, 2017, 9:57:28 AM2/7/17
to tesseract-ocr
+1 for this question. The training documentation for Tesseract 4.0 by now only covers training with font files (synthetic materials). What is missing is information on training with real data (i.e. manually aligned ground truth).
Any hints on that matter are greatly appreciated.
Cheers,
Kay

ShreeDevi Kumar
Feb 7, 2017, 10:34:11 AM2/7/17
to tesser...@googlegroups.com
For LSTM training, box files need to have an additional line for each text line with the tab character to indicate a new line.
If you have existing box/tiff pairs, you can use a box editor (such as jtessboxeditor) and insert a box at end of each line and add a tab character in it.
>On the toolbar, the Character textbox has a built-in conversion function. If you enter U+0009 and hit Enter key or click on the adjacent Tool icon, the escape sequences will be converted to Unicode. You can also enter the tab character via Alt+09 numpad keys on Windows.
o
r add a dummy sequence such as @@@ and then replace to tab character in a text editor.
See attached files as a sample.
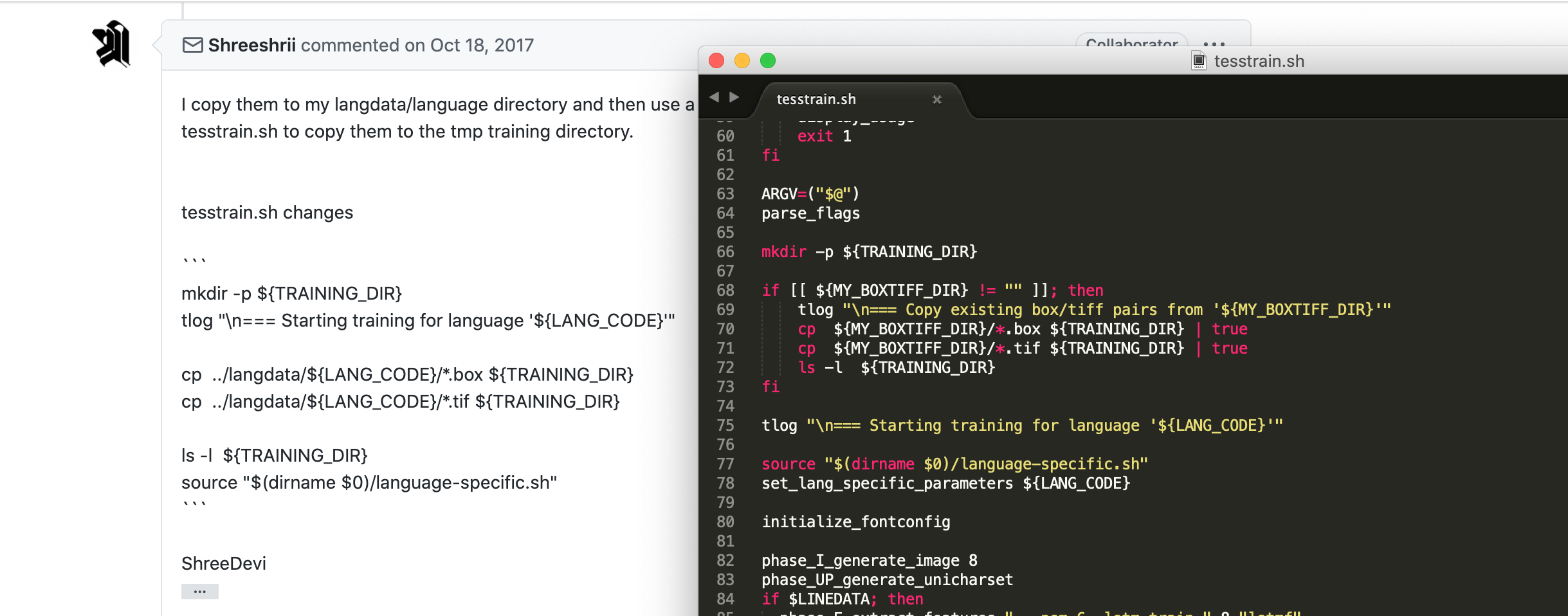
Then modify tesstrain.sh to copy the box tiff pairs to the training directory before starting training
mkdir -p ${TRAINING_DIR}
tlog "\n=== Starting training for language '${LANG_CODE}'"
cp ./*.box "${TRAINING_DIR}/"
cp ./*.tif "${TRAINING_DIR}/"
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-ocr+unsubscribe@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/7bffab95-3e6b-4165-929e-a152f1799703%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Quan Nguyen
Feb 8, 2017, 9:03:31 AM2/8/17
to tesseract-ocr
On Tuesday, February 7, 2017 at 9:34:11 AM UTC-6, shree wrote:
For LSTM training, box files need to have an additional line for each text line with the tab character to indicate a new line.If you have existing box/tiff pairs, you can use a box editor (such as jtessboxeditor) and insert a box at end of each line and add a tab character in it.
The jTessBoxEditor beta version has a new Mark EOL function that does just that.
>On the toolbar, the Character textbox has a built-in conversion function. If you enter U+0009 and hit Enter key or click on the adjacent Tool icon, the escape sequences will be converted to Unicode. You can also enter the tab character via Alt+09 numpad keys on Windows.or add a dummy sequence such as @@@ and then replace to tab character in a text editor.
See attached files as a sample.Then modify tesstrain.sh to copy the box tiff pairs to the training directory before starting trainingmkdir -p ${TRAINING_DIR}tlog "\n=== Starting training for language '${LANG_CODE}'"cp ./*.box "${TRAINING_DIR}/"cp ./*.tif "${TRAINING_DIR}/"
On Tue, Feb 7, 2017 at 8:27 PM, Kay-Michael Würzner <wuer...@gmail.com> wrote:
+1 for this question. The training documentation for Tesseract 4.0 by now only covers training with font files (synthetic materials). What is missing is information on training with real data (i.e. manually aligned ground truth).Any hints on that matter are greatly appreciated.Cheers,Kay
On Wednesday, January 18, 2017 at 12:31:54 AM UTC+1, chen...@huawei.com wrote:I have a bunch of images, containing English words.I would like to generate training data by these images, and do the training.How should I do?Thanks a lot.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
ShreeDevi Kumar
Feb 8, 2017, 9:52:58 AM2/8/17
to tesser...@googlegroups.com
Thanks, Quan
- excuse the brevity, sent from mobile
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-ocr+unsubscribe@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/ab8bc158-95b1-4c08-bc99-76a7442a919d%40googlegroups.com.
Kay-Michael Würzner
Feb 9, 2017, 5:08:13 AM2/9/17
to tesseract-ocr
Thanks also from my side. I'll have a look into the jTessBoxEditor beta, try to setup training and get back to you.
Kay

timothylegg
Feb 21, 2017, 2:06:40 AM2/21/17
to tesseract-ocr
I found this thread to be interesting since I tried training Tesseract a few years ago and gave up. Has anybody considered writing any documentation on this something that is best explained whenever a user can't figure it out from trial/error? I'm open to maybe writing about this if there is a need for it, but first, I will have to understand it better myself.

BartoszN.
Jan 8, 2018, 3:21:00 PM1/8/18
to tesseract-ocr
Hi there,
Any news about training Tesseract 4.0?
I'm trying to train my fonts for few days... but still can't go anywhere.
I'm looking for compact manual for training from txt/ttf files for new fonts in various languages.
Will be appreciate for any help.
Any news about training Tesseract 4.0?
I'm trying to train my fonts for few days... but still can't go anywhere.
I'm looking for compact manual for training from txt/ttf files for new fonts in various languages.
Will be appreciate for any help.

Anubhav Rohatgi
Jan 11, 2018, 2:19:23 AM1/11/18
to tesseract-ocr
Hi Shree,
The box file uploaded by you as the attachment seems to contradict with the LSTM4.0 training tutorial guidelines, as there it states that the boxes should actually be at line level instead of at character level. Please do correct me if I am wrong. I still am not able to understand how to train tesseract on real image data I have collected from scanned documents. It would be beneficial to all of us here if we could have a sample video guiding us on how to train tesseract, at least the starting steps with proper commands.
Thanks in advance.
Anubhav
On Tuesday, 7 February 2017 21:04:11 UTC+5:30, shree wrote:
For LSTM training, box files need to have an additional line for each text line with the tab character to indicate a new line.If you have existing box/tiff pairs, you can use a box editor (such as jtessboxeditor) and insert a box at end of each line and add a tab character in it.>On the toolbar, the Character textbox has a built-in conversion function. If you enter U+0009 and hit Enter key or click on the adjacent Tool icon, the escape sequences will be converted to Unicode. You can also enter the tab character via Alt+09 numpad keys on Windows.or add a dummy sequence such as @@@ and then replace to tab character in a text editor.
See attached files as a sample.Then modify tesstrain.sh to copy the box tiff pairs to the training directory before starting trainingmkdir -p ${TRAINING_DIR}tlog "\n=== Starting training for language '${LANG_CODE}'"cp ./*.box "${TRAINING_DIR}/"cp ./*.tif "${TRAINING_DIR}/"
On Tue, Feb 7, 2017 at 8:27 PM, Kay-Michael Würzner <wuer...@gmail.com> wrote:
+1 for this question. The training documentation for Tesseract 4.0 by now only covers training with font files (synthetic materials). What is missing is information on training with real data (i.e. manually aligned ground truth).Any hints on that matter are greatly appreciated.Cheers,Kay
On Wednesday, January 18, 2017 at 12:31:54 AM UTC+1, chen...@huawei.com wrote:I have a bunch of images, containing English words.I would like to generate training data by these images, and do the training.How should I do?Thanks a lot.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
ShreeDevi Kumar
Jan 11, 2018, 3:57:43 AM1/11/18
to tesser...@googlegroups.com
Currently, Ray/Google has NOT released info on how to train Tesseract 4 (LSTM) with real life images. The only supported option is to use synthetic training data created by tesstrain.sh script using training text and unicode fonts.
To train an LSTM model from scratch requires a large amount of training data and huge computing resources and time (in days/weeks).
As a user, your best bet for training is to try finetuning for a particular font or adding a couple of characters.

minh...@gmail.com
Aug 8, 2020, 12:13:46 AM8/8/20
to tesseract-ocr
Dear Quan,
I don't see Mark EOL function, is it in Box Editor tab, or it is automatic add box a box at end of each line and add a tab character when using Generator?
Thanks,
TuPM
minh...@gmail.com
Aug 8, 2020, 12:36:14 AM8/8/20
to tesseract-ocr
This post from 2017,
PANGOCAIRO_BACKEND=fc \
~/tesseract/src/training/tesstrain.sh \
--fonts_dir /Library/Fonts \
--lang vie \
--linedata_only \
--noextract_font_properties \
--exposures "0" \
--langdata_dir ~/tesstutorial/langdata \
--tessdata_dir ~/tesstutorial/tesseract/tessdata \
--fontlist "Times New Roman" \
--output_dir ~/tesstutorial/vietrain
do I have to change it with tesseract 5.0 version
Because the code already indicate the langdata --langdata_dir ~/tesstutorial/langdata \
the tesstrain.sh as follow:
~/tesseract/src/training/tesstrain.sh \
--fonts_dir /Library/Fonts \
--lang vie \
--linedata_only \
--noextract_font_properties \
--exposures "0" \
--langdata_dir ~/tesstutorial/langdata \
--tessdata_dir ~/tesstutorial/tesseract/tessdata \
--fontlist "Times New Roman" \
--output_dir ~/tesstutorial/vietrain
Best regards,
TuPM
On Tuesday, February 7, 2017 at 10:34:11 PM UTC+7 shree wrote:
For LSTM training, box files need to have an additional line for each text line with the tab character to indicate a new line.If you have existing box/tiff pairs, you can use a box editor (such as jtessboxeditor) and insert a box at end of each line and add a tab character in it.>On the toolbar, the Character textbox has a built-in conversion function. If you enter U+0009 and hit Enter key or click on the adjacent Tool icon, the escape sequences will be converted to Unicode. You can also enter the tab character via Alt+09 numpad keys on Windows.or add a dummy sequence such as @@@ and then replace to tab character in a text editor.See attached files as a sample.Then modify tesstrain.sh to copy the box tiff pairs to the training directory before starting trainingmkdir -p ${TRAINING_DIR}tlog "\n=== Starting training for language '${LANG_CODE}'"cp ./*.box "${TRAINING_DIR}/"cp ./*.tif "${TRAINING_DIR}/"On Tue, Feb 7, 2017 at 8:27 PM, Kay-Michael Würzner <wuer...@gmail.com> wrote:+1 for this question. The training documentation for Tesseract 4.0 by now only covers training with font files (synthetic materials). What is missing is information on training with real data (i.e. manually aligned ground truth).Any hints on that matter are greatly appreciated.Cheers,Kay
On Wednesday, January 18, 2017 at 12:31:54 AM UTC+1, chen...@huawei.com wrote:I have a bunch of images, containing English words.I would like to generate training data by these images, and do the training.How should I do?Thanks a lot.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.

sat...@jukshio.com
Aug 22, 2020, 3:56:08 PM8/22/20
to tesseract-ocr
Hi Sir/madam
I am requesting for the following questions
can we print the input shape and output shape for each layer in the training process
can you explain how an image feed into the LSTM cells with timestamps in the training process ?
how does Tesseract language model work in the training
I am requesting for the following questions
can we print the input shape and output shape for each layer in the training process
can you explain how an image feed into the LSTM cells with timestamps in the training process ?
how does Tesseract language model work in the training

Murtuza Dahodwala
Jan 8, 2021, 3:32:41 AM1/8/21
to tesseract-ocr
It is now 2 years since this answer was posted. Is it possible to train tesseract 4 on real images now?
Kay-Michael Würzner
Jan 9, 2021, 9:34:18 AM1/9/21
to tesser...@googlegroups.com
Of course you can! Just checkout the tesstrain tool:
https://github.com/tesseract-ocr/tesstrain
Cheers,
Kay
> --
> You received this message because you are subscribed to a topic in the Google Groups "tesseract-ocr" group.
> To unsubscribe from this topic, visit https://groups.google.com/d/topic/tesseract-ocr/S8g4ihT9sXQ/unsubscribe.
> To unsubscribe from this group and all its topics, send an email to tesseract-oc...@googlegroups.com.
> To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/2afd940d-f7e1-48f7-8792-a1542741d336n%40googlegroups.com.
https://github.com/tesseract-ocr/tesstrain
Cheers,
Kay
> You received this message because you are subscribed to a topic in the Google Groups "tesseract-ocr" group.
> To unsubscribe from this topic, visit https://groups.google.com/d/topic/tesseract-ocr/S8g4ihT9sXQ/unsubscribe.
> To unsubscribe from this group and all its topics, send an email to tesseract-oc...@googlegroups.com.
> To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/2afd940d-f7e1-48f7-8792-a1542741d336n%40googlegroups.com.
Murtuza Dahodwala
Jan 12, 2021, 12:29:34 AM1/12/21
to tesseract-ocr
Tesstrain only uses single line of text for training. I want to train several block of texts.

Ajinkya Bobade
Jan 12, 2021, 2:01:08 PM1/12/21
to tesser...@googlegroups.com
Hi,
If you need help on training tesseract 4 please write me mail at ajinkya...@gmail.com
Regards
Ajinkya
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/e5ebc5f9-d59d-49c4-944f-9348999691a6n%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages