OCR on number 0 usualy working but not always
48 views
Skip to first unread message

Sofie Geens
Mar 1, 2023, 10:05:11 AM3/1/23
to tesseract-ocr
I want to read numbers with pytesseract and it does it with 100% accuracy until a certain point, from there it just doesn't read anything anymore. The total grid of numbers I want to read looks something like this:
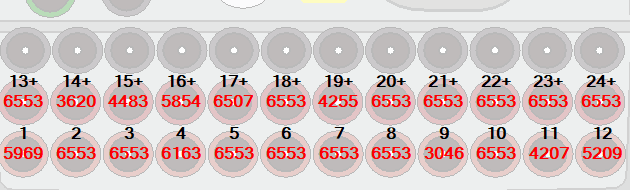
I only want to know the red numbers (these are green when smaller then 10). To read the numbers, I take screenshots from only the number that looks something like this:
 or
or 
Then I remove the background, and make the numbers bigger so that the number is about 30 pixels high. That looks like this:

Then I try use the following line of code to read this:
result = pytesseract.image_to_string(img, lang='eng', config='--psm 10 --oem 3 -c tessedit_char_whitelist=0123456789')
print(result)
print(result)
This works for all the red numbers and some of the green numbers. The ones on the bottom row work perfectly, even when the number becomes 0. When it reaches the top row however, red and green works, except for the 0. It always fails there. The picture it tries to read is the one shown before (white background, big black 0, I don't have an example of a 0 where it works fine). I have no clue why it doesn't work, I do the exact same preprocessing as with the bottom row, but don't get the same good results. What can I do to get this to work?
Reply all
Reply to author
Forward
0 new messages