Tesseract doesn't recognize some numbers from an image

javalover
In order to calculate the correct skew angle, we compare the maximum difference between peaks and using this skew angle, thus rotate the image using the correct angle to correct the skew.
Each image (which has a single number) has prefixed background and foreground (number) color:
- If the first pixel of the background is black, the foreground is dark gray.
- If the first pixel of the background is white, the foreground is dark white.
Here are some sample images:
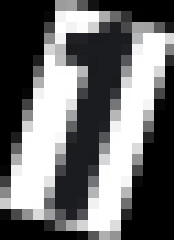
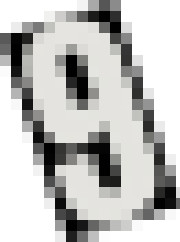
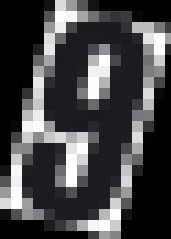
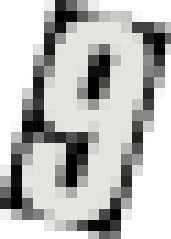
which all of them get successfully deskewed to these:
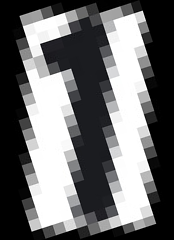

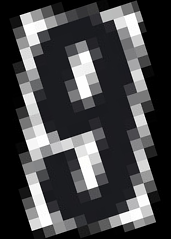

After it's been deskewed, I've tried with no luck to improve image quality to let OCR (PyTesseract) recognize the numbers.
import cv2
import numpy as np
import scipy.ndimage
import pytesseract
from PIL import Image, ImageEnhance, ImageFilter
from scipy.ndimage import interpolation as inter
def correct_skew(image, delta=6, limit=150):
def determine_score(arr, angle):
data = inter.rotate(arr, angle, reshape=False, order=0)
histogram = np.sum(data, axis=1)
score = np.sum((histogram[1:] - histogram[:-1]) ** 2)
return histogram, score
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.medianBlur(gray, 21)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
scores = []
angles = np.arange(-limit, limit + delta, delta)
for angle in angles:
histogram, score = determine_score(thresh, angle)
scores.append(score)
best_angle = angles[scores.index(max(scores))] + 90
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, best_angle, 1.0)
rotated = cv2.warpAffine(image, M, (w, h), flags=cv2.INTER_CUBIC)
## Image processing to improve OCR accuracy
"""
#rotated = cv2.medianBlur(rotated, 20)
rotated = rotated.astype(np.float) / 255.
# Calculate channel K:
rotated = 1 - np.max(rotated, axis=2)
# Convert back to uint 8:
rotated = (255 * rotated).astype(np.uint8)
binaryThresh = 190
_, binaryImage = cv2.threshold(rotated, binaryThresh, 255, cv2.THRESH_BINARY)
binaryThresh = 190
_, binaryImage = cv2.threshold(rotated, binaryThresh, 255, cv2.THRESH_BINARY)
# Use a little bit of morphology to clean the mask:
# Set kernel (structuring element) size:
kernelSize = 3
# Set morph operation iterations:
opIterations = 2
# Get the structuring element:
morphKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (kernelSize, kernelSize))
# Perform closing:
rotated = cv2.morphologyEx(binaryImage, cv2.MORPH_CLOSE, morphKernel, None, None, opIterations, cv2.BORDER_REFLECT101)
"""
return best_angle, rotated
if __name__ == '__main__':
image = cv2.imread('number.jpg')
if image[0][0][0] > 128: image = cv2.bitwise_not(image)
angle, rotated = correct_skew(image)
print(angle)
cv2.imshow('rotated', rotated)
cv2.imwrite('rotated.png', rotated)
pytesseract.pytesseract.tesseract_cmd = r'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
text = pytesseract.image_to_string(rotated, config="-c tessedit_char_whitelist=0123456789")
print("number:", text)
cv2.waitKey()
This code (PyTesseract) recognizes the first and the second number, while not the others. Why?

Zdenko Podobny
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/b6d80f87-893b-40de-8067-a0cb1b0865d2n%40googlegroups.com.
javalover
If you've tried the above and are still getting low accuracy results, ask on the forum for help, ideally posting an example image.
- Rescaling
- Binarisation
- Noise Removal
- Dilation / Erosion
- Rotation / Deskewing
- Borders
- Transparency / Alpha channel
- Tools / Libraries
- Examples
- Tables recognitions
Zdenko Podobny
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/9626b246-4983-439e-b2dc-24b7b77ec1d5n%40googlegroups.com.
javalover
@zdenop: the code I posted in the @OP doesn't have do the rescaled image and removed borders but I've already tried with no luck.
