Improve OCR Accuracy
297 views
Skip to first unread message

Hamzeh abu-ajameia
Mar 26, 2021, 9:46:52 AM3/26/21
to tesseract-ocr
Hi Everyone,
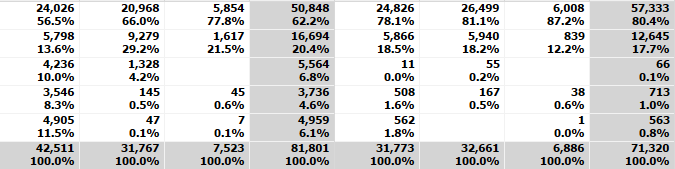
I am a newbie to OCR, I've been trying to reach a 99% accuracy but i didn't manage to, would you please give some tips to improve the results, below is a amole of used codes, it keeps skip some numbers and sometime predict wrong numbers.
Code :
import cv2 import pytesseract
# Load the image
img = cv2.imread("FD2sX.png")
# Up-sample
img = cv2.resize(img, (0, 0), fx=2, fy=2)
# Convert to the gray-scale
gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# OCR
print(pytesseract.image_to_string(gry))
The results
24,026
56.5%
5,798
13.6%
4,236
10.0%
3,546
8.3%
4,905
11.5%
42,511
100.0%
20,968
66.0%
9,279
29.2%
1,328
4.2%
145
0.5%
47
0.1%
31,767
100.0%
5,854
77.8%
1,617
21.5%
45
0.6%
0.1%
7,523
100.0%
50,848
62.2%
16,694
20.4%
5,564
3,736
4.6%
4,959
6.1%
81,801
100.0%
24,826
78.1%
5,866
18.5%
11
0.0%
1.6%
562
1.8%
31,773
100.0%
26,499
81.1%
5,940
18.2%
55
0.2%
167
0.5%
32,661
100.0%
6,008
87.2%
839
12.2%
0.6%
0.0%
6,886
100.0%
57,333
80.4%
12,645
17.7%
0.1%
713
1.0%
0.8%
71,320
100.0%
Thanks in advance.

Lorenzo Bolzani
Mar 26, 2021, 10:09:00 AM3/26/21
to tesser...@googlegroups.com
Hi Hamzeh,
next time please explain exactly where the problem is so that people here do not have to manually check all the numbers to spot the mistakes.
Try to threshold the image and upscale it more, I would start with four times.
Bye
Lorenzo
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/d1c54d14-0eb4-49e4-8483-a1bb4c2d8748n%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages