Force Tesseract to do individual character OCR only
4,180 views
Skip to first unread message

Dave Wood
Oct 29, 2019, 12:12:34 AM10/29/19
to tesseract-ocr
I am trying to use Tesseract to OCR screen shots from various Windows applications. So essentially the data is a random collection of letters and numbers, not written words/sentences like it was primarily oriented to handle.
Here is my setup:
-Tesseract Windows Version 5.0.0 from UB-Mannheim
-image cleaning and resizing using openCV (have put much effort into getting this as good as I can)
-parameters --psm 6 --oem 1 (have also tried oem 0 and 3 with pretty much same results)
-config file contents
language_model_penalty_non_dict_word 0.0
language_model_penalty_chartype 0.0
language_model_penalty_case 0.0
language_model_penalty_non_freq_dict_word 0.0
Tesseract is performing reasonably well for my needs, but I have a couple of problems that I can't resolve. They seem to be related to Tesseract functionality which tries to decide what a given character is not just based on its pixel layout, but also based on the context that the character occurs in.
Issue #1
Occasionally Tesseract inserts extra characters in its output, seemingly when it is unsure how to choose between a couple of different alternatives:
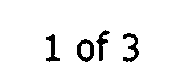
For the above image, Tesseract produces the following output:
10of3
As you can see, Tesseract inserts the digit 0 in front of the lower case letter o in the output. It also ignores the white space in the image.
Others have reported this issue, for example the thread below:
Issue #2
As shown in the above example, Tesseract sometimes ignores white space which at least to my eye is big enough not to be missed.
Issue #3
Tesseract has a hard time dealing with random strings of alpha characters and digits mixed together in no particular order. It has a tendency to output a digit when the previous character was a digit, and an alpha when the previous character was an alpha.
Others have reported this issue, for example the thread below:
Suggestion:
At least for my situation, it seems that the best thing would be if there were a definitive Tesseract option to interpret individual characters without reference to their context. Since my data comes from screen shots, it is very clear and very consistent, and I would think that a character-by-character mode would work well.

Shree Devi Kumar
Oct 29, 2019, 12:18:06 AM10/29/19
to tesseract-ocr
Have you tried to ocr it character by character, using appropriate psm.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/a434e930-a53e-44e0-bfd7-a46385ea091a%40googlegroups.com.
Dave Wood
Oct 29, 2019, 1:38:28 PM10/29/19
to tesseract-ocr
Thanks for the reply Shree. However, I don't think processing character by character is practical. The example I sent is just selected randomly from one of the screen shots I have processed. In general, I do not know where the characters are, so I would need to use Tesseract just to figure that out in the first place.
I am attaching the character level HOCR output from this same image. If you look at it, you can see that the location of the boxes containing digit zero and the lower case letter o overlap significantly, and the digit zero has a lower confidence score than the letter o. Consequently, since this information is clearly available to Tesseract as it does it's processing, there could be configuration settings which tell it just to choose the highest scoring character in the case where the boxes for two or more characters overlap by some configurable percentage (in my case I would choose 50% or so).
Dave Wood
Oct 29, 2019, 6:38:13 PM10/29/19
to tesseract-ocr
My Issue#2 above is the case when Tesseract does not separate items which to my eye at least are far enough apart to be considered separate. I have captured the full list of Tesseract configuration parameters and there are many of them that deal with the issue of spacing. However, there are too many of them for me to figure out which ones might be relevant for dealing with the example I have provided. Is there anybody out there who could give me some suggestions in this regard?
Thanks.
On Monday, October 28, 2019 at 9:12:34 PM UTC-7, Dave Wood wrote:

Lorenzo Bolzani
Oct 30, 2019, 5:45:06 AM10/30/19
to tesser...@googlegroups.com
Hi,
first crop the white border around the text. In this way I get correct the result.
Try this on a large batch of data and see what works best, no border, one pixel border, etc.. Also try different text sizes, from 30 to 50, just upscale the image.
If this does not help have a look here:
https://github.com/tesseract-ocr/tesseract/pull/2635
https://github.com/tesseract-ocr/tesseract/blob/84c410a8e30bd0ae589871b985f62e708a702fb1/src/ccmain/tesseractclass.h#L1078
https://github.com/tesseract-ocr/tesseract/blob/84c410a8e30bd0ae589871b985f62e708a702fb1/src/ccmain/tesseractclass.h#L1078
I did not try these myself yet, I do not know the exact situation for the 5.x version you are using, but could be something to try.
I would try lstm_choice_mode 1 and 2 and lstm_choice_iterations a few values above and below 5 (probably above is better)
I think a tesseract mode where characters are interpreted out of context is not possible as the neural network uses the context to recognize the characters, is not something you can switch off. The solution would be a different model trained/fine tuned on randomly mixed text and not on real words.
Lorenzo
Dave Wood
Oct 30, 2019, 2:32:29 PM10/30/19
to tesseract-ocr
Thanks for the response Lorenzo.
I did try your suggestion about lstm_choice parameters, trying many combinations, but that didn't make any difference. What would make sense to me would be if there was an option to tell Tesseract not to output multiple characters where the box overlaps significantly, like in the case of this small example. If you look at the HOCR output from this image, you can see that the boxes for both the 'o' and the '0' overlap by 90%. Tesseract should have an option to tell it to output only the highest confidence level character as opposed to both choices.
On Monday, October 28, 2019 at 9:12:34 PM UTC-7, Dave Wood wrote:
Lorenzo Bolzani
Oct 31, 2019, 7:20:07 AM10/31/19
to tesser...@googlegroups.com
Hi Dave,
are you sure the parameters are being used? For example setting lstm_choice_mode to an invalid number or lstm_choice_iterations to zero should at least produce some errors. With lstm_choice_mode > 0 you should get the extra matches in the HOCR.
About the boxes, these are a problem in decoding the neural network output. Sometimes the overlap is big other times an individual characters is fragmented in small parts, they are not so easy to detect and also to decide which character to keep (the confidence is not completely reliable as the decoding had problems).
You can see some more examples here in this issue I created some time ago (for 4.0):
What you, or tesseract, could do is to analyse the boxes and fix these problems. This is what I do with ugly custom code and I can fix most of these problems even if sometimes I introduce some new errors too.
But those boxes are what tesseract just produced so processing these again does not make much sense, it should simply generate them correctly in the first place (like they tried to do in 4.1). This, I think, is why there is no option to process those boxes again (the double letters are not alternatives, are distinct letters. You can get alternatives choices but, with lstm_choice_mode, but it is a different thing).
Did you try 4.1 version? 5.x is not released yet (but I do not expect big differences). Did you try to crop the border?
Lorenzo
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/6eee7de8-b364-4fa2-afbe-b8992b4ed050%40googlegroups.com.
Dave Wood
Nov 4, 2019, 11:38:51 PM11/4/19
to tesseract-ocr
Hi again Lorenzo,
And thanks again for the informative reply. Looks like your issue in the link you sent most recently is pretty much the same as the example I posted. That is, Tesseract includes multiple character choices in the output stream for what is clearly just one character in the input image.
I did experiment with the parameters you mention, and I am confident that I did use them accurately, but they were no help. For my little example, all valid values for lstm_choice_mode behaved the same way, namely giving multiple options for one character. What I want is to get a single character, not multiple options. Surely there must be some way to tell Tesseract to do that, in other words just include the highest confidence level character when there are multiple options for the same area of the input image.
I too am considering processing the HOCR output stream to remove the duplicates and then reassemble the items and lines, but that seems like a lot of work for something that should be easily handled by Tesseract in the first place.
Regards,
Dave
On Thursday, October 31, 2019 at 4:20:07 AM UTC-7, Lorenzo Blz wrote:
Hi Dave,are you sure the parameters are being used? For example setting lstm_choice_mode to an invalid number or lstm_choice_iterations to zero should at least produce some errors. With lstm_choice_mode > 0 you should get the extra matches in the HOCR.About the boxes, these are a problem in decoding the neural network output. Sometimes the overlap is big other times an individual characters is fragmented in small parts, they are not so easy to detect and also to decide which character to keep (the confidence is not completely reliable as the decoding had problems).You can see some more examples here in this issue I created some time ago (for 4.0):What you, or tesseract, could do is to analyse the boxes and fix these problems. This is what I do with ugly custom code and I can fix most of these problems even if sometimes I introduce some new errors too.But those boxes are what tesseract just produced so processing these again does not make much sense, it should simply generate them correctly in the first place (like they tried to do in 4.1). This, I think, is why there is no option to process those boxes again (the double letters are not alternatives, are distinct letters. You can get alternatives choices but, with lstm_choice_mode, but it is a different thing).Did you try 4.1 version? 5.x is not released yet (but I do not expect big differences). Did you try to crop the border?Lorenzo
To unsubscribe from this group and stop receiving emails from it, send an email to tesser...@googlegroups.com.
Reply all
Reply to author
Forward
0 new messages