Training Tesseract 5 with known data in tables
1,670 views
Skip to first unread message

Peter Vallsten
May 22, 2022, 1:04:46 PM5/22/22
to tesseract-ocr
Hi!
I'm trying to get started with Tesseract and OCR to make my life a bit easier. I'll try to be as descriptive as possible.
I'm trying to get started with Tesseract and OCR to make my life a bit easier. I'll try to be as descriptive as possible.
Basically what I'm trying to do:
Me and my friends are playing F1 together over Ps5 and I have google sheets with all the stats from our races. Link to document: F1 Google Sheets stats

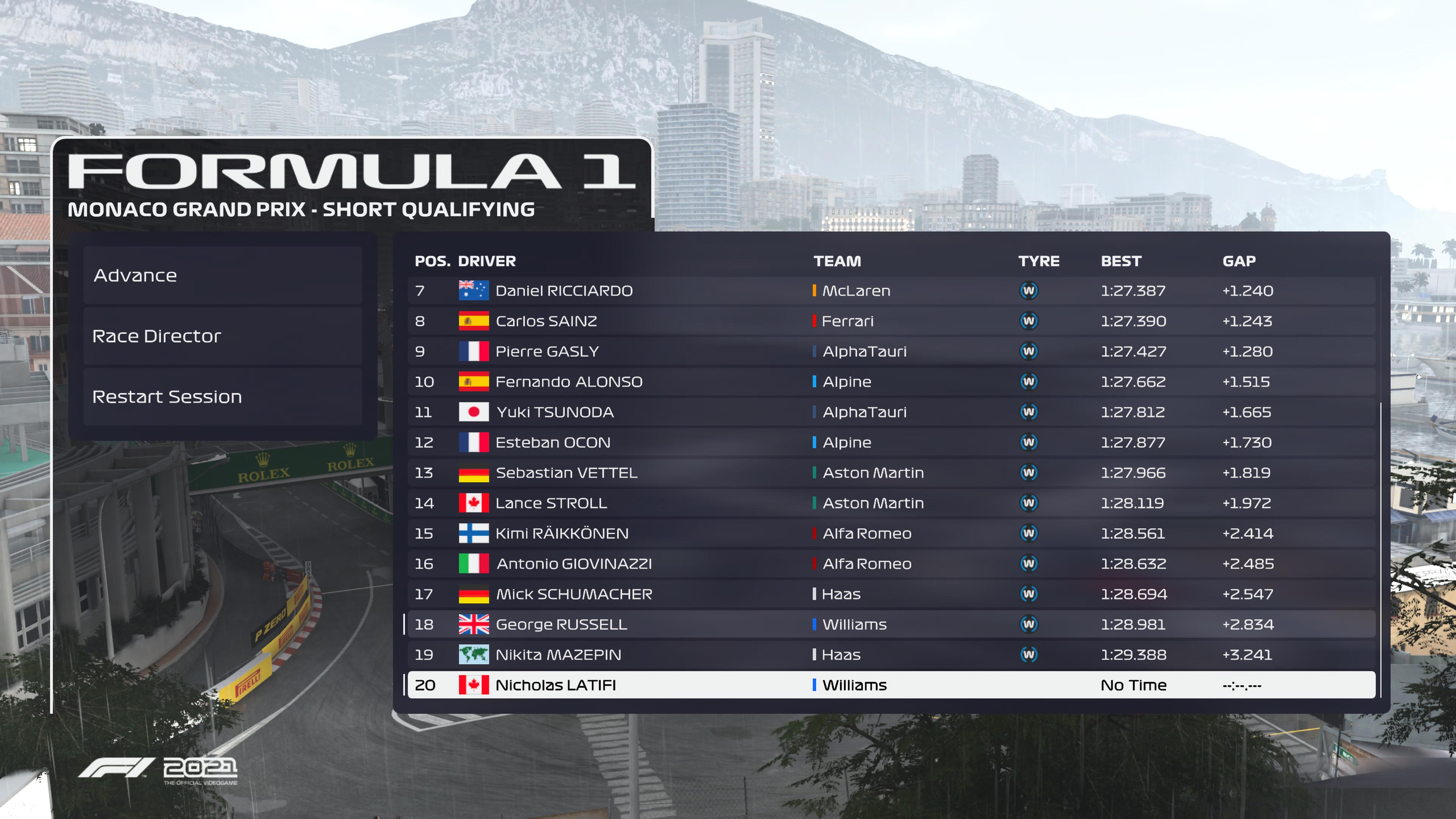
Me and my friends are playing F1 together over Ps5 and I have google sheets with all the stats from our races. Link to document: F1 Google Sheets stats
Right now I'm typing in all the data myself with is super tedious and time-consuming. I want to load a screenshot into tesseract and get the data ready to copy-paste into the document and make it more automatic. (Example in the bottom of this post)
What I want to do:
I want to parse the data from the screenshots, all the data is already known and the screenshots will be in clear 1080p pictures. I know the name of all the drivers and teams and the lap times are in the format: d:dd.ddd
and the gap times are in the format: +d.ddd (possible: +dd.ddd)
d = integer
I want the output of every position 1-20, name of the driver, team, lap time & gap time to leader.
What I've tried to do:
I'm on Windows so I installed Tesseract 5.1.0 with pre-build binaries. After some googling I got the feeling that Tesseract is easier with Linux so I installed Ubuntu via WSL and installed Tesseract there as well.
I followed the guide Training for Tesseract 5 and cloned "Tesstrain" repo.
But I'm very confused what "LSTM" is and what training modules are deprecated/unsupported for Tesseract 5.
The Tesstrain repo has "ocrd-testset.zip" with .tif files and textfiles that describe the expected output so I did the same with my case. (Included F1 training files as a zip to this post). I created a "data/foo-ground-truth" as described in tesstrain readme and ran "make training"
Output:
find -L data/foo-ground-truth -name '*.gt.txt' | xargs paste -s > "data/foo/all-gt"
unicharset_extractor --output_unicharset "data/foo/unicharset" --norm_mode 2 "data/foo/all-gt"
Bad box coordinates in boxfile string! 10 Fernando Alonso Alpine W 1:27.662 +1.515
Extracting unicharset from plain text file data/foo/all-gt
Other case I of i is not in unicharset
Other case U of u is not in unicharset
Other case Z of z is not in unicharset
Other case Ä of ä is not in unicharset
Other case Ö of ö is not in unicharset
Other case X of x is not in unicharset
Wrote unicharset file data/foo/unicharset
PYTHONIOENCODING=utf-8 python3 generate_line_box.py -i "data/foo-ground-truth/alonso.tif" -t "data/foo-ground-truth/alonso.gt.txt" > "data/foo-ground-truth/alonso.box"
Traceback (most recent call last):
File "generate_line_box.py", line 6, in <module>
from PIL import Image
ModuleNotFoundError: No module named 'PIL'
Makefile:218: recipe for target 'data/foo-ground-truth/alonso.box' failed
make: *** [data/foo-ground-truth/alonso.box] Error 1)
unicharset_extractor --output_unicharset "data/foo/unicharset" --norm_mode 2 "data/foo/all-gt"
Bad box coordinates in boxfile string! 10 Fernando Alonso Alpine W 1:27.662 +1.515
Extracting unicharset from plain text file data/foo/all-gt
Other case I of i is not in unicharset
Other case U of u is not in unicharset
Other case Z of z is not in unicharset
Other case Ä of ä is not in unicharset
Other case Ö of ö is not in unicharset
Other case X of x is not in unicharset
Wrote unicharset file data/foo/unicharset
PYTHONIOENCODING=utf-8 python3 generate_line_box.py -i "data/foo-ground-truth/alonso.tif" -t "data/foo-ground-truth/alonso.gt.txt" > "data/foo-ground-truth/alonso.box"
Traceback (most recent call last):
File "generate_line_box.py", line 6, in <module>
from PIL import Image
ModuleNotFoundError: No module named 'PIL'
Makefile:218: recipe for target 'data/foo-ground-truth/alonso.box' failed
make: *** [data/foo-ground-truth/alonso.box] Error 1)
I'm quite stuck and don't know how to train my Tesseract 5. Is it deprecated? Should I downgrade my tesseract to version 4 or 3? Am I missing some dependencies? Anyone that can guide me how to train my Tesseract into doing what I want?
Tesseract version:
Output in the terminal: (tesseract --version)
tesseract 5.1.0-32-gf36c0
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.2) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found FMA
Found SSE4.1
Found OpenMP 201511
Found libarchive 3.2.2 zlib/1.2.11 liblzma/5.2.2 bz2lib/1.0.6 liblz4/1.7.1
Found libcurl/7.58.0 OpenSSL/1.1.1 zlib/1.2.11 libidn2/2.0.4 libpsl/0.19.1 (+libidn2/2.0.4) nghttp2/1.30.0 librtmp/2.3
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.2) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found FMA
Found SSE4.1
Found OpenMP 201511
Found libarchive 3.2.2 zlib/1.2.11 liblzma/5.2.2 bz2lib/1.0.6 liblz4/1.7.1
Found libcurl/7.58.0 OpenSSL/1.1.1 zlib/1.2.11 libidn2/2.0.4 libpsl/0.19.1 (+libidn2/2.0.4) nghttp2/1.30.0 librtmp/2.3
Python version: Output in the terminal: (py --version)
Pythonpy ???
Python 3.6.9
Python 3.6.9
Example:
The screenshots look like this:
Expected output:
Pos Driver Team Tyre Best Gap
1 Lewis Hamilton Mercedes-AMG Petronas W 1:26.147 -
2 Max Verstappen Red Bull W 1:26.383 +0.236
3 Bottas Mercedes-AMG Petronas W 1:26.431 +0.284
4 Sergio Perez Red Bull W 1:26.538 +0.391
5 Charles Leclerc Ferrari W 1:26.981 +0.834
6 Lando Norris McLaren W 1:27.274 +1.127
7 Daniel Ricciardo McLaren W 1:27.387 +1.240
8 Carlos Sainz Ferrari W 1:27.390 +1.243
9 Pierre Gasly AlphaTauri W 1:27.427 +1.280
10 Fernando Alonso Alpine W 1:27.662 +1.515
11 Yuki Tsunoda AlphaTauri W 1:27.812 +1.665
12 Esteban Ocon Alpine W 1:27.877 +1.730
13 Sebastian Vettel Aston Martin W 1:27.966 +1.819
14 Lance Stroll Aston Martin W 1:28.119 +1.972
15 Kimi Räikkönen Alfa Romeo W 1:28.561 +2.414
16 Antonio Giovinazzi Alfa Romeo W 1:28.632 +2.485
17 Mick Schumacher Haas W 1:28.694 +2.547
18 George Russell Williams W 1:28.981 +2.834
19 Nikita Mazepin Haas W 1:29.388 +3.241
20 Nicholas Latifi Williams W No Time -
1 Lewis Hamilton Mercedes-AMG Petronas W 1:26.147 -
2 Max Verstappen Red Bull W 1:26.383 +0.236
3 Bottas Mercedes-AMG Petronas W 1:26.431 +0.284
4 Sergio Perez Red Bull W 1:26.538 +0.391
5 Charles Leclerc Ferrari W 1:26.981 +0.834
6 Lando Norris McLaren W 1:27.274 +1.127
7 Daniel Ricciardo McLaren W 1:27.387 +1.240
8 Carlos Sainz Ferrari W 1:27.390 +1.243
9 Pierre Gasly AlphaTauri W 1:27.427 +1.280
10 Fernando Alonso Alpine W 1:27.662 +1.515
11 Yuki Tsunoda AlphaTauri W 1:27.812 +1.665
12 Esteban Ocon Alpine W 1:27.877 +1.730
13 Sebastian Vettel Aston Martin W 1:27.966 +1.819
14 Lance Stroll Aston Martin W 1:28.119 +1.972
15 Kimi Räikkönen Alfa Romeo W 1:28.561 +2.414
16 Antonio Giovinazzi Alfa Romeo W 1:28.632 +2.485
17 Mick Schumacher Haas W 1:28.694 +2.547
18 George Russell Williams W 1:28.981 +2.834
19 Nikita Mazepin Haas W 1:29.388 +3.241
20 Nicholas Latifi Williams W No Time -

Zdenko Podobny
May 22, 2022, 1:46:15 PM5/22/22
to tesser...@googlegroups.com
I think you made it too complicated... IMO no (re)training is not needed.
If you are working with images where you know text location you have solved one big problem already.
Working with a limited number of known text strings (players' names, teams' names) gives you other (and IMHO faster) options than OCR. I would use python and pyautogui.locateOnScreen[1]. It will return the position of the text at the screenshot, so you can sort and calculate the position at the race. Of course, you will need OCR of the best time and maybe GAP (which you can use to the check of OCR quality)
Another solution would be:
- Open screenshot as grayscale
- Inver it (so there will be dark letters on white background,
- Threshold image (convert to black and white)
- OCR each "cell" separately
I made a qick test and some times are not recognized correctly (e.g. there is a missing ":" in time for Valtteri BOTTAS, but I think this could be solver in python with post-processing of OCR result + GAP time result. Or maybe better image preprocessing could solve it too, as I see jpg artifact on the thresholded image.
ne 22. 5. 2022 o 19:04 Peter Vallsten <irandig...@gmail.com> napísal(a):
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/aae40372-4656-42f3-987f-6724108dd525n%40googlegroups.com.
{kind=link}
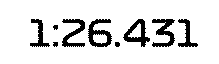{kind=link}
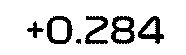{kind=link}
Peter Vallsten
May 22, 2022, 6:01:42 PM5/22/22
to tesseract-ocr
Hi zdenop!
Thanks for your reply! Great to know that it could be done with easier methods, I've never quite worked with python before though!
Thanks for your reply! Great to know that it could be done with easier methods, I've never quite worked with python before though!
So if I understand you correctly you mean that I could create a script that runs "pyautogui.locateOnScreen" for each possible name, team and position and when two y-values match (within a few pixels +/-) I have the position for that player and then create my output based on that?
It would be easier to just have to use OCR on the numbers but I'm not sure though how I would use that previous information to connect the time to each driver.
Do you have any example of the quick test that you ran how you did it?
Any suggestions how I can correctly read the numbers and connecting them to the names?
Any suggestions how I can correctly read the numbers and connecting them to the names?
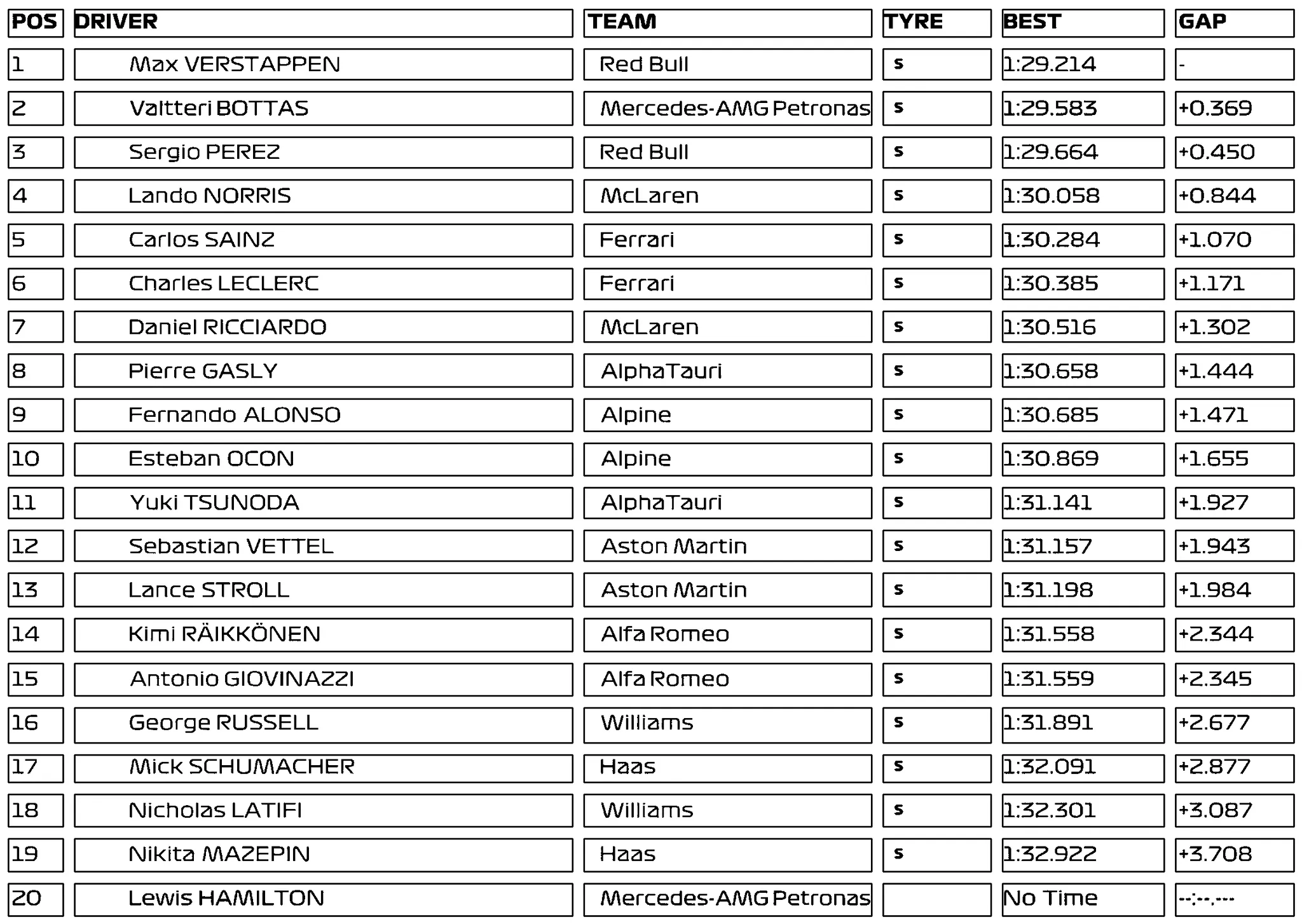
When I'm running OCR with command: 'tesseract C:\f1_grayscale.png test.txt --psm 6' it gives the output:
= hs ~Xi2, =e 3
= ~~ y - Nae
—-ORNUL
1 MONACO GRAND PRIX - SHORT QUALIFYING
a POS. DRIVER TEAM TYRE BEST GAP
Ly Advance
> 1 BK Lewis HAMILTON I Mercedes-AMG Petronas W) 1:26.147 -
Lad
is 2 im Max VERSTAPPEN Red Bull ) 1:26.383 +0.236 Amr
SS WI Race Director = ~
’ t 3 gee ValtteriBOTTAS I Mercedes-AMG Petronas W) 1:26.431 +0.284 es
Pr: ak a = = : --
” —_ : 4 5 Sergio PEREZ Red Bull WN) 1:26.538 +0.391 =——.
= Restart Session « = x 2a
3 fgg Charles LECLERC | Ferrari (w) 1:26.981 +0.834 ES te
c= . NS
Li S 6 IK Lando NorRIS I McLaren Ww) 1:27.274 +1.127 = eee
7 ——n = «67 ~—s) Daniel RICCIARDO I McLaren w) 1:27.387 +1.240 —-
: : — . Tied
_ / oN 8 Em Carlos SAINZ ! Ferrari I) 1:27.390 +1.243 C) i
= a 9 Bl) Pierre GASLY AlphaTauri iC) 1:27.427 +1.280 _ 2
maa — x 4 a
-S 10 [EM Fernando ALONSO I Alpine (w) 1:27.662 +1515 “Gane
4 ais De * Te
A : aa Yuki TSUNODA AlphaTauri w) 1:27.812 +1.665 eS
r wv ft . / 12 |) Esteban OCON I Alpine Ww) 1:27.877 +1.720 ty atone
La Le =
* } a al 153 Ql Sebastian VETTEL ! Aston Martin cD) 1:27.966 +1.819 an. sd
Se Be ae | 14 = Lance STROLL | Aston Martin wi) 1:28.119 +1.972 a f
Det oeee ly ee | LAY at Lae
; * Ves ‘om Sat F Saf = — a _— ee" pe
ea a i = : : = > Sas —
| ey Verstappen... >i Se
| y —, (X)*SELECT
bia Whe. = : por . sa ; 4 .
7 | a | = | < jee )
\ | es : i} es 8 | —— ee ema Rey
= ~~ y - Nae
—-ORNUL
1 MONACO GRAND PRIX - SHORT QUALIFYING
a POS. DRIVER TEAM TYRE BEST GAP
Ly Advance
> 1 BK Lewis HAMILTON I Mercedes-AMG Petronas W) 1:26.147 -
Lad
is 2 im Max VERSTAPPEN Red Bull ) 1:26.383 +0.236 Amr
SS WI Race Director = ~
’ t 3 gee ValtteriBOTTAS I Mercedes-AMG Petronas W) 1:26.431 +0.284 es
Pr: ak a = = : --
” —_ : 4 5 Sergio PEREZ Red Bull WN) 1:26.538 +0.391 =——.
= Restart Session « = x 2a
3 fgg Charles LECLERC | Ferrari (w) 1:26.981 +0.834 ES te
c= . NS
Li S 6 IK Lando NorRIS I McLaren Ww) 1:27.274 +1.127 = eee
7 ——n = «67 ~—s) Daniel RICCIARDO I McLaren w) 1:27.387 +1.240 —-
: : — . Tied
_ / oN 8 Em Carlos SAINZ ! Ferrari I) 1:27.390 +1.243 C) i
= a 9 Bl) Pierre GASLY AlphaTauri iC) 1:27.427 +1.280 _ 2
maa — x 4 a
-S 10 [EM Fernando ALONSO I Alpine (w) 1:27.662 +1515 “Gane
4 ais De * Te
A : aa Yuki TSUNODA AlphaTauri w) 1:27.812 +1.665 eS
r wv ft . / 12 |) Esteban OCON I Alpine Ww) 1:27.877 +1.720 ty atone
La Le =
* } a al 153 Ql Sebastian VETTEL ! Aston Martin cD) 1:27.966 +1.819 an. sd
Se Be ae | 14 = Lance STROLL | Aston Martin wi) 1:28.119 +1.972 a f
Det oeee ly ee | LAY at Lae
; * Ves ‘om Sat F Saf = — a _— ee" pe
ea a i = : : = > Sas —
| ey Verstappen... >i Se
| y —, (X)*SELECT
bia Whe. = : por . sa ; 4 .
7 | a | = | < jee )
\ | es : i} es 8 | —— ee ema Rey
Zdenko Podobny
May 23, 2022, 2:05:37 AM5/23/22
to tesser...@googlegroups.com
So if I understand you correctly you mean that I could create a script that runs "pyautogui.locateOnScreen" for each possible name, team and position and when two y-values match (within a few pixels +/-) I have the position for that player and then create my output based on that?
Yes. Learning pyautogui is a good investment. It can help you to automate a lot of repetitive GUI tasks... even playing games ;-) [1] (But be careful using bots in games is usually forbidden :-| )
When I'm running OCR with command: 'tesseract C:\f1_grayscale.png test.txt --psm 6' it gives the output:
This is totally useless. Did you read documentation[2]? You have to remove all graphics elements, usually also jpg artefacts...
And because your text has a table structure you need to make a layout analysis (on input image) by yourself.
Zdenko
po 23. 5. 2022 o 0:01 Peter Vallsten <irandig...@gmail.com> napísal(a):
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/9102ec05-dbe4-4868-9ae6-ff8d0d4314f6n%40googlegroups.com.
Peter Vallsten
May 26, 2022, 6:45:24 PM5/26/22
to tesseract-ocr
Thank you for your tips!
I'm getting there, successfully located each cell of data in code and hopefully improving readability.
Next step will be to scan each cell of data.
Python is powerful, learning alot!
{kind=link}
Reply all
Reply to author
Forward
0 new messages