Tesseract confused between a character and a digit which look-alike

Yash Mistry
I am facing challenge to extract correct a letter from a word which are look-alike, i.e 5 & S, I & 1, 8 & S.
I applied image pre-processing techniques like Blurring, erode, dilate, normalised the noise, remove unnecessary component and text detection from the input image but after these much of pre-processing tesseract OCR isn't giving correct result.
Please check attached images,
Original Image

Pre-processed Image
.png?part=0.2&view=1)
Detected Text
.png?part=0.4&view=1)
.png?part=0.1&view=1)
Tesseract Configuration
-l eng --oem 1 --psm 7 -c tessedit_char_whitelist="ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789\n" load_system_dawg=false load_freq_dawg=false
Result of OCR: TITLENUMBER 81003716
As we can see OCR extract S as 8 even after pre-processing and text detection.
Is there anyway we can overcome this problem?
Tesseract Version: tesseract 5.1.0-32-gf36c0
Note: Asked same question in pytesseract github repo and got suggestion to drop this question here.

Lorenzo Bolzani
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/72dac625-d07f-4240-9032-3fa856868b8dn%40googlegroups.com.
Yash Mistry
Lorenzo Bolzani
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/c46185ed-b502-4320-bf98-966a6b2e90een%40googlegroups.com.
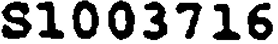{kind=link}
{kind=link}