STS benchmark

eneko
Dear participant,
we are glad to launch STS benchmark. STS Benchmark comprises a selection
of the English datasets used in the STS tasks organized by us in the
context of SemEval between 2012 and 2017.
In order to provide a standard benchmark to compare among systems, we
organized it into train, development and test. The development part can
be used to develop and tune hyperparameters of the systems, and the test
part should be only used once for the final system.
Please find all details in http://ixa.si.ehu.eus/stswiki/STSbenchmark
We think that this benchmark can be used in the future for setting the
state-of-the-art in Semantic Textual Similarity for English.
We would like to gather the results of the best participants in 2017, so
we can gather a leaderboard in
http://ixa.si.ehu.eus/stswiki/STSbenchmark. We would also like to
include a section in the task description paper. Those interested,
please train one of your runs using just the train dataset provided, and
send us your development and test results by the end of March,
mentioning the CodaLab run ID.
best
eneko
--
Eneko Agirre
Euskal Herriko Unibertsitatea
University of the Basque Country
http://ixa2.si.ehu.eus/eneko

Basma Hassan
It is great to know that STS benchmark is launched and I am interested in running my system on it. But unfortunately, the link you sent is not successfully opened. I got the page in this screenshot
Basma
Basma Hassan Kamal,
Assistant Lecturer,
Computer Science Department,
Faculty of Computers and Information,
Fayoum University, Egypt
--
--
Website of task, http://alt.qcri.org/semeval2017/task1/
To post to this group, send email to sts-s...@googlegroups.com
To unsubscribe, send email to sts-semeval+unsubscribe@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
--- You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
eneko
sorry about that, the correct url: http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark
To unsubscribe, send email to sts-semeval...@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
---
You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

w0927...@gmail.com
| run ID | Model | Dev | Test |
| 386608 | RF | 0.8333 | 0.7993 |
| 386610 | GB | 0.8356 | 0.8022 |
| 386611 | EN-seven | 0.8466 | 0.8100 |
To unsubscribe, send email to sts-semeval...@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
--- You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
--
Website of task, http://alt.qcri.org/semeval2017/task1/
To post to this group, send email to sts-s...@googlegroups.com
To unsubscribe, send email to sts-semeval...@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
---
You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Eneko Agirre
Hi Junfeng,
thanks for sending your results, I already added them to http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark
Just to double check, please confirm whether your system was trained on the train data in STSbenchmark, or whether you used additional training data.best
eneko
w0927...@gmail.com

sndr....@gmail.com
eneko
http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark
--
--
Website of task, http://alt.qcri.org/semeval2017/task1/
To post to this group, send email to sts-s...@googlegroups.com
To unsubscribe, send email to sts-semeval...@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
---
You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Ergun Bicici
To unsubscribe, send email to sts-semeval+unsubscribe@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
---
You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
-- Eneko Agirre Euskal Herriko Unibertsitatea University of the Basque Country http://ixa2.si.ehu.eus/eneko
--
--
Website of task, http://alt.qcri.org/semeval2017/task1/
To post to this group, send email to sts-s...@googlegroups.com
To unsubscribe, send email to sts-semeval+unsubscribe@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
---
You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval+unsubscribe@googlegroups.com.
Ergun Bicici
| dataset | OnWN | FNWN | headlines | images | tweet-news | deft-news | deft-forum | MSRpar | MSRvid | SMT | SMTeuroparl | SMTnews | belief | answers-students | answers-forums | Total | ||
| trial2012 | ||||||||||||||||||
| train2012 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 750 | 750 | 0 | 734 | 0 | 0 | 0 | 0 | 2234 | ||
| test2012 | 750 | 0 | 0 | 0 | 0 | 0 | 0 | 750 | 750 | 0 | 459 | 399 | 0 | 0 | 0 | 3108 | ||
| trial2013 | 5 | 5 | 5 | 5 | 20 | |||||||||||||
| test2013 | 561 | 189 | 750 | 0 | 0 | 0 | 0 | 0 | 0 | 750 | 0 | 0 | 0 | 0 | 0 | 2250 | ||
| trial2014 | 5 | 0 | 5 | 5 | 5 | 5 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 30 | ||
| test2014 | 750 | 0 | 750 | 750 | 750 | 300 | 450 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3750 | ||
| Total: | 2071 | 194 | 1510 | 755 | 755 | 305 | 455 | 1500 | 1500 | 755 | 1193 | 399 | 0 | 0 | 0 | 11392 | ||
| trial2015 | 0 | 0 | 5 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 25 | 25 | 70 | ||
| test2015 | 750 | 750 | 375 | 750 | 375 | 3000 | ||||||||||||
| Total: | 2071 | 194 | 2265 | 1510 | 755 | 305 | 455 | 1500 | 1500 | 755 | 1193 | 399 | 385 | 775 | 400 | 14462 | ||
| 100 more | ||||||||||||||||||
| dataset | post-editing | plagiarism | answer-answer | que.-que. | 0 | |||||||||||||
| test2016 | 249 | 244 | 230 | 254 | 209 | 1186 | ||||||||||||
| Total: | 2071 | 194 | 2514 | 1510 | 999 | 305 | 455 | 1500 | 1500 | 755 | 1423 | 399 | 385 | 1029 | 609 | 15648 | ||
| track5.en-en test set | ||||||||||||||||||
| 10 | 5 | 15 | 10 | 5 | 5 | 5 | 0 | 0 | 100 | 0 | 10 | 25 | 250 | |||||
| 14278 | 15648 | -755 | -775 | -90 | 250 |
2012 trial dataset scoring appears sorted and the true scores appear missing:
http://ixa2.si.ehu.es/stswiki/images/d/d3/STS2012-en-trial.zip
For instance, the first sentence can get a 5 but it is scored 0:
The bird is bathing in the sink. Birdie is washing itself in the water basin.
Eneko Agirre
Dear Ergun,
thanks for your questions.
We separated the datasets released in past Semeval STS campaigns
into the STS benchmark and the Companion dataset.
The STS benchmarks focuses on image captions, news headlines and
user forums, in order to reduce the variability of genres, and
provide a standard benchmark to compare among meaning
representation systems in future years. We would love to see
competing meaning representation proposals (e.g. Arora et al.
2017; Mu et al. 2017; Wieting et al. 2016) being evaluated on STS
benchmark, alongside the results of Semeval participants.
best
eneko
To unsubscribe, send email to sts-semeval...@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
---
You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Eneko Agirre
Euskal Herriko Unibertsitatea

Tsuki
To unsubscribe, send email to sts-semeval...@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
---
You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
-- Eneko Agirre Euskal Herriko Unibertsitatea University of the Basque Country http://ixa2.si.ehu.eus/eneko
--
--
Website of task, http://alt.qcri.org/semeval2017/task1/
To post to this group, send email to sts-s...@googlegroups.com
To unsubscribe, send email to sts-semeval...@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
---
You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
--
Website of task, http://alt.qcri.org/semeval2017/task1/
To post to this group, send email to sts-s...@googlegroups.com
To unsubscribe, send email to sts-semeval...@googlegroups.com
For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
---
You received this message because you are subscribed to the Google Groups "STS SemEval" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sts-semeval...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Eneko Agirre
Dear Tsuki,
thnaks for your comment.
it is totally OK to use vector representations learned from
external corpora. We now realize that the wording was confusing,
so we will try to be more clear on that.
We welcome any other suggestions which would make the STS
benchmark more useful for the community.
best
eneko

nabin maharjan
Eneko Agirre
thanks again!
I would be grateful if you could you please check
http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark#Results and Section
6 of the attached pdf, and ensure that evetything said with respect to
your system is correct.
Any comments welcome!
best
eneko
03/23/2017 10:10 PM(e)an, nabin maharjan igorleak idatzi zuen:
> please train one of your runs using just the train dataset
> provided, and
> send us your development and test results by the end of March,
> mentioning the CodaLab run ID.
>
> best
>
> eneko
>
>
> --
>
> Eneko Agirre
> Euskal Herriko Unibertsitatea
> University of the Basque Country
> http://ixa2.si.ehu.eus/eneko
>
> --
> Website of task, http://alt.qcri.org/semeval2017/task1/
> To post to this group, send email to sts-s...@googlegroups.com
> To unsubscribe, send email to sts-semeval...@googlegroups.com
> For more options, http://groups.google.com/group/sts-semeval?hl=en?hl=en
> ---
> You received this message because you are subscribed to the Google
> Groups "STS SemEval" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to sts-semeval...@googlegroups.com
Eneko Agirre
Euskal Herriko Unibertsitatea
Eneko Agirre
sorry for the previous mail, it was intended for a specific participant,
please ignore.
best
eneko
04/06/2017 04:19 PM(e)an, Eneko Agirre igorleak idatzi zuen:
Ergun Bicici

top r in STS 2016 = 0.7781 (Samsung Poland NLP Team)
top RTM r in STS 2016 = 0.6746 (unofficial results [4])
top r in STS 2014 = 0.7610 (DLS@CU-run2)
top RTM r in STS 2013 = 0.58 (unofficial results, [1])


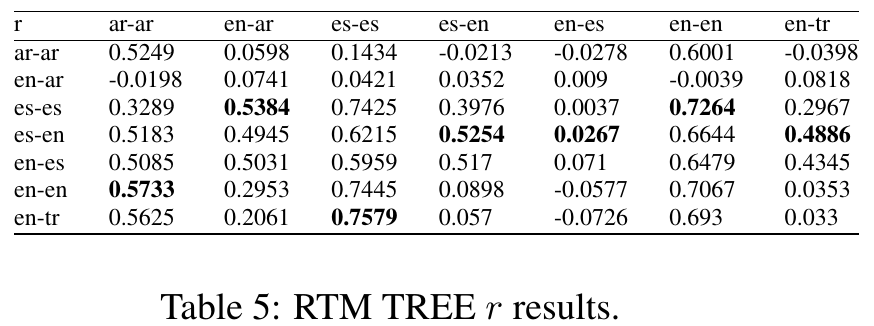
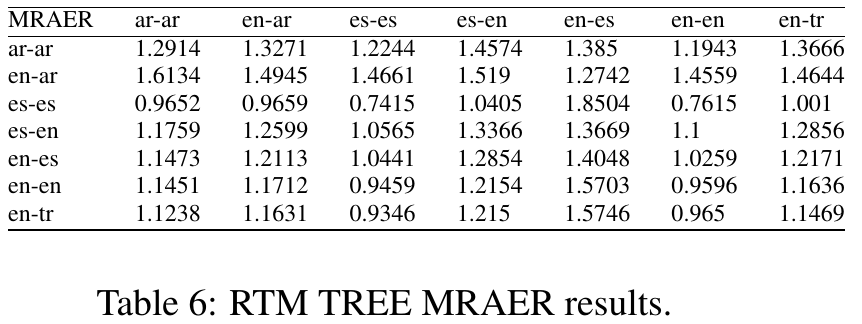
http://aclanthology.info/papers/semeval-2016-task-1-semantic-textual-similarity-monolingual-and-cross-lingual-evaluation

Universidad del Pais Vasco
University of the Basque Country
http://ixa2.si.ehu.eus/eneko
--
Ergun Bicici