Multiple observations in lexical diversity research
69 views
Skip to first unread message

ekbrown77
Oct 27, 2021, 7:04:17 PM10/27/21
to StatForLing with R
A methodological question rather than a coding question here:
We see three options and would like your opinion on which is best:
Option 1
Retain our mixed-effect linear regression with student as a random effect.
Option 2
Fit a separate regression for each semester and analyze general trends across the semesters.
Option 3
Only use the most recent response from each student. (This seems silly to remove data points.)
Is there a sound reason to not use a mixed-effect linear regression with student as a random effect in this situation?
Thank you much!

Stefan Th. Gries
Oct 27, 2021, 7:07:39 PM10/27/21
to StatForLing with R
It would help us to see the exact model formula you were using when
you got this result ("A vast majority of the variance is explained by
you got this result ("A vast majority of the variance is explained by
the individual students themselves and little variance is explained by
the lexical diversity measures").
ekbrown77
Oct 28, 2021, 8:51:56 PM10/28/21
to StatForLing with R
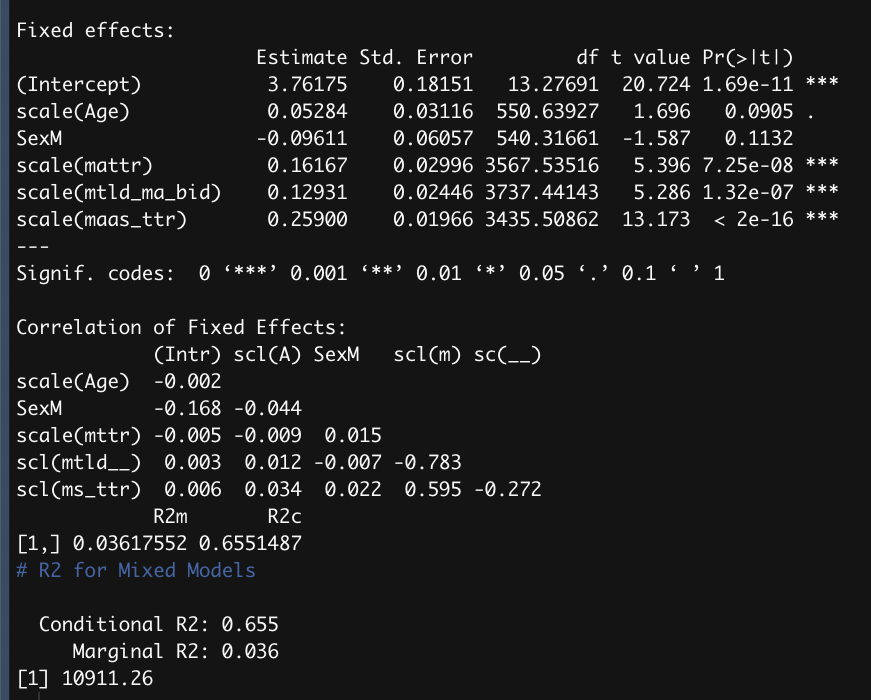
The random effect "id" is speaker. Its variance is relatively high (0.641) and the conditional R2 is relatively high (0.655), but the marginal R2 is low (0.036). As I understand it (from here), conditional R2 measures the variance of both the random effects and fixed effects, while the marginal R2 only measures the variance of the fixed effects, in this case three lexical diversity measures and two sociodemographic variables.

Stefan Th. Gries
Oct 29, 2021, 1:45:44 PM10/29/21
to StatForLing with R
Some thoughts based on what I understand meaning it might be all wrong, you'll see ... (and this is one of those questions where, without doing one's own full exploration and analysis, it's hard to make firm recommendations).
- you have 4206 observations but also 861 speakers so there aren't many observations per speaker (on average at least);
- from how I understand this (recall caveat from above), your main predictors of interest are the LexDiv variables but actually also SemYear (?). Aren't you trying to find out how the writing proficiency goes up (as measured by the LexDivs) and over time (as measured by SemYear)? If the answer to that question is yes, then
-- wouldn't SemYear need to be a fixef predictor, not a ranef?
-- wouldn't you need random slopes for all 4 predictors of interest (to rule out anticonservative effects)?
Generally, tho, I don't see how you can ignore student as some kind of ranef source (which is what your main question was, so I think you need some version of option 1) and, you didn't ask about that but I'll say it anyway because it might explain the low R^2^~marg~, the relation between your LexDiv predictors and FairAverage may be stronger than you so far think, but curvilinear.
Just my $0.02, like I said, very hard to say in the abstract ...
ekbrown77
Nov 1, 2021, 1:57:11 PM11/1/21
to StatForLing with R
Thank you much!
Reply all
Reply to author
Forward
0 new messages