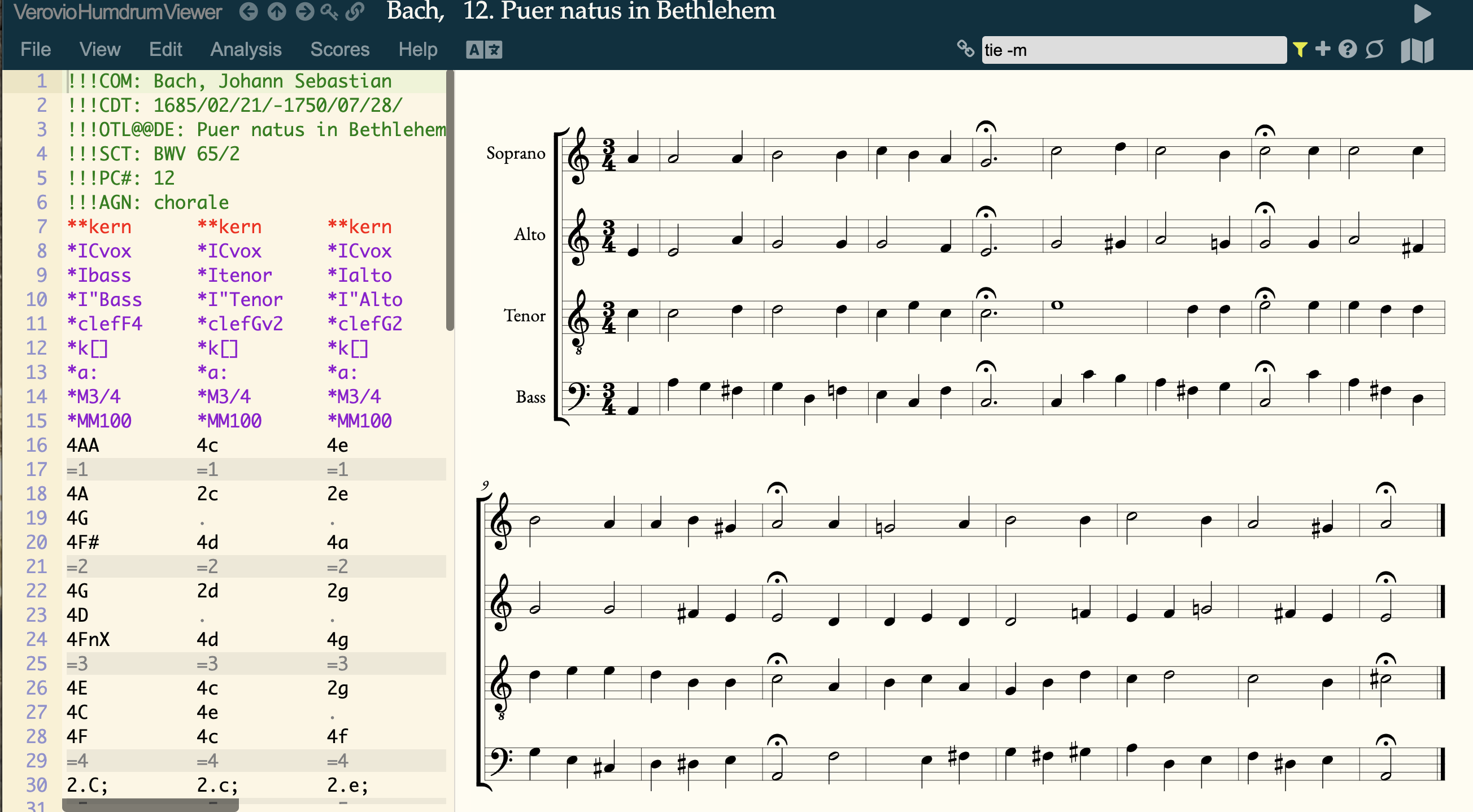
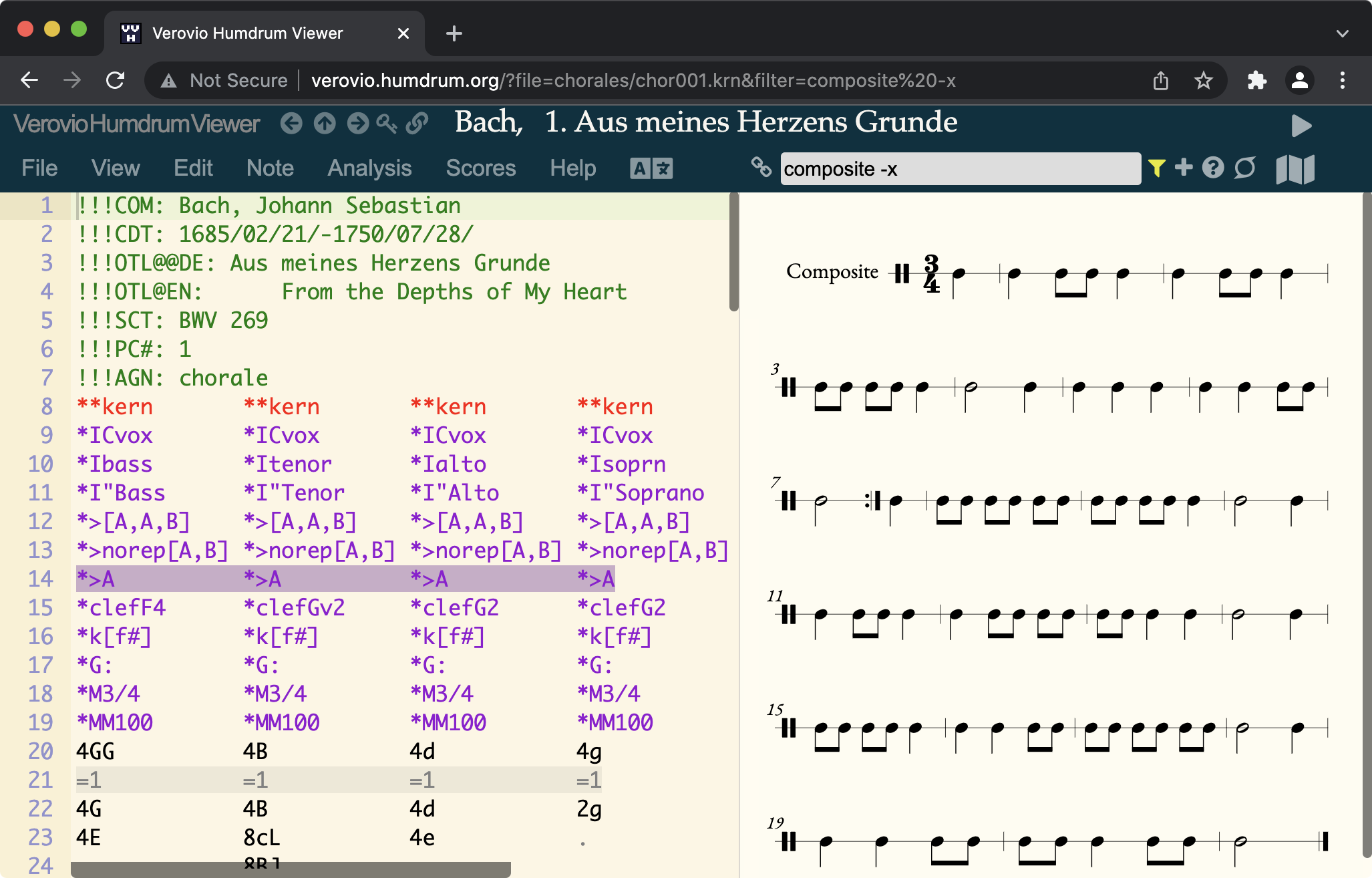
simple way of counting the aggregate rhythm of tied notes?

Claire Arthur

Huron, David
Sent: Friday, March 4, 2022 12:43 PM
To: starstarhug <stars...@googlegroups.com>
Subject: [**HUG] simple way of counting the aggregate rhythm of tied notes?
--
This is a message is from the **HUG newgroup.
To post to this group, send email to stars...@googlegroups.com
To unsubscribe from this group, send email to
starstarhug...@googlegroups.com
For more options, visit this group at
http://groups.google.com/group/starstarhug?hl=en
---
You received this message because you are subscribed to the Google Groups "starstarhug" group.
To unsubscribe from this group and stop receiving emails from it, send an email to starstarhug...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/starstarhug/3f612738-14c1-42a2-aa0f-3161650e7f78n%40googlegroups.com.
Claire Arthur

Craig Sapp
43648 1
29395 0.5
5385 2
2170 0.25
1253 3
1000 1.5
740 1R
655 1.5T
372 1T
250 2T
243 4
111 0.75
53 2.5T
38 3T
22 2R
16 1.75T
15 0.5R
10 0.125
9 6T
9 1.25T
8 8
8 6
8 5T
6 4T
5 3R
5 3.5T
3 0.75T
2 8T
2 2.75T
1 4R
1 2.25T
1 16T
1 4.5T
1 3.75T
1 7T
1 9T
1 14T
45.64 1.5T
25.92 1T
17.42 2T
3.69 2.5T
2.65 3T
1.11 1.75T
0.63 6T
0.63 1.25T
0.56 5T
0.42 4T
0.35 3.5T
0.21 0.75T
0.14 2.75T
0.14 8T
0.07 3.75T
0.07 14T
0.07 7T
0.07 16T
0.07 2.25T
0.07 9T
0.07 4.5T
44020 1
29395 0.5
5635 2
2170 0.25
1655 1.5
1291 3
249 4
114 0.75
53 2.5
17 6
16 1.75
10 0.125
10 8
9 1.25
8 5
5 3.5
2 2.75
1 16
1 3.75
1 7
1 2.25
1 14
1 9
1 4.5
44020 1
29395 0.5
5635 2
2170 0.25
1655 1.5
1291 3
740 1R
249 4
114 0.75
53 2.5
22 2R
17 6
16 1.75
15 0.5R
10 0.125
10 8
9 1.25
8 5
5 3R
5 3.5
2 2.75
1 14
1 9
1 2.25
1 4R
1 16
1 4.5
1 3.75
1 7
39.11 0.25
28.58 0.5
10.13 1
7.16 0.125
4.61 0.166667
3.02 0.333333
1.81 0
1.47 1.5
1.29 2
1.08 0.75
0.39 0.0625
0.35 3
0.31 0.375
0.12 1.25
0.12 0.0833333
0.12 4
0.05 0.625
0.05 2.5
0.03 0.03125
0.03 1.75
0.02 6
0.02 0.666667
0.02 0.875
0.02 3.5
0.02 2.25
0.01 1.33333
0.01 0.1875
0.01 0.0714286
0.01 5
0.01 1.125
0 0.6875
0 1.375
0 0.3125
0 0.5625
0 4.5
0 3.25
0 1.6875
0 2.75
0 0.571429
0 7
0 1.16667
0 16
0 5.25
0 4.75
0 0.0416667
0 0.583333
0 1.0625
--
Craig Sapp
69.01 0.5
19.34 1
7.06 0.25
2.77 2
0.93 3
0.59 1R
0.18 4
0.04 1.5
0.03 0.125
0.02 0.75
0.01 2R
0.01 8
0.01 6

--