Partial Observability of Loaded Coin, strong definition needed

Morgaine
"So the Loaded Coin example is clearly Partially Observable, and the reason is, it is actually useful to have memory. If you flip it more than one time, so you can learn more about what the actual probability is. Therefore looking at the most recent coin flip is insufficient to make your choice."
This is a good explanation, but it still leaves questions because I'm not sure if the explanation is actually a definition. My best shot inferred from the explanation above is that the definition of Partial Observability is:
- An environment is defined as being Partially Observable if using memory of past percepts can improve the agent's knowledge of that environment.
Is this correct, in all circumstances and not just in Loaded Coin?
If that is the formal definition of Partial Observability in this course, great, it becomes axiomatic. However, it still doesn't really help us understand what element of the environment is actually hidden. Is it a state that is hidden? Is the loading of the coin considered a hidden element of the environment, or is the loading a component of the stochastic action function? Perhaps it's just a matter of definition again, so let's try this one for size:
- Every Stochastic problem is defined as having a Partially Observable environment, because the randomness of actions or percepts is considered the result of a hidden element in that environment.
Is this correct?
If not, then we need stronger definitions if we are to really learn the meaning of P.O., rather than just debate semi-convincingly.
Morgaine.

Steven Powell
Make sense?
--
You received this message because you are subscribed to the Google Groups "Stanford AI Class" group.
To post to this group, send email to stanford...@googlegroups.com.
To unsubscribe from this group, send email to stanford-ai-cl...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/stanford-ai-class?hl=en.

Tim McNamara
observable results are those where memory could lead to judging a
correct answer.
On the basis of this, I got this wrong for two questions:
For the coin toss, each throw is independent from the next => no.
For the maze, each move requires knowledge about previous moves => yes.

Emre Mater
mislead you but I lead the solution by thinking as follows:
Thinking that the system is "Stochastic" (i.e. randomness is involved)
I would say it is not possible to determine or observe the environment
completely. for that reason you could say a system is partially
observable..
And the question is are there fully observable stochastic environments
exist?
On Oct 18, 9:54 pm, Tim McNamara <paperl...@timmcnamara.co.nz> wrote:
> To be honest, I was left with the impression that a partially
> observable results are those where memory could lead to judging a
> correct answer.
>
> On the basis of this, I got this wrong for two questions:
>
> For the coin toss, each throw is independent from the next => no.
> For the maze, each move requires knowledge about previous moves => yes.
>
Morgaine
Your question "[do] fully observable stochastic environments exist?" would determine whether I was correct to propose that "Every Stochastic problem is defined as having a Partially Observable environment". I don't actually know.
Will we ever find out in any authoritative way, that's the problem.
Morgaine.
==================

Fernanda Montiel
Yes. You can have a random (stochastic) num from 0 to 10. Even if is
infinite, you know that NEVER it's going to be 20, or -1.
Fully observable means you can know the whole context. Stochastic means you
don't have a pattern, it's more like "a chance", even if you have or don't a
context.

Davy Meers

Jodi Schneider
<pape...@timmcnamara.co.nz> wrote:
> For the coin toss, each throw is independent from the next => no.
You get more info from each coin throw.
> For the maze, each move requires knowledge about previous moves => yes.
It doesn't:
"Your controls are move forward to the next wall or intersection, turn
left 90 degrees, and turn right 90 degrees." -- so there is no
backtracking possible. The worst someone could do would be to turn
e.g. right after you had just turned left. But after the first move
there's no harm done. No?
-Jodi

David Weiseth
Morgaine
Neither of them has any hidden state in the environment that the other doesn't have. They're both driven by dice and no other element in the environment.
Morgaine.
=======================
David Weiseth
Davy Meers
Morgaine
Exactly as you wrote, "if it's your turn (ie. always in this case) you know which fields there are (there are no fields in this case), the position off all the pieces (you know the position of all the peices, of which there are zero) and the number of fields that can be moved (which is zero). There is no need to remember any previous turns. (And the agent does not need to remember any previous turns to flip the next one in Loaded Coin either.)
The only purpose of the memory in Loaded Coin is so that the agent can provide the requested answer as a probability by combining successive percepts. It's purely an output function, and is not used to improve the choice of actions whatsoever. It's completely like Backgammon, albeit with a nearly empty environment.
Morgaine.
=====================
David Weiseth
David Weiseth
Morgaine
One is an AI process as was described to us at the very beginning by Prof Thrun: a process involving an agent, an environment, sensors+percepts, and actuators+actions, plus the function drawn by the Prof as a red line called "Control Policy for the Agent". The memory and computation of probability is not part of that process in Loaded Coin at all, because it is not used in that cyclic process.
Computing the probability does not impact on the agent's flipping of the coin whatsoever. It is entirely separate from the task performed by the Intelligent Agent, not a part of the cyclic model that was described to us.
Instead, the memory and computation of the probability is a completely separate output process, performed only because the agent was requested to provide the output in that form.
As a somewhat silly yet still appropriate example, if the agent were given a task of ringing a bell each time that a percept came in, that would not be part of the model either. It's a separate output process.
I'm beginning to think that Loaded Coin was a dreadful choice of example for Homework. It introduced a situation that was not covered in the videos, and muddles the waters with a process that is not part of the agent's control loop.
Morgaine.
=======================

Mark Rampton
Morgaine
It's a jolly funny way to run a "Stanford level" course.
But to get back to the topic, it must be possible to define where the Intelligent Agent ends and other software starts. If the Intelligent Agent of Loaded Coin is running under an operating system, which connects to Google, which connects to NASA, which connects to the Voyager probes that are currently leaving the Solar System, does our Intelligent Agent extend all the way to beyond Pluto? No of course it doesn't. It has a boundary, and that boundary was described by Prof Thrun's control loop. The generation of a probability lies outside of that control loop because it is not used in the control loop.
It was a really bad example. He should have chosen something else.
Morgaine.
==================
Mark Rampton
David Weiseth
Morgaine
You can't just randomly say that something is part of the Intelligent Agent when it falls outside of the formally defined model that we have been given. This is a Stanford course, not some random 2-bit amateurish outfit where anything goes. We've been given a formal model and we have to adhere to it.
This particular case is no different to the joke example I gave earlier, about the "task" being to ring a bell when the percept is received. Despite the fact that the code would probably process the "ring bell" operation inline with receiving the percept, such a program operation could not be considered part of the Intelligent Agent because the Intelligent Agent model has no place for additional actuators that are not its environment actuators nor for code that is not part of its control loop. *Real* programs of course will have room for such things, but the theoretical model does not, and it is the model that determines properties such as P.O..
Anyway, I'm getting tired of this so I'll say no more. If people want to be sloppy about definitions, so be it. But I expected precision. Lack of that precision has led to this incredible outpouring of uncertainty on the many Internet forums about what we are meant to be learning and understanding.
Morgaine.
===========================
Davy Meers
David Weiseth

Stuart Gale

Manoel Brasileiro
probability (aka Stochasticity or Randomness) is NOT PART OF THE
CONTROL LOOP". It´s part of the environment and cannot be accessed
directly by the Agent, which only can 'sense' (ie, using its sensors)
its effects (the coin face after a toss). It isn't also required for
the Agent to act over the environment: the agent only 'senses' the
environment and provides an output that doesn't affect such
environment (like the actuator being just a display).
But the Agent can't provide such an output (a useful one) using just a
current snapshot of this environment. It must take many measurements
and record their results in order to carry out its duty: to decide if
the coin is loaded or not and with which probability. Thus the
environment is partially observable to the Agent who can't see (sense)
the previous flips and must record itself such past measurements.
>
> >> I based my answers (and my reply to this thread) from what I read in the
> >> book. I know they said the book is optional for this class -- but I don't
> >> really agree with that. The material in the book def. sheds light on this
> >> problem.
>
>
> >>> If we're mixing up our cases, it's because the videos did such a poor job
> >>> of explaining the topic. It was never defined with any kind of precision
> >>> exactly what is hidden in an environment that is Partially Observable, and
> >>> so we don't know. Everyone is just putting their own interpretation on it,
> >>> including both you and I, because it was never properly defined for us by
> >>> the Profs.
>
> >>> It's a jolly funny way to run a "Stanford level" course.
>
> >>> But to get back to the topic, it must be possible to define where the
> >>> Intelligent Agent ends and other software starts. If the Intelligent Agent
> >>> of Loaded Coin is running under an operating system, which connects to
> >>> Google, which connects to NASA, which connects to the Voyager probes that
> >>> are currently leaving the Solar System, does our Intelligent Agent extend
> >>> all the way to beyond Pluto? No of course it doesn't. It has a boundary,
> >>> and that boundary was described by Prof Thrun's control loop. The
> >>> generation of a probability lies outside of that control loop because it is
> >>> not used in the control loop.
>
> >>> It was a really bad example. He should have chosen something else.
>
> >>> Morgaine.
>
> >>> ==================
>
>
> >>>>>>>> No, backgammon and the loaded coin problem are different:
>
> >>>>>>>> Backgammon is fully observable because if it's your turn you know
> >>>>>>>> which fields there are, the position off all the pieces and the
> >>>>>>>> number of fields that can be moved. There is no need to remember any
> >>>>>>>> previous turns.
>
> >>>>>>>> The problem of the loaded coin is different:
> >>>>>>>> They might have adapted the coin so that instead of a 50/50
>
>
> plus de détails »
Tim McNamara
completely. Thanks.
Davy Meers

Gustavo Cardial
An environment is fully observable if, at any time, the data agent's
sensors can sense is completely sufficient for it to make the optimal
decision.
Otherwise, it's partially observable.
If we suppose the only action the agent can perform is "determine the
probability", I think that's obvious that it makes the environment
fully observable. After all, the agent can't optimally determine the
probability just looking at the result from the last coin flip. The
agent has to analyze every flip. It needs memory. Partially
observable.
BUT what if the agent has 2 possible actions:
1 - Flip the coin
2 - Determine probability
To determine the probability it'll need memory anyway, just like
explained before. That would make the environment partially
observable.
But the agent can always flip the coin, and for that it doesn't need
memory. Fully observable, then?
But to flip the coin is an optimal decision? If it is, it implies that
the agent can always keep with this action. After all, when the coin
is flipped there is no other change in the state indicating the agent
should change from action 1 (flip the coin) to action 2 (determine
probability).
Turns out that to just flip the coin is not an optimal decision. The
agent is supposed to SOLVE THE PROBLEM. The problem is "to determine
the probability".
I think that this two reasons refute Morgaine's need for a stronger
definition. 1 being that keep infinitely flipping a coin is not an
optimal decision (won't solve the problem) and 2 being that to solve
the problem we will always, in the end, need memory.
>
> >> The Loaded Coin doesn't seem to be any different at all in the ways you
> >> describe.
>
> >> Exactly as you wrote, "if it's your turn (ie. always in this case) you
> >> know which fields there are (there are no fields in this case), the position
> >> off all the pieces (you know the position of all the peices, of which there
> >> are zero) and the number of fields that can be moved (which is zero). There
> >> is no need to remember any previous turns. (And the agent does not need to
> >> remember any previous turns to flip the next one in Loaded Coin either.)
>
> >> The only purpose of the memory in Loaded Coin is so that the agent can
> >> provide the requested answer as a probability by combining successive
> >> percepts. It's purely an output function, and is not used to improve the
> >> choice of actions whatsoever. It's completely like Backgammon, albeit with
> >> a nearly empty environment.
>
> >> Morgaine.
>
> >> =====================
>
>
> >>> No, backgammon and the loaded coin problem are different:
>
> >>> Backgammon is fully observable because if it's your turn you know which
> >>> fields there are, the position off all the pieces and the number of
> >>> fields that can be moved. There is no need to remember any previous turns.
>
> >>> The problem of the loaded coin is different:
> >>> They might have adapted the coin so that instead of a 50/50 change there
> >>> is another probability of getting heads or tails.
>
> >>> From the video: "your task will be to understand from coin
> >>> flips, whether a coin is loaded, and if so, at what probability."
>
> >>> You cannot determine this from 1 coin flip.
> >>> In order to do this you need to track the past coin flips too.
> >>> That's why the loaded coin is partially observable.
>
>
> >>> 2011/10/19 Morgaine <morgaine.din...@googlemail.com>
> >>>> If Backgammon is Stochastic but Fully Observable, then so is Loaded
> >>>> Coin. That would mean that the official answer is incorrect.
>
> >>>> Neither of them has any hidden state in the environment that the other
> >>>> doesn't have. They're both driven by dice and no other element in the
> >>>> environment.
>
> >>>> Morgaine.
>
> >>>> =======================
>
>
> >>>>> Fully observable stochastic environments do exist.
> >>>>> Think of the game backgammon:
>
> >>>>> it is fully observable: everything that is needed to make the optimal
> >>>>> decision is known every single turn. (There is no need to remember the
> >>>>> past moves)
> >>>>> It is stochastic: dices determine the number of fields that can be
> >>>>> moved in a turn.
>
> >>>>>> Yes. You can have a random (stochastic) num from 0 to 10. Even if is
> >>>>>> infinite, you know that NEVER it's going to be 20, or -1.
>
> >>>>>> Fully observable means you can know the whole context. Stochastic
> >>>>>> means you
> >>>>>> don't have a pattern, it's more like "a chance", even if you have or
> >>>>>> don't a
> >>>>>> context.
>
>
> mais »
Gustavo Cardial
>
> mais »
Morgaine
There is a reason to have formal models in subjects like AI. It's so that we can make clear analyses of a model without including factors outside our model that would complicate the analysis. And should we find our simple model inadequate then we first have to formally extend it, and then analyze this new improved version. This is exactly what Prof Norvig did repeatedly as he defined progressively more complex versions of the remove_choice() and add_path() functions. That is well-structured systematic refinement of models and analysis.
In contrast, all the explanations of Loaded Coin suggested here have added pieces outside of the formal model which defines the Intelligent Agent. Sure, the suggestions may be reasonable (in fact they ARE), but the trouble is that they do not form part of the formal model in which the agent performs computations in what has officially been called the "Control Policy for the Agent" (the red arrow). They do not form part of it because these computations in the formal model have the function of generating a rational decision for the agent when choosing actions to perform through its actuators based on the percepts received. Any computations that do not have this purpose must lie outside of the agent model as current defined, even if they are otherwise fully reasonable.
It's a matter of well-formed analysis. If I wrote a program to solve this simple problem then I would do exactly what so many have suggested here. But I cannot do that in the formal analysis, because the suggestions lie outside of the agent model that we have been given. There is no agent model currently defined that includes computations which do not have an effect on the control loop of the agent. I wish there was, but there isn't, at least at the time of Homework 1.
By the way, I'd like to point out that this discussion about formal agent models, while very interesting, has not really helped answer the two questions in my initial post. We still don't know the answer to either, as precise definitions have not been given by the Profs.
Morgaine.
===================
Davy Meers
David Weiseth
Morgaine
You wrote:
1) definition of Fully and Partial Observability:
"...An environment is fully observable if the sensors can always see the entire state of the environment. It's partially observable if the sensors can only see a fraction of the state, ..." - http://www.youtube.com/watch?feature=player_embedded&v=5lcLmhsmBnQ#t=94s
The percepts that reach us indicate the presence of only two discrete states in the environment, and we certainly have not been told that the process that results in loading of the coin operates through hidden state. It's quite a stretch to suggest that loading implies hidden state when we can represent everything that we need to represent about a loaded die as an outcome probability on the throw, ie. the action. No hidden state needed. It's as silly as defining an "ether" in centuries past, not needed at all.
Be that as it may, my reasoning is as lacking in authority as yours is in this context. WE HAVE NOT BEEN TOLD what the true story is, because the model and environment have not been defined with the required degree of precision. If the Profs were to state that loading of a stochastic mechanism is modeled in the Intelligent Agent as hidden state of the environment, I would be wildly happy to accept it. But they haven't, so it's an invention of ours at this point.
2) "Every Stochastic problem is defined as having a Partially Observable environment, because the randomness of actions or percepts is considered the result of a hidden element in that environment."This is not correct.
Your Backgammon example using a fair die wasn't analogous to Loaded Coin, for reasons I already explained. I made my suggestion (2) only to get us out of this predicament caused by lack of a precise definition of what may and may not constitute hidden state. I don't have any reason to believe that (2) is correct at all (it was just an easy way out), but it's academic anyway since we don't have confirmation nor denial from the Profs in either direction.
Unfortunately, that still leaves us with the quandry as to what is really going on in Loaded Coin, because (i) it does not fit the Intelligent Agent model since calculating the probability is not a formal part of its control loop, and (ii) we have no indication from the Profs whether coin loading can be considered hidden state, or hidden anything else. In fact, they have not even said what is the domain of X in Partially_Observable(X).
It's dreadfully imprecise, and that's why we're wasting time on this discussion instead of doing something productive like learning.
Unless someone can attract the attention of one of the Profs to give us more info, I strongly suggest that we do not pursue this further. Our guesses mean nothing, no matter how much we try to substantiate them. We simply lack the required precise formal definitions. Unless this is corrected, we will be guessing in the exam.
Morgaine.
===============================
Gustavo Cardial
Approach,
they classify Backgammon as fully observable and stochastic.
You don't know what's on your opponent's mind, but you can see the
whole board and have enough information to make an optimal decision
on
how to play your next move.
On 20 out, 18:20, David Weiseth <dweis...@gmail.com> wrote:
> Fully observable, I do not think so, I submit for your consideration...
>
> This is what I removed from Wikipedia on Backgammon, I do not know the game
> well, but check out the description.
>
> Although luck is involved and factors into the outcome, strategy plays a
> more important role in the long
> > Now about the loaded coin: (which i now think was an incomplete problem
> > description)
>
> > the state of the environment is the value of the coin, whether the coin is
> > loaded or not and (if applicable) how much the coin is loaded.
>
> > Is the environment fully or partially observable?
> > It depends on the assumption you make about the sensors:
>
> > If you assume there is only a sensor that gets the value of a coin after a
> > flip, then the environment is partially observable.
> > If you assume there are sensors that gets the value of the coin after a
> > flip, detect whether the coin is loaded or not, and determine how much the
> > coin is loaded (if it is loaded), then the environment is fully observable.
>
> > I hope i was able to clearly state how i see things.
> > Please correct me if i am wrong; i am here to learn too.
>
> > Regards,
> > Davy
>
>
> mais »
Morgaine
If the dice are loaded (as all real physical dice are to some extent) then Backgammon becomes Partially Observable by the same reasoning that Davy Meers gave for Loaded Coin, by his own argument.
However, I do not subscribe to that argument because I wish to adhere to the formal agent model given by Prof Thrun, and he has not declared that the loading of a coin or a die is modeled as hidden state. From what we have been told, stochastic behaviour is a property either of our agent's actions (the coin flip or die toss) or of another actor in the environment. We have no reason to believe that another actor is present in Loaded Coin.
While I am happy to invent 50 new things before breakfast where necessary, I do not believe it is admissible for any of us to add things to this formal model just to explain something that otherwise seems to be a matter of dispute. And that is why I consider Real Backgammon and also Loaded Coin to be Fully Observable despite the loading of their stochastic elements.
Really this needs to go back to the Profs, otherwise there are going to be a lot of failures in the exams. Definitions at this level need to be precise. "Stanford Quality" should mean something.
Morgaine.
====================
> ...
>
> mais »
David Weiseth
> ...
>
> mais »

Raf
That would be wonderful, except for the fact that the course definitions are so imprecise that they don't tell us what constitutes state and what doesn't. How can we assign a meaning to "if the sensors can always see the entire state of the environment" if we don't know what is allowable as "state"?
The percepts that reach us indicate the presence of only two discrete states in the environment, and we certainly have not been told that the process that results in loading of the coin operates through hidden state. It's quite a stretch to suggest that loading implies hidden state when we can represent everything that we need to represent about a loaded die as an outcome probability on the throw, ie. the action. No hidden state needed. It's as silly as defining an "ether" in centuries past, not needed at all.
<CUT>


stanford...@gmail.com
@StanfordAIClass It would be nicer if you would link to the explicit thread instead of to the home page of this google group
Manoel Brasileiro
I would like to try again.
I think we're approaching a clearer state now :) There should be a
misunderstanding about environment observability and agent control
loop (or the mapping function between sensors outputs and agent's
actuators as stated by Prof Thrun and mentioned by Morgaine).
Let's consider the chess example. We can imagine two distinct Game
Agents, for example me and Deep Blue's, looking at the chessboard.
Even if we see the same match (environment state) our actions would be
very different. That occurs because our previous knowledge and
training on chess. My knowledge is somewhat shallow and my strategies
are weak. Deep Blue's agent should have a much more complex mapping
function (responsible for his strategies) and therefore his moves will
be more worthy (or least cost) in order to protect his own pieces and
defeat the opponent than my moves (a kind of 'dumb' agent :).
But the environment is the same in despite of the different actions of
these agents. The remaining pieces and their current positions can be
instantly verified by both agents. Thus the environment is fully
observable and each agent action (next move) can be determined by such
a current state and its own strategy (mapping function from its inputs
to outputs, which can be more or less complex). The same works to
backgammon, checkers, and so on.
What do you think, guys?
On 20 oct, 22:32, David Weiseth <dweis...@gmail.com> wrote:
> Incredible, you are right and they characterize Chess as Fully observable
> too, wow. Even though IBM reluctantly admitted training Deep Blue to
> specifically fight Kasparov, by learning from HIS games. There is even a
> real world example the proves that wrong.
>
> Remember everything is theoretically fully observable, if we could view the
> brain via MRI with amazing resolution down to the neural level, but this is
> not about theory, this is all about practical Agents!
>
> Well I guess I am going to be bold and say the book is wrong, but Chess is
> even more obvious. Wow, backgammon is a stretch, but I still think could be
> true, I must admit I do not know backgammon well enough, but still think the
> rule of if it is adversarial it is stochastic and partially observable is a
> good rule in all but the simplest games. Backgammon might be simple enough,
> but Wikipedia's description if correct disputes this.
>
> hmmm. Ok.
>
> On Thu, Oct 20, 2011 at 6:04 PM, Gustavo Cardial
>
> plus de détails »
David Weiseth
Morgaine
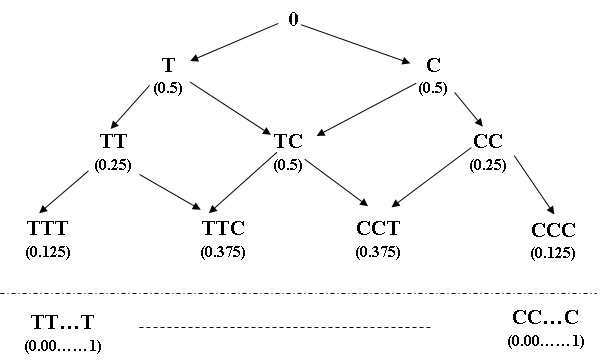
Your diagram and explanation are indeed helpful (extremely helpful), but not in the way you expect. They are helpful because they illustrate perfectly that there are no additional hidden states in the environment other than the two states T and C which are directly visible through percepts. This is true in both the case of a fair coin and that of a loaded coin. I am sure you agree with this, since you have not added any additional environment states.
Instead, what you have done is to create a search state space of your own, separate from the environment, in which each state of the search space has a name or attribute indicating the number of times that a particular percept has been seen. This search state space of yours (which is an great suggestion by the way) is an infinite state space, because the problem specification has not requested that we return the probability with any particular value of precision or error bound, so the tree has no lower boundary. An actual implementation could of course allow our calculation of probability to be read out at any time or at multiple times, but nevertheless the search state space is infinite, since we do not have a termination condition. And it's an infinite space in principle as well.
Now then, let me state why this suggestion is so excellent.
First of all, it is the first suggestion made in this thread that has in any way provided an answer within the context of Prof Thrun's formal model of the Intelligent Agent. All the others have gone outside of it, which I believe is inadmissible in our educational context. The reason why yours lies within the model is because every computation it performs belongs to the Control Program of the Agent because it is used to modify our decision process to navigate the agent intelligently through its search state space in the direction of our goal. That is exactly as per the definitions of Intelligent Agent and goal searching given by both Profs, and it is easy to see how it delivers the desired result. Excellent.
But notice three things:
- Your search state space is internal to the agent and does not seek to model the external environment directly. Instead it defines a topologically different internal state space in order to be able to solve the problem specified. This is entirely permissible since we have not been told that the search state space has to mirror the environment state space in any way. Since the nature of search spaces has not been constrained, and your proposal does not conflict with the formal model of Intelligent Agent, this is almost certainly OK, and very helpful.
- Your search state space is an infinite space as I detailed above, and although its states are discrete, there is an unbounded number of them. This makes the agent's problem inherently continuous as there exists an unbounded number of states in its search tree. Revisiting Prof Thrun's definition of discrete vs continuous, he uses the word "finitely" numerous times to distinguish between the two, but alas his explanation is ambiguous: he says "finitely many action choices / things you can sense", but he also says "finitely many board positions" which suggests that search state space is relevant too. I'm not sure how to quantify your infinite search state space by Thrun's rules, since "infinite but discrete" appears not to fall in either of his categories. This relates strongly to the next point, environment state space versus search state space.
- The external environment remain totally discrete and finite, with only two states, and your proposal offers no reason to postulate any additional environment states. This brings us to a dilemma: All 4 properties defined by Prof Thrun are properties of the environment, and the environment is external to the Intelligent Agent in the formal model. (The environment is that part of the overall system which acts on the agent's sensors to generate percepts, and which is affected by actions whenever the agent uses its actuators, ie. the environment is always external to the agent.) So while your agent's chosen internal state space is clearly Partially Observable (since your agent cannot see states further ahead in its search space in advance of receiving percepts), the environment state space is equally clearly Fully Observable, as it has only two states, no hidden actors, and no reason for postulating any additional environment states. This is a problem of model definition. Although neither of the Profs has defined precisely what elements may appear in the environment (but the environment has to be external to the Agent), they have clearly defined the 4 properties as being properties of the environment. Yet, here we have an excellent formulation of the search state space which allows us to solve the problem entirely within the constraints of the model but which has properties which are totally different to those of the environment. Which properties should be used for our answers, the nature of the environment or the nature of our chosen state space?
All of the above underlines extremely strongly that the definitions we have been given LACK PRECISION. We have a perfect solution now, entirely within the formal Agent model, yet we have no means of deciding on Partially vs Fully Observable because our agent's solution has a Partially Observable state space while the environment has a Fully Observable state space. This is really not good enough. If I were on campus I would ply Sebastian or Peter with free drinks until they clear up this mess. The definitions we have been given are so imprecise that they are unusable in cases like this one.
As an aside, it's worth noting that no memory of past events is required in your solution in order to calculate the loading probability estimated so far at any node of the tree. All we need is normal path cost arithmetic similar to that used in the Romanian example. Memory used to accumulate path cost along a path was not regarded as a reason for claiming that the environment was Partially Observable in Romania, and nor is it in your solution. (However, your unbounded search state space does give us a different reason to claim Partial Observability, albeit not of the environment but of your search space.)
In summary, excellent suggestion, Raf. Unfortunately it just highlights even more the truly bad state of definitions in the formal model. We need some simple questions answered, and it is not sufficient that WE answer them to our own satisfaction. WE are not going to be marking the exams.
This needs fixing by the Profs, or we will enter the exams just guessing.
Morgaine.
======================

{kind=link}
Rick Post
and am lost in the complexity and formality. I'm a simple person that
is trying to take this down to examples at a practical application
level.
I have a spacecraft that's going to land on an unknown asteroid and
determine the length of the local day in order to collect solar
energy. All the Agent in charge of this job has is a light sensor (my
inputs) and my "actuator" is a place to store the # of hours of
daylight and the length of day.
Once an hour, I wake up, check my light sensor and save some numbers
depending on if it's light or dark. (like a coin flip)
If I am implemented with NO MEMORY, I wake up, see light and store one
in the light variable. At this point, all I know id the day is at
least about 1 hour long. Next hour, I wake up, no memory of what I saw
last time, check my sensor, it's still light, so I store 1 in the
light variable. I know the local day is at least about an hour long
but nothing more. I'm learning NOTHING about my state space if I have
no memory of previous trials.
If I am implemented with MEMORY, I wake up, see the light, store a one
in the light variable and go to sleep. At this point, I know the day
is at least about an hour long. Next hour, wake up, still light? Yes,
ADD one to the light variable. I now know the daylight lasts for at
least about 2 hours. Wake up the next hour, it's still light, ADD one
to the light variable and I now know that I have at least about 3
hours of daylight to work. Wake up the next hour and it's dark, the
atmosphere agent has determined no atmosphere so it just didn't get
cloudy, there were no catastrophic events during sleep, so now I know
it's night. I add done to the dark variable. Now I know the day lasts
at least about hours and I need to start tracking night.
The environment I was dumped into is partially observable to the
agent. One snapshot is full observable (light/dark) but it tells me
nothing. In order to reach my goal: day/night cycle time, I need to
record previous states until I'm satisfied with my results.
Does this fit the formal definition? I don't know, I don't get hung
about on formal definitions. I have inputs, I have an agent examining
the inputs in order to complete a goal, I have outputs. My agent is
learning about its environment and can make an intelligent decision
based upon observations.
Rick
>
> read more »
Morgaine
If you use Raf's type of solution above then you are creating a search space internal to the agent which contains an infinite sequence of search space nodes (you can decide on a termination condition to keep the tree finite though). This will need no additional memory, because it's equivalent to computing the incremental path cost in the Romanian example --- in your case, each new node refines the previous estimation of day length by sending the agent down one of two choices, either "Day/night has not switched yet so the half-period is longer than this extra hour" or "Day/night switch is now detected so the half-period is longer than this extra hour". The fact that the actual calculation is arithmetically a bit different to the Romanian or Loaded Coin ones is not germane. You do not need extra memory beyond the memory inherent in storing your path through the tree, since the path contains all the information you need to compute the day length to any degree of accuracy (subject to some Nyquist limits). Note that your environment is fully observable and discrete, but your problem space is infinite unless you add a termination condition such as accuracy or duration of measurement, and an infinite search space appears to be one of the properties of a continuous rather than a discrete space, according to the videos. So there are two question marks here, as we're not totally certain whether it is the properties of the environment or the properties of the chosen search space that matter. Either way, we will get the desired day-length result, but we won't necessarily pass the exam since the definitions are sloppy. :-)
On the other hand, we can use the type of solution suggested by most of the contributors to this discussion: we can ignore the model of Intelligent Agent given by Prof Thrum, and allow memory that has nothing to do with agent choices made by the Control Program to be a determinant of Partial Observability of the environment. That would work pragmatically of course, but it's extremely sloppy educationally to not adhere to the formal model that we have been given. Also, it results in the very poor conclusion that the environment is only Partially Observable because we have used memory, when it's pretty obvious to anyone that the day/night sequence in the environment is totally and completely Fully Observable.
So, once again, we have an example that highlights how the existing definitions just don't work well at all, and can give the wrong answers for Partial/Fully and for Discrete/Continuous even while pragmatically giving the right answer numerically.
Our solutions don't have a problem, but our educational concepts do.
Morgaine.
====================
David Weiseth
Morgaine
Sure, a computer program agent is always going to employ memory, but that is not germane to the definition of Partial or Full Oberservability. If it were germane then all systems would be Partially Observable because they would all employ memory. Obviously this is NOT what Prof Thrun meant when he referred to use of memory.
His reference to memory was specific to memory required in the theoretical model defined for the Intelligent Agent which allows that agent to make the best decision in navigating through its decision tree towards its desired goal. It's a very specific meaning of "use memory".
Rick's example is a great one for illustrating the problem. Memory is used to remember what the day/night state was at preceding sample points, and so one might conclude from Prof Thrun's videos that the environment is Partially Observable since memory is used to help us. However, that is a silly conclusion since it is obvious from inspection that the day/night state space is Fully Observable, as is the length of the day. Nothing is hidden. It's a clear indication that using memory, even within the model, has little or nothing to do with Observability of the environment.
Morgaine.
=====================
Rick Post
In the matter of an hour or so, I've made a silly conclusion and
missed something "pretty obvious to anyone that the day/night sequence
in the
environment is totally and completely *Fully* Observable. "
Coin Toss: Goal is to determine if a coin is fair or loaded.
#1) Take 100 identical coins, flip each coin and place on table either
heads or tails, as then landed. Examine 100 coins to determine as best
as able the fairness of the.
I see this (#1) as a fully observable environment.
#2) Take one coin of unknown fairness. Flip coin 100 times
a) record the result of each flip (you state memory is being
created with each flip). After 100 flips, determine fairness. You
sense the result one flip at a time and then commit to the state
memory before observing the next result.
b) flip the coin 100 times. DO NOT RECORD THE RESULT IN ANY WAY.
You sense the result one flip at a time but in no way record the
observed states.
#2a is partially observable and the goal can only be completed by
introducing state memory to record the outcomes.
#2b is unsolvable since you only have each individual flip to
determine the fairness. With one flip, EVERY coin is FAIR and/or EVERY
coin is loaded.
My day/night scenario is like #2. You don't have continuous
observability of daylight, only what you see when you wake up and take
your snapshot.
A maze from rat's view is partially observable, from researchers view,
fully observable. A route solution problem from the cars point of view
(street level) is partially observable, from an aerial view with a
map, fully observable.
Being silly and blind to the obvious, my scenarios above seem to make
sense to me.
Rick
On Oct 21, 4:01 pm, Morgaine <morgaine.din...@googlemail.com> wrote:
> You're confusing the implementation with the model, David.
>
> Sure, a computer program agent is always going to employ memory, but that is
> not germane to the definition of Partial or Full Oberservability. If it
> were germane then all systems would be Partially Observable because they
> >> memory*, when it's pretty obvious to anyone that the day/night sequence
> >> in the environment is totally and completely *Fully* Observable.
> >> So, once again, we have an example that highlights how the existing
> >> definitions just don't work well at all, and can give the wrong answers for
> >> Partial/Fully and for Discrete/Continuous even while pragmatically giving
> >> the right answer numerically.
>
> >> Our solutions don't have a problem, but our educational concepts do.
>
> >> Morgaine.
>
> >> ====================
>
>
> read more »
David Weiseth
Morgaine
Being silly and blind to the obvious, my scenarios above seem to make sense to me.
This is why it is imperative that the educational models are defined very precisely, so that we can deal with problems analytically by using those models as templates that straightjacket our many problem spaces.
The fact that the definitions have been so hugely imprecise that they are unable to tightly constrain our problem spaces into analytical forms worries me greatly.
Morgaine.
=======================
> ...
>
> read more »
Morgaine
There is no way to determine Partial Observability without knowing the problem/goal of the Agent, because it is about the ability of the model to allow the goal to be satisfied, and it is always in the context of what is practical or workable.
Properties like Full/Partial Observability should not refer to the environment (which is the part beyond the agent's sensors and actuators and is not a function of the agent's Control Program). Those properties should instead refer to the chosen search state space of the agent.
And Observability of the environment has almost nothing to do with whether agent memory is used in dealing with it, as memory used is entirely a function of the strategy employed by the agent as various examples have now identified.
What a mess.
Morgaine.
===================
Mark Rampton
Morgaine
I have only an interest in understanding how to apply the formal models we've been given to solve the example problems we are given. The lack of precision in the definitions does not allow us to do that analytically, which is why this thread exists. Since you seem to have acquired certainty about what the Profs meant anyway, consider yourself lucky.
Have a good day.
Morgaine.
==================
Morgaine
In other words, we are all handwaving, and the exam is going to require pure guesswork on our part unless by chance the problems fit easily into the formal model. Loaded Coin did not fit.
And finally ... in my 7th post I said I was going to stop writing to this thread because, short of receiving direct input from the Profs to resolve the uncertainties, this was leading nowhere. Well some of the contributors were so insightful that I felt it necessary to rejoin, but if we're going to start receiving negative "help" like from the previous poster then it's time to stop again.
Many thanks to everyone who tried to assist. The definitional problem is not going to be solved unless a Prof turns up here, so we might as well adjourn.
(Special thanks to Raf Ventaglio for your excellent state diagram which made me think a lot.)
Good luck to you all in your exams.
Morgaine.
David Weiseth
Stuart Gale
homework video again. Listen to what Prof Thrun says, carefully, from
27s onwards:
"You're task [is] to understand from coin flips whether a coin is
loaded and if so at what probability..."
In order to work out if a coin is loaded or not requires the coin
flipper to take note of what the flips came out as, hence the task is
partially observable. It cannot be determined by any single flip.
Stuart
David Weiseth
Raf
Excellent, Raf!
Your diagram and explanation are indeed helpful (extremely helpful), but not in the way you expect. They are helpful because they illustrate perfectly that there are no additional hidden states in the environment other than the two states T and C which are directly visible through percepts. This is true in both the case of a fair coin and that of a loaded coin. I am sure you agree with this, since you have not added any additional environment states.
Instead, what you have done is to create a search state space of your own, separate from the environment, in which each state of the search space has a name or attribute indicating the number of times that a particular percept has been seen. This search state space of yours (which is an great suggestion by the way) is an infinite state space, because the problem specification has not requested that we return the probability with any particular value of precision or error bound, so the tree has no lower boundary. An actual implementation could of course allow our calculation of probability to be read out at any time or at multiple times, but nevertheless the search state space is infinite, since we do not have a termination condition. And it's an infinite space in principle as well.