gamma_log encountering negative inverse scale parameter
445 views
Skip to first unread message

rcdr...@gmail.com
Feb 4, 2016, 10:35:46 AM2/4/16
to Stan users mailing list
Hi,
I'm having some problems with a model I'm trying to run.
I have a series of values I'm trying to estimate and am fitting them as a random walk.
So in the parameters section I have:
parameters {
...
real exp_subclinical[n_years];
...
}where n_years is an integer passed in as data, and in the model section:
model {
exp_subclinical[1] ~ uniform(1,upper_lambda1);
for( oy in 2:n_years ){
exp_subclinical[oy] ~ gamma(exp_subc_k, exp_subc_k/exp_subclinical[oy-1]);
}
...
}where exp_subc_k is a positive number provided as part of the data.
When I am running the model I get Metropolis proposals rejected because of:
Exception thrown at line 104: stan::math::gamma_log: Inverse scale parameter is -61.6392, but must be > 0!Line 104 is the line within the for loop with the gamma sampling statement, and there can be quite a lot of these messages.
I don't understand how the inverse scale parameter can become negative, being the division of a positive value by a value which is either from a uniform(1,some positive value I supplied) or a gamma distribution.
I did not observe this when I initially ran the problem for few iterations with unrealistic initial values (all exp_subclinical were 1000) but did when running for many iterations - the values of exp-subclinical decline from 1:n_years so providing more realistic initial values lets me see the problem at lower numbers of iterations and would indicate that it is related to low exp_subclinical values.
I have tried this with cmdstan and rstan with the same outcome.
Why would this be happening?
Thanks.

Jonah Gabry
Feb 4, 2016, 11:03:00 AM2/4/16
to Stan users mailing list
One issue is that parameters with constraints need to be declared with those constraints in the parameters block or you can get invalid proposals. So if a parameter has to be positive it should be declared with <lower=0>, if it's a probability it needs to be declared with <lower=0, upper=1>, etc. So using a constrained uniform distribution on a parameter declared without those constraints is a problem. Does that parameter actually have a logical lower bound of 1? If you just think it's unlikely for it to be less than 1 than I would use a prior that places low probability mass in (0,1) but without impose a lower bound of 1 unless it's a logical requirement.
Jonah
Ron
Feb 4, 2016, 11:44:39 AM2/4/16
to Stan users mailing list
Hi Jonah,
On Thursday, February 4, 2016 at 4:03:00 PM UTC, Jonah Gabry wrote:
One issue is that parameters with constraints need to be declared with those constraints in the parameters block or you can get invalid proposals. So if a parameter has to be positive it should be declared with <lower=0>, if it's a probability it needs to be declared with <lower=0, upper=1>, etc. So using a constrained uniform distribution on a parameter declared without those constraints is a problem. Does that parameter actually have a logical lower bound of 1? If you just think it's unlikely for it to be less than 1 than I would use a prior that places low probability mass in (0,1) but without impose a lower bound of 1 unless it's a logical requirement.Jonah
Thanks, I'll explicitly include the constraints in the parameter block and try again.
The constraint on the first value could be placed at zero, since the upper bound is high (1000s) the probability would be very small.
If I made the prior on the first value something like ~ gamma(x,1) with x half way along my previous uniform range that might be better too.
Jonah Gabry
Feb 4, 2016, 12:31:28 PM2/4/16
to Stan users mailing list
Hi Ron,
I hope that works better, but I also wanted to take your example as an opportunity to point out a common (though totally understandable) misconception about Stan. You say
I don't understand how the inverse scale parameter can become negative, being the division of a positive value by a value which is either from a uniform(1,some positive value I supplied) or a gamma distribution.
I added the emphasis because it's not actually true that this value will be from a uniform or gamma. In terms of how the model is written it might seem like that would be true, but Stan isn't actually drawing values from those distributions. Taking the gamma as an example, when you do something like
theta ~ gamma(a, b)Stan does not draw a value for theta from a gamma(a,b) distribution. The value of theta comes from the state of the Markov chain. Taking that value for theta, Stan computes (up to a constant) the value log(gamma(theta | a, b)), i.e. the value of the
gamma(a,b) distribution evaluated at theta. The following are equivalent (up to a normalizing constant)
theta ~ gamma(a, b)
increment_log_prob(gamma_log(theta, a, b))So while it's true that this is equivalent (for Stan) as placing a gamma(a,b) prior on theta, it does not actually mean that theta is being sampled from a gamma distribution. The only place in a Stan program where that explicitly happens is in generated quantities, where you could do something like
x <- gamma_rng(a,b)
Bob Carpenter
Feb 4, 2016, 2:30:52 PM2/4/16
to stan-...@googlegroups.com
We only recommend uppper/lower bound constraints where necessary,
not as a kind of hard prior knowledge. The main reason is that
if there's any probability mass around the boundary it'll be
problematic both computationally and statistically, wheras there's
no downside for not including a hard constraint.
- Bob
> --
> You received this message because you are subscribed to the Google Groups "Stan users mailing list" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to stan-users+...@googlegroups.com.
> To post to this group, send email to stan-...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
not as a kind of hard prior knowledge. The main reason is that
if there's any probability mass around the boundary it'll be
problematic both computationally and statistically, wheras there's
no downside for not including a hard constraint.
- Bob
> You received this message because you are subscribed to the Google Groups "Stan users mailing list" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to stan-users+...@googlegroups.com.
> To post to this group, send email to stan-...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.

Andrew Gelman
Feb 4, 2016, 8:46:45 PM2/4/16
to stan-...@googlegroups.com
This reminds me . . . have we considered removing the uniform distribution entirely from Stan? It seems like the _only_ use for it is either completely redundant or else wrong (e.g., a variable is defined as unconstrained but then the user gives a uniform with fixed bounds).
Jonah Sol Gabry
Feb 4, 2016, 8:58:29 PM2/4/16
to stan-...@googlegroups.com
On Thu, Feb 4, 2016 at 8:46 PM, Andrew Gelman <gel...@stat.columbia.edu> wrote:
This reminds me . . . have we considered removing the uniform distribution entirely from Stan? It seems like the _only_ use for it is either completely redundant or else wrong (e.g., a variable is defined as unconstrained but then the user gives a uniform with fixed bounds).
I have yet to see an example where calling uniform() is useful. If it's not already implied by the constraints then something hasn't been declared properly.
That said, I think some people like calling uniform() because when reading a Stan program it can be nice to see every unknown explicitly get a prior.
Andrew Gelman
Feb 4, 2016, 9:02:48 PM2/4/16
to stan-...@googlegroups.com
That’s another reason not to do it, then!
Bob Carpenter
Feb 5, 2016, 2:04:03 AM2/5/16
to stan-...@googlegroups.com
The only use I see for the pdf is normalization.
But we need the PRNG, and maybe the CDFs.
If we did get rid of the uniform distribution, we'd
probably want to flag it as missing on purpose in the
parser.
- Bob
But we need the PRNG, and maybe the CDFs.
If we did get rid of the uniform distribution, we'd
probably want to flag it as missing on purpose in the
parser.
- Bob
Andrew Gelman
Feb 5, 2016, 2:07:44 AM2/5/16
to stan-...@googlegroups.com
Yes, or alternatively we could have the parser spit out a warning if there’s a uniform and say don’t do it. But that would just confuse people more…
Ron
Feb 5, 2016, 3:39:04 AM2/5/16
to Stan users mailing list, gel...@stat.columbia.edu
Thanks for the clarification, Jonah.
And thanks for the discussion on the use of uniform, I'm going to try to avoid the temptation to use it from now on.
My model is running much better now with constraints declared explicitly in the parameter section and using a gamma prior instead of a uniform. Now to see if I can make any speed improvements.

Guido Biele
Feb 5, 2016, 6:04:41 AM2/5/16
to Stan users mailing list
about the usefulness of the uniform:
for me it was very useful when I had difficulties using the Cauchy distribution,
which, as the stan reference explains can be difficult to sample from because
different step sizes are optimal dependent on if one is in the tails or not.
as recommended in the stan reference I then re-parameterized
chauchy(location, scale)
to
location + scale * tan(uniform(0,pi()/2))
which worked much better.
so please keep the uniform!!
cheers - guido

Michael Betancourt
Feb 5, 2016, 11:23:56 AM2/5/16
to stan-...@googlegroups.com
Guido,
The point is that such a transformation could be implemented as
parameters {
real<lower=0, upper=0.5 * pi()> alpha_tilde;
…
}
model {
…
alpha <- location + scale * alpha_tilde;
…
}
No uniform is necessary once alpha_tilde is properly constrained.
Bob Carpenter
Feb 5, 2016, 11:47:04 AM2/5/16
to stan-...@googlegroups.com
Not just "could", but "should". The uniform by itself isn't
enough --- you need the constraint. But when you have the constraint,
you don't need the uniform (other than to normalize).
- Bob
enough --- you need the constraint. But when you have the constraint,
you don't need the uniform (other than to normalize).
- Bob
Guido Biele
Feb 5, 2016, 11:53:16 AM2/5/16
to stan-...@googlegroups.com
OK,
I had constrained alpha_tilde as you write,
and now I also remember that the manual
stated that the statement
alpha_tilde ~uniform(0,pi()/2)
is not necessary if alpha_tilde was
properly constrained.
You received this message because you are subscribed to a topic in the Google Groups "Stan users mailing list" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/stan-users/AqBZT2h5Jyw/unsubscribe.
To unsubscribe from this group and all its topics, send an email to stan-users+...@googlegroups.com.
Guido Biele
Feb 5, 2016, 12:24:28 PM2/5/16
to stan-...@googlegroups.com
Let me continue this wit a question about that I could
use instead of the uniform in a specific case:
I am estimating a multilevel model with group-specific
over-dispersion parameter "phi" for the negative binomial.
at the moment I am doing the following:
parameters {
...
real<lower=0, upper=50> alpha_phi;
real<lower=0, upper=50> beta_phi;
real<lower=0> phi[M];
...
}
model {
...
phi ~ gamma(alpha_phi, beta_phi);
...
}
(I started with a Cauchy as a priors for the over dispersion,
but then switched to the gamma, which Kruschke uses as a
hierarchical prior for error variance in his book).
I tried to avoid using the uniform priors (even though
the model converges just fine) by putting priors gamma-priors
on the mean and variance of the gamma and then transform
mean and variance to phi_alpha and phi_beta in the transformed
parameters block:
parameters {
...
real<lower=0> phi_mu;
real<lower=0> phi_sigma;
real<lower=0> phi[M];
...
}
transformed parameters {
...
real phi_alpha;
real phi_beta;
phi_alpha <- phi_mu^2/phi_sigma^2;
phi_beta <- phi_mu/phi_sigma^2;
...
}
model {
...
phi_mu ~ gamma(8,6);
phi_sigma ~ gamma(8,6);
phi ~ gamma(phi_alpha , phi_beta );
...
}
but here my problem was that I "data peaked" to get an
idea about the priors for phi_mu and phi_sigma, and that
this did not converge nearly as well as directly
using uniform priors.
What would you recommend to model hierarchical error
variances/over dispersion?
Guido
Taking the risk to one again expose my ignorance :-)
I understand that the log probability is incremented
when one uses "~" or increment_log_prob. I guess log_prob
is also incremented when puts constraints on a parameter
and does not use uniform(), i.e. log_prob would in this case
be incremented without a "~" or an increment_log_prob statement?
Bob Carpenter
Feb 5, 2016, 12:56:05 PM2/5/16
to stan-...@googlegroups.com
[changed subject]
Every constrained variable contributes a Jacobian term
to the log density --- they're all defined in a chapter of
the manual. The uniform is a scaled and translated inverse
logit. That's because Stan's densities are expressed on
the unconstrained scale.
I think part of the issue for hierarchical variances is how
plausible values near zero are (i.e., complete pooling).
Andrew discusses behavior around zero in his papers (cited
in the manual).
What we need is an update here:
https://github.com/stan-dev/stan/wiki/Prior-Choice-Recommendations
- Bob
P.S. That's "peeked", not "peaked"! You want to do sensitivity
analysis whatever you do on these priors and make sure you're
not adding in too much prior information (where "too much" is
of course dependent on your prior knowledge!).
Every constrained variable contributes a Jacobian term
to the log density --- they're all defined in a chapter of
the manual. The uniform is a scaled and translated inverse
logit. That's because Stan's densities are expressed on
the unconstrained scale.
I think part of the issue for hierarchical variances is how
plausible values near zero are (i.e., complete pooling).
Andrew discusses behavior around zero in his papers (cited
in the manual).
What we need is an update here:
https://github.com/stan-dev/stan/wiki/Prior-Choice-Recommendations
- Bob
P.S. That's "peeked", not "peaked"! You want to do sensitivity
analysis whatever you do on these priors and make sure you're
not adding in too much prior information (where "too much" is
of course dependent on your prior knowledge!).
Jonah Sol Gabry
Feb 5, 2016, 2:56:05 PM2/5/16
to stan-...@googlegroups.com
On Friday, February 5, 2016, Guido Biele <guido...@gmail.com> wrote:
about the usefulness of the uniform:for me it was very useful when I had difficulties using the Cauchy distribution,which, as the stan reference explains can be difficult to sample from becausedifferent step sizes are optimal dependent on if one is in the tails or not.as recommended in the stan reference I then re-parameterizedchauchy(location, scale)tolocation + scale * tan(uniform(0,pi()/2))which worked much better.so please keep the uniform!!
As others have pointed out you don't actually need to call uniform() to do this. Although even if you did you could get around it by going a different route and inverse-cdf-ing a standard normal.

Ben Goodrich
Feb 5, 2016, 3:00:36 PM2/5/16
to Stan users mailing list
To clarify, Jonah meant inverse-cdf-ing the CDF of a parameter whose prior is standard normal.
Ben
Andrew Gelman
Feb 5, 2016, 4:15:51 PM2/5/16
to stan-...@googlegroups.com
Yes, exactly. You should not do the uniform unless you have the corresponding constraint on the parameter. And, if you have the constraint, the uniform adds nothing. Hence, the uniform can only cause trouble.
On Feb 5, 2016, at 11:23 AM, Michael Betancourt <betan...@gmail.com> wrote:
Andrew Gelman
Feb 5, 2016, 4:29:14 PM2/5/16
to stan-...@googlegroups.com
On a more practical point, if you were planning to do a uniform(0,50) prior, you could instead do a half-normal(0,50), i.e., constrain the parameter to be greater than 0, and then give a normal(0,50) prior. But I really don’t like priors with a scale of 50. I like models to be scale free so that parameters should rarely be much more than 1 in absolute value, in which case we can use normal(0,1) priors or, if you want to be really weak, normal(0,5).
Jonah Sol Gabry
Feb 5, 2016, 6:14:08 PM2/5/16
to stan-...@googlegroups.com
On Fri, Feb 5, 2016 at 3:00 PM, Ben Goodrich <goodri...@gmail.com> wrote:
To clarify, Jonah meant inverse-cdf-ing the CDF of a parameter whose prior is standard normal.
Ben
Yes, thanks for clarifying. That is indeed what I meant.
Guido Biele
Feb 24, 2016, 8:00:43 AM2/24/16
to Stan users mailing list
Thanks everyone for chiming in!
About Andrews advocacy for scale free models:
I try to follow this recommendation when possible.
However, for the data I am working with I need
to use the negative binomial distribution, and here
the over dispersion parameter can take larger values
that are maybe not best modeled with normal(0,1) or
chauchy(0,1) as priors
About my attempts to find suitable priors for hierarchical
modeling of the overdispersion parameter (i.e. the phi of
neg_binomial_2):
I chose to model the hierarchical prior phi with the gamma
distribution, because it has to be larger than zero.
I could also have tried the chauchy, but it appeared more
natural for me to choose the gamma for a _hierarchical_ prior
whose mean I expect to be larger than zero.
Modeling the gamma directly with shape and inverse scale
parameters alpha and beta did not work well. Instead I used
priors for the mean and sd of the gamma distribution
and transformed them to alpha and beta.
Using the cauchy as a prior for the mean of the gamma works
well. Finding a good prior for the sd of the gamma seems
harder. I get the same posteriors for the variance of the
gamma independent if I use a cauchy or uniform prior, but
n_eff is generally low (around 50-80 effective samples from 3
chains with 400 samples each). The low n_eff seems mainly
to be caused by relatively high auto-correlation of the sd
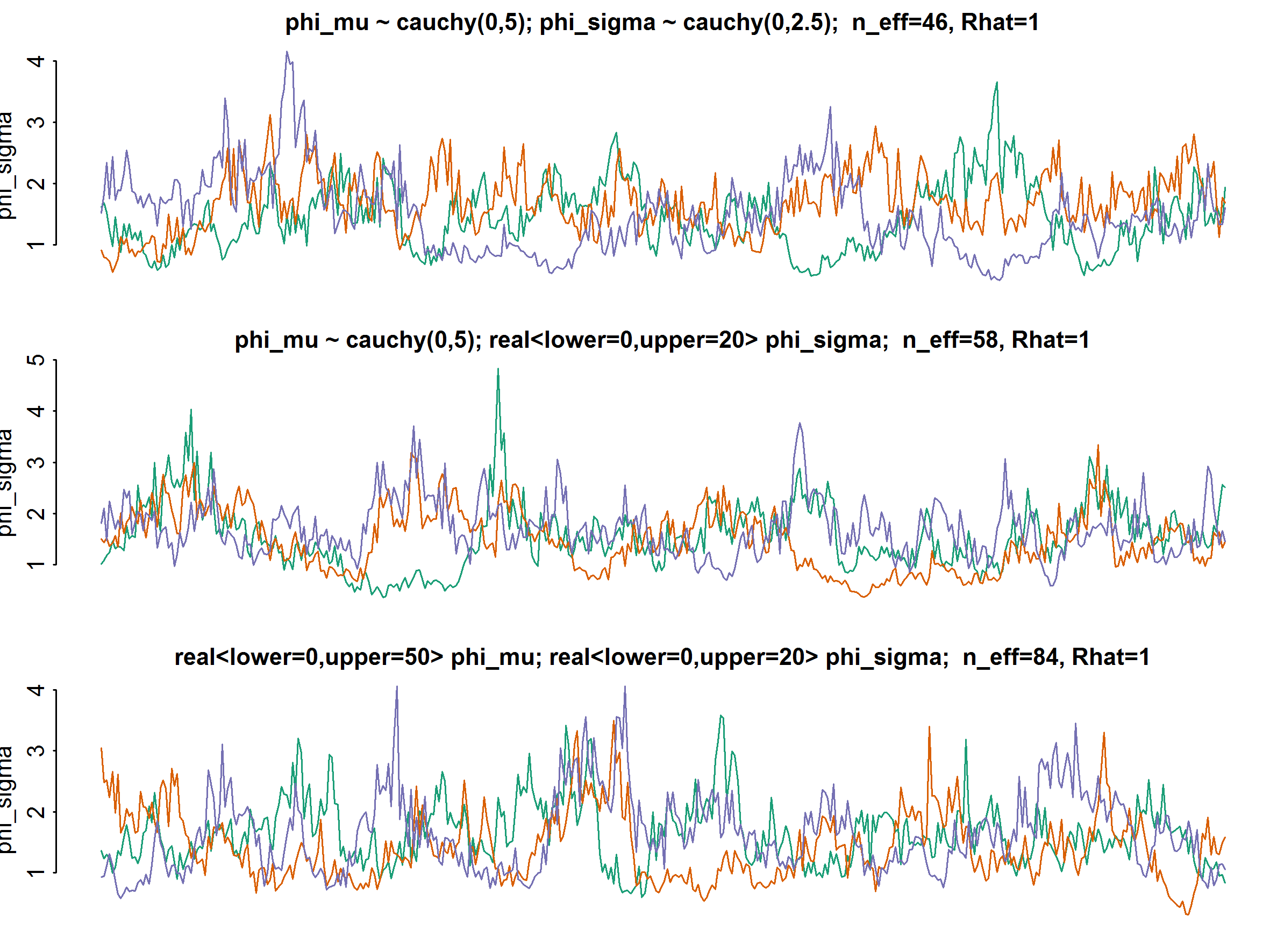
of the gamma distribution (see attachments). I'd welcome
any suggestion to reduce this auto-correlation (of course
i can always run the chain longer).
here are the relevant snippets of how i am currently modeling
hierarchical priors for phi:
parameters {
...
// overdispersion of negative binomial
real<lower=0, upper=pi()/2> phi_mu_unif;
real<lower=0, upper=pi()/2> phi_sigma_unif;
real<lower=0> phi[M]; // M = number of groups
}
transformed parameters {
...
phi_mu <- 5 * tan(phi_mu_unif);
phi_sigma <- 2.5 * tan(phi_sigma_unif);
}
model {
...
phi ~ gamma(phi_mu^2/phi_sigma^2, phi_mu/phi_sigma^2);
// could also calculate alpha and beta in the transformed parameters block ...
...
}
Some more observations:
It looks as if I can stick to the default adapt_delta when using
uniform priors for the variance of the gamma, whereas I have
to increase adapt_delta when using cauchy priors in order to avoid
divergent iterations (I only tried .95, which worked)
I find the re-parameterization of the cauchy described in the manual
very useful.This seems especially useful for the prior scale tau of
the hierarchical regression model. Maybe it would be useful for
other users to include a version of the model on page 75 of the
manual (version 2.9.0) into the manual that also uses a
re-parameterization for the prior scale tau.
Cheers - Guido
{kind=link}
Bob Carpenter
Feb 24, 2016, 6:06:59 PM2/24/16
to stan-...@googlegroups.com
> On Feb 24, 2016, at 8:00 AM, Guido Biele <guido...@gmail.com> wrote:
>
> ...
> I find the re-parameterization of the cauchy described in the manual
> very useful.This seems especially useful for the prior scale tau of
> the hierarchical regression model. Maybe it would be useful for
> other users to include a version of the model on page 75 of the
> manual (version 2.9.0) into the manual that also uses a
> re-parameterization for the prior scale tau.
as well as the code.
And thanks much for the detailed report.
- Bob
Guido Biele
Feb 26, 2016, 6:36:10 AM2/26/16
to stan-...@googlegroups.com
--
You received this message because you are subscribed to a topic in the Google Groups "Stan users mailing list" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/stan-users/AqBZT2h5Jyw/unsubscribe.
To unsubscribe from this group and all its topics, send an email to stan-users+...@googlegroups.com.
Bob Carpenter
Feb 26, 2016, 3:40:56 PM2/26/16
to stan-...@googlegroups.com
Awesome. Thanks. I'll try to review it in the next
few days --- I'm a bit backed up right now.
- Bob
few days --- I'm a bit backed up right now.
- Bob
> You received this message because you are subscribed to the Google Groups "Stan users mailing list" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to stan-users+...@googlegroups.com.
Reply all
Reply to author
Forward
0 new messages