backrefs for xrefs in domain index
33 views
Skip to first unread message

Charles Bouchard-Légaré
Mar 23, 2022, 12:21:57 AM3/23/22
to sphinx-dev
Hello there,
I am creating an APIs that generate domains, basically a bit of boilerplate code for simple ObjectDefinition directives, XRefRole roles, domain indices.
Under a domain index entry (sub-entries) I would like to add links to xref roles, basically list the object description, but also from where they are cross-refed. Docutils does something similar for footnotes and citations within a given document. The implementation feel really specific for footnotes and citations and I don't think that it provides useful insights for my use-case.
My pain is that the domain index is entirely built before any pending-xref, which happens in a post-transform (per document) at priority 10 (the ReferencesResolver), of course I only want to add to the index resolved cross-references. While reviewing Sphinx events, I didn't find any obvious way of altering domain indices after the doctree resolution.
I am going to try and write a later post-transform (say priority 10+1) that would edit the self.app.builder.domain_indices, I am confident that would be enough.
I was simply wondering if anybody here have been trying to post-transform domain indices before, or if anyone would have some tip I might be missing.
Have a nice day!
I am creating an APIs that generate domains, basically a bit of boilerplate code for simple ObjectDefinition directives, XRefRole roles, domain indices.
Under a domain index entry (sub-entries) I would like to add links to xref roles, basically list the object description, but also from where they are cross-refed. Docutils does something similar for footnotes and citations within a given document. The implementation feel really specific for footnotes and citations and I don't think that it provides useful insights for my use-case.
My pain is that the domain index is entirely built before any pending-xref, which happens in a post-transform (per document) at priority 10 (the ReferencesResolver), of course I only want to add to the index resolved cross-references. While reviewing Sphinx events, I didn't find any obvious way of altering domain indices after the doctree resolution.
I am going to try and write a later post-transform (say priority 10+1) that would edit the self.app.builder.domain_indices, I am confident that would be enough.
I was simply wondering if anybody here have been trying to post-transform domain indices before, or if anyone would have some tip I might be missing.
Have a nice day!
Charles Bouchard-Légaré
Mar 25, 2022, 2:07:28 PM3/25/22
to sphinx-dev
Hello again! To answer my own question
The domain index will generate also index entries for resolved cross-references (stored in the domain data). The issue is that the resolution happens after the generation of indices. The following transformer regenerate the index entries after the resolution of cross-references
I've made something and will post here in case this triggers feedback.
tl;dr
- It works, but it was complicated and will not scale well for large documentations. I might open an issue to suggest introducing a new event, but I would really need some guidance to provide the patch myself
- This whole need comes from a package for generating Sphinx Domain easily that I'll soon publish, stay tuned ;)
class BackrefsIndexer(SphinxPostTransform):
default_priority = ReferencesResolver.default_priority + 1
index_class: Type
domain_name: str
def is_supported(self) -> bool:
return super().is_supported() and hasattr(self.app.builder, "domain_indices")
def run(self, **kwargs: Any) -> None:
domain_indices = getattr(self.app.builder, "domain_indices", [])
# Find the domain index we are rebuilding
index_number = 0
for index_name, index_class, original_entries_for_char, collapse in domain_indices:
if index_class == self.index_class:
break
index_number += 1
else:
return
index = index_class(self.env.domains[self.domain_name])
# Generate again the index
regenerated, _ = index.generate()
# Use a dict instead of list of tuples expected
new_entries_for_char = defaultdict(list, regenerated)
# Merge with entries not in this docname
for character, entries in original_entries_for_char:
new_entries = []
for entry in entries:
if self.env.docname != entry.docname:
new_entries.append(entry)
new_entries_for_char[character].extend(new_entries)
def key(character_entries):
# sub index items have their own display name
# ignore it in the sorting
character, entries = character_entries
return (character, [entry for entry in entries if entry.subtype in (0,1)])
# Change the dict into the sorted list of tuples expected
resorted = sorted(new_entries_for_char.items(), key=key)
# Replace the regenerated index
domain_indices[index_number] = (
index_name,
index_class,
resorted,
collapse
)
default_priority = ReferencesResolver.default_priority + 1
index_class: Type
domain_name: str
def is_supported(self) -> bool:
return super().is_supported() and hasattr(self.app.builder, "domain_indices")
def run(self, **kwargs: Any) -> None:
domain_indices = getattr(self.app.builder, "domain_indices", [])
# Find the domain index we are rebuilding
index_number = 0
for index_name, index_class, original_entries_for_char, collapse in domain_indices:
if index_class == self.index_class:
break
index_number += 1
else:
return
index = index_class(self.env.domains[self.domain_name])
# Generate again the index
regenerated, _ = index.generate()
# Use a dict instead of list of tuples expected
new_entries_for_char = defaultdict(list, regenerated)
# Merge with entries not in this docname
for character, entries in original_entries_for_char:
new_entries = []
for entry in entries:
if self.env.docname != entry.docname:
new_entries.append(entry)
new_entries_for_char[character].extend(new_entries)
def key(character_entries):
# sub index items have their own display name
# ignore it in the sorting
character, entries = character_entries
return (character, [entry for entry in entries if entry.subtype in (0,1)])
# Change the dict into the sorted list of tuples expected
resorted = sorted(new_entries_for_char.items(), key=key)
# Replace the regenerated index
domain_indices[index_number] = (
index_name,
index_class,
resorted,
collapse
)
Sadly, it generates the whole index for each document. This would not be required if I could know that we are post-transforming the last document, or if there was an event that happens just before writing or something.
Here is the result
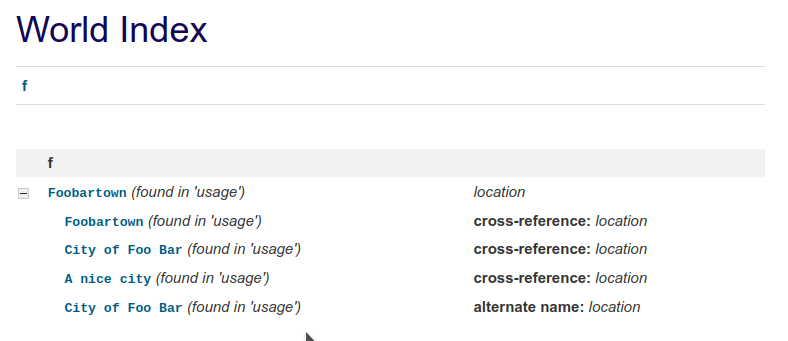
Here is the result
In this case
- location objects can have multiple names (directives arguments),
- whereas the first one is a "primary name". Imagine having "New York City" which is also called "The Big Apple".
- The entry `A nice city` is a cross-reference with an explicit title, say :world:location:`A nice city <Foobartown>`.
Reply all
Reply to author
Forward
0 new messages