Labeling layer

Martin Sustrik
Here are some initial thoughts on the requirements for labeling layer:
Any at least slightly complex messaging system needs a way to annotate
the messages. The annotations are then used to route the messages to
correct destinations. These annotations are often referred to as
"message envelope".
The term "label" is borrowed from MPLS (RFC3032) and is used to refer to
a single annotation attached to the message.
Example: JMS uses "ReplyTo" field of the message to specify the
application that is supposed to receive the reply in the request/reply
pattern. Another example would be "CorrelationID" field of the message
that contains unique ID of the request, so that requester could pair
replies with requests. Both these fields can be thought of as labels.
However, as SP is meant to support a broader, open-ended set of
messaging patterns, the labeling layer won't do with specific hard-wired
labels like "ReplyTo" or "CorrelationID". It should rather define a
generic pattern-agnostic method for annotating messages. Specifications
of different messaging patterns can then define specific labels along
with their semantics.
Given that the labels have no associated semantics at this layer, the
labels should be as generic as possible, presumably meaning that a label
should be a simple sequence of bytes.
It's not clear at the moment whether label should be fix-sized or
variable-sized. MPLS, for example, uses 32 bit labels which are great
for HW processing. In the case of SP it is not obvious whether 32-bit
labels (or any fix-sized labels, for what it's worth) would be
sufficient for all the messaging patterns and whether some patterns
won't be forced to split longer labels into multiple 32-bit
pseudo-labels to hack their way around the limitation.
It should be possible to attach unlimited number of labels to a single
message. The rationale is that in the case of N-hop message transfer,
each intermediate node may need a label of its own to correctly route
the message thus resulting in N-1 labels attached to the message.
Limiting the number of labels would prevent messages to be passed on the
paths with more than N hops.
Note: The above argument assumes that routing information is stored in
the messages and that the nodes are stateless. The alternative -- one
that IP uses -- is to store routing tables in nodes and do with a single
"address" label in the message. Discussing the pros and cons of the two
designs would require a paper of its own, however, at this point let's
only note that "statefull message and steless node" approach was choosen
for SP because the other option assumes more or less stable topologies
and limited number of entities the node has to keep track of. In SP
where the primary entity is message rather than connection or even host,
the routing tables at nodes would have to be too large and change too
rapidly (think of millions messages per second) for it to make sense.
The labels should form an atomic unit with the message itself. It
doesn't make sense to receive a label without a corresponding message or
vice versa. This requirement seems to indicate that message with all the
attached labels should form a single frame (framing layer guarantees
atomicty, see the framing I-D). The alternative option would be to move
the atomicity requirement from framing layer to labeling layer.
Finally, it should be as easy to process the labels as possible,
presumably in such a way that wire speed routing is possible. There are
couple of issues to take into consideration here:
1. The labels should be fixed size and/or relatively small (as discussed
above)
2. Adding and removing labels should be a simple operation, preferably
not requiring any change to the message content itself.
3. The labels should precede the message so that they can be processed
before the processing of the message itself is even started. The reason
is that labels control routing. With labels in front of the message,
intermediate node can choose the destination for the message first and
then stream the body of the message to that peer. If the labels were
following the message, the intermediary would have to store the entire
message, then check the labels and decide on the destination, then
finally send the stored message to the destination.
4. The labels that will be processed first should come before those that
will br processed later. The idea is that often, after processing a
label, you can drop it from the message thus getting the next label to
the front for further processing. MPLS treats the labels this way,
effectively creating a stack of labels.
Thoughts? Comments?
Martin

Paul Colomiets
>
> Thoughts? Comments?
Should labels be used only for routing?
Does we need to differentiate kind of label? E.g. system may want to have a
stack of labels to forward message to (dropping a message at a time),
and a stack of labels for reply channel (adding a message at a time).
Obviosly it can be built into application itself by prefixing label, but may
be it's worth to integrate into basic protocol.
--
Paul
Martin Sustrik
>> Thoughts? Comments?
>
> Should labels be used only for routing?
>
> Does we need to differentiate kind of label? E.g. system may want to have a
> stack of labels to forward message to (dropping a message at a time),
> and a stack of labels for reply channel (adding a message at a time).
> Obviosly it can be built into application itself by prefixing label, but may
> be it's worth to integrate into basic protocol.
Obviously, labels can be differentiated. However, at the generic
labeling layer there are no semantics defined. Labels are just opaque
sequences of bytes attached to a message. Thus, there's no way to define
specific label types at that level -- given that the set of messaging
patterns is meant to be open-ended you don't even know what types of
labels will be needed in the future.
Types of labels can be instead defined within the specific messaging
patern. Say, if you were to define JMSQueue pattern (as an underlying
protocol for JMS Queues) you could define ReplyTo label and
CorrelationID label.
Does that make sense?
Martin
Martin Sustrik
> Here are some initial thoughts on the requirements for labeling layer:
More thoughts:
1. How to delimit the label stack? How does the a node processing a
message know where the label stack ends and message content begins?
a. If we can guarantee that the labels are alway processed by pairs of
nodes, one generating a label, other one consuming it, there's no need
for explicit bottom-of-the-stack delimitation. When the message arrives
at the destination all the labels were already consumed and what remains
is the message content.
b. Label con contain "bottom-of-the-stack" flag (as MPLS labels do). The
advantage of this approach is that there's no need to modify the message
body in any way. Everything following the bottom-of-the stack label is
the unmodified message body.
c. Finally, each item (either label or message body) can contain a flag
specifying whether it's a label or a body. The advantage is that this
system can easily cope with additional types, e.g. commands.
2. How to encode commands? Command are entities passed between SP
endpoints which have no user content.
a. If commands can be guaranteed to never intermix with messages,
there's no problem to solve. However, is it possible? Are there patterns
that require commands to be passed at an exact point of the message
sequence, meaning that they can't be passed on a different channel?
b. Adopt the system described in pt c. above. Assign special type for
commands.
c. Don't deal with commands on labeling layer. Let the message pattern
distinguish the messages from the commands. It's not clear whether this
option solves anything or just pushes the problem to the higher layer...
d. Command can be a message without a body. If so, would it be possible
to send an 0-byte long message? (Note: SCTP does not allow for 0-byte
messages.)
Martin

Kohei Honda
--
Note Well: This discussion group is meant to become an IETF working group in the future. Thus, the posts to this discussion should comply with IETF contribution policy as explained here: http://www.ietf.org/about/note-well.html
Kohei Honda
Kohei Honda
Paul Colomiets
> d. Command can be a message without a body. If so, would it be possible to
> send an 0-byte long message? (Note: SCTP does not allow for 0-byte
> messages.)
Zero-length message should not be a problem, as you want either a 0-byte
message and label(s) or longer message.
Overall I think flag on each item either label or body is good. Also I think
there are several flags on labels:
1a. Message should be forwarded even if label type is not known to intermediary
1b. Message should be rejected if label type is not known to intermediary
2a. Label should be dropped before forwarding (maybe extend this to:
all labels of
this kind should be dropped vs first label of this type should be dropped)
2b. Label should be kept before forwarding
3. Label is a command (?)
That's why I want type of label to be somehow part of protocol. These
flags can be first few bits of type field, and type could have range of
values for well-known label types, and a range for site specific ones.
--
Paul
Martin Sustrik
Thanks for the insightful comments! See my comments inlined.
> the idea is called encapsulation and de-multiplexing. It is when you
> move down one-level in the stacks, that you do a labelling, remembering
> the higher-level stack you were in --- which means the destination
> "higher" layer. When the message arrives, you go up the stack (up-call),
> and at that time you use the recorded information.
>
> So when you are TCP, you make an IP packet saying it is TCP. Then the
> receiving IP stack can "route" the packet to the TCP stack, rather than
> say the UDP stack, hence TCP can take care of it. In turn, the TCP port
> number is remembered in the TCP header, so that it can be routed
> "upwards" to the application in question.
>
> I explained this obvious, since I wish to emphasise that, in this
> classical setting, the labelling is not the function of a specific
> layer, but the function of all layers (except the link layer since it
> does not have a lower layer).
Yes.
One special issue to take into consideration is that such "labels" are
either embedded in the payload of the underlying layer (TCP ports
embedded in the IP datagram), or they are attached to the message of the
layer on top (MPLS attaching labels to an IP datagram).
While both TCP and MPLS are meant to add certain capabilities to the IP,
the former can be though of as living "on the top" of IP, while the
latter is living "underneath" the IP.
I have yet no clear idea what the full implications of either design
are, but what I can tell from the practical experience at the moment is
that MPLS-style design ("underneath") is generally more efficient that
TCP-style design ("on top").
Here's an concrete example: Let's consider SCTP framing so that we don't
have to mess with details of message delimitation. In TCP style design
(labeling on top of framing) the labels would be contained in SCTP messages:
+--------+--------+---------+--------+--------+---------+
| label2 | label1 | payload | label2 | label1 | payload |
+--------+--------+---------+--------+--------+---------+
| SCTP message 1 | SCTP message 2 |
+---------------------------+---------------------------+
In MPLS style design (labeling underneath the framing, the binary layout
would look like this:
+--------+--------+---------+--------+--------+---------+
| label2 | label1 | payload | label2 | label1 | payload |
+--------+--------+---------+--------+--------+---------+
| SCTP 1 | SCTP 2 | SCTP 3 | SCTP 4 | SCTP 5 | SCTP 6 |
+--------+--------+---------+--------+--------+---------+
> In MPLS, it is interesting, since a label is used for specifying the
> horizontal route: it is about how you traverse MPLS-enabled routers,
> more than how you go up in the local stacks. Martin noted this is
> "stateless", but this is not exactly true (though I understand Martin's
> direction), since each MPLS node should have a local routing table which
> links each label to the "next hop". This information needs be maintained
> across MPLS-enabled routers.
Oops. I haven't tries to suggest that MPLS is stateless. It's not. What
I was trying to say was that we can possibly adopt MPLS concept of
"stack of labels" *and* that SP should presumably have stateless nodes.
Let me give an example of stateless vs. statefull design.
Let's imaging a request/reply scenario. One of the requirements here is
that reply is delivered to the client that issued the original request.
Let's also imagine we have a classic star topology as in AMQP.
The stateless approach (as adopted by AMQP) is to label the request
request with ReplyTo field. When the request gets to the service it
copies the ReplyTo field to the reply and broker uses the field to route
the reply back to the original requester. Note that there's no
per-message state stored in the broker. All the relevant info is stored
in the message itself.
The stefull approach would be to label the request with RequestID. The
broker, when passing the request to the particular instance of the
service would remember the RequestID->ClientID mapping. Service would
generate the reply and copy the RequestID into it. The broker would
check it's mappings to find out which client corresponds to the
RequestID and send the reply to that client.
While the two approaches may seem similar (it's just one label in both
cases, right?) the difference becomes obvious if there are more
intermediary nodes on the path from the client to the service.
In "stateless" approach there has to be a label added to the request at
each intermediary node, resulting in stack of lables. As reply traverses
back to the client, the labels are popped one-by-one from the stack by
intermediary nodes. When the reply arrives back at the client, there are
no more labels attached to it.
In the "statefull" approach, there's only one label (RequestID) attached
to the message during its whole lifetime. The per-message routing info
(RequestID->next hop) is instead stored at the nodes.
I was arguing for the stateless design because:
1. With high message load and long request processing times,
intermediary nodes would quickly run out of memory.
2. It's the design used by most existing messaging systems anyway.
> From here, we go into Martin's initiative. Can we have a generic way to
> "label" messages in SP? What would be the shape of it?
>
> Martin assumed a direction that we wish to make the routers as stateless
> as possible. I believe that, by this, he meant the following situation:
>
> "by looking at a label or a vector/set of labels, a local
> stack can decide what to do immediately, without
> having a non-trivial routing protocol such as OSPF."
Yes. As exemplified above.
> From the preceding discussions, it looks we are assuming the existence
> of a SP layer already. In the SP layer, we wish to go up one level, to
> reach an application. So within the SP layer, we wish to have this
> labelling layer, like putting the keywords. I hope this understanding is
> correct, if not, Martin, please correct me.
Yes. The idea of keywords summarises it nicely. One difference to keep
in mind though is that keywords are meaningful to the end user (they are
part of application logic) while labels are opaque, used only for
routing and possibly even invisible to the end user.
Martin
Martin Sustrik
> First, reflecting on my background discussions, as well as the practice
> of messaging as Martin noted, one notable point of the labelling layer
> of SP looks that the set of labels associated with a message can have
> two functions:
>
> (1) at an endpoint, this field may decide how a message is delivered
> upwards to an application.
> (2) at a SP-enabled router (or intermediaries in general), it may decide
> the "next hop(s)".
Yes. Let me give an example:
Let's say that request/reply pattern handler reliability by resending
the request if the reply doesn't arrive within a specified timeout.
Of course, then there's a problem that delayed reply for a previous
request may arrive when the next and unrelated request is already being
processed. The pattern needs a way to distinguish the old reply from the
valid reply. One way to do this is for the client to label the request
by some kind of request ID, so that it can check the reply whether it
contains the request ID of the request being processed at the moment and
drop any replies that don't match.
Note that this label makes sense only for the endpoint, Kohei's point (1).
At the same time intermediary nodes need some kind of labels to know
which peer to route the reply to as discussed in the previous email.
These labels only make sense for intermediaries corresponding to the
point (2).
> On the other hand, it is also true that, generally, having a category of
> labels be treated with a fixed semantics and mechanisms would make the
> design and executions w.r.t. (1) and (2) well-organised, allowing
> experiments, and making performance predictable, hence as a whole giving
> a potential basis for scalability. Of course, only if we have a good
> category of labels for this!
The question is whether the set of label categories is fixed or open-ended.
I would argue for the latter.
Let's take an example of a tunnel. We may want to take several
topologies and funnell all the messages through a single TCP connection
(say when passing firewalls or similar scenarios).
One end of the tunnel would take a message, label it with a topology ID
and send it through. The other end would retrieve a message from the
tunnel check the topology ID, decide which topology should the message
be forwarder to, drop the label and forward the message.
If the message is a request or reply (as described above) it now
contains 3 different label categories:
1. Request ID (to be processed by the endpoint)
2. Routeback stack (so that reply can be passed to the original requester)
3. Topology ID (so that it can be correctly de-multiplexed on the other
end of the tunnel).
My feeling is that you can think of arbitrary number of such mechanisms,
which would, make the number of different label categories unlimited.
Thus, if we wanted to place label category IDs to the labels, we would
have to create a registry of label category IDs in IANA, which in turn
would make addition of new mechanisms to the protocol administratively
complex (applying for ID with IANA etc.) and would hinder
experimentation and innovation.
> Apart from this consideration, it may be worth doing to enumerate
> typical ways we may use labels. Perhaps it is worth enumerating them, as
> well as illustrating how they are used at the endpoint (1) and at
> intermediaries (2). This will give us a good basis for discussions on
> the design of labelling functions. I also think it can shed light on the
> general dynamics associated with SP.
Yes. I hope we'll get to actual patterns shortly. Each pattern would
then define what kinds of labels it uses.
Btw, I don't think we have to make the labeling design perfect at the
moment. Let's rather make it as simple as possible, and if it turns out
it's insufficient in the future, we can enhance it then.
Martin
Martin Sustrik
> Zero-length message should not be a problem, as you want either a 0-byte
> message and label(s) or longer message.
Unless we decide to adopt MPLS-style system of prefixing unmodfied
message by separately-framed labels. Conisder following framing/labeling:
+------+-----------+-------+------+------------+-------+------+------+
| size | more-flag | label | size | !more-flag | label | size | body |
+------+-----------+-------+------+------------+-------+------+------+
| label 1 | label 2 | message |
> 1a. Message should be forwarded even if label type is not known to intermediary
> 1b. Message should be rejected if label type is not known to intermediary
> 2a. Label should be dropped before forwarding (maybe extend this to:
> all labels of
> this kind should be dropped vs first label of this type should be dropped)
> 2b. Label should be kept before forwarding
What's the use case?
The ugly part here is that implementing such behaviour would require
traversing the complete label stack at each intermediary node, which
does not match well with wire-speed processing.
> 3. Label is a command (?)
Yes. Commands are a problem. However, command=label is not the only
available solution. More thinking needed...
> That's why I want type of label to be somehow part of protocol. These
> flags can be first few bits of type field, and type could have range of
> values for well-known label types, and a range for site specific ones.
Martin
Paul Colomiets
On Tue, Aug 23, 2011 at 1:40 PM, Martin Sustrik <sus...@250bpm.com> wrote:
> Hi Paul,
>
>> Zero-length message should not be a problem, as you want either a 0-byte
>> message and label(s) or longer message.
>
> Unless we decide to adopt MPLS-style system of prefixing unmodfied message
> by separately-framed labels. Conisder following framing/labeling:
>
> +------+-----------+-------+------+------------+-------+------+------+
> | size | more-flag | label | size | !more-flag | label | size | body |
> +------+-----------+-------+------+------------+-------+------+------+
> | label 1 | label 2 | message |
>
As long as all this stack is single sctp message, its not a problem
for message part to be 0-byte.
>> 1a. Message should be forwarded even if label type is not known to
>> intermediary
Usually addition of another label type should not break intermediaries.
>> 1b. Message should be rejected if label type is not known to intermediary
Sometimes label means: this message is new kind of command. So it
should not be forwarded. Also it can mean content is gzipped, but you
must ungzip it before forwarding. It may say the following labels are
of request-reply pattern version 2.0, so you should not treat them as
old-style labels.
>> 2a. Label should be dropped before forwarding (maybe extend this to:
>> all labels of
>> this kind should be dropped vs first label of this type should be dropped)
This is something like zeromq uses for reply in request-reply pattern.
You may need forward path to send request to, not only reply-to
labels. But ok, it's known and will probably hardcoded for this
pattern. But what if at some point in time you want to add priority of
request(reply) at each intermediate. So you adding a pair of labels,
address and priority, with priority being a new label type. Then if
some intermediate doesn't understand priority it can queue message as
normal, but it whould be better if corresponding label would be popped
from the stack, so they wount be shifted for the next intermediaries.
>> 2b. Label should be kept before forwarding
As with above you may want to keep labels while forwarding request, so
that reply can use this label at the backwards route. (This comes from
experience of writing custom zeromq devices). Also most new label
types would be kept.
> What's the use case?
Described one by one. Overall, the systems using this protocol will
grow, and it's impossible to upgrade all devices and endpoints at once
in big installation. So some mechanisms of forward compatibility
should exists.
> The ugly part here is that implementing such behaviour would require
> traversing the complete label stack at each intermediary node, which does
> not match well with wire-speed processing.
>
Yes, that the sad part. But having current zeromq architecture in
mind, it's not a problem. Having command as a label, needs traversing
anyway. Also for small messages it should not be a problem, since
whole message will probably be in cpu cache. For big messages, I don't
think the label part would be big, but the message part. So you are
limited by the network when streaming message body anyway. It's more
of a problem for a hardware processing, but we don't have strong
evidence if hardware can be intermediary for us.
>> 3. Label is a command (?)
>
> Yes. Commands are a problem. However, command=label is not the only
> available solution. More thinking needed...
>
It's fun for commands be labels. It means we can batch commands (like
forwarding initial subscriptions in pub-sub). For not traversing whole
message to find command may be the whole message(envelope?) flag
needed.
--
Paul
Martin Sustrik
>> What's the use case?
>
> Described one by one. Overall, the systems using this protocol will
> grow, and it's impossible to upgrade all devices and endpoints at once
> in big installation. So some mechanisms of forward compatibility
> should exists.
Ok. I am with you on this one. (Actually I make same argument when
arguing for subscription as end-to-end functionality with subscription
forwarding viewed as an optional optimisation in the intermediaries. I'm
just writing the analysis, will publish it shortly.)
However, what's going on here is not a triffle. It boils down to whether
we can do wire-speed processing of messages or not...
>> The ugly part here is that implementing such behaviour would require
>> traversing the complete label stack at each intermediary node, which does
>> not match well with wire-speed processing.
>>
> Yes, that the sad part. But having current zeromq architecture in
> mind, it's not a problem. Having command as a label, needs traversing
> anyway. Also for small messages it should not be a problem, since
> whole message will probably be in cpu cache. For big messages, I don't
> think the label part would be big, but the message part. So you are
> limited by the network when streaming message body anyway. It's more
> of a problem for a hardware processing, but we don't have strong
> evidence if hardware can be intermediary for us.
I, personally, strongly believe that hardware should be allowed to be an
intermediary. If we deliberately reject the option, we effictively rule
out the largest-scale deployments where messages are passed at the wire
speed through the high-load backbones. While this scenario may seem too
far-fetched, if we mess it today, it will never materialise. Ever.
By the way, taking the existing thriving FPGA ecosystem into
consideration, creating a hardware device is not as big a problem as it
used to be in the past. Even better, with emerging initiatives like
OpenFlow (thanks to Gary Berger for introducing it to this group) we
have a way to programatically control network switches and experiment
with "hardware" solutions even without messing with real iron.
As for technical details (HW experts will correct me if I'm wrong) we
need an underlying transport that systematically aligns the messages
with the networks packets. It can be DCCP, SCTP or even IPv6 which
doesn't allow for packet re-fragmentation, hell, even IPv4 with the DF
bit set, if that's at all possible.
The hardware device gets a packet, checks a fixed sized chunk at its
beginning, say IP header, DCCP header and SP header and does a
routing/processing decision based on the data therein, then forwards the
packet.
That's why I'm saying that "the labels that will be processed first
should come before those that will be processed later" and even
speculate about fixed-sized labels.
So, the idea is that the HW device can check only the first label in the
label stack, do a routing decision and forward the message with the
first label stripped off. The same can happen at the next intermediary etc.
Anyway. The question is whether we can address the scenarios you've
mentioned without sacrificing the HW-friendliness of the wire format.
There are two basic use cases AFAICS.
The first is using pattern-agnostic devices for compression, encryption,
multiplexing and alike. The goal here is to make these devices work as
expected with any possible pattern, without requiring the device to know
anything about those patterns.
The important point here is that these devices are always deployed in
pairs: compression/expansion, encryption/decryption, mux/demux etc.
Therefore, I believe there's no real problem with that. If a message is
to be passed via an encrypted tunnel, the encryption device doesn't care
about the message content or labels, it simply encrypts it at one side
of the tunnel and pass it to the other side which decrypts it. No label
checking needed.
More complex example: Multiplexing several feeds, each possibly being a
different pattern. In this case multiplexer gets a message from one of
the input topologies, doesn't even look at its label stack and adds a
label containing the topology ID. When the message is received on the
other side of the tunnel is simply gets the topology ID, strips the
label off and routes the message to the particular topology. Once again,
no checking of label stack needed.
The second use case is extending the existing patterns by allowing for
new labels/commands, This is a more complex topic, however, the
argumentation above still applies. If there's a label passed on wire
there's a node that creates the label and a node that consumes the
label. So you have 2 nodes that have to implement the same protocol
version. If they don't the desired functionality won't work anyway. All
the intermediary nodes can implement any version of the protocol as all
what they do is forwarding the message along with any the labels they
don't use themselves.
Note that this pair of nodes can actually collapse into a single node:
In request reply scenrio the intermediary (broker) tags the message with
the client ID, then uses client ID in the reply to route it to the
correct client. The node that produces the label is the same node that
consumes it.
The real problem emerges if a particular label is intended not for a
single pair of nodes, but for all the nodes on the path.
It would be interesting to discuss this scenario in detail, however, we
need concrete use cases here. At the moment I think I have no realistic
use case, feel free to propose one...
In any case, if we decide that every label is produced by exactly one
node and consumed by exactly one node, the extensibility problem is
solved and there's no need for label IDs/flags, traversing the label
stack at each intermediary etc. That, in turn, would make the protocol
friedly to wire-speed processing.
(Oh god, what a rant! Congratulations if you have got this far!)
Martin
Martin Sustrik
> The real problem emerges if a particular label is intended not for a
> single pair of nodes, but for all the nodes on the path.
>
> It would be interesting to discuss this scenario in detail, however, we
> need concrete use cases here. At the moment I think I have no realistic
> use case, feel free to propose one...
Ok, I've think I've found one. Let's say there's a loop detection
mechanism built into the protocol, the same used by IP: If a message is
forwarded more than N times without reaching the destination, it is dropped.
This requires a TTL field, that would be decremented at each intermediary.
How would we encode that?
Here's an idea: What about separating the "generic properties" that can
be touched by any node and "pair-node" properties that are produced by
one node and consumed by another node.
The former could be encoded as standard message header (TTL at al.)
The latter can be encoded as a label stack.
The header precedes the label stack:
+--------+--------+---------+---------+---------+
| header | label1 | label 2 | label 3 | content |
+--------+--------+---------+---------+---------+
The nice thing about the above design is that it can be still processed
at the wire speed. The node checks the header and first label and does
routing decision based on that. There's no need for label stack traversal.
Martin

Tony Garnock-Jones
Here's an idea: What about separating the "generic properties" that can be touched by any node and "pair-node" properties that are produced by one node and consumed by another node.
I *strongly* recommend reading John Day's book :-)
This feels like an encoding of the nested/recursive network structure Day discusses. Rather than considering a fixed division, it might be worthwhile to think in terms of an (infinite) tower of networks, each a substrate for the next, with the application network at the top of the stack. Seen from one level, the "generic properties" look like "pair-node" properties, and the "pair-node" properties are not visible; seen from the next level up, the "generic properties" are not visible, and the "pair-node" properties look like "generic properties". There's a level-shifting relativity principle at work, basically.
Lots of university libraries have a copy of the book, BTW, and it doesn't take too long to get the gist of the argument. It's John Day, "Patterns in Network Architecture: A Return to Fundamentals", Pearson Education, 2007, ISBN 0-13-225242-2.
Regards,
Tony
Martin Sustrik
> I *strongly* recommend reading John Day's book :-)
I definitely have to do so. Unfortunately the libraries here in
Bratislava have no copy of the book. I have to order one from Amazon.
Martin
Paul Colomiets
> The hardware device gets a packet, checks a fixed sized chunk at its
> beginning, say IP header, DCCP header and SP header and does a
> routing/processing decision based on the data therein, then forwards the
> packet.
>
So each packet must have full stack of labels? Then let's just build on
top of UDP. In TCP we can't do that. Am I missing something here?
> That's why I'm saying that "the labels that will be processed first should
> come before those that will be processed later" and even speculate about
> fixed-sized labels.
>
Sorry, but it's too simplified to be applied to wide range of tasks.
>The header precedes the label stack:
>
>+--------+--------+---------+---------+---------+
>| header | label1 | label 2 | label 3 | content |
>+--------+--------+---------+---------+---------+
So you just invented a new kind of label. That label sticks on top.
It's not going to be fixed header. Almost nobody needs TTL, only
rare poor souls :) Another sticky field is definitely a priority. And
then how TTL and Priority should be aligned? I'm sure a lot of
other cases will be invented.
>The important point here is that these devices are always
>deployed in pairs: compression/expansion,
>encryption/decryption, mux/demux etc.
That's not true in generic case. Consider you have two redundant
brokers which split work between workers. When you upgrade
one broker, and some of the workers(so that others still work,
if upgrade went bad), you may want announcements of new
workers be discarded at the old broker, because they can't
process requests anyway (for some other reasons).
Another example is pubsub. Imagine you always distributed
exchange rates as "USD-EUR:1.2345" then after a few years
you adding another kind of data: bids on forex. So you have
two options: add a label, or add a text. In the former case your
customers can ignore label and treat bids as exchange rates.
In the latter case you probably now distribute a message like:
"BID:USD-EUR:1.234". And your customers can think that
its exchange rate of "BID:USD" vs "EUR" or "BID" vs "USD-EUR"
depending on robustness of their parser :)
The problem with the latter case of course with early
design decisions of the application. But labels seem to be
the obvious way to provide such kind of extensibility.
Returning to the topic. For pub/sub you're defining intermediates
that don't do filtering and others' that do the job. May be it's
reasonable to have similar description for others? Anyway I don't
believe there are devices, that can do load balancing for me. Or
ones can retry a request at another worker, etc.
Also your use-case of stripping one label at the start, and treating
it as a next hop, is the only one use case of a label. And it works
at a hardware well: just send to a correct IP address and it will
be forwarded throught as many hops as needed.
--
Paul
Martin Sustrik
> On Wed, Aug 24, 2011 at 11:00 PM, Martin Sustrik<sus...@250bpm.com> wrote:
>> The hardware device gets a packet, checks a fixed sized chunk at its
>> beginning, say IP header, DCCP header and SP header and does a
>> routing/processing decision based on the data therein, then forwards the
>> packet.
>>
> So each packet must have full stack of labels? Then let's just build on
> top of UDP. In TCP we can't do that. Am I missing something here?
You mean you can't control the packet fragmentation in TCP, right? True,
but is there any point in using different labeling formats for different
transports? If we have a lableing that would work for UDP why not use it
for TCP as well. It would definitely make implementing the thing simpler.
Additionally, DPI can inspect TCP packets and if the format is
HW-friendly it won't definitely hurt.
>> That's why I'm saying that "the labels that will be processed first should
>> come before those that will be processed later" and even speculate about
>> fixed-sized labels.
>>
>
> Sorry, but it's too simplified to be applied to wide range of tasks.
>
>> The header precedes the label stack:
>>
>> +--------+--------+---------+---------+---------+
>> | header | label1 | label 2 | label 3 | content |
>> +--------+--------+---------+---------+---------+
>
> So you just invented a new kind of label. That label sticks on top.
> It's not going to be fixed header. Almost nobody needs TTL, only
> rare poor souls :) Another sticky field is definitely a priority. And
> then how TTL and Priority should be aligned? I'm sure a lot of
> other cases will be invented.
I would argue that priority should *not* be part of the message header,
rather it should be set on per-feed basis. The reason is that even if
you do put it into the header, the priority setting will be ignored by
lower layers of the stack, eg. a low-priority message could block a
high-priority message when both are passed via a single TCP connection.
What you need is to separate the feeds, use two connections, presumably
two different ports, then set the network infrastructure to apply
particular QoS on each feed etc.
If the above logic is accepted we are back to the original question:
what are the properties that have to be inspected at each intermediary
node? We need use cases.
>> The important point here is that these devices are always
>> deployed in pairs: compression/expansion,
>> encryption/decryption, mux/demux etc.
>
> That's not true in generic case. Consider you have two redundant
> brokers which split work between workers. When you upgrade
> one broker, and some of the workers(so that others still work,
> if upgrade went bad), you may want announcements of new
> workers be discarded at the old broker, because they can't
> process requests anyway (for some other reasons).
Not sure about this. Forward compatibility is a tricky problem. You
don't know in advance what changes will be necessary in the future and
thus adding random extension points or overly generic abstraction
mechanisms is often doing more hurt than good.
Been there, seen it. The result is normally on overbloated protocol with
little appeal to developers, with extension hooks that are never used
and with the need to do backward-incompatible changes when a new and
unexpected requirement pops up anyway.
What we need at the moment is the broadest possible spectrum concrete
use cases. We can design to accomodate that and hope that the variety of
use cases elicits versatility needed to make the protocol future-proof.
> Another example is pubsub. Imagine you always distributed
> exchange rates as "USD-EUR:1.2345" then after a few years
> you adding another kind of data: bids on forex. So you have
> two options: add a label, or add a text. In the former case your
> customers can ignore label and treat bids as exchange rates.
> In the latter case you probably now distribute a message like:
> "BID:USD-EUR:1.234". And your customers can think that
> its exchange rate of "BID:USD" vs "EUR" or "BID" vs "USD-EUR"
> depending on robustness of their parser :)
>
> The problem with the latter case of course with early
> design decisions of the application. But labels seem to be
> the obvious way to provide such kind of extensibility.
There's SP layer and there's application layer. If you need an extension
mechanism on the application level, implement it there, don't drag it to
SP layer. Imagine if TCP allowed for used messing with it's packet format :(
The rule of the thumb: Labels are an SP-level entity and are invisible
to applications.
> Returning to the topic. For pub/sub you're defining intermediates
> that don't do filtering and others' that do the job. May be it's
> reasonable to have similar description for others?
Sure. If you have an idea how to do that for other patterns, do propose
it. The important thing is to have a clear idea of how the pattern would
work when faced with unknown extension to the protocol and that new
extensions won't break the semantics of the pattern.
For example, adding new matching algorithms works like this: If
subscription of unknown type is received from the downstream node,
forward it to the upstream node and tag the downstream node to receive
*all* the messages. Given that filtering is done on the subscriber edge
(the node that issued the subscription and knows the associated
filtering algorithm) non-matching messages are always filtered out at
the last hop and never delivered to the end user. So, having the
intermediaries which don't understand the subscription will never change
the semantics, it will only make the topology less bandwidth-efficient.
> Also your use-case of stripping one label at the start, and treating
> it as a next hop, is the only one use case of a label.
Sure, feel free to document the other use cases. Take care not to mix
the application logic and SP logic though.
> And it works
> at a hardware well: just send to a correct IP address and it will
> be forwarded throught as many hops as needed.
See the discussion of the statelessness from last week. The problem with
IP-style routing is that it works on relatively stable, not frequently
changed topologies meaning that routing tables can of a reasonable size
can be stored at nodes and not change too much to become a bottleneck.
Once you consider a routing table entry per message, the system would
become unviable. Imagine storing 1M routing entries per second etc.
Martin
Paul Colomiets
On Sat, Aug 27, 2011 at 9:59 AM, Martin Sustrik <sus...@250bpm.com> wrote:
> Hi Paul,
>
>> On Wed, Aug 24, 2011 at 11:00 PM, Martin Sustrik<sus...@250bpm.com>
>> wrote:
>>>
>>> The hardware device gets a packet, checks a fixed sized chunk at its
>>> beginning, say IP header, DCCP header and SP header and does a
>>> routing/processing decision based on the data therein, then forwards the
>>> packet.
>>>
>> So each packet must have full stack of labels? Then let's just build on
>> top of UDP. In TCP we can't do that. Am I missing something here?
>
> You mean you can't control the packet fragmentation in TCP, right? True, but
> is there any point in using different labeling formats for different
> transports? If we have a lableing that would work for UDP why not use it for
> TCP as well. It would definitely make implementing the thing simpler.
>
Makes sense.
> I would argue that priority should *not* be part of the message header,
> rather it should be set on per-feed basis. The reason is that even if you do
> put it into the header, the priority setting will be ignored by lower layers
> of the stack, eg. a low-priority message could block a high-priority message
> when both are passed via a single TCP connection. What you need is to
> separate the feeds, use two connections, presumably two different ports,
> then set the network infrastructure to apply particular QoS on each feed
> etc.
>
This leads to having a duplicate topology for just sending seldom priority
messages (they are definitely seldom, because otherwise they would
not be a priority messages). It's viable or not depending on the context.
So I would not rule out that use case.
> There's SP layer and there's application layer. If you need an extension
> mechanism on the application level, implement it there, don't drag it to SP
> layer. Imagine if TCP allowed for used messing with it's packet format :(
>
> The rule of the thumb: Labels are an SP-level entity and are invisible to
> applications.
>
The distinction is blurry sometimes.
If you need a command for a worker to stop doing current task. Is it
command or an application-specific message? It's better be a
command because then it can clean message on the queue if it's
not processing currently (again, given 0mq architecture it's almost
impossible to implement, but it doesn't mean any implementation
should be constrained).
If you have a flush-to-disk command for queue device is it a command
or application-specific message? Sure, if you have a message broker
this is a control command, which is done on separate connection. But
if you have a distributed queue. I would argue, that it's just another
command, because a) it should be inband, so that flush occurs
just after specific message and b) it's sharing properties of a message
pattern (so quite similar to subscriptions in pub-sub in some sense)
>> Returning to the topic. For pub/sub you're defining intermediates
>> that don't do filtering and others' that do the job. May be it's
>> reasonable to have similar description for others?
>
> Sure. If you have an idea how to do that for other patterns, do propose it.
> The important thing is to have a clear idea of how the pattern would work
> when faced with unknown extension to the protocol and that new extensions
> won't break the semantics of the pattern.
>
Needs some more thinking...
>
>> And it works
>> at a hardware well: just send to a correct IP address and it will
>> be forwarded throught as many hops as needed.
>
> See the discussion of the statelessness from last week. The problem with
> IP-style routing is that it works on relatively stable, not frequently
> changed topologies meaning that routing tables can of a reasonable size can
> be stored at nodes and not change too much to become a bottleneck. Once you
> consider a routing table entry per message, the system would become
> unviable. Imagine storing 1M routing entries per second etc.
>
Even with 1M subscriptions per second, system won't work with forwarding
all subscription to an upstream. It needs nodes which do filtering
themselves and
do duplicate subscriptions optimization. And even with these optimisations it
probably needs to have duplicate nodes which handle all incoming traffic and
do not forward subscriptions (depends on nature of the topics, though). So
that point is arguable.
Even more. We have established infrastructure for limiting propagation of
network changes by using gateways an so forth. The problem is current
infrastructure can't even answer if any local IP is currently alive in a fast
way. Which is crucial for assisting in any message distribution (keeping
a list of nodes to forward message to).
I think we should discuss message patterns, and then decide how hardware
can assist each of them. E.g. for pubsub hardware can do multicast for us
(but probably not subscriptions); for request-reply and push-pull it can forward
request to any node if it knows which ones are alive (is that state viable for
hardware devices? If not, it can only route packet to specified IP and reading
labels whould not help in any way).
--
Paul
Martin Sustrik
>> I would argue that priority should *not* be part of the message header,
>> rather it should be set on per-feed basis. The reason is that even if you do
>> put it into the header, the priority setting will be ignored by lower layers
>> of the stack, eg. a low-priority message could block a high-priority message
>> when both are passed via a single TCP connection. What you need is to
>> separate the feeds, use two connections, presumably two different ports,
>> then set the network infrastructure to apply particular QoS on each feed
>> etc.
>>
> This leads to having a duplicate topology for just sending seldom priority
> messages (they are definitely seldom, because otherwise they would
> not be a priority messages). It's viable or not depending on the context.
> So I would not rule out that use case.
My point was that once they are passed via the same TCP connection, they
don't behave like priority messages. They behave like plain old standard
messages. And if it quacks like a duck...
>> There's SP layer and there's application layer. If you need an extension
>> mechanism on the application level, implement it there, don't drag it to SP
>> layer. Imagine if TCP allowed for used messing with it's packet format :(
>>
>> The rule of the thumb: Labels are an SP-level entity and are invisible to
>> applications.
>>
>
> The distinction is blurry sometimes.
True. APIs are much better for enforcing layer separation than protocols
are. We'll have to live with that.
> If you need a command for a worker to stop doing current task. Is it
> command or an application-specific message? It's better be a
> command because then it can clean message on the queue if it's
> not processing currently (again, given 0mq architecture it's almost
> impossible to implement, but it doesn't mean any implementation
> should be constrained).
Yes. This looks like a command. It contains no application data,
implements a functionality that is specific for the messaging pattern,
not for the application logic etc.
> If you have a flush-to-disk command for queue device is it a command
> or application-specific message? Sure, if you have a message broker
> this is a control command, which is done on separate connection. But
> if you have a distributed queue. I would argue, that it's just another
> command, because a) it should be inband, so that flush occurs
> just after specific message and b) it's sharing properties of a message
> pattern (so quite similar to subscriptions in pub-sub in some sense)
Yes. That's another example of a command. It contains no application
data, the functionality is specific for the pattern etc.
On the other hand, this thread have started by you referring to
forex-specific data such as BID/ASK flag. That's a nice example of an
application level enitity, ie. not a command or label.
> I think we should discuss message patterns, and then decide how hardware
> can assist each of them. E.g. for pubsub hardware can do multicast for us
> (but probably not subscriptions); for request-reply and push-pull it can forward
> request to any node if it knows which ones are alive (is that state viable for
> hardware devices? If not, it can only route packet to specified IP and reading
> labels whould not help in any way).
Yes. You've succinctly pointed out a fundamental problem with my
approach. The patterns are at the heart of SP work and framing, labeling
etc. is just a boring academic attempt to normalise some little parts of
the functionality that happens to occur in multiple patterns. I guess
premature normalisation is a root of all evil in this case.
So, I'll propose a simplified natural layering
(transport/pattern/application) in the next email. The idea being that
we can do the normalisation later on, if it is needed at all.
Martin
Paul Colomiets
On Sun, Aug 28, 2011 at 11:12 AM, Martin Sustrik <sus...@250bpm.com> wrote:
>
> Yes. That's another example of a command. It contains no application data,
> the functionality is specific for the pattern etc.
>
Ok, "no application data" is not a good criterion. If you want to flush
messages starting with prefix "something:". It's a piece of application
data.
More over, if flush is a good command between queue nodes, what's
if it will be reused between application and queue?
Even more, if you think it's a command, then you probably agree that
the whole queue is a treated as the network infrastructure. So what
the database is? Isn't the queue is just another kind of database?
> On the other hand, this thread have started by you referring to
> forex-specific data such as BID/ASK flag. That's a nice example of an
> application level enitity, ie. not a command or label.
>
May be example is not as good as it should be. So what if "bid" should
go in another queue? Then it's label. But as it's pub-sub it's not going to
be next-hop label, it can be forwarded throught many intermediaries
until reaches one, that have a separate queue for it (or one that knows
nothing about this label, and wants to discard it). Sure, now it smell like
in need another topology (even if the topology is proxied throught
existing infrastructure), but anyway it shows that distinctions is not
a clear one.
All in all, we probably should discuss this distinction more, and put a
special section describing good and bad usecases for labels and
commands. (And anyway people will misuse that thing :) )
>
> Yes. You've succinctly pointed out a fundamental problem with my approach.
> The patterns are at the heart of SP work and framing, labeling etc. is just
> a boring academic attempt to normalise some little parts of the
> functionality that happens to occur in multiple patterns. I guess premature
> normalisation is a root of all evil in this case.
>
> So, I'll propose a simplified natural layering
> (transport/pattern/application) in the next email. The idea being that we
> can do the normalisation later on, if it is needed at all.
>
Well, I'm more or less agree with layering. But my point was not to discard
labeling idea as a whole. The good thing about generic labels, is that you
can add a site-specific thing into labels without upgrading each node in the
network. The thing I want in the spec is something along the lines of:
Intermediaries MUST not reorder set of labels of the same type. Order
of the labels of different types can be arbitrary. Except
RESPONSE_ADDR MUST be first.
Intermediaries CAN read the first label only to determine next hop
address. Intermediary SHOULD reject messages having flag
REJECT_UNKNOWN_LABEL, for effeciency reasons. But endpoints
MUST NOT rely on messages to be rejected.
So that only nodes which process messages should traverse the whole
stack (they do that anyway). It doesn't play well with POP_THIS_LABEL,
flag, but it can be documented to be popped only when it's known to
intermediary. Not sure it is a good idea, though.
The important point here is that if you want to optimise some label
to be parsed at the hardware label, you must take care of ordering of
this label with respect of others, but treat others as dictionary of lists.
As long as hardware must be instructed to parse this label it doesn't
seem to be a problem. But if you software mistakenly put another
kind of label at the top, hardware should not blindly try to find node
with the name equal to e.g. request-id, but to reject message, and
probably increment apropriate error counter.
--
Paul
Martin Sustrik
>> Yes. That's another example of a command. It contains no application data,
>> the functionality is specific for the pattern etc.
>>
> Ok, "no application data" is not a good criterion. If you want to flush
> messages starting with prefix "something:". It's a piece of application
> data.
>
> More over, if flush is a good command between queue nodes, what's
> if it will be reused between application and queue?
>
> Even more, if you think it's a command, then you probably agree that
> the whole queue is a treated as the network infrastructure. So what
> the database is? Isn't the queue is just another kind of database?
Hm, I think I don't get the argument. Can you elaborate?
>> On the other hand, this thread have started by you referring to
>> forex-specific data such as BID/ASK flag. That's a nice example of an
>> application level enitity, ie. not a command or label.
>>
> May be example is not as good as it should be. So what if "bid" should
> go in another queue? Then it's label. But as it's pub-sub it's not going to
> be next-hop label, it can be forwarded throught many intermediaries
> until reaches one, that have a separate queue for it (or one that knows
> nothing about this label, and wants to discard it). Sure, now it smell like
> in need another topology (even if the topology is proxied throught
> existing infrastructure), but anyway it shows that distinctions is not
> a clear one.
>
> All in all, we probably should discuss this distinction more, and put a
> special section describing good and bad usecases for labels and
> commands.
I guess the proposal to not to discuss the labeling as a separate layer
would help here. That way we won't be tempted to do over-generalisations
and put in only the fields that are really needed by the pattern. We can
do generalisation once we have say 3-4 patterns defined.
Also, it would make sense to define at least a mock API for the
patterns. That would make it clear which features of the protocol are to
be used just by SP layer itself and which are meant to be accessible to
the user.
> (And anyway people will misuse that thing :) )
Consider this: TCP protocol allows for arbitrary splitting of the
bytestream into packets. Thus, in theory, you could use TCP packets to
delimit messages (one message per packet). However, POSIX TCP API makes
it clear that that's something you should not and actually cannot do.
So, you have a protocol feature prone to misuse, but the canonical model
of the protocol, expressed by the API, actually forces user into correct
usage patterns. At least I never heard of anyone separating L7 messages
by putting them into separate TCP packets :)
>> Yes. You've succinctly pointed out a fundamental problem with my approach.
>> The patterns are at the heart of SP work and framing, labeling etc. is just
>> a boring academic attempt to normalise some little parts of the
>> functionality that happens to occur in multiple patterns. I guess premature
>> normalisation is a root of all evil in this case.
>>
>> So, I'll propose a simplified natural layering
>> (transport/pattern/application) in the next email. The idea being that we
>> can do the normalisation later on, if it is needed at all.
>>
> Well, I'm more or less agree with layering. But my point was not to discard
> labeling idea as a whole. The good thing about generic labels, is that you
> can add a site-specific thing into labels without upgrading each node in the
> network.
Yes. However, you can do the same thing on the application level. Ie.
you can define your own application labels and leave the SP-level data
alone.
> The thing I want in the spec is something along the lines of:
>
> Intermediaries MUST not reorder set of labels of the same type. Order
> of the labels of different types can be arbitrary. Except
> RESPONSE_ADDR MUST be first.
>
> Intermediaries CAN read the first label only to determine next hop
> address. Intermediary SHOULD reject messages having flag
> REJECT_UNKNOWN_LABEL, for effeciency reasons. But endpoints
> MUST NOT rely on messages to be rejected.
>
> So that only nodes which process messages should traverse the whole
> stack (they do that anyway). It doesn't play well with POP_THIS_LABEL,
> flag, but it can be documented to be popped only when it's known to
> intermediary. Not sure it is a good idea, though.
>
> The important point here is that if you want to optimise some label
> to be parsed at the hardware label, you must take care of ordering of
> this label with respect of others, but treat others as dictionary of lists.
> As long as hardware must be instructed to parse this label it doesn't
> seem to be a problem. But if you software mistakenly put another
> kind of label at the top, hardware should not blindly try to find node
> with the name equal to e.g. request-id, but to reject message, and
> probably increment apropriate error counter.
Same thing. This is a premature generalisation. I'm not saying something
like that could not appear in the final spec, but until you get at least
3-4 patterns defined you are just guessing what features will be needed.
Let's rather postpone this discussion until we have something to work on.
And to start the work on message formats for individual patterns let me
make this suggestion:
"PUB/SUB message has no SP-specific fields. It's composed entirely of
the opaque payload."
What do you think?
Martin
Paul Colomiets
On Tue, Aug 30, 2011 at 9:19 AM, Martin Sustrik <sus...@250bpm.com> wrote:
> On 08/28/2011 01:48 PM, Paul Colomiets wrote:
>
>>> Yes. That's another example of a command. It contains no application
>>> data,
>>> the functionality is specific for the pattern etc.
>>>
>> Ok, "no application data" is not a good criterion. If you want to flush
>> messages starting with prefix "something:". It's a piece of application
>> data.
>>
>> More over, if flush is a good command between queue nodes, what's
>> if it will be reused between application and queue?
>>
>> Even more, if you think it's a command, then you probably agree that
>> the whole queue is a treated as the network infrastructure. So what
>> the database is? Isn't the queue is just another kind of database?
>
> Hm, I think I don't get the argument. Can you elaborate?
>
Sure. I assume "contains no application data" means that you split
data into "application data" and "SP-data". So application specific
code handles application data, and what I called "network infrastructure"
handles labels and so forth. So in you have granted the following
sequence of messages for handling distributed queues (square
brackets for labels, parentheses for commands and quotes for
application data):
[que1] "hello"
[que2] "world"
[que1] (flush)
Now how far is it from the following:
[db1] [set] "key1:value1"
[db1] [get] "key1"
[db1] (flush)
Smells like some weird misuse of labels and commands. But
if you have intermediaries between actual db and client,
it's fun to use labels, because it adds power to route different
dbs to different endpoints (and routing write and read requests
to different places also useful). And this kind of thing would probably
be easier to use than parsing messages at intermediary, because
parsing labels is expected to work in any (read, in some generic
implementation of) intermediary.
>> (And anyway people will misuse that thing :) )
>
> Consider this: TCP protocol allows for arbitrary splitting of the bytestream
> into packets. Thus, in theory, you could use TCP packets to delimit messages
> (one message per packet). However, POSIX TCP API makes it clear that that's
> something you should not and actually cannot do.
>
> So, you have a protocol feature prone to misuse, but the canonical model of
> the protocol, expressed by the API, actually forces user into correct usage
> patterns. At least I never heard of anyone separating L7 messages by putting
> them into separate TCP packets :)
>
I've seen a lot of code that break if packets arrive not as expected. Some
even is running in production. But, that cases are probably not counted :)
API decisions help with TCP. But it's much bigger problem for us. If API
would not expose labels and commands then you have no way to write
a broker or another device in terms of zeromq. So probably two kinds
of API should be for applications and for low level stuff., And then again:
is queue server an application or low-level stuff?
>
> Yes. However, you can do the same thing on the application level. Ie. you
> can define your own application labels and leave the SP-level data alone.
>
Sure. I can write a network protocol for my application. What I expect from SP
is widely available queues which aggregate streams by labeling messages
and sort messages by label, brokers which throws away duplicate
requests by request-id and prioritize tasks by label and so forth.
This expectation is seen throught whole this mail. Do you expecations match?
That's not a big deal from my point of view. I think we can have
e.g. labels with type 0-127 which reserved to well known patterns
and 128-255 (assuming we have one byte for type) for user-defined
usage, including application-specific ones. Why not, if its documented
for this use case? This partially solves the problem of misusing
labels.
> And to start the work on message formats for individual patterns let me make
> this suggestion:
>
> "PUB/SUB message has no SP-specific fields. It's composed entirely of the
> opaque payload."
>
> What do you think?
>
It depends.
1. Backwards pipe for subscriptions not counted here?
2. Do you think topics must always be created on the fly? (I know your
approach for pub sub is generalised one. But some implementation
can as well use topics) If not, some implementation may need a
notification (which is a command) of destroyed (and may be
created) topics.
3. I think that obvious way of aggregating several feeds to be split
later is to add label with origin feed name, don't you?
4. I have at least one use case where I don't need to forward
topic to final endpoint (which is websocket client BTW), so it's
arguable whether topic contained in a message and not a label.
It can be thought of as pub/sub intermediary with message
processor which strips topic, but not sure it's better in any way.
--
Paul
Martin Sustrik
> Sure. I assume "contains no application data" means that you split
> data into "application data" and "SP-data". So application specific
> code handles application data, and what I called "network infrastructure"
> handles labels and so forth. So in you have granted the following
> sequence of messages for handling distributed queues (square
> brackets for labels, parentheses for commands and quotes for
> application data):
>
> [que1] "hello"
> [que2] "world"
> [que1] (flush)
>
> Now how far is it from the following:
>
> [db1] [set] "key1:value1"
> [db1] [get] "key1"
> [db1] (flush)
>
> Smells like some weird misuse of labels and commands. But
> if you have intermediaries between actual db and client,
> it's fun to use labels, because it adds power to route different
> dbs to different endpoints (and routing write and read requests
> to different places also useful). And this kind of thing would probably
> be easier to use than parsing messages at intermediary, because
> parsing labels is expected to work in any (read, in some generic
> implementation of) intermediary.
Understood. There are several possibilities IMO:
1. Routing messages to/from the DB follows some well defined pattern
(like req/rep) in which case just use the pattern and there it goes.
2. The routing follows some well-defined pattern that was not defined on
SP level. Solution: create a new SP pattern. (That way you would have
access to the labeling mechanism etc.)
3. The routing is an ad hoc solution, possibly leaky, but one that would
do in the concrete use case. Solution: Implement it on the application
layer.
>>> (And anyway people will misuse that thing :) )
>>
>> Consider this: TCP protocol allows for arbitrary splitting of the bytestream
>> into packets. Thus, in theory, you could use TCP packets to delimit messages
>> (one message per packet). However, POSIX TCP API makes it clear that that's
>> something you should not and actually cannot do.
>>
>> So, you have a protocol feature prone to misuse, but the canonical model of
>> the protocol, expressed by the API, actually forces user into correct usage
>> patterns. At least I never heard of anyone separating L7 messages by putting
>> them into separate TCP packets :)
>>
>
> I've seen a lot of code that break if packets arrive not as expected. Some
> even is running in production. But, that cases are probably not counted :)
That's interesting. How do they do it? Custom TCP implementation?
> API decisions help with TCP. But it's much bigger problem for us. If API
> would not expose labels and commands then you have no way to write
> a broker or another device in terms of zeromq. So probably two kinds
> of API should be for applications and for low level stuff., And then again:
> is queue server an application or low-level stuff?
Exactly! There are definitely two layers involved here (hop-by-hop vs.
end-to-end), but so far I've deliberately refrained from addressing how
intermediaries are to be implemented, not to make the discussion too
confusing.
We'll have to discuss it though...
>> Yes. However, you can do the same thing on the application level. Ie. you
>> can define your own application labels and leave the SP-level data alone.
>>
>
> Sure. I can write a network protocol for my application. What I expect from SP
> is widely available queues which aggregate streams by labeling messages
> and sort messages by label, brokers which throws away duplicate
> requests by request-id and prioritize tasks by label and so forth.
> This expectation is seen throught whole this mail. Do you expecations match?
More or less yes. Agreed.
However, there should be clear boundary between SP and application layer.
In short: At the end-to-end level, no internal mechanisms (like labels)
should be visible.
They should be visible to SP intermediaries (hop-by-hop layer).
However, take care not to conflate SP-level intermediaries with
application layer intermediaries. The former see the labels. The latter
don't. From SP's point of view the latter are just endpoints. See the
attached diagram.
The SP intermediaries are those that do exactly the work defined by the
pattern (load-balancing, message filtering etc.)
The application-level intermediaries do things like message
transformation, computing aggreggates from business-level data etc.
> That's not a big deal from my point of view. I think we can have
> e.g. labels with type 0-127 which reserved to well known patterns
> and 128-255 (assuming we have one byte for type) for user-defined
> usage, including application-specific ones. Why not, if its documented
> for this use case? This partially solves the problem of misusing
> labels.
Allowing higher layers to use internal mechanisms of the lower layers
may look harmless. It's there, so why not use it. But it turns out that
conflating layers this way can lead to ugly consequences later. Think of
how TCP uses IP addressing instead of it's own. Now with IPv6 being
deployed, every TCP application has to jump through loops to support
IPv6 and different IPv4/IPv6 combinations. I even recall that Vint Cerf
admitted that they've erred here when they've designed the Internet stack :)
>> And to start the work on message formats for individual patterns let me make
>> this suggestion:
>>
>> "PUB/SUB message has no SP-specific fields. It's composed entirely of the
>> opaque payload."
>>
>> What do you think?
>>
>
> It depends.
>
> 1. Backwards pipe for subscriptions not counted here?
Yes. Let's focus on messages first and look at subscription commands later.
> 2. Do you think topics must always be created on the fly? (I know your
> approach for pub sub is generalised one. But some implementation
> can as well use topics) If not, some implementation may need a
> notification (which is a command) of destroyed (and may be
> created) topics.
How does the generalised approach prevent using topics?
If you use prefix-matching algorithm, the application can decide to use
say 0x01 as topic-content delimiter (think FIX) and subscribe for things
like "forex.USD.GBP\x01".
If the topic isn't placed at the beginning of the message body,
different matching algorithm can be defined (eg. regexp).
> 3. I think that obvious way of aggregating several feeds to be split
> later is to add label with origin feed name, don't you?
You are speaking of tunnelling, right? You definitely need a mux/demux
on each side, but it doesn't seem to have much to do with SP as such.
A generic tunnelling solution would work well on any kind of messages,
whether pub/sub messages, req/rep messages, SCTP messages, websocket
messages, UDP packets etc.
Thus, I would say it's a technology orthogonal to SP / layered on top of SP.
> 4. I have at least one use case where I don't need to forward
> topic to final endpoint (which is websocket client BTW), so it's
> arguable whether topic contained in a message and not a label.
> It can be thought of as pub/sub intermediary with message
> processor which strips topic, but not sure it's better in any way.
The problem is that there are often quite elaborate filters used in the
wild (x-path, SQL-like) that don't allow for clear separation of the
topic and the body.
For example, messages can look like this:
|market=forex.USD.GBP|price=2.01|amount=10|
And the filter can look like this:
SELECT * WHERE market LIKE forex.*.GBP AND amount > 100
Martin
Paul Colomiets
On Wed, Aug 31, 2011 at 1:45 PM, Martin Sustrik <sus...@250bpm.com> wrote:
> Understood. There are several possibilities IMO:
>
> 1. Routing messages to/from the DB follows some well defined pattern (like
> req/rep) in which case just use the pattern and there it goes.
>
> 2. The routing follows some well-defined pattern that was not defined on SP
> level. Solution: create a new SP pattern. (That way you would have access to
> the labeling mechanism etc.)
>
> 3. The routing is an ad hoc solution, possibly leaky, but one that would do
> in the concrete use case. Solution: Implement it on the application layer.
>
Well, probably I'm getting your vision more clear now. Looks interesting,
more thinking is needed, though.
>> I've seen a lot of code that break if packets arrive not as expected. Some
>> even is running in production. But, that cases are probably not counted :)
>
> That's interesting. How do they do it? Custom TCP implementation?
>
No they do read call, and parse only one message. And it works until they have
tens or hundreds messages per second (until messages start to be joined,
or fragmented). I've said that that code is broken?
>>
>> It depends.
>>
>> 1. Backwards pipe for subscriptions not counted here?
>
> Yes. Let's focus on messages first and look at subscription commands later.
>
>> 2. Do you think topics must always be created on the fly? (I know your
>> approach for pub sub is generalised one. But some implementation
>> can as well use topics) If not, some implementation may need a
>> notification (which is a command) of destroyed (and may be
>> created) topics.
>
> How does the generalised approach prevent using topics?
>
> If you use prefix-matching algorithm, the application can decide to use say
> 0x01 as topic-content delimiter (think FIX) and subscribe for things like
> "forex.USD.GBP\x01".
>
> If the topic isn't placed at the beginning of the message body, different
> matching algorithm can be defined (eg. regexp).
>
Our project currently uses topics not just as filter, but as separate entity.
We authorize users to subscribe on the topics and also have a method
to force unsubscribe all users from specific topic, etc. This is what I've
tried to explain. But as I see now, it's a separate pattern from your
point of view, which for example can be called "authorithed content
distribution" or whatever. So nevermind, I'm just throwing ideas and see
if that helps.
>> 3. I think that obvious way of aggregating several feeds to be split
>> later is to add label with origin feed name, don't you?
>
> You are speaking of tunnelling, right?
Kinda, Yes.
> You definitely need a mux/demux on
> each side, but it doesn't seem to have much to do with SP as such.
>
> A generic tunnelling solution would work well on any kind of messages,
> whether pub/sub messages, req/rep messages, SCTP messages, websocket
> messages, UDP packets etc.
>
So how it should work? Like a VPN (PPTP, L2TP, OpenVPN)? Not sure I
mean that.
> Thus, I would say it's a technology orthogonal to SP / layered on top of SP.
>
Do you mean I should pick up whole message and labels stack, pack it into
a SP message and send thought a tunnel?
Let me explain my use case for such a device. We have a several clusters
of an application. In each cluster we have several services (about 5), and
quite a few instances of each service (about 10-100), each services does
have several entry points (2-5). A small percent of tasks(about 10% or
lower) is distributed between clusters (in a sense of tasks having subtasks
in two or more clusters). In the straightforward approach we need to
connect instances to each-other. For only two clusters, we would have about
(5*100*5)^2 = 2500^2 = 6250000 connections in total and about 2500 ones
in each process. Which is definetly not that big problem for today's
machines. But there are plenty of problems:
1. Each new service instance starts 2500 connections = sends more
than 5000 tcp packets = wakes up 2500 other processes. Even 10 to 100
times more when booting another machine.
2. Network configuration must be synchronised, which SP explicitly tries
avoid (if I understand correctly)
3. Load-balancing is flawed
4. Netstat and tcpdump output is unreadable, TCP ports can be exhausted
and other admins' problems
We do that by aggregating all the data into a zeromq device forward
to other cluster's device, and route inside the cluster apropriately.
We have a connection per pattern.
We probably could live without tunelling, that would bring up
(services x entry-points-per-service x number of clusers) ^ 2,
but we have few bonuses with tunelling:
1. Number of inter-cluster connections are hundred times lower:
(number-of-patterns x number of clusers) ^ 2
2. Bringing up and shutting down services does not introduce
inter-cluster traffic
Before you asked, we have no head of line blocking problem,
because traffic between clusters is small, and we have fast
device which does read all the messages quickly and queues/load
balances appropriately. Per-service statistics is also handled
by the device.
>> 4. I have at least one use case where I don't need to forward
>> topic to final endpoint (which is websocket client BTW), so it's
>> arguable whether topic contained in a message and not a label.
>> It can be thought of as pub/sub intermediary with message
>> processor which strips topic, but not sure it's better in any way.
>
> The problem is that there are often quite elaborate filters used in the wild
> (x-path, SQL-like) that don't allow for clear separation of the topic and
> the body.
>
Sure. And there are ones that do allow. I'm just bringing more wide
overview for discussion.
Frankly, everything I've implemented in my projects so far
do skip topic while delivering to the endpoint.
--
Paul
Martin Sustrik
>>> I've seen a lot of code that break if packets arrive not as expected. Some
>>> even is running in production. But, that cases are probably not counted :)
>>
>> That's interesting. How do they do it? Custom TCP implementation?
>>
>
> No they do read call, and parse only one message. And it works until they have
> tens or hundreds messages per second (until messages start to be joined,
> or fragmented). I've said that that code is broken?
Ah, got it. Like polling for inbound data, then doing a non-blocking
read and expecting to get the whole message -- while it may deliver just
a part of the message in case it is fragmented on the TCP level.
>> How does the generalised approach prevent using topics?
>>
>> If you use prefix-matching algorithm, the application can decide to use say
>> 0x01 as topic-content delimiter (think FIX) and subscribe for things like
>> "forex.USD.GBP\x01".
>>
>> If the topic isn't placed at the beginning of the message body, different
>> matching algorithm can be defined (eg. regexp).
>>
>
> Our project currently uses topics not just as filter, but as separate entity.
> We authorize users to subscribe on the topics and also have a method
> to force unsubscribe all users from specific topic, etc.
Right, I see. This aspect of pub/sub is actually quite interesting. The
problem is that if there are intermediate nodes or if there's an
uni-directional transport (such as multicast), the publisher doesn't
even know about the individual subscribers.
In the case of intermediate nodes, if the node is under the enterprise's
control it's still possible to do authorisation there. However, if you
start thinking of purely infrastructural middle nodes (say at ISPs or at
internet backbones), these are out of control of the particular business
entity (company) and thus should be treated as untrusted.
The only real solution, AFAICS, is encrypting the messages in end-to-end
manner, where middle nodes are not able to decrypt the content and do
only dumb forwarding.
I am not an security expert and there's definitely more thinking needed
here...
>> A generic tunnelling solution would work well on any kind of messages,
>> whether pub/sub messages, req/rep messages, SCTP messages, websocket
>> messages, UDP packets etc.
>>
>
> So how it should work? Like a VPN (PPTP, L2TP, OpenVPN)? Not sure I
> mean that.
No idea. What I am saying is that tunneling/mutliplexing solutions tend
to pop up on different layers of the stack. So, we should think of
whether it's needed on the SP layer, and if so, why? For example:
1. Is it because there only one port open in the firewall?
2. Is it because we want to avoid memory usage caused by multiple open
sockets?
3. Is it because we want to avoid excessive TCP connection initiation
handshakes?
Etc.
Having clear answers to these questions would hopefully give more
indication about what layer we want the multiplexing to work on.
>> Thus, I would say it's a technology orthogonal to SP / layered on top of SP.
>>
> Do you mean I should pick up whole message and labels stack, pack it into
> a SP message and send thought a tunnel?
That would be right if the multiplexing is done of top of SP. If it
should be done on IP layer, you need mutliple TCP connections. If it's
to be done on L4, you need something like SCTP. If you want to do in on
WebSocket layer, there's an multiplexing extension being discussed at
IETF hybi working group. Etc.
Aha. I see your problem.
I think it is important to distinguish real "tunnelling" from simply
using a particular SP pattern.
"Tunnelling" IMO means that you funnel random unrelated stuff through a
single TCP connection. Say one req/rep feed two different pub/sub feeds
etc. In this case the tunnel works as a dumb point-to-point delivery
mechanism with mux/demux attached.
The case you are referring to is different AFAICS. It's a single
well-defined topology. If every node would be connected to every other
node you would end up with quadratic number of connections, which is a
model that is bound to break at some point.
Thus, you define a more sensible topology where the messages pass
through pattern-specific devices that kind of do multiplexing (see
attached diagram). There's no tunnelling involved.
Now, if it's not possible to achieve this kind of setup using the native
mechanisms of the pattern, we should check whether the pattern isn't
broken in some way and try to fix it.
>>> 4. I have at least one use case where I don't need to forward
>>> topic to final endpoint (which is websocket client BTW), so it's
>>> arguable whether topic contained in a message and not a label.
>>> It can be thought of as pub/sub intermediary with message
>>> processor which strips topic, but not sure it's better in any way.
>>
>> The problem is that there are often quite elaborate filters used in the wild
>> (x-path, SQL-like) that don't allow for clear separation of the topic and
>> the body.
>>
> Sure. And there are ones that do allow. I'm just bringing more wide
> overview for discussion.
>
> Frankly, everything I've implemented in my projects so far
> do skip topic while delivering to the endpoint.
Ok. That raises a question: Is it worth creating a "topic-based pub/sub"
pattern (where topic is in a label and gets dropped before the last hop)
in addition to "content-based pub/sub"?
Note that such pattern would yield a non-homogenous topologies -- the
last hop would be different protocol-wise (no topics on the wire) from
all the other hops.
Martin
Paul Colomiets
On Tue, Sep 6, 2011 at 2:17 PM, Martin Sustrik <sus...@250bpm.com> wrote:
> Right, I see. This aspect of pub/sub is actually quite interesting. The
> problem is that if there are intermediate nodes or if there's an
> uni-directional transport (such as multicast), the publisher doesn't even
> know about the individual subscribers.
>
> In the case of intermediate nodes, if the node is under the enterprise's
> control it's still possible to do authorisation there. However, if you start
> thinking of purely infrastructural middle nodes (say at ISPs or at internet
> backbones), these are out of control of the particular business entity
> (company) and thus should be treated as untrusted.
>
Tracking of individual endpoints is not needed here. You authorize some
intermediate to access to a subset of topics, and that is doing authorization
on it's own. We can think of it as a node in different organization which
provides distrubution there.
> The only real solution, AFAICS, is encrypting the messages in end-to-end
> manner, where middle nodes are not able to decrypt the content and do only
> dumb forwarding.
>
> I am not an security expert and there's definitely more thinking needed
> here...
>
Yes. Some drawbacks off the top of my head:
1. If content is encrypted, so how to filter at intermediaries?
2. If can't filter at intermediaries, traffic is huge
3. How many keys is needed to subscribe to diffferent topics? Even
worse, if you have fuzzy subscribtions (prefix, regex...etc)
4. Small messages (which are most frequent use case for pub-sub) are
very hard to encrypt securely (but I'm not a security expert either)
>
> 1. Is it because there only one port open in the firewall?
> 2. Is it because we want to avoid memory usage caused by multiple open
> sockets?
> 3. Is it because we want to avoid excessive TCP connection initiation
> handshakes?
>
For my usecases they are exactly point (2) and (3) from the above, as
I described in previous mail.
> Thus, you define a more sensible topology where the messages pass through
> pattern-specific devices that kind of do multiplexing (see attached
> diagram). There's no tunnelling involved.
>
> Now, if it's not possible to achieve this kind of setup using the native
> mechanisms of the pattern, we should check whether the pattern isn't broken
> in some way and try to fix it.
>
Ok, so is it elligible for pubsub? Then we want labels (or is there
another way?) for content-based pub-sub. It seems to be obvious how to
do that for (not yet defined) topic-based pub/sub.
>> Frankly, everything I've implemented in my projects so far
>> do skip topic while delivering to the endpoint.
>
> Ok. That raises a question: Is it worth creating a "topic-based pub/sub"
> pattern (where topic is in a label and gets dropped before the last hop) in
> addition to "content-based pub/sub"?
>
> Note that such pattern would yield a non-homogenous topologies -- the last
> hop would be different protocol-wise (no topics on the wire) from all the
> other hops.
>
That's interesting point. In any pattern we strip labels before delivering to
final application, so it's ok if treated like that. If delivering to
the endpoint is
should be with topic stripped off, we can treat last hop as content-based
pub/sub (presumably without filtering). Other way is also interesting. For
multiplexing we can switch to topic-based pub/sub (with topic being
original feed name), and then switch back when demultiplexing.
So is switching between patterns is considered to be normal or not?
--
Paul
Tony Garnock-Jones
1. If content is encrypted, so how to filter at intermediaries?
4. Small messages (which are most frequent use case for pub-sub) are
very hard to encrypt securely (but I'm not a security expert either)
If you can use CTR or GCM modes this might improve the situation quite a bit. But such modes are inherently "connected", requiring synchronised state shared between the sender and receivers. (Do you have a link getting into the details of the difficulties involved in encrypting small messages?)
Tony
--
Tony Garnock-Jones
tonygarn...@gmail.com
http://homepages.kcbbs.gen.nz/tonyg/
Paul Colomiets
On Wed, Sep 7, 2011 at 3:38 PM, Tony Garnock-Jones
<tonygarn...@gmail.com> wrote:
> On 7 September 2011 03:54, Paul Colomiets <pa...@colomiets.name> wrote:
>>
>> 1. If content is encrypted, so how to filter at intermediaries?
>
> http://en.wikipedia.org/wiki/Homomorphic_encryption ;-)
>
Can you elaborate a bit more on how it can be done?
>>
>> 4. Small messages (which are most frequent use case for pub-sub) are
>> very hard to encrypt securely (but I'm not a security expert either)
>
> If you can use CTR or GCM modes this might improve the situation quite a
> bit. But such modes are inherently "connected", requiring synchronised state
> shared between the sender and receivers.
CTR doesn't work here, and ASAICS GCM doesn't work either. Synchronized
state between sender and receiver defeats scalability most of the time.
> (Do you have a link getting into
> the details of the difficulties involved in encrypting small messages?)
>
No, sorry :)
--
Paul
Tony Garnock-Jones
Can you elaborate a bit more on how it can be done?
Not really - I'm just vaguely aware of the idea of Homomorphic Encryption, that is, that some computations can be done on encrypted data without decrypting it, possessing the key, or learning what the data itself says. It may not be applicable to routing... but then again, it may be. It's almost certainly far enough out-of-scope for this list to warrant the ";-)" though, I think!
Synchronizedstate between sender and receiver defeats scalability most of the time.
Granted. In this situation there is no need for feedback from the receiver to the sender, of course. I'm imagining something like PGM enhanced with some kind of key exchange for receivers to initially gain synchronisation with senders, which could put CTR or GCM back on the table I think. Hairy.
Cheers,
Tony
Martin Sustrik
>> I am not an security expert and there's definitely more thinking needed
>> here...
>>
>
> Yes. Some drawbacks off the top of my head:
>
> 1. If content is encrypted, so how to filter at intermediaries?
> 2. If can't filter at intermediaries, traffic is huge
> 3. How many keys is needed to subscribe to diffferent topics? Even
> worse, if you have fuzzy subscribtions (prefix, regex...etc)
> 4. Small messages (which are most frequent use case for pub-sub) are
> very hard to encrypt securely (but I'm not a security expert either)
These are very good points.
I guess it means that the "header" of the message (eg. the topic) should
be formally separated from the message content itself, so that the
encryption algorithm can encrypt only the content, leaving header intact
and available for routing by the intermediate nodes.
Few thoughs:
Even so, intermediate node could take the encrypted content, replace the
header and send the message to who haven't subscribed for it.
Take an example of a stock quote where topic is the market code while
body is the price. By taking a price from one topic and sending it as
another topic, attacker can confuse the trading algorithms at the
destination.
Thus, I guess, some measure is needed to ensure that a message wasn't
meddled with, including it's header (and thus non-encrypted) part.
Another though is about different routing algorithms. Say a message is a
collection of fields. The filter is SQL-style expression. Given that SQL
expression can possibly check any field in the message, no fields can be
encrypted.
Does the above make sense at all? Is there a way to combine arbitrary
routing algorithms with end-to-end encryption.
Martin
Martin Sustrik
> 1. If content is encrypted, so how to filter at intermediaries?
>
> http://en.wikipedia.org/wiki/Homomorphic_encryption ;-)
That's an clever idea!
Think of it this way:
1. Sender encrypts the topic in the message.
2. Subscriber encrypts the topic in the subscription request.
3. Intermediary node compares the encrypted topic in the message with
the encrypted topic in the subscription, if it matches, the original
topic matches.
Obviously, the above applies only if the encryption algorithm is
homomorphic wrt. operation of equality.
Other kinds of filtering can be harder to implement. For example, I
believe there could be an encryption algorithm that would be homomorphic
wrt. prefix comparison, however, I dounbt about encryption homomorphic
wrt. regular expressions.
Martin
Tony Garnock-Jones
Even so, intermediate node could take the encrypted content, replace the header and send the message to who haven't subscribed for it.
Those who don't have the key just end up with more to drop on the floor. To guard against the attack you point out, it suffices to use integrity protection on the message as well as (or even instead of, depending on application needs) encryption: you'd sign both the price and the market code together to produce the signature. Simplest might be to repeat the market code in the body as well as the routing headers, but a more complex signature scheme could include routing headers by reference in some cases. (Though those cases might be overly simple; it's probably best not to permit such references and just go with including all the relevant information needing integrity protection together in the body of the message.)
Does the above make sense at all? Is there a way to combine arbitrary routing algorithms with end-to-end encryption.
So long as information intended for the routing network itself (a kind of distributed application) is clearly separated from the information intended for the ultimate recipient, then I reckon the answer is "yes, but it requires careful thinking about who you trust at each layer".
Tony
Tony Garnock-Jones
1. Sender encrypts the topic in the message.
2. Subscriber encrypts the topic in the subscription request.
3. Intermediary node compares the encrypted topic in the message with the encrypted topic in the subscription, if it matches, the original topic matches.
I don't know if this lines up with the disciplinary definition of homomorphic encryption or not ;-) but it seems pretty leaky to me. It seems with this scheme likely that an observer could reconstruct the routing tree fairly straightforwardly via traffic analysis.
Tony
Paul Colomiets
>
> 1. Sender encrypts the topic in the message.
> 2. Subscriber encrypts the topic in the subscription request.
> 3. Intermediary node compares the encrypted topic in the message with the
> encrypted topic in the subscription, if it matches, the original topic
> matches.
The does not solve the problem of authorizing different users to listen
on different topics. This way any user that has a key can listen on any
topic. This does cut down the traffic. But does need a shared key for
each user. It's certainly can work for some use cases, but it is not
a real authorization system.
--
Paul

Robert G. Jakabosky
The subscriber could receive the pre-encrypted topic from the server, when
requesting access to the content.
--
Robert G. Jakabosky
Martin Sustrik
> On 18 September 2011 09:21, Martin Sustrik <sus...@250bpm.com
Good point.
Martin
Martin Sustrik
close to understanding.
What about splitting the work into 2 phases:
1. Define a viable non-secure pub/sub system.
2. Discuss the security problems and possible solutions.
That would allow us to get some kind of pub/sub document rapidly so that
we have something to start with in IETF.
Of course, not neglecting the security issues and explicitly
acknowledging that the proposal is work in progress is crucial.
Martin

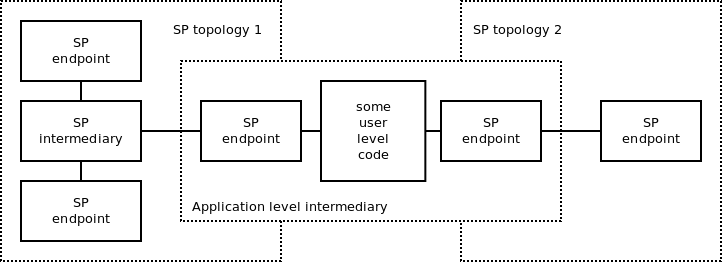{kind=link}
{kind=link}
Pieter Hintjens
> 1. Define a viable non-secure pub/sub system.
> 2. Discuss the security problems and possible solutions.
Perhaps worth building on what's already been done on top of 0MQ where
possible. We have a raw pub-sub security model here:
http://www.zeromq.org/topics:pubsub-security.
Which is based on Thomas Hatch's Salt security model:
https://github.com/thatch45/salt.
-Pieter
Martin Sustrik
Yes. That was the intent.
However, the discussion earlier in this thread seems to indicate that
the problem is more complex than that.
Martin