Logiciel du jour offert 2 : PDF Text OCR Xtractor 3.2.2.20
22 views
Skip to first unread message

Fred
Apr 17, 2023, 9:53:40 PM4/17/23
to sos windows2
PDF Text OCR Xtractor est parfait pour extraire du texte à partir de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres ascutes utiles, avant les analyseurs.
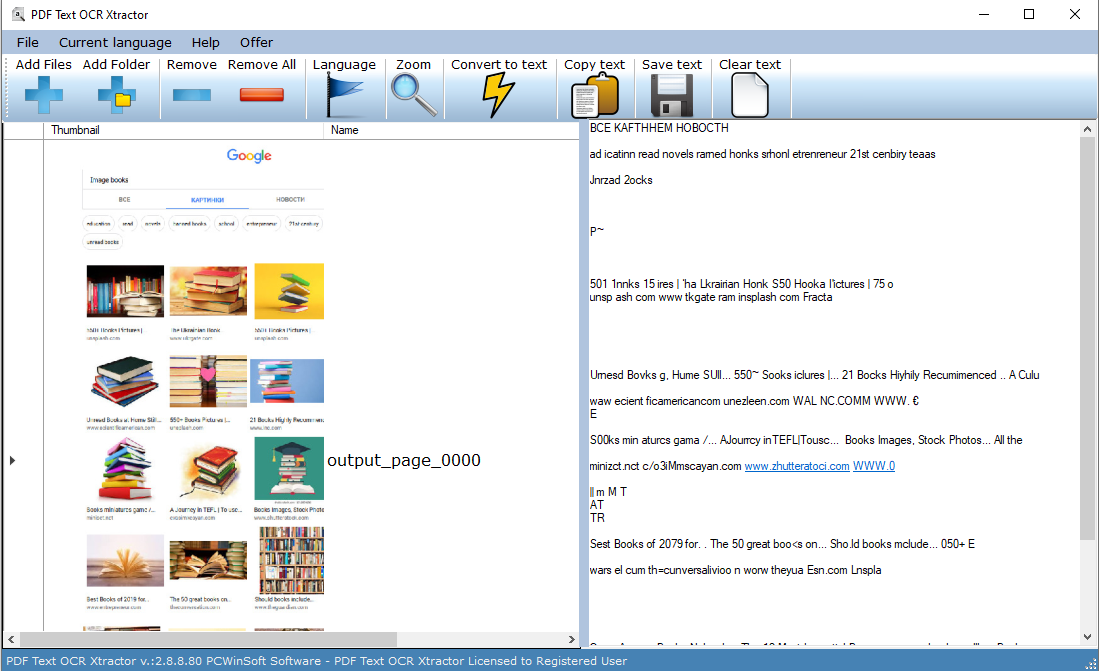
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Il reste 7 heures pour en profiter :






PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres ascutes utiles, avant les analyseurs.
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Il reste 7 heures pour en profiter :
https://fr.giveawayoftheday.com/pdf-text-ocr-xtractor-2-8-8-80/
Caractéristiques principales:
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires:
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouges trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Caractéristiques principales:
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires:
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouges trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Fred
May 9, 2024, 12:49:29 AM5/9/24
to sos windows2
6 jours et 2 heures de plus pour profiter de ce logiciel qui permet de récupérer du texte à partir de fichiers image :
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
PDF Text OCR Xtractor est parfait pour extraire du texte à partir de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres astuces utiles, avant les analyseurs.
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Caractéristiques principales :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouvez trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Fred
Jun 9, 2024, 11:52:24 PM6/9/24
to sos windows2
3 heures de plus pour profiter de ce logiciel de reconnaissance de caractères :
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
PDF Text OCR Xtractor est parfait pour extraire du texte à partir de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres astuces utiles, avant les analyseurs.
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Caractéristiques principales :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouvez trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Fred
Sep 5, 2024, 10:36:14 PM9/5/24
to sos windows2
6 heures de plus pour profiter de ce logiciel de reconnaissance de caractères pour fichiers PDF :
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
PDF Text OCR Xtractor est parfait pour extraire du texte à partir de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres astuces utiles, avant les analyseurs.
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Caractéristiques principales :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouvez trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Fred
Mar 2, 2025, 3:26:27 AM3/2/25
to sos windows2
24 heures de plus pour profiter de ce logiciel de reconnaissance de caractères sur fichiers PDF :
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
PDF Text OCR Xtractor est parfait pour extraire du texte à partir de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres astuces utiles, avant les analyseurs.
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Caractéristiques principales :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouvez trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Fred
Oct 12, 2025, 11:51:28 PM10/12/25
to sos windows2
4
heures de plus pour profiter de ce logiciel de reconnaissance de caractères sur fichiers PDF :
PDF Text OCR Xtractor est parfait pour extraire du texte à partir de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres astuces utiles, avant les analyseurs.
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Caractéristiques principales :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouvez trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Fred
Nov 29, 2025, 9:29:35 PM11/29/25
to sos windows2
6 heures de plus pour profiter de ce logiciel de reconnaissance de caractères (OCR) sur fichiers PDF :
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
PDF Text OCR Xtractor est parfait pour extraire du texte à partir de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres astuces utiles, avant les analyseurs.
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Caractéristiques principales :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouvez trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Fred
Dec 1, 2025, 10:43:58 PM12/1/25
to sos windows2
4 heures de plus pour profiter de ce logiciel de reconnaissance de caractères :
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
PDF Text OCR Xtractor est parfait pour extraire du texte à partir de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres astuces utiles, avant les analyseurs.
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Caractéristiques principales :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouvez trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Fred
12:43 AM (11 hours ago) 12:43 AM
to sos windows2
3
heures de plus pour profiter de ce logiciel de reconnaissance de caractères :
PDF Text OCR Xtractor est parfait pour extraire du texte à partir de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor utilise la technologie Tesseract OCR. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avance et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publiée sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres astuces utiles, avant les analyseurs.
PDF Text OCR Xtractor est une grande précision et obtient n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Caractéristiques principales :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. Utilisation de la meilleure technologie OCR disponible.
2. Prenez en charge plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctions supplémentaires :
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous pouvez trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Reply all
Reply to author
Forward
0 new messages