Chassis DB connectivity support for multi-asic linecards
37 views
Skip to first unread message

Maxime Lorrillere
Jun 8, 2021, 6:28:14 PM6/8/21
to sonic-chass...@googlegroups.com, Eswaran Baskaran, ans...@microsoft.com
Hi All,
A problem we have been looking at is the connectivity between multi-asic namespaces on linecards to Chassis DB running on the supervisor.
On a VoQ Chassis, we configure an internal network with subnet 127.100.0.0/16. Each linecard has a subinterface eth0.42 with IP 127.100.<slot id>.1. This allows all docker instances to connect to Chassis DB.
Problem: On a multi-asic linecard, per-asic docker instances run in a separate namespace and are only connected to docker's default bridge (240.127.1.1/24), so they can't access our 127.100.0.0/16 network.
We solved this problem by creating a macvlan docker network that attach to eth0.42 of the linecard. Each per-asic docker instance is connected to this new docker network and has an eth1 interface that gets an IP in the 127.100.<slot id>.1/24 range. This step cannot be done by platform implementation as all multi-asic namespace creation and which network to attach to are pretty much hardcoded in docker_image_ctl.j2.
This works for us, but since this is dependent on how the internal network was configured, and this is part of platform implementation as per VoQ architecture design document (see https://github.com/Azure/SONiC/blob/master/doc/voq/architecture.md).
So it seems that we should come up with a generalized way to connect to Chassis DB from linecards.
Did any of you ran into similar issues with multi-asic linecards?
Should we bring this up to tomorrow's Chassis Subgroup Meeting?
Thanks,
Maxime

Sureshkannan
Jun 10, 2021, 9:39:20 AM6/10/21
to Maxime Lorrillere, sonic-chassis-subgroup, Eswaran Baskaran, Anshu Verma
Hi All,
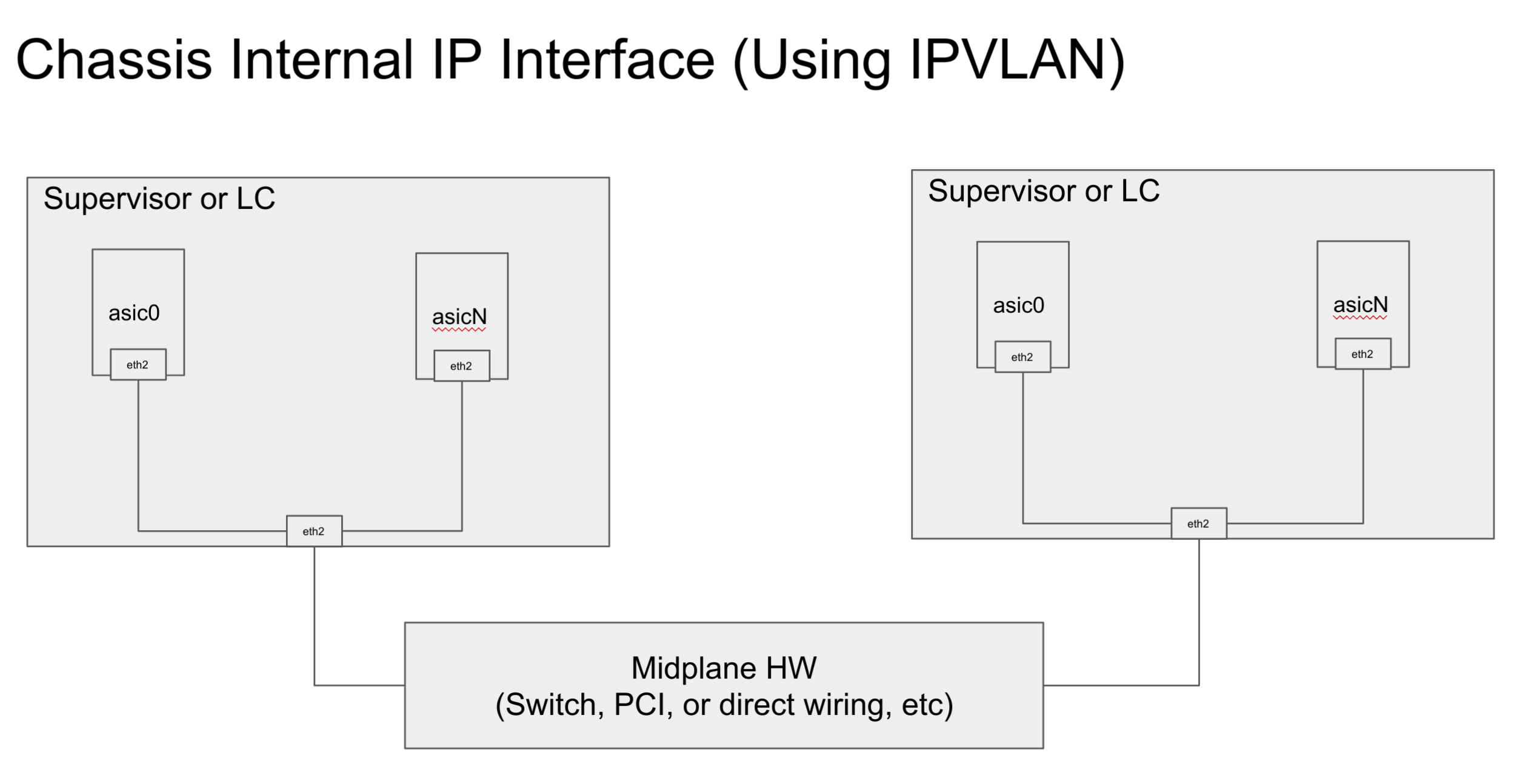
To continue our discussion about chassis internal connectivity for accessing chassis-db..
Option A: Using NAT rule in HOST
In every LC, using NAT to expose <240.127.1.1, 6380> endpoint that is hosted in the supervisor card. From each LC netns, treats 240.127.1.1, 6380 as local database but because of NAT, it all goes to supervisor card.
# iptables -t nat -A POSTROUTING -d <supervisor-card-ip> -s 240.127.1.0/24 -p tcp --dport 6380 -j SNAT --to <internal-slot-ip>
Pros: Simple enough.
Cons: NAT rules shouldnt be affected SONIC services. Can it be configured via SONIC services that handles this NAT table.
Option B: Using IPVLAN concept
Lets create new/reuse(leave it platform vendor to decide) VLAN over midplane. Each NS(aka asic0, asic1, etc) will get an unique IP address that is reachable over midplane.
# ip link add name ceth2 link eth2 type ipvlan mode l2 # ip link set dev ceth2 netns asic0
ceth2 is chassis interface (chassis-eth2) that gets created by platform and moved to NS. As such IP addresses are assigned by platform, only discovery is done by the SONiC upper layer. This gives flexibility/optimization to the platform vendor in terms of address assignment.
Pros: Doesn't get affected by any SONIC upper layer service like NATmgr because its IP address is isolated.
Cons: anything?
Option C: Using MACVLAN concept
MACVLAN and IPVLAN are very similar. Just that IPVLAN uses a different IP addressing scheme, MACVLAN uses different MAC addresses for demux.
# ip link add macvlan1 link eth0 type macvlan mode bridge # ip link add macvlan2 link eth0 type macvlan mode bridge # ip link set macvlan1 netns asic0 # ip link set macvlan2 netns asicN
Below link explains when to pick IPVLAN vs MACVLAN
6. What to choose (macvlan vs. ipvlan)? These two devices are very similar in many regards and the specific use case could very well define which device to choose. If one of the following situations defines your use case then you can choose to use ipvlan - (a) The Linux host that is connected to the external switch / router has a policy configured that allows only one mac per port. (b) No virtual devices created on a master exceed the mac capacity and puts the NIC in promiscuous mode and degraded performance is a concern. (c) If the slave device is to be put into the hostile / untrusted network namespace where L2 on the slave could be changed / misused.
Thanks,
Suresh
--
You received this message because you are subscribed to the Google Groups "sonic-chassis-subgroup" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sonic-chassis-sub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/sonic-chassis-subgroup/CAEw%3DEYdoBxo85Re-0%3DPQixk9iozEtXCGBukU8B92Yie0XfVEUg%40mail.gmail.com.
Maxime Lorrillere
Jun 22, 2021, 7:51:15 PM6/22/21
to Sureshkannan, sonic-chassis-subgroup, Eswaran Baskaran, Anshu Verma
Hi All,
Any option would work for us. Do you have a preference or a particular plan in mind?
Thanks,
Maxime
Sureshkannan
Jun 23, 2021, 1:58:22 PM6/23/21
to Maxime Lorrillere, Abhishek Dosi, sonic-chassis-subgroup, Eswaran Baskaran, Anshu Verma
Summary:
- Lets start with ipvlan and use interface.j2 (interface.service?) to configure a unique ip address across chassis by using switch-id sonic configuration. @Abhishek Dosi : Can you explain how a unique IP address can be obtained using interface.j2
- There will be a common script that will create eth1 to each namespace using ip link command. eth1 is also created in a host that is connected to underlying HW wire/switch by platform based on platform capabilities.
foreach asic in {asics}
# ip link add name ns-eth1 link eth1 type ipvlan mode l3
# ip link set dev ns-eth1 netns asicX
# ip netns exec asicX ip link set ns-eth1 name eth1- ns-eth1 is an interface created inside asic namespace.
- eth1 is exposed by a platform vendor that wires up lines cards with supervisor cards.
Please feel free to add/edit as required.
Thanks,
Suresh

Judy Joseph
Jul 6, 2021, 6:52:50 PM7/6/21
to Sureshkannan, Maxime Lorrillere, Abhishek Dosi, sonic-chassis-subgroup, Eswaran Baskaran, Anshu Verma
Hi All,
Continuing further on this discussion, adding more details ..
1. The sonic-platform-modules-* for different vendor chassis models, use their own platform-systemd-service script run on card bootup to create/bringup up the midplane interface in linux host. This platform script names the interface as eth1/eth1-midplane in linux host ?
2. Add the midplane n/w subnet, as a variable in platform_env.conf ( eg: MIDPLANE_SUBNET=172.16.0.0/16, the IP address for eth1 in Sup1 is 172.16.1.1, linecard 3 is 172.16.3.1 etc )
3. The slot_id of the supervisor/linecard - is assumed to be present for use in the sonic instance.
With this info available, we should be able to configure the interfaces in namespaces using the ip link commands which Suresh shared earlier. Two ways,
1. The namespaces are set up when we create the respective database@0, database@1.. etc services. We could run the ip link commands in the database.sh script itself. The namespace_id derived from $DEV, can be used to uniquely set the ip address.
2. The interfaces-config.service systemd service is called after database services are run ( the namespaces would have already been created by then ). We could have a loop foreach asic in {asics}, where the max number of asics could be obtained from asic.conf file present. This logic could be added either in interfaces/interfaces.j2 file or in the script interfaces/interfaces-config.sh
Please share if anyone tried out more on creating the ipvlan interfaces in l3 mode.
Regards,
Judy.
To view this discussion on the web visit https://groups.google.com/d/msgid/sonic-chassis-subgroup/CAAfdQhOyWBxHapUVbbLvV_uSG4CnNMcinE6UeKrhEMBKwyxQaQ%40mail.gmail.com.
Maxime Lorrillere
Jul 7, 2021, 1:04:01 PM7/7/21
to Judy Joseph, Sureshkannan, Abhishek Dosi, sonic-chassis-subgroup, Eswaran Baskaran, Anshu Verma
Hi Judy,
Regarding option 2. I believe interfaces-config.service starts after config-setup.service. When config-setup will indirectly try to connect to chassis DB; this should be fixed by https://github.com/Azure/sonic-utilities/pull/1707, but I think it makes more sense to create the interfaces in namespaces in database.sh itself so that when the database@ container starts everything is ready.
Besides that this looks good, we will try this at Arista and get back to you.
Thanks,
Maxime
Maxime Lorrillere
Jul 15, 2021, 8:03:35 PM7/15/21
to Judy Joseph, Sureshkannan, Abhishek Dosi, sonic-chassis-subgroup, Eswaran Baskaran, Anshu Verma
Hi all,
I was able to use ipvlan in l2 mode. As far as I understand it, l3 mode is not suitable for us because it requires the subinterfaces to be in a different subnet.
Also, at Arista we use 127.100.0.0/16 which requires that:
1. We change the loopback address in the namespaces from 127.0.0.1/8 to 127.0.0.1/16 (this change was already made to the host here)
2. Enable route_localnet on eth1
Here is what I did:
1. Add MIDPLANE_SUBNET=127.100.0.0/16 in platform_env.conf
2. We already have a platform service that configures eth1-midplane
3. Add the following code to database.sh in link_namespace():
# Setup eth1 if we connect to a remote chassis DB.
PLATFORM_ENV="/usr/share/sonic/device/$PLATFORM/platform_env.conf"
[ -f $PLATFORM_ENV ] && source $PLATFORM_ENV
if [[ -z "$MIDPLANE_SUBNET" ]]; then
# Use /16 for loopback interface
ip netns exec $NET_NS ip addr add 127.0.0.1/16 dev lo
ip netns exec $NET_NS ip addr del 127.0.0.1/8 dev lo
# Create eth1 in database instance
ip link add name ns-eth1 link eth1-midplane type ipvlan mode l2
ip link set dev ns-eth1 netns $NET_NS
ip netns exec $NET_NS ip link set ns-eth1 name eth1
# Configure IP address and enable eth1
local lc_slot_id=$(python -c 'import sonic_platform.platform; platform_chassis = sonic_platform.platform.Platform().get_chassis(); print(platform_chassis.get_my_slot())' 2>/dev/null)
local lc_ip_address=`echo $MIDPLANE_SUBNET | awk -F. '{print $1 "." $2}'`.$lc_slot_id.$((DEV + 10))
local lc_subnet_mask=${MIDPLANE_SUBNET#*/}
ip netns exec $NET_NS ip addr add $lc_ip_address/$lc_subnet_mask dev eth1
ip netns exec $NET_NS ip link set dev eth1 up
# Allow localnet routing on the new interfaces
ip netns exec $NET_NS bash -c "echo 1 > /proc/sys/net/ipv4/conf/eth1/route_localnet"
fi
Thanks,
Maxime
Judy Joseph
Aug 2, 2021, 7:16:34 PM8/2/21
to Maxime Lorrillere, Sureshkannan, Abhishek Dosi, sonic-chassis-subgroup, Eswaran Baskaran, Anshu Verma
Hi Maxime,
Thanks for trying this out, we can go with ipvlan l2 mode as in our use case the sub-interfaces (created in different namespaces) from the master eth1-midplane are in the same subnet.
Regarding the approach to take, If the dependency of config-setup systemd service connecting to chassis DB is getting fixed, it would be good to keep all the interfaces related config in one place in the interfaces.j2 and use it in interfaces-config.sh/interfaces-config.service systemd service - can share more details on this offline if that helps so that we could raise a PR, let me know.
thanks,
Judy.
Maxime Lorrillere
Aug 4, 2021, 12:18:58 PM8/4/21
to Judy Joseph, Sureshkannan, Abhishek Dosi, sonic-chassis-subgroup, Eswaran Baskaran, Anshu Verma
Hi Judy,
I'll try to make it work in interfaces-config and open a PR if I don't run into a major issue.
Thanks,
Maxime

Abhishek Dosi
Apr 7, 2022, 8:03:28 PM4/7/22
to Maxime Lorrillere, Judy Joseph, Sureshkannan, Abhishek Dosi, sonic-chassis-subgroup, Eswaran Baskaran, Anshu Verma
Hi All,
Revisiting this thread:-
During my testing I found of couple of issues and have create PR https://github.com/Azure/sonic-buildimage/pull/10500 to address this:
Issue1: By setting up of ipvlan interface in interface-config.sh we are not tolerant to failures. Reason being interface-config.service is one-shot and do not have restart capability.
Scenario: For example if let's say database service goes in fail state then interface-services also gets failed because of dependency check but later database service gets restart
but interface service will remain in stuck state and the ipvlan interface nevers get created.
Solution: Moved all the logic in database service from interface-config service which looks more align logically also since the namespace is created here and all the network setting (sysctl) are happening here.
With this if database starts we recreate the interface.
Issue 2: Use of IPVLAN vs MACVLAN
Currently we are using ipvlan mode. However above failure scenario is not handle correctly by ipvlan mode. Once the ipvlan interface is created and ip address assign to it
and if we restart interface-config or database (new PR) service Linux Kernel gives error "Error: Address already assigned to an ipvlan device." based on this:https://github.com/torvalds/linux/blob/master/drivers/net/ipvlan/ipvlan_main.c#L978
Reason being if we do not do cleanup of ip address assignment (need to be unique for IPVLAN) it remains in Kernel Database and never goes to free pool even though namespace is deleted.
Solution: Considering this hard dependency of unique ip macvlan mode is better for us and since everything is manager by Linux Kernel
Issue3: Namespace database Service do not check reachability to Supervisor Redis Chassis Server.
Currently there is no explicit check as we never do Redis PING from namespace to Supervisor Redis Chassis Server. With this check it's possible we will start database and all other docker even though
there is no connectivity and will hit the error/failure late in cycle
Solution: Added explicit PING from namespace that will check this reachability.
Please review the PR.
Best Regards
Abhishek Dosi
To view this discussion on the web visit https://groups.google.com/d/msgid/sonic-chassis-subgroup/CAEw%3DEYek02Zf%2Bfm%3DvicpxNH7Rqdj8KSiuXQZMEwX%2Bup-nqfBdw%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages