[qhanzi] Upgrade; new algorithm; home server problems
37 views
Skip to first unread message

Ben Bullock
Aug 20, 2020, 8:27:21 PM8/20/20
to sljfaq.org
A user wrote me an email detailing a recognition problem with some input he had made, which was quite a common type of writing "mistake", so I spent the time to improve the recognition of this particular thing. The recognition accuracy is now at 98.1%:
Total 52598 tests, found: 51613 (98.127%), average position: 1.58126828512197.
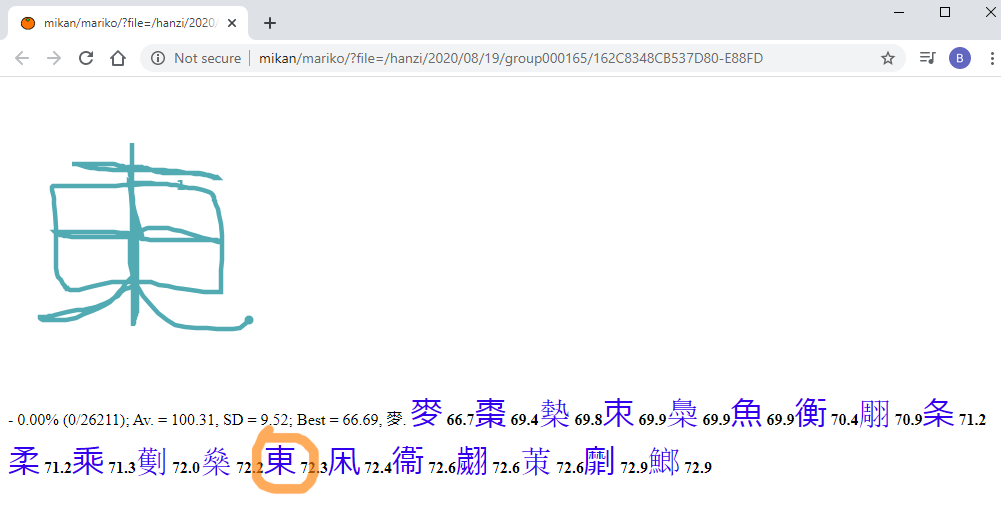
I've also been working on a new recognition algorithm which works solely on shapes, here is an example where the user has drawn 東 as a single line:
As can be seen from the orange circle, it finds the image at the 15th position, but this is a search over 26,000 characters so the 15th position is not too bad. The algorithm (codename "mariko") is in its infancy and is a little flaky at the moment but improvements should be possible.
Also my home server (the "mikan" in the above URL in fact) is suffering from sudden crashes which look like hard disc faults, and the computer itself is rather slow, so I'm probably going to replace the disks and possibly the computer itself. Everything is fairly well backed up and mirrored but this might cause some unexpected problems somehow.
Reply all
Reply to author
Forward
0 new messages