Scylla scylla-server-2.3.1 cluster collapse due to low storage on 1 node

Andrei
<fauxnomakaalias@gmail.com>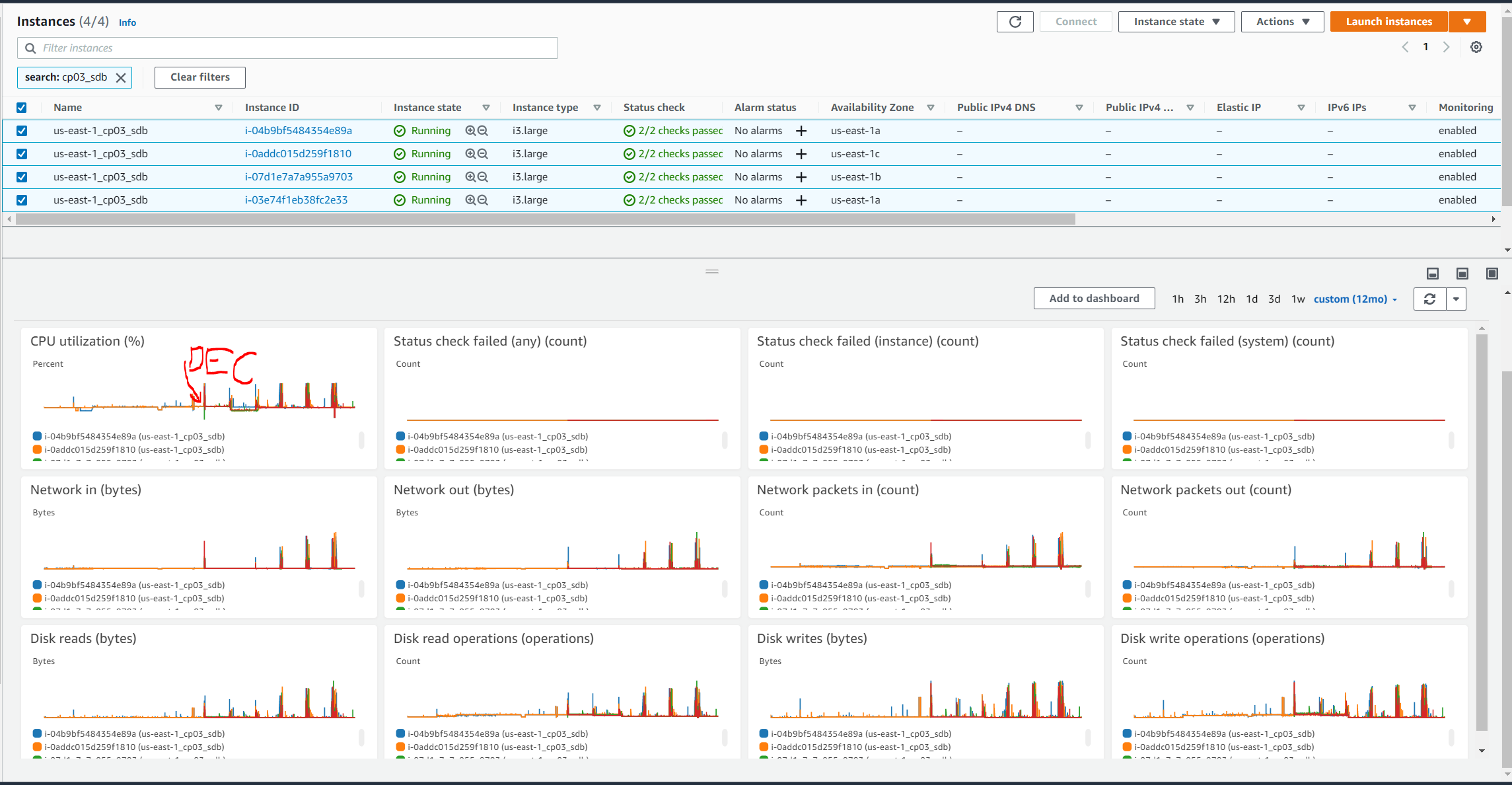

Avi Kivity
<avi@scylladb.com>2.3.1 is an outdated version. It's no longer supported, you should keep your nodes running updated versions with all the fixes.
It's also very important to keep enough gfree space in the nodes (by pruning snapshots, deleting unneeded data, and growing the cluster if needed).
My recommendation is to resolve the out-of-space error (if you can do this by deleting snapshots), recover the cluster, and upgrade all the way to 4.4.
If you cannot recover space, you may need to replace the node
with a larger instance and rebuild it. I'm not sure what the best
strategy is. Copying Asias for guidance.
--
You received this message because you are subscribed to the Google Groups "ScyllaDB users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scylladb-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/scylladb-users/43c23a61-ae14-4c79-9e74-e5421838dc1an%40googlegroups.com.
Andrei
<fauxnomakaalias@gmail.com>Thanks for the reply Avi. I'm very new to Scylla but I read about the nodetool commands we use in that maintenance script and some of them for me don't make sense.

Asias He
<asias@scylladb.com>
Thanks for the reply Avi. I'm very new to Scylla but I read about the nodetool commands we use in that maintenance script and some of them for me don't make sense.I don't know who created that "script".
According to the official Scylla documentation "nodetool cleanup" is used to remove data from nodes in case of a token ring modification aka when the cluster is expanded with new nodes or when a node is removed from the cluster.This is not the case for us so I don't see why we would run this command at the beginning of every month. What do you think ? Does it help or should we remove this command from the script ?
Next commmand "nodetool repair" I think it makes sense to run it in order to sync data across all nodes periodically but according to the docs maybe we should run it more often because indeed we do regular deletions, we keep 1 year of data and delete everything that's older.Last command "nodetool drain", i don't see its purpose. According to the docs it is used before an upgrade or a maintenance operation. Why run it after "repair" and "cleanup" ?
To view this discussion on the web visit https://groups.google.com/d/msgid/scylladb-users/f0303909-542d-43b5-b09b-795b1c212ce3n%40googlegroups.com.
--
Asias He
<asias@scylladb.com>2.3.1 is an outdated version. It's no longer supported, you should keep your nodes running updated versions with all the fixes.
It's also very important to keep enough gfree space in the nodes (by pruning snapshots, deleting unneeded data, and growing the cluster if needed).
My recommendation is to resolve the out-of-space error (if you can do this by deleting snapshots), recover the cluster, and upgrade all the way to 4.4.
If you cannot recover space, you may need to replace the node with a larger instance and rebuild it. I'm not sure what the best strategy is. Copying Asias for guidance.
--
Andrei
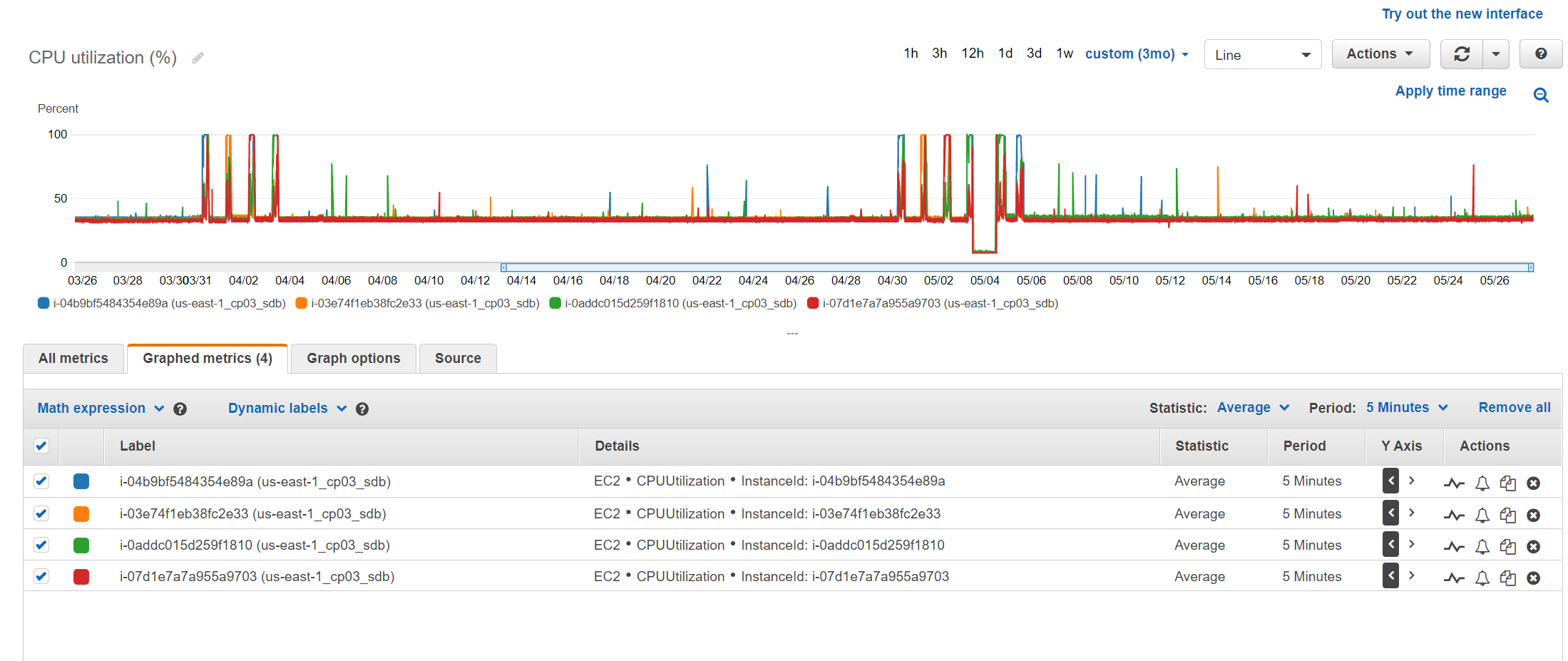
<fauxnomakaalias@gmail.com>UN Node 2 83.23 GB
UN Node 3 89 GB
UN Node 2 51.64 GB
UN Node 3 54.54 GB
Avi Kivity
<avi@scylladb.com>It will be super helpful to upgrade. That's much more productive than trying to chase a bug which may will have been fixed.
2.3.1 was released on October 2018, that's almost three years ago.
To view this discussion on the web visit https://groups.google.com/d/msgid/scylladb-users/e80e3e84-5055-4457-8755-9b175a8cc3ccn%40googlegroups.com.
Avi Kivity
<avi@scylladb.com>4.4.4. Note that you should upgrade one minor version at a time -
2.3 -> 3.0 -> 3.2 -> 3.3 etc.
Hi Avi, thanks for the input. I agree with you. I will try to an upgrade on some of our lower environments and see the results.Our HW setup is the following :
Model vCPU Memory (GiB) Networking Performance Storage (TB) i3.large 2 15.25 Up to 10 Gigabit 1 x 0.475 NVMe SSD
The OS is CentOS Linux release 7.5.1804 (Core)
Given this setup, which version do you recommend to upgrade to ?
Andrei
<fauxnomakaalias@gmail.com>Avi Kivity
<avi@scylladb.com>I advise against jump-upgrading.
We have a policy of dropping wire compatibility with 2 year old branches. 2.3 was released three years ago, so the nodes may even not be able to talk to each other.
You could upgrade a major release at a time (2.3 -> 3.0 ->
4.4). These have the code to talk to each other. But we only ever
test upgrading across one minor release, so you'll be the first
one to test those code paths. It is brave, but you don't want to
be brave in production. It will also be hard to assist you if
something goes wrong.
To view this discussion on the web visit https://groups.google.com/d/msgid/scylladb-users/102b2285-c940-47f2-b7b7-9d5e31fe1dben%40googlegroups.com.

Tomer Sandler
<tomer@scylladb.com>This can be a hot/cold migration - you can read more about migration strategies here
To view this discussion on the web visit https://groups.google.com/d/msgid/scylladb-users/03d07717-81be-2f09-f299-3b40ab50263a%40scylladb.com.
Andrei
<fauxnomakaalias@gmail.com>The biggest concern with jump-upgrading is that nodes with different versions may not be able to communicate with each other and this can cause downtime for the cluster.
Tomer Sandler
<tomer@scylladb.com>After upgrades running `nodetool upgradesstables` or just firing a major compaction like you did, will compact the sstables and the newly created will be with the newly supported sstable file format.
This is just 1 storage footprint optimization I can think of, there are probably some more.
It would be VERY hard to go over 3 years of developments spreading over tens of patch, minor and major version releases.
You can dive into our release notes and read about all that happened from 2.2 until 4.4 (which is A LOT).
To view this discussion on the web visit https://groups.google.com/d/msgid/scylladb-users/7e51370d-158a-432d-aa18-d5528ac94f53n%40googlegroups.com.
Tomer Sandler
<tomer@scylladb.com>Some reading:
- https://ultrabug.fr/Tech%20Blog/2019/2019-03-29-scylla-four-ways-to-optimize-your-disk-space-consumption/
- https://scylladb.medium.com/capacity-planning-with-style-57eddbbf92d1
Andrei
<fauxnomakaalias@gmail.com>Thanks Tome for the explanation and thanks a lot Scylla team! I tried a "jump-upgrade" from 2.3.1 --> 3.0 --> 4.3.6 and everything looks ok.